Evolution to the Data Lakehouse - The Databricks Blogの翻訳です。
この記事はForest Rim Technologyのデータチームによるゲスト記事です。CEOのBill Inmon、Chief Data Strategy OfficerのMary Levinsの貢献に感謝の意を表します。
オリジナルデータの問題
アプリケーションの急増によって、データの完全性の問題が生じました。膨大な数のアプリケーションの到来によって、同じように見えるが異なる値を持つデータが多くの場所に存在することになりました。意思決定を行うために、ユーザーは多くのアプリケーションの中からどのバージョンのデータを使うべきかを見つけ出す必要がありました。正しいバージョンのデータを見つけ出し、利用できない場合には、間違った決定がなされる可能性があります。

人々は、意思決定に用いる正しいデータを発見するには、異なるアーキテクチャによるアプローチが必要であることに気付きました。データウェアハウスの誕生です。
データウェアハウス
データウェアハウスによって、異なるアプリケーションデータを別々の物理的な場所に格納することになってしまいました。アーキテクトは、データウェアハウスに代わる全く新たなインフラストラクチャを構築する必要性に迫られました。

データウェアハウスを取り巻く分析インフラストラクチャには以下のようなものがあります。
- メタデータ - どこに何のデータがあるのかを示すガイド
- データモデル - データウェアハウスにあるデータの抽象概念
- データリネージュ - ウェアハウスにあるデータのオリジナルとデータ変換の来歴
- サマライゼーション - データを作成するようにデザインされたアルゴリズムに対する説明
- KPI - キーパフォーマンスインジケーター
- ETL - アプリケーションデータを企業データに変換
企業で取り扱うデータの種類(テキスト、IoT、画像、音声、動画など)が増えるに従って、データウェアハウスの限界が明らかになってきました。さらに、機械学習(ML)、AIの出現によって、SQL以外の方法でデータに直接アクセスする必要のある、インタラクティブなアルゴリズムが導入されました。
企業における全てのデータ
多くのケースで、データウェアハウスが重要かつ有用であるのは、データウェアハウスが構造化データ向けに設計されているからです。しかし、今では企業には他のデータタイプが数多く存在しています。企業にどのようなデータが存在しているのかを見るために、簡単な図を示します。

構造化データは主に日々のビジネスを行うために、企業によって生成されるトランザクションベースのデータです。テキストデータは、企業内でやりとりされる手紙、メール会話などから生成されるデータです。他の非構造化データは、IoTデータ、画像、動画、アナログデータなど他のデータソースから得られるデータです。
データレイク
データレイクは企業におけるあらゆる種類のデータを合併したものです。データレイクは、Apache ParquetやORCなどの一般的かつオープンなファイルフォーマットでデータを保持するファイルAPIを用いて、低コストのストレージシステムに企業のデータをオフロードする場所となりました。オープンフォーマットの利用によって、データレイクが機械学習システムのように幅広い他の分析エンジンに直接アクセスできるようになりました。

最初データレイクが出現したときには、データレイクに求められる全てのことは、データレイクでデータが抽出され格納されることだと考えられていました。かつて、データレイクにおいては、エンドユーザーは単にデータレイクにアクセスし、データを検索し、分析を行うことができました。しかし、すぐに企業は、データレイクにおけるデータ利用は、単にレイクにデータを保持するのとは完全に違う話であることに気づきました。
データレイクで約束されていたことの多くは、いくつかの重要な機能が欠如していたため実現されませんでした:トランザクションの未サポート、データ品質やデータガバナンスに対する強制の欠如、貧弱なパフォーマンス最適化などが挙げられます。結果として、企業のデータレイクの多くはデータスワンプになってしまいました。
現在のデータアーキテクチャの課題
