How (Not) to Build AI Apps in 5 Easy Steps | by AI on Databricks | Nov, 2025 | Mediumの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
著者: Ricardo Portilla, Principal Architect — Databricks
多くの企業のように、日々のタスクを拡張するためにAIを用いた新たなペルソナの爆発を目撃していることでしょう。現在の世界においては、いくつかのリファレンス文書があればエージェントの作成には2分もかからないでしょう。しかし、実践者として以下の選択肢に直面することになります: A) 型通りのエージェントで日々のワークフローを拡張する。 あるいは、 B) 同僚があなたの知識ベースを参照できるようにする洗練された自律エージェントを構築するために、ルーティングロジック、メモリー、プロンプトキャッシュ、マルチターンのロジックの作成に数週間を費やす。
過去数ヶ月間において、私は同僚の生産性を大幅に引き上げ、週あたり数時間を削減するパスAに属するAIアプリを作成しました。しかし、ここ最近ではよくある話で他のチームが同じものを構築していたのです。このため、私はパスBに進み始めました - モデルチューニング、ベクトル検索、マルチターンの会話、コンテキストエンジニアリングです。午後くらいでは複製されない何かです。そして、私は間違った問題を解いていることに気づきました。
日々私が受け取るリクエストにはパターンがあります: RFPにおける競合のポジショニング、ドキュメント化されていないマイグレーションパターン、アーキテクチャ上のエッジケースです。これらはワンオフの質問ではなくシステム化されたツールを必要とする繰り返し起こる問題です。しかし、優れたツールの作成には一般的ではないデータソースの活用、自動化されたAIテストによる密接な内部ループ、価値を立証するためのツールの観測可能性が必要となります。
私は、新たなアーキテクトにとってポジショニングとベストプラクティスで支援するデータ中心のAIアプリをDatabricksを用いて構築しましたが、このアプリ自身が強みではありません。再利用可能なツールを構築するために活用されたエンジニアリングファーストのアプローチが重要です。以下では、あなた自身の生産性を増幅するツールを作成する5つのステップを示します。
ステップ1 - ポートフォリオマネージャのように考えましょう
ポートフォリオマネージャーは単に公開されている証券を購入するのではありません。彼らは、衛星画像、出荷マニフェスト、空輸価格のデータに関係なく、彼らに強みを与える代替データを探しています。希少性があったり、発掘が困難なデータです。
あなたの会社も同じ機会を持っています。
あなたの会社の競合優位性は、あなたのSME(特定領域の専門家)の個人用GDriveにある乱雑なPPTXファイル、ドキュメント化されていないGitHubのリポジトリ、決して公開されない業界文書に存在しています。
これを説明するために、我々はSMEの知識ベースからCoE(センターオブエクセレンス)チェックリストや素晴らしいベストプラクティスの文書を入手しました。これは最有力候補ですが煩雑なものです。PPTX自身には一貫性のないカラムや階層構造が欠如しているテーブルやマージされたセルが存在しています。最初のステップは、高度に非構造化されたデータ、バイナリーデータを格納し、テキスト抽出のためにOCRを行うための保護された場所であるUnity Catalogのボリュームにこれらの文書をロードすることです。
ここでストップして、エージェントに生の文書を入力することもできます。しかし、品質がひどい可能性があります。実際のところ、我々は生のデータをクエリーして、より高度なレベル7のカテゴリーではなく、最初の会話で期待すべき主要なCoEの13カテゴリーを作るようにAIに依頼しました。乱雑な回答を生成する乱雑な情報を有している場合があることで、エージェントがハルシネーションを起こすことでしょう。データを綺麗にしない限りAIはあなたに反抗します。
