先日こちらの記事を投稿しました。
自分にとってのもう一つの謎は、 Databricksでデータベースを使いたい(SQLを使ってデータにアクセスしたい)場合にはどうすればいいのか?そもそも、データベースはあるのか? ということでした。
以下のような記事を書いてくる中で腹落ちはしましたが、今回も絵や実例を駆使して可能な限り分かりやすくDatabricksにおけるデータベースを説明してみたいと思います。これでも分かりにくい場合には私の修行がまだ足りないので精進します。
Databricksクイックスタートガイドのコンテンツです。
注意
この記事のスコープにはUnity Catalogを含めていません。Unity Catalog(UC)ではデータベースにさらに新たなコンセプトを導入しているので、別途UCもスコープに含めた記事を書く予定です。
Databricksにデータベースはあるのか?SQLでデータを操作できるのか?
答え データベースはあります。SQLで操作もできます。
ただ、ここはそもそものデータベースの定義など踏まえて説明をした方が良いと思います。こちらの記事でも引用していますが、
データベースとは
コンピューティングにおいて、データベースは、電子的に保存され、アクセスできる組織化されたデータの集合である。
この定義に沿って考えれば、答えはYESです。しかし、OracleやSQL Server、MySQL、Snowflakeのようなデータベース管理システム(DBMS)がインストールされているのか?と聞かれると答えはNOとなります。これらのDBMSやデータウェアハウスとDatabricksにおけるデータベースは実装が異なります。
では、なぜDatabricksにおけるデータベースの実装が他のデータベース管理システムやデータウェアハウスと異なるのでしょうか。それは、Databricksがレイクハウスであることに由来します。Databricksの実装の説明をする前に、このレイクハウス誕生の背景を説明させてください。
レイクハウス誕生の背景
こちらでレイクハウス誕生の経緯の説明と、レイクハウスとデータウェアハウス、データレイクとの比較をおこなっています。