データレイク、データウェアハウスの限界から、データレイクといくつかのデータウェアハウス、そして、他の機能特化システムといった複数のシステムを組み合わせることが一般的なアプローチとなっていますが、3つの一般的な問題を引き起こしています。
- オープン性の欠如 データウェアハウスはデータをプロプライエタリなフォーマットにロックインし、他のシステムへのデータ移行に伴うコストを増加させます。データウェアハウスは主にSQLのみのアクセスを提供しているので、機械学習システムのような他の分析エンジンを実行することが困難となります。さらに、SQLを用いたウェアハウスへのデータへの直接アクセスする際には非常に遅く、高価になり、他の技術とのインテグレーションが困難になります。
- 機械学習に対する限定的なサポート MLとデータ管理の統合に関して多くの研究がなされましたが、TensorFlow、PyTorch、XGBoostのような先進的な機械学習はデータウェアハウス上で動作しません。少量のデータを抽出するBIと異なり、MLシステムは複雑な非SQLコードを用いて大量データを処理します。これらのユースケースにおいては、ウェアハウスベンダーはデータをファイルにエクスポートすることを推奨しており、複雑性を増加させ、データの鮮度を損なうことなります。
- データレイクとデータウェアハウス間のトレードオフの強制 オープンかつダイレクトなファイルアクセスを提供することによる柔軟性から、企業データの90%は安価なストレージを利用しているデータレイクに格納されています。データレイクにおける性能と品質の欠如を解決するために、企業は多くの重要な意思決定のために、ETLを通じてデータレイクにあるデータの小規模なサブセットを下流のデータウェアハウスやBIアプリケーションにデータを投入しています。この二重のシステムアーキテクチャは、データレイクとデータウェアハウス間での継続的なデータのETL処理を必要とします。それぞれのETLステップはエラーを引き起こし、データ品質を低下させるバグを導入し、データレイクとデータウェアハウスの一貫性を維持することを困難にし、コストを引き上げます。継続的ETLの費用に加え、ユーザーはデータウェアハウスにコピーされるデータに対して二重のストレージコストを支払うことになります。
データレイクハウスの出現
我々は今、データレイクハウスと呼ばれる新たなデータアーキテクチャの出現を目撃しています。データレイクハウスは新たなオープンかつ標準化されたデザインによって実現されています:データレイクで用いられている低コストストレージ上に、データウェアハウスと同様のデータ構造、データ管理機能を実装します。
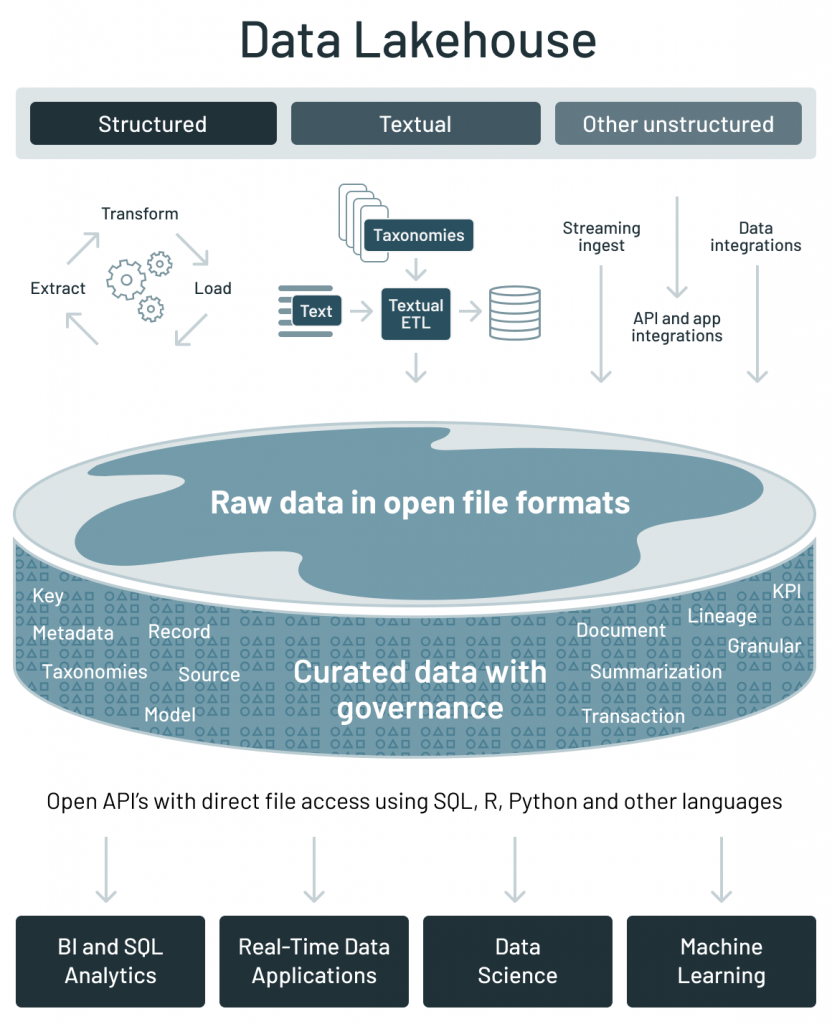
データレイクハウスアーキテクチャは、上のセクションで議論された現在のデータアーキテクチャの主要な課題に取り組んでいます。
- Apache Parquetのようなオープンフォーマットを用いた、オープンかつダイレクトなアクセスの実現
- データサイエンス、機械学習に対するネイティブサポート
- 低コストストレージにおける最高のパフォーマンスと信頼性の提供
レイクハウスアーキテクチャで提供される主要な機能は以下の通りです。
オープン性
- オープンファイルフォーマット: Apache ParquetやORCのようなオープンかつ標準化されたファイルフォーマットに準拠
- オープンAPI: プロプライエタリなエンジンやベンダーロックインを回避できる、データに直接かつ効率的にアクセスするためのオープンAPIの提供
- 言語サポート: SQLによるアクセスだけではなく、機械学習、Python/Rライブラリを含む様々なツール、エンジンのサポート
機械学習のサポート
- 様々なデータタイプのサポート: 画像、動画、音声、準構造化データ、テキストを含む様々なアプリケーションで用いられるデータの格納、精製、分析、アクセスをサポート
- 非SQLによるダイレクトかつ効率的なデータ読み込み: R、Pythonライブラリを用いた機械学習実験における大容量データに対するダイレクトかつ効率的なアクセス
- データフレームAPIのサポート: TensorFlow、PyTorch、XGBoostのようなMLシステムはデータ操作に対する主要な抽象概念としてデータフレームを採用しているため、MLワークロードにおけるデータアクセスのクエリー最適化を伴う宣言型のデータフレームAPIをビルトインでサポート
