Pandas-Profiling Now Supports Apache Spark - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
pandas-profilingはydata-profilingとなりました
データプロファイリングは、データの品質やその他の特性を評価するために、データの統計情報やサマリーを収集するプロセスです。データプロファイリングによって、信頼でき、かつ、アクション可能な洞察を導き出すことのできる品質の良いデータフローを保証できるので、データディスカバリーとデータサイエンスライフサイクルの両方において重要なステップとなっています。プロファイリングには、1変量と多変量の観点の両方からのデータ分析が関与します。手動でのこの分析の実行は限定的で時間を浪費するものであり、特に大規模データセットにおいてはエラーが混入する可能性があります。
Databricksはデータ中心のMLプラットフォームへの要件を理解しており、これがDatabricksノートブックではすでにデータプロファイルタブを通じたビルトインのプロファイルやsummarizeコマンドをサポートをしている理由となっています。また、Databricksはオープンソースソフトウェアの強力なサポーターであり、お客様が自身の最も困難なデータ&AIの問題に取り組む際に必要とするいかなるオープンソースツールを常に活用できるようにしています。だからこそ、データプロファイリングのオープンソースライブラリであるpandas-profilingを提供しているYDataと合同でこの合同記事に取り組めることを嬉しく思っています。
新たな名前とSparkデータフレームのサポートによって、ydata-profilingは大規模なデータプロファイリングに取り込む際の新たな選択肢を提供します。Databricksとシームレスにインテグレーションされることで、最小限の労力でビッグデータに対する洗練された分析を実現します。以降では、数行のコードでydata-profilingをどのようにDatabricksノートブックとデータフローに組み込み、データプロファイリングのパワーを完全に活用するのかの詳細を説明します。始めましょう!
ydata-profilingによるデータプロファイリング:データ品質における標準的なEDAからベストプラクティスまで
pandas-profilingのローンチ以降、Apache Sparkデータフレームのサポートは最もリクエストされる機能の一つとなっていました。この機能は最新リリース(4.0.0)で利用でき、このより広範なサポートを反映するために公式名称もydata-profilingに変更されました。このオープンソースパッケージはGitHubで公開されており、データ専門家の大規模なコミュニティによってスタンドアローンのライブラリとして積極的に活用されています。pandas-profilingはpandasデータフレームのプロファイリングにおいてはDatabricksにおいても素晴らしい働きをしていましたが、ydata-profilingにおけるSparkデータフレームのサポートによって、ユーザーはビッグデータのフローからも最大の価値を得られるようになります。
多方面に渡るデータプロファイリングのプロセスには、大きく4つのコンポーネントが含まれます:
- データの概要: 特徴量の数やタイプ、利用できる観測結果の数、データにおける欠損値や重複レコードのパーセンテージのようなデータの主要な特性の要約を生成します。
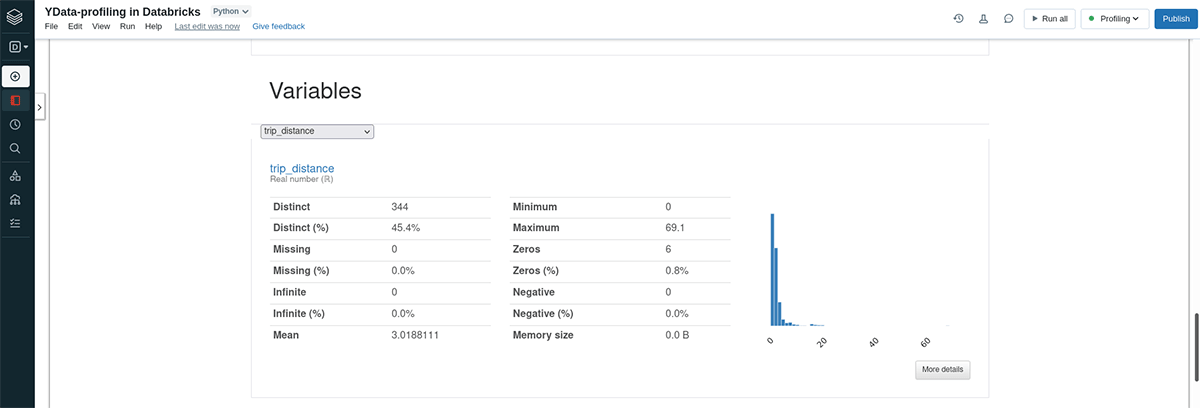