データウェアハウスの出現
まず、データ管理プラットフォームとしてデータウェアハウス(個人的にはデータベースと同義だと思っています)が1990年台に台頭し、多くの企業で導入されました。ビジネス上の意思決定を行うためにデータを蓄積し、BIなどを通じて意思決定にデータが活用されるようになりました。データウェアハウスの特徴をざっくり列挙します。
- 行と列で構成される構造化データを蓄積
- SQLによる問い合わせ、加工が可能
- (比較的)大量のデータを管理可能
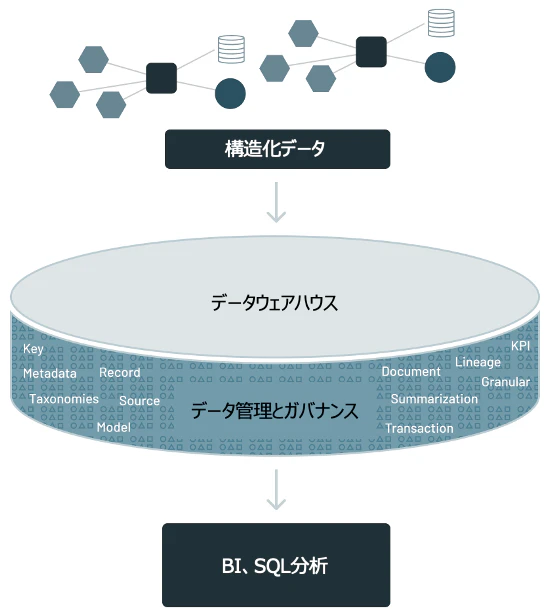
これらの特徴は現在においても多くの企業のデータ活用に役立っており、ある意味成熟したテクノロジーと言えます。しかし、ここ数年、このデータウェアハウスでは応えられない要件が出現しています。そう、機械学習やAIの活用です。
データレイクの台頭
BIやSQLを用いた分析など、過去の構造化データを蓄積し、活用するというシーンにおいてはデータウェアハウスは非常に有用です。一方、機械学習モデルをトレーニングし、将来の予測に活用する、画像やテキストを分析するという要件にデータウェアハウスは応えることができませんでした。そのため、機械学習・AIのニーズに応えることのできる新たなデータ管理プラットフォームが求められました。これによって、2010年頃にデータレイク誕生しました。データレイクの特徴をざっくり列挙します。
- クラウドサービスのオブジェクトストレージにデータを格納
- 構造化データ、非構造化データに対応
- 理論上、容量は無制限
- 機械学習のワークロードとの親和性が高い
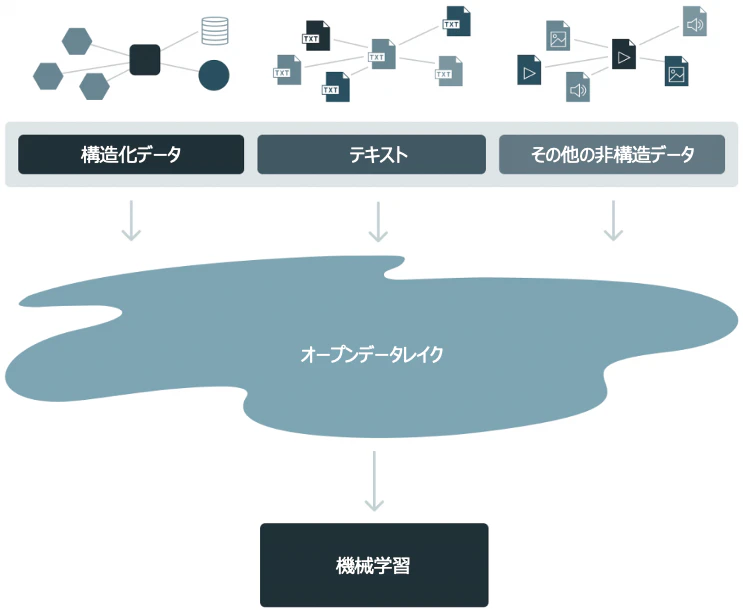
これによって、データレイクを活用し始めた人々は機械学習・AIによる明るい未来を夢想しました。しかし、世の中はそんなに甘くありません。上述の特徴は確かに機械学習の取り組みにおいては非常に有用なものでありましたが、企業の取り組みにおける重要な観点が欠落していました。パフォーマンスとガバナンスです。