ステップ2 - コンテンツを綺麗にしましょう
あなたが最初の5つの文書を集めると、文書構造においては共通パターンが存在しないことを理解し始めることでしょう。ここで、地味なAI、データ操作にフォーカスした実践的なAIが、あなたの乱雑な文書を適切にタグづけされ、自己記述的でAIレディのデータに変換する助けとなります。私が見つけたベストプラクティスを含む文書群には、音声の書き起こし、煩雑なPowerpoint内のチェックリスト、文書化されていない古いコードベース、そしてコードスニペットが含まれていました。
直感と反する最初のステップとして、初めにPPTXをPDFに変換します。DatabricksネイティブのAI関数のai_parse_documentが、マージされたセルやcolspanと苦戦するのではなく、視覚的なレイアウトから構造を推定するので、PDFからよりクリーンに抽出を行います。現時点でai_parse_documentがサポートしている文書タイプの完全な一覧です:
- ppt/pptx
- jpg/jpeg
- doc/docx
- png
これによって、最初のOCRステップの助けとなりますが、検索に有用なメタデータとしての階層構造やコンテンツカテゴリーに解析の問題を完全に解決するわけではありません。HTMLタグがつけられたセクションへの典型的な解析は、LLMが詳細な質問に答えられるようにする文書の意味的な構造を明確にしません - 例えば、以下のCoEコンテンツでは、モニタリングとコストのアラートにおけるベストプラクティスに対する可観測性チェックリストのすべての要素を知る必要があります。すべてのベストプラクティスを知る必要のある情報をアーキテクトに高品質な情報を提供するために、グルーピングすべきハイレベルのカテゴリーを理解している場合にのみこれが可能となります。
解析(パーシング)によって得られるもの
✅ 文書の要素(テーブル、段落、画像)の特定
✅ 一つのAPIで複数のフォーマットに対応(PPTX、DOCX、PDF)
解析で得られないもの
❌ 階層構造や関係性の推定
❌ あなた固有のユースケースに合わせた構造化

こちらは、AIレディなVector Searchにデータを取り込むために必要なすべてを抽出しようとする完全なコードです。データ中心のアーキテクチャではデータはレイクハウスに存在するので、ネイティブなVector Searchの活用が重要となります。レイクハウスのデータをエクスポートすることはコピーを作成することになるだけではなく、同期のためのエンジニアリング工数を増加させます。DatabricksネイティブのVector Searchでは、Unity Catalogテーブルのチェンジデータフィードを用いて同期がインクリメンタルに行われます。さらに、ドキュメントのベクトル化を行うためのネイティブなエンベディングがあるので、ツールであなたのデータを処理するための工数を削減します。
# 1. PARSE: Use Databricks AI function to extract document structure
pdf_path = "/Volumes/main/field_ai/coe_ppts/CoE Value Checklist.pdf"
parsed_df = spark.read.format("binaryFile").load(pdf_path) \
.selectExpr("path", "ai_parse_document(content) as parsed_content")
# 2. STRUCTURE: Use LLM to convert unstructured text → structured JSON
query_result = spark.sql(f"""
SELECT ai_query(
'databricks-meta-llama-3-1-405b-instruct',