- ML実験におけるデータバージョン管理: 監査、ロールバック、ML実験の再現を行うために、以前のバージョンのデータへの復旧、あるいはデータサイエンス、機械学習チームが以前のバージョンのデータにアクセスできるようにデータのスナップショットを提供
低コストでベストな性能と信頼性を提供
- パフォーマンス最適化: ファイルの統計情報、適切なサイズへのファイルコンパクションを用いることによる、キャッシュ、多次元クラスタリング、データスキッピングなどの様々な最適化手法を提供
- スキーマ強制、ガバナンス: スター/スノーフレークスキーマのようなデータウェアハウスのスキーマアーキテクチャのサポート、および、堅牢なガバナンス、監査機構の提供
- トランザクションのサポート: 主にSQLを用いて複数のユーザーが同時にデータを読み書きする際に、ACIDトランザクションを用いて一貫性を保証
- 低コストのストレージ: レイクハウスアーキテクチャは、Amazon S3、Azure Blob Storage、Google Cloud Storageのような低コストのオブジェクトストレージ上に構築されています
データウェアハウス、データレイク、データレイクハウスの比較
| データウェアハウス | データレイク | データレイクハウス | |
|---|---|---|---|
| データフォーマット | クローズド、プロプライエタリなフォーマット | オープンフォーマット | オープンフォーマット |
| データタイプ | 構造化データ、一部の準構造化データ | 全てのタイプ:構造化データ、準構造化データ、テキストデータ、非構造化(生)データ | 全てのタイプ:構造化データ、準構造化データ、テキストデータ、非構造化(生)データ |
| データアクセス | SQLのみ、ファイルへの直接アクセスは未サポート | SQL、R、Pythonなど他の言語による直接のファイルアクセスのためのオープンAPI | SQL、R、Pythonなど他の言語による直接のファイルアクセスのためのオープンAPI |
| 信頼性 | ACIDトランザクションによる高品質、高信頼性のデータ | 低品質、データスワンプ | ACIDトランザクションによる高品質、高信頼性のデータ |
| ガバナンス、セキュリティ | テーブルの行/列レベルでのきめ細かいセキュリティ、ガバナンス | ファイルレベルのセキュリティ、貧弱なガバナンス | テーブルの行/列レベルでのきめ細かいセキュリティ、ガバナンス |
| パフォーマンス | 高 | 低 | 高 |
| スケーラビリティ | スケーリングによるコストは指数関数的に増加 | データタイプに関係なく、低コストで大規模データを保持できるようにスケーリング | データタイプに関係なく、低コストで大規模データを保持できるようにスケーリング |
| ユースケースサポート | BI、SQLアプリケーション、意思決定に限定 | 機械学習に限定 | BI、SQL、機械学習に対応できるアーキテクチャ |
レイクハウスのインパクト
我々がデータウェアハウスマーケットの黎明期に見たもの比較して、データレイクハウスは新たな機会を提供すると信じています。レイクハウスがデータをオープンな環境で管理するユニークな機能によって、企業のあらゆる部分から得られる様々なデータをブレンドし、データレイクに対するデータサイエンスのフォーカスと、データウェアハウスにおけるエンドユーザーによる分析を組み合わせることで、企業にとって計り知れない価値を解き放つことでしょう。
詳細が知りたいですか?であれば、データコミュニティのグローバルイベントData + AI Summitに参加してください。Bill InmonとDatabricks創始者&CEOであるAli Ghodsiの会話を聴講できます。この無料のバーチャルイベントでは、データ&AIのビジョナリスト、ソートリーダー、エキスパートがハイライトされています。スピーカーの完全な一覧はこちらを参照ください。
Forest Rim TechnologyはBill Inmonによって創立され、深い洞察と意味のある意思決定を行うために、構造化されていないテキストデータを構造化データベースに変換する分野における世界的なリーダーとなっています。