- 単変量分析、特徴量統計情報: データセットのそれぞれの特徴量にズームインし、キーとなる統計情報をレポートしたり、洞察のあるビジュアライゼーションを生成することでそれらの特性を調査することができます。この点に関して、ydata-profilingはそれぞれの特徴量のタイプと、特徴量が数値かカテゴリー変数かに基づいた統計情報を提供します。数値の特徴量は範囲、平均値、中央値、分散、偏り、尖度、ヒストグラム、分布曲線によって要約されます。カテゴリー変数の特徴量は、モード、カテゴリー分析、頻度テーブル、棒グラフによって説明されます。
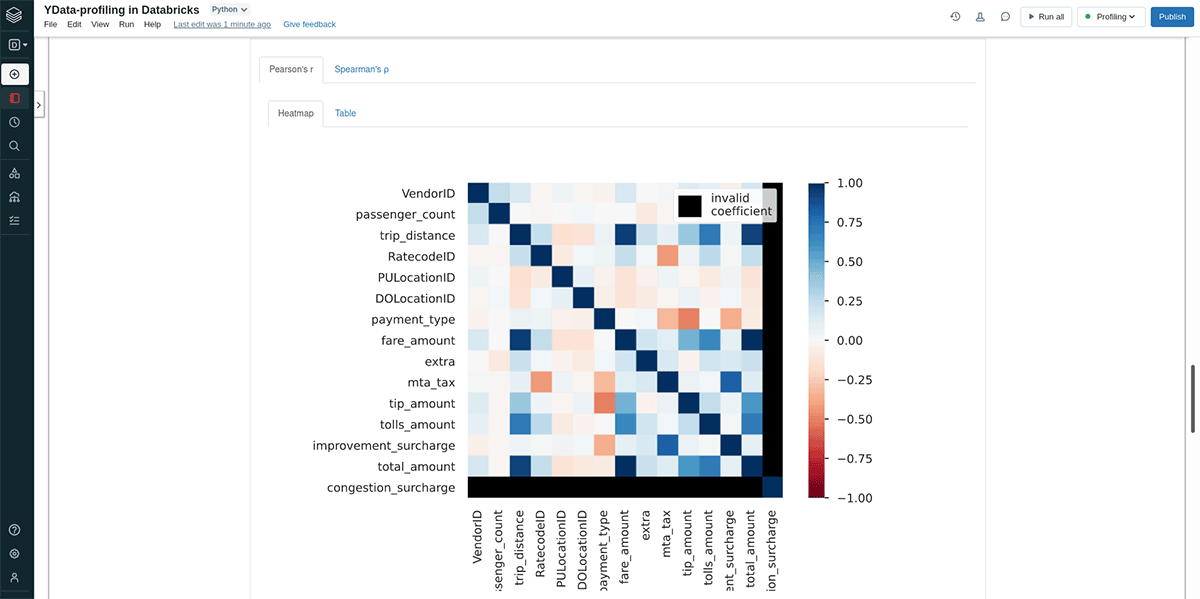
- 多変量分析、相関評価: このステップでは、多くの場合、相関係数や相互関係の可視化によって特徴量間の関係を調査します。ydata-profilingでは、特定のペアごとの散布図を用いて相互関係をうまく探索できるマトリクスやヒートマップを通じて相関関係が評価されます。
- データ品質評価: ここでは、モデル開発の前に更なる調査を必要とするような重要なデータ品質問題のシグナルを捉えます。現在サポートされているデータアラートにはユーザーがしきい値をカスタマイズできる、定数、ゼロ、ユニーク、無限値、偏りのある分布、高い相関やカーディナリティ、欠損値、クラスの非均衡が含まれます。
継続的かつ標準化されたデータプロファイリングステップを実行することは、企業で利用できるデータ資産を完全に理解するためには重要なこととなります。これなしには、データチームは効果的な機械学習ソリューションを提供するための自身の能力に直接のインパクトを与えるような、属性間の重要な関係性、データ品質問題、その他の問題の識別に失敗する可能性があります。また、これはデータフローの効率的なデバッグやトラブルシュートや、データ管理や品質管理におけるベストプラクティスの構築を可能とします。これによってデータ専門家は、多くの場合リアルタイムで発生するプロダクションのモデリングのエラー(例: レアなイベント、データドリフト、公正性の制約、プロジェクトゴールからの逸脱)をクイックに対策することが可能となります。
Databricksでydata-profilingを使い始める
このチュートリアルでは、NYC yellow taxi trip dataを使用します。これは、コミュニティではよく知られたデータセットであり、乗車/降車、移動距離、支払い詳細を含むタクシー移動の情報が含まれています。
Databricksノートブックにおけるこのデータセットのプロファイリングは、これらの簡単なステップに従うだけの非常にシンプルなものとなっています。
- ydata-profilingのインストール
- データの読み込み
- プロファイルレポートの設定、実行、表示
ydata-profilingのインストール
Databricksノートブックでydata-profilingを使い始めるには、以下の2つの選択肢のいずれかを使用します:
以下のコードを実行してノートブックスコープライブラリとしてインストール:
%pip install ydata-profiling==4.0.0
あるいは、クラスターにパッケージをインストールします:
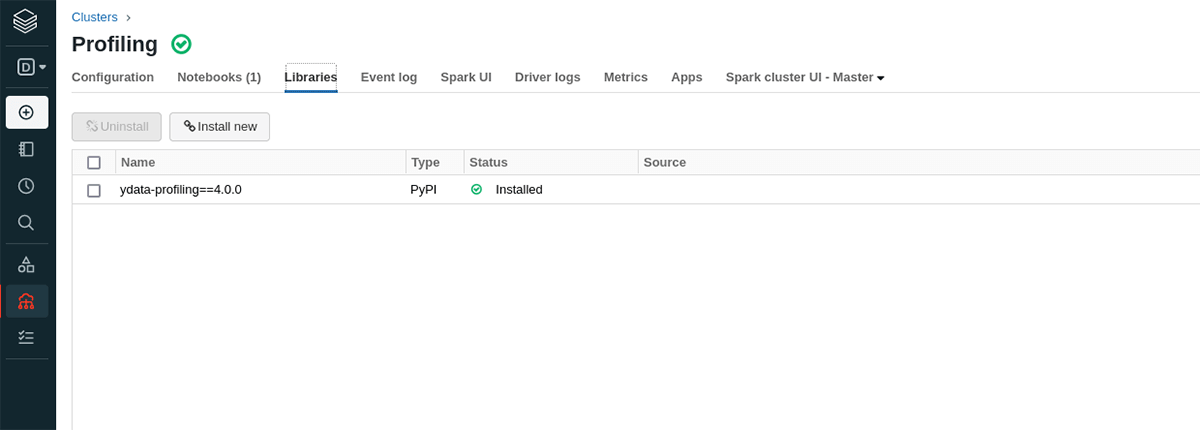
主にご自身のフローや、ほかのノートブックでもプロファイリングを行うのかどうかによって意思決定が異なります。
データの読み込み
NYC taxiデータセットはDatabricksワークスペースにすでに存在しているので、サンプルとしてそこからファイルをロードします。DBFSのdatabricks-datasetsディレクトリではこのファイルや他のデータセットにアクセスすることができます。自由に他のファイルを読み込んでも構いませんが、必要に応じてクラスターのサイズをスケールさせる必要があるかもしれません。
# Load an example CSV and save it as a Delta table.
raw_path = 'dbfs:/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-01.csv.gz'