'Extract checklist items with category, deliverable, priority...',
'{full_text}'
) as result
""")
# 3. LOAD: Write to Delta table with change data feed enabled
spark_df.write.format("delta").mode("overwrite").saveAsTable(source_table_fqn)
spark.sql(f"""
ALTER TABLE {source_table_fqn}
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
""")
display(spark.table(source_table_fqn))

以下は、さまざまな生のコンテンツにおいて優れたデータ補強のための完全なアーキテクチャがどのようなものになるかを示したものです:
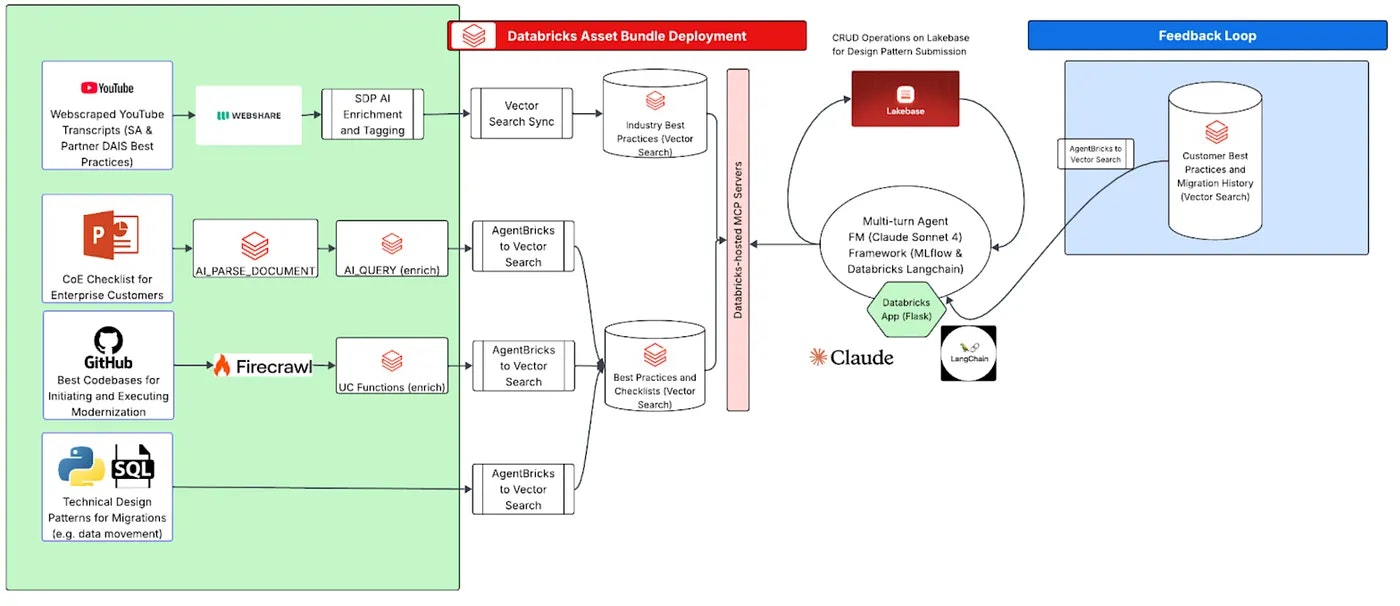
汎用的なリファレンスとして、DatabricksのAI関係のすべての製品の中で緑でハイライトされているツールはあなたのドキュメントを補強しデータをAIレディにします。我々のリファレンス実装ではこれら全てを使用しました。

この時点で、あなたはご自身のベクトルストアに格納されているクリーンで適切に構造化されたデータを手に入れたことになります。多くのチームはここでストップして、エージェントの構築に突撃します。これは魅力的ですが未熟といえます。あなたは、あなたのチームが知っていることのみに関する単一目的のチャットボットを構築し、今から6ヶ月後にさらに3バージョンのチャットボットを目撃することになります。
ここに罠があります: 数週間のデータクリーニングの後でエージェントの構築は自然な衝動となります。耐えてください。代わりに、再利用なツールとしてあなたのデータを公開しましょう。
ステップ3 - エージェントではなくツールにフォーカスしましょう
エージェントファーストの開発は、ハーバードビジネスレビューがAIワークスロップとして引き合いに出す、ユーザーにより認知を求める負荷と作業を強いる低品質なAI生成アウトプットにつながる傾向にあります。低品質アウトプットのリスクに加えて、現在のAIアプリの主要な問題の一つは、あなたを新たなアプリにロックインしたり、カスタムAPIを繋ぎ合わせることを強制するということです。幸運なことに、外部ツールにLLMを接続するオープン標準であるモデルコンテキストプロトコル(MCP)は、ユーザーがすでに使用しているツールや環境(Cursor、Claude、Databricks Appsなど)にあなたのクライアントを即座に接続できるようにします。このメリットを示す2つのシナリオがあります: a) 高品質なツールを再構築したり、固定的なインテグレーションなしに、エージェントはカイブでホスティングされているMCPサーバーを発見、アクセスすることができます。 b) ほとんどのクライアントにはすでにMCPインテグレーションが搭載されており、インテグレーションのためにカスタムのクライアントコードを記述する必要性を低減します。
a)を説明するために、MCPツールインテグレーションに対する統合アプローチを示す以下のクライアントコードを見てみましょう。ここでは、Genieのような自然言語クエリーツール、任意のUnity Catalog関数、Databricks Vector Searchに格納されているインデックスされたコンテンツに対するDatabricksマネージドのMCPサーバーの使用法をハイライトしています。
# With MCP - ONE method for ALL indexes
def search_any_index_via_mcp(index_name: str, query: str):
return mcp_client.call_tool(index_name, {"query": query})