オブジェクトストレージに無尽蔵にデータを格納できたとしても、検索・更新に非常に時間を要してしまい、さらには、管理がなされないためゴミだらけでのデータレイクになってしまうということが頻発しました。結果として、データレイク(湖)ならぬデータスワンプ(沼)とまで揶揄されるようになってしまいました。
レイクハウスの誕生
上の記事にもレイクハウスがなぜ必要だったのかという説明がありますので、詳細はここでは割愛しますが要はこれまでに出現しているデータプラットフォームそれぞれでは、今の機械学習・AIのニーズに応えきれないから(データ)レイクハウスが開発されたということです。
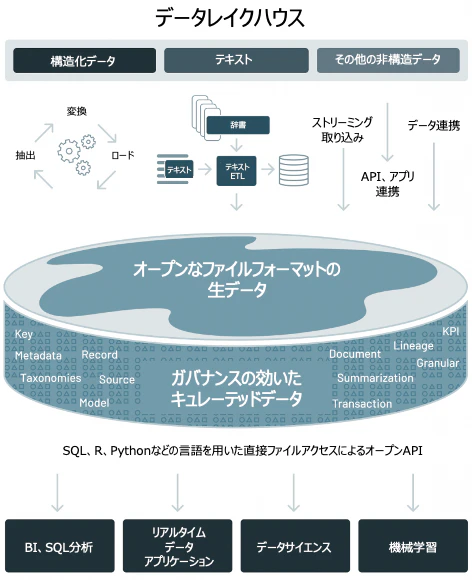
元記事にも記載されていますが、レイクハウスではデータはオープンなフォーマットでクラウドストレージに格納します。これによって、ベンダーロックインの回避、無限のストレージ、機械学習ワークロードとの親和性といったことを実現します。さらに、データウェアハウスで培われたパフォーマンスやガバナンスをも実現しているのです。
Databricks(レイクハウス)におけるデータベースの実装
前置きが長くなりましたが、レイクハウスでは生データはas-isの状態でクラウドのオブジェクトストレージに保存することで、上述のメリットを提供しています。なので、まずはDatabricksはファイルベースのデータ管理を行っていることに留意する必要があります。一方、従来のデータベースはファイル管理をデータベースでカプセル化しているので、ユーザーの方は通常はファイルを意識することはほとんどありません。個人的にはこの実装の違いがとっつきにくい所になっているのかなと思います。
ただ、従来のデータベースでは、パフォーマンスを最適化した独自フォーマットでデータを保持することで上記のカプセル化を実現しており、そのためにはデータベースへのデータのインポート(コピー)が発生することに加えて、敢えてベンダーロックインされに行っているとも言えます。