bronze = (
spark.read.format('csv')
.option('inferSchema', True)
.option('header', True)
.load(raw_path))
bronze.write.format('delta').mode('overwrite').saveAsTable('yellowtaxi_trips')
これでDeltaテーブルをロードし、処理の基盤として活用できるようになります。分析においてはこのデータに対して多くの処理を行うことがあるので、このデータフレームをキャッシュしておきます。
df = spark.table('yellowtaxi_trips').cache()
display(df)
プロファイルレポートの設定、実行、表示
Sparkデータフレームのプロファイルを生成できるようにするには、ProfileReportインスタンスを設定する必要があります。デフォルトのSparkデータフレームのプロファイル設定はydata-profilingのconfigモジュールで確認できます。ydata-profilingのpandasデータフレームのいくつかの機能がSparkデータフレームでは(まだ!)利用できないため、この手順が必要となります。ProfileReportのコンテキストはreportコンストラクタを通じて設定できます。
from ydata_profiling import ProfileReport
report = ProfileReport(df,
title='NYC yellow taxi trip',
infer_dtypes=False,
interactions=None,
missing_diagrams=None,
correlations={"auto": {"calculate": False},
"pearson": {"calculate": True},
"spearman": {"calculate": True}})
レポートを表示するには、コマンドの最後の行としてレポートオブジェクトを評価するか、より明示的にするためにHTMLを抽出してdisplayHTMLを使用します。ここでは後者を実行します。注意: これを初回実行する際にはメインの処理が発生し、少々の時間を要する場合があります。 以降の実行と評価は同じ分析結果を再利用します。
report_html = report.to_html()
displayHTML(report_html)
コマンド出力の一部としてレポートを表示することに加え、別個のHTMLファイルとして計算されたレポートを容易に保存することができます。例えば、これによって組織の他の方と容易にレポートを共有することができます。
report.to_file('taxi_trip.html')
同様に、このレポートの洞察を後段のデータワークフローに組み込みたい場合には、JSONファイルとしてレポートを抽出、保存することができます。
report.to_file('taxi_trip.json')
HTMLやJSONとして書き出すかどうかは、ファイルの拡張子によって決定されます。
まとめ
Sparkデータフレームのサポートの追加によって、ydata-profilingはスタンドアローンパッケージとして大規模データプロファイリングと、DatabricksのようにすでにSparkを活用しているプラットフォームとのシームレスなインテグレーションの両方の扉を開きました。ご自身の大スケールユースケースでこのシナジーをすぐに活用してみてください: こちらのクイックスタートサンプルにアクセスし、ご自身で試してみてください!
すぐにでもDatabricksで、新たなydata-profilingのSparkサポートをトライしてみてください!