# Works for security, migration, testing, CoE...
search_any_index_via_mcp("main.field_ai.bronze_youtube_dais_best_practices_idx", "What does databricks recommend for streaming DR?")
search_any_index_via_mcp("main.field_ai.bronze_migration_idx", "What's the strategy for moving stored procs in Teradata to Databricks?")
上のコードでは対応していない未解決の複雑性は、ユーザーがツール観点で何が利用可能なのかを理解する助けとなる集中管理されたカタログです。Databricksでは、マネージドMCPサーバーから外部MCPサーバーをカバーし、Unity Catalogでそのようなツールに対するガバナンスやアクセスをシンプルにするMCPカタログでこの問題を解決します。
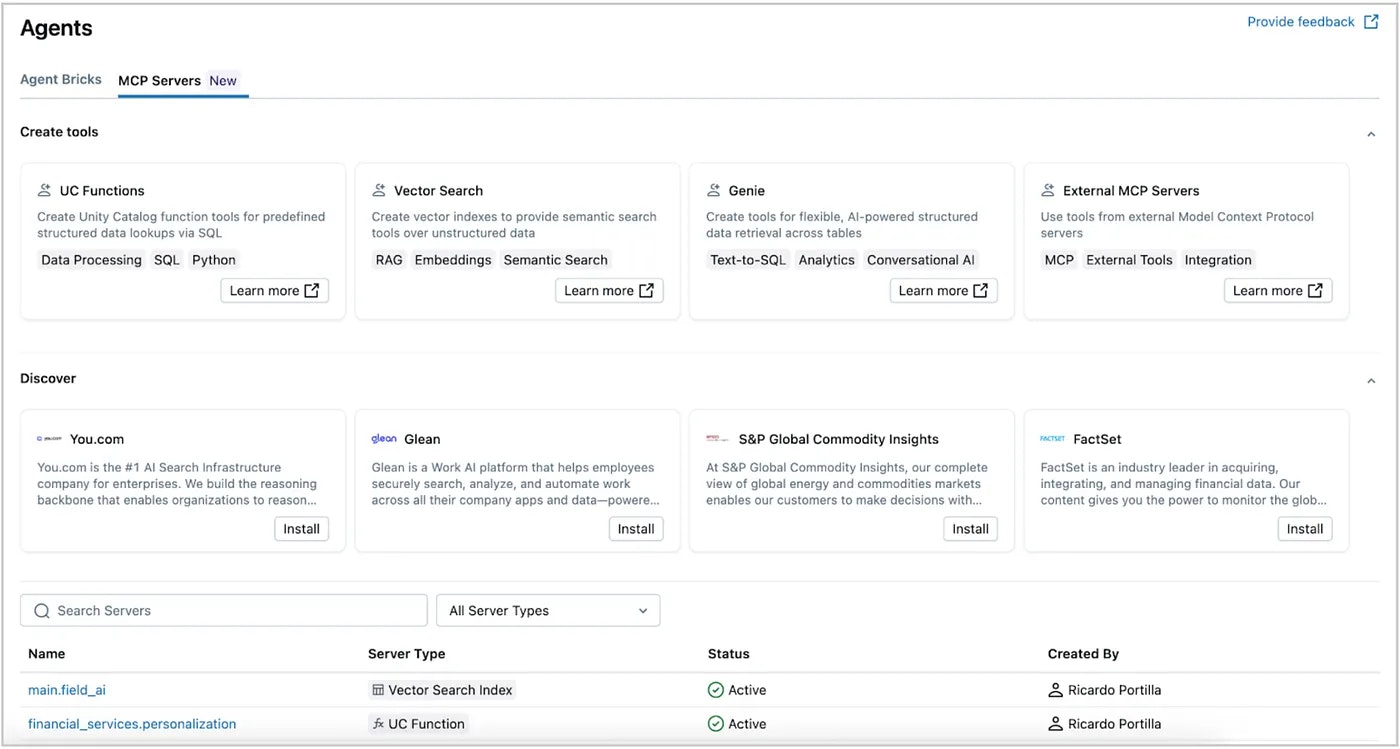
これで、再利用可能なツールのライブラリを開発、発見したのでエージェントを構築することができます。実際、インテグレーションテストではシンプルなエージェントが必要となります。しかし、初めのいくつかの疑問のため、あなたのツールが実際にうまく動作するのかどうかがわかりません。多くの企業では、退行を認識した際には結果をバイブチェックしたり、長期にわたる繰り返しのサイクルをおこなってしまっています。彼らは、壊れているものを出荷したり、信頼を失っています。次で説明するのがテストを行う正しい方法です。
ステップ4 - LLMジャッジで品質を改善しましょう
ツールを出荷してうまく動くことを期待することはできません。従来のコードではバグは常に存在します - まとめて修正するか修正続けることになります。LLMを用いることで、あなたのツールは今日素晴らしい回答をもたらすかもしれませんが、あなたがベクトルストアの日等のドキュメントを変更したことで明日はハルシネーションを起こすかもしれません。品質チェックを自動化する必要があります。ソリューションはLLMジャッジです。