レイクハウスでは、オブジェクトストレージに生データを配置することでユーザーの自由度を担保しつつも、繰り返しになりますが、高いパフォーマンスとガバナンスを実現しています。この部分に関してはDelta Lakeが重要な役割を担っているのですが、本記事の主旨から若干外れるので割愛します。
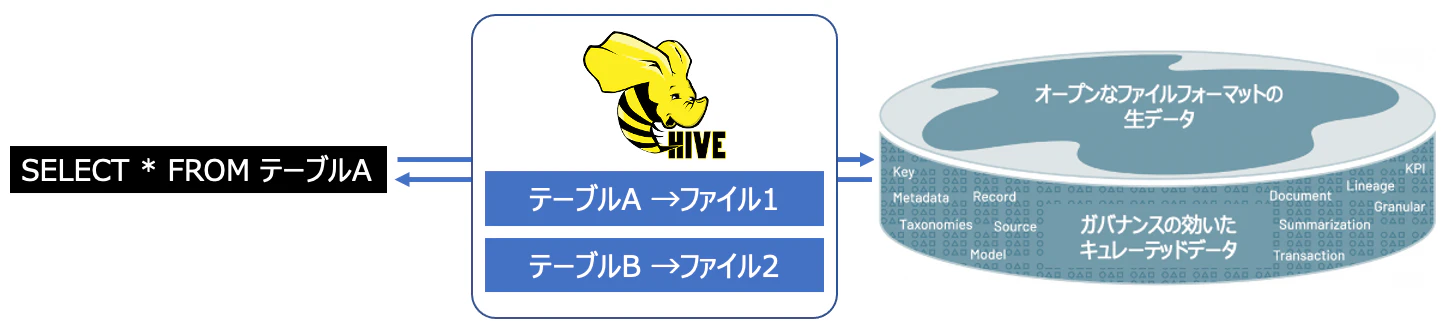
一般論になりますが、クラウドストレージは容量無制限というメリットがある一方で、膨大な数のファイルの一覧に時間を要するという課題が存在しています。このアーキテクチャにおいて、SQLを実現する際にこれが大きな障壁となります。この課題を解決するためにDatabricksではメタストアが導入されています。
SQLといえば、SELECT文が有名ですが、
SELECT * FROM hoge;
というようにテーブルを指定して各種の操作を行います。従来のデータベースを利用している際には、テーブルを作成すればそのままSQLを適用できる訳ですが、上述の通り、Databricksではファイルベースのデータ管理をおこなっているので、 このテーブルはどのファイル? という紐付けをしてあげないと、SQLを発行することができません。これを助けてくれるのがメタストアです。名前の通り、メタデータを格納するデータベースです。この場合はファイルのメタデータを格納することで、SQLを実行する際にこのテーブルはこのファイルですという関連づけを行なってくれます。メタストアを活用することで、ファイルベースのデータ管理をしている中でも、テーブルに対応するファイルを高速に特定できることに加え、テーブルをシームレスに参照してSQLを実行できるようになります。
DatabricksではデフォルトでHiveメタストアが同梱されているので、これを活用することでデータに対してSQLを実行できるようになっています。ファイルフォーマットによりますが、データをメタストアに登録すれば、あとは自動でデータとメタデータが同期されるようになります。
注意
- Databricksの処理エンジンはApache Sparkですが、Spark自身がSQLをサポートしていますので、DatabricksではネイティブでSQLをサポートしています。
- メタストアを介さずにファイルを指定してSQLを実行することもできます。後ほどデモします。
DatabricksにおけるSQLの活用
まず、メタストアに登録されているデータは、サードメニューのデータからアクセスすることができます。データベース.テーブルという2レベルの名前空間となっています。
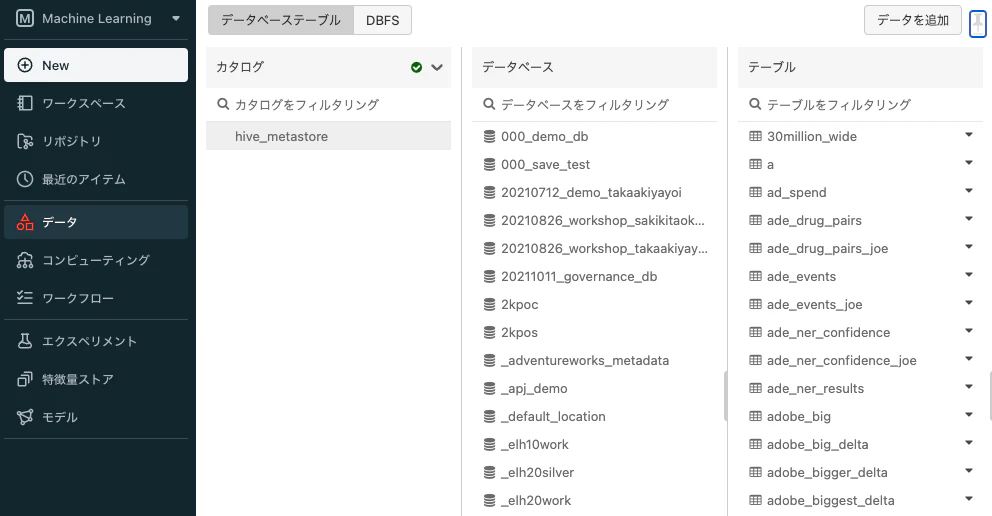
注意
Unity Catalogでは新たにカタログが導入され、カタログ.データベース.テーブルという3レベルの名前空間になっています。
テーブルの参照
SQLノートブックを作成すれば、デフォルト言語がSQLとなりますので、このノートブックで自由にSQLを操作することができます。データベースを一覧します。
SHOW DATABASES;
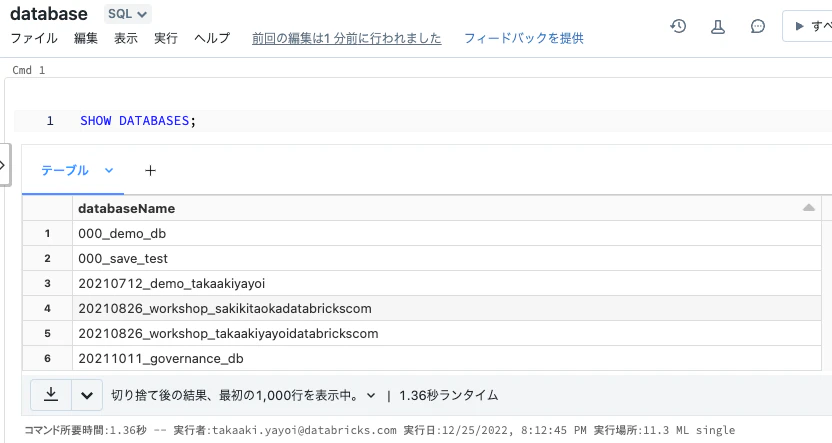
データベースを選択して、データベース内のテーブルを一覧します。
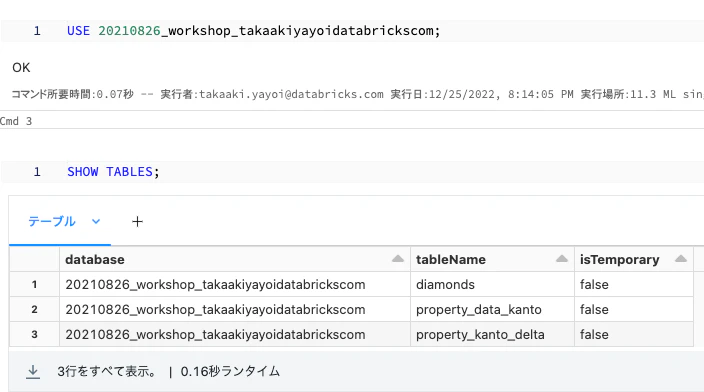
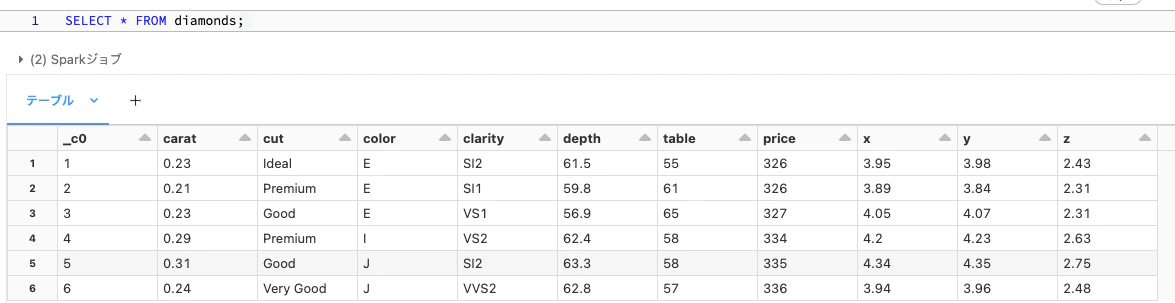
テーブルにSELECTを実行します。
SELECT * FROM diamonds;
データベースと同じように結果を取得することができます。
なお、DESCRIBE句を用いることでテーブルのメタデータを確認することができます。
DESCRIBE DETAIL diamonds;

locationでテーブルの格納場所を確認することができます。
メタストアを介さずにSQLを実行
上で触れたように、メタストアを介さずにSQLでファイルパスを直接指定することができます。ただ、この場合、テーブル名という概念なしに操作を行うので、柔軟性という意味では若干難ありでクイックに内容を確認する、ファイルからテーブルを作成するという用途に使う形になるかと思います。フォーマット.パスという書式です。