上の画像に示すように、SMEによって提供される問題の文脈で回答を検証することでLLMがヘビーリフトをおこなっています。このフレームワークを活用するには、質問と期待する回答を含むCSVファイルである回答シートにプラグインするための標準的なAPIを提供するMLflowのLLM-as-a-judgeを用いたテストツールを実行します。これをさらに一歩進めて、MLflowのビルトインのRetrievalQualityやRelevanceジャッジを活用しつつも、カスタムのMLflowスコアラーを用いたすべてのテストのファクトチェックを組み込むためにジャッジをカスタマイズしました。非同期のテストハーネスと繰り返し可能なテストフレームワークによってローカルでのイテレーションは非常に高速ですが、CI/CDプロセスは100の実験に数時間を要する場合があります。MLflowと後述のレポートで実現できるカスタムスコアラー実装がどれだけシンプルでパワフルなのかを示すスニペットを以下に示します。ご自身で試すには、こちらのcomposite evaluator GitHub repositoryをご覧ください。
def create_facts_scorer():
"""
Custom MLflow metric that checks if key facts appear in LLM responses.
Perfect for evaluating technical accuracy in domain-specific answers.
"""
def facts_eval_fn(predictions: pd.Series, metrics: Dict[str, Any], facts: pd.Series) -> MetricValue:
"""
Evaluate if key facts/terms are present in predictions.