SELECT * FROM csv.`dbfs:/databricks-datasets/atlas_higgs/atlas_higgs.csv`
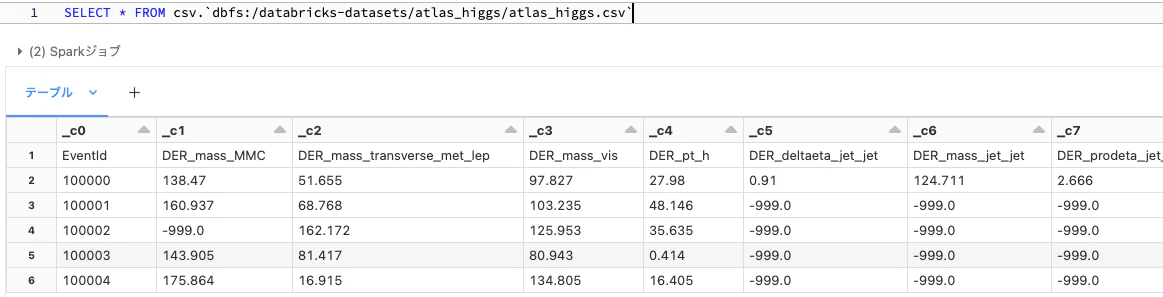
テーブルの作成
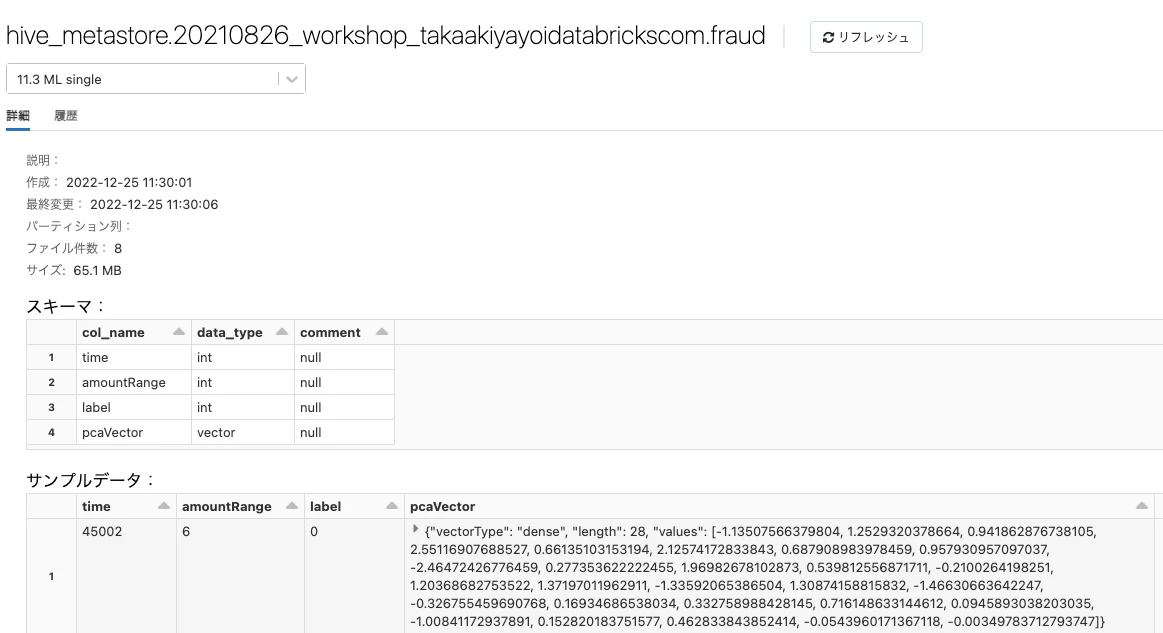
メタストアに登録しなくてもSparkを用いてSQLを実行できるのは、上のセクションで述べた通りなのですが、一緒に作業している人たちが毎度ファイルパスを見にいくよりはメタストアに登録されたテーブルを参照した方がコラボレーションしやすいと思います。そのため、データはメタストアに登録することをお勧めします。以下の例では、ファイルシステムに格納されているParquetファイルから読み込んだデータをテーブルfraudとしてメタストアに登録しています。
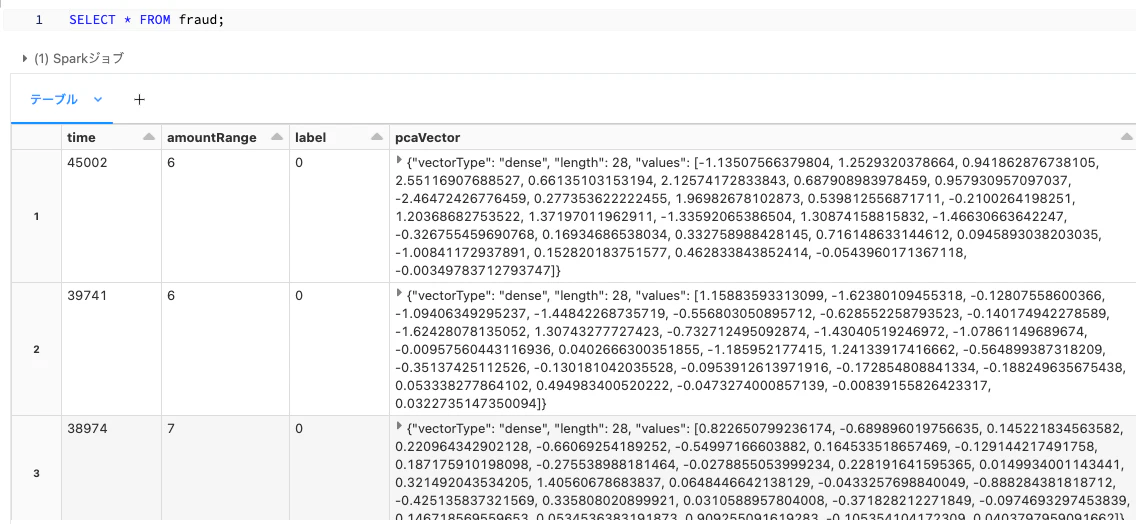
CREATE TABLE fraud USING DELTA AS SELECT * FROM parquet.`dbfs:/databricks-datasets/credit-card-fraud/data/`
こうすることで、あなたを含めた皆様がデータにアクセスする際にSQLを用いてテーブルfraudを参照できるようになります。
まとめ
データの永続化ではデータベース、データウェアハウスを活用するというのは非常に合理的な選択肢と言えます。SQLのパワーを活用することで様々なデータ処理を実現できるようになります。メタデータとデータファイルという概念は最初は取っ付きにくいかもしれませんが、柔軟性やパフォーマンス、オープンフォーマットの維持(ベンダーロックインの回避)などの観点で非常にメリットが多いアーキテクチャと言えます。さらに、ファイルフォーマットをDelta Lakeにすることで、メタデータの同期、データのバージョン管理、非構造化データの管理、高パフォーマンスなど更なるメリットを享受することができますので、データレイクにDelta形式でデータを保持し、快適なSQLライフを楽しんでいただければと思います。