Args:
predictions: LLM responses to evaluate
metrics: Other computed metrics (from MLflow)
facts: Lists of expected facts for each response
Returns:
MetricValue with individual scores and aggregates
"""
scores = []
for prediction, facts_list in zip(predictions, facts):
# Check how many facts appear in the response
matched = sum(1 for fact in facts_list
if fact.lower() in str(prediction).lower())
# Score as percentage of facts found (0-5 scale)
score = (matched / len(facts_list)) * 5.0
scores.append(score)
# Return MetricValue with scores and aggregates
return MetricValue(
scores=scores,
aggregate_results={
'mean': sum(scores) / len(scores),
'min': min(scores),
'max': max(scores)
}
)
# Register as MLflow metric
return mlflow.metrics.make_metric(
eval_fn=facts_eval_fn,
greater_is_better=True,
name="facts_presence",
version="v1"
)

これで堅牢なテストを導入したので、ツールの可観測性を考える時間です。こでは、あなたのツールが真の生産性倍増器であるのかどうかを判断し始めることになります。
ステップ5 - ROIを示す計測指標をセットアップしましょう
あなたのアプリを完成させると、ビジネスインパクトを毎日計測することが重要になります。Databricksでは、Unity Catalogではあなたのデータアプリケーションの完全なライフサイクルを捕捉するシステムテーブル、特にVector Searchの監査テーブルを公開しています。以下では、収益のインパクト、ユーザー、使用量を捕捉しており、ビジネスパフォーマンス測定のスタート地点を提供しています。これは、インパクト監視を容易にするためにAI/BIダッシュボード上にネイティブでインストールされています。タイプごとの使用量を計測するために以下に示しているAI/BIダッシュボードを作成するために使用したクエリーの一例を以下に示しています。このクエリーは人間のユーザーとサービスアカウントを区別し、自動化処理の使用量とインタラクティブな使用量に対する明確な全体像を提供します。
SELECT
CASE
WHEN user_identity['email'] LIKE '%@%.iam.gserviceaccount.com'
OR user_identity['email'] LIKE 'app-%'
OR user_identity['email'] NOT LIKE '%@%'
THEN 'Application/Service' ELSE 'Individual User'
END as user_type,
user_identity['email'] as user_email,
COUNT(*) as query_count,
COUNT(DISTINCT request_params['name']) as unique_indexes,
COUNT(DISTINCT DATE(event_date)) as active_days,
MAX(event_time) as last_query
FROM system.access.audit
WHERE service_name = 'vectorSearch'
AND action_name IN ('queryVectorIndex', 'queryVectorIndexFastPath')
AND request_params['name'] LIKE '%main.field_ai%'
AND event_date >= current_date() - 90
GROUP BY user_type, user_email
ORDER BY query_count DESC
LIMIT 30

これで、ハルシネーションを削減するクリーンで適切にタグづけされたコンテンツを構成するプロプライエタリなデータ、重複を防ぐ再利用可能なツール、信頼性を確実なものとする品質テストを手に入れたことになります。これで、エージェントを構築するのに適切な時期になりました。現実的には、特にインテグレーションテストのためのアクセラレータが必要となるでしょう。しかし、ツールが製品であるということを認識しましょう。
まとめ
ポートフォリオマネージャのように考えましょうという提案からスタートしました。成功している投資家から盗むべき他の優れた教訓は、複合的な勝利はクイックな勝利を上回るということです。2分間のエージェントは1/4の達成率です。再利用可能なツールは複合的な資産となります。
現時点では、おそらく皆様の企業では認識せずに重複したデータパイプラインを作成しているかもしれません。AIの参入障壁の低さは、数百のチームが独立してエージェントを立ち上げるることを意味し、実際にそうしています。それぞれのエージェントは同じデータソースを再構築し、同じ品質問題を解決し、自身の信頼性に関する問題を引き起こします。数学は厳しいものです: それぞれが3つのデータソースを必要とする100のエージェントは300の重複したシステムを意味します。しかし、これらの3つのソースを一つにまとめることで、297のコピーを排除しつつも100のエージェントを現実のものにします。
上のステップは、あなたのデータとツールに対するエンジニアリングファーストのマイドセットを適用する助けとなります。高品質なデータ、検証、計測によって、ユーザーはリバレッジを手に入れ、インフラの再構築ではなく問題の解決に時間を費やすことができます。ベストな部分は、上で説明したUnity Catalog、MCP、MLflowのインタフェースを活用した際に、これらの計測値の全てが捕捉されるということです。スタート地点として、これらのAI品質計測を実装するために、こちらのGitHubリポジトリを活用してください。