ハマったのでメモ。
外部ロケーションとはUnity Catalogでクラウドストレージにアクセスする際に使用するオブジェクトです。ストレージ資格情報と組み合わせて使用します。作成方法はこちら。
Databricksワークスペースとアクセス先のS3が同じAWSアカウントであれば上の手順でOKなのですが、クロスアカウントの際は?となった次第です。
結論は、
- S3があるAWSアカウントでS3にアクセスするためのIAMロールの信頼ポリシーにUnity Catalogの信頼関係を追加。
- 上記S3にアクセスするためのIAMロールのARNをコピー。
- Databricksワークスペースで上記ARNを用いてストレージ資格情報を作成。
- 上記ストレージ資格情報を用いて外部ロケーションを作成。
という流れでした。すなわち、DatabricksがデプロイされているAWSアカウントではAWSの設定変更は不要ということです。
S3があるAWSアカウントでの作業
-
S3にアクセスするためのIAMロールがない場合には作成します。
-
このIAMロールの信頼ポリシーに以下の内容を追加します。ここでは、
<bucket-owner-acct-id>はS3のあるAWSアカウントのアカウントID、bucket-owner-acct-s3-access-roleはS3にアクセスするためのIAMロール、<DatabricksアカウントID>は、Unity Catalogが稼働しているDatabricksのアカウントIDです。JSON{ "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL", "arn:aws:iam::<bucket-owner-acct-id>:role/bucket-owner-acct-s3-access-role" ] }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "<DatabricksアカウントID>" } } } -
上記IAMロールのS3へのアクセス権を適宜設定します。
-
bucket-owner-acct-s3-access-roleのARNをコピーしておきます。
Databricksでの作業
ストレージ資格情報の作成
- メタストア管理者あるいはアカウント管理者でDatabricksにログインします。
- サイドメニューのデータを選択します。

-
ストレージ資格情報をクリックします。

-
資格情報を作成ボタンをクリックします。
- わかりやすい名称をつけます。
- IAMロールには上のステップでコピーしたARNを貼り付けます。
- コメントを入力します。
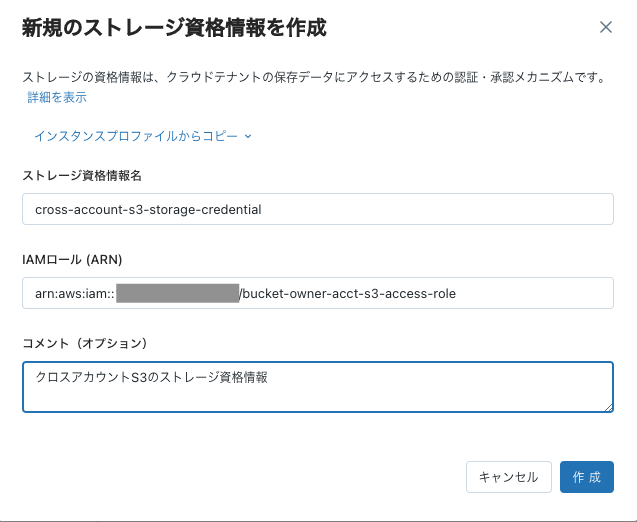
- 作成をクリックします。
外部ロケーションの作成
-
外部ロケーションをクリックします。
-
ロケーションを作成ボタンをクリックします。
- わかりやすい名称をつけます。
- URLにはアクセス先のS3のURLを入力します。
- ストレージ資格情報では、上で作成したストレージ資格情報を選択します。
- コメントを入力します。
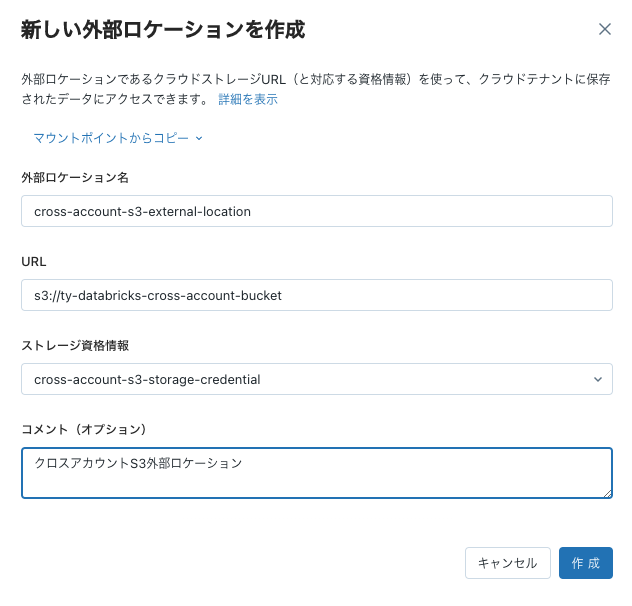
- 作成をクリックします。
これでクロスアカウントの外部ロケーションが作成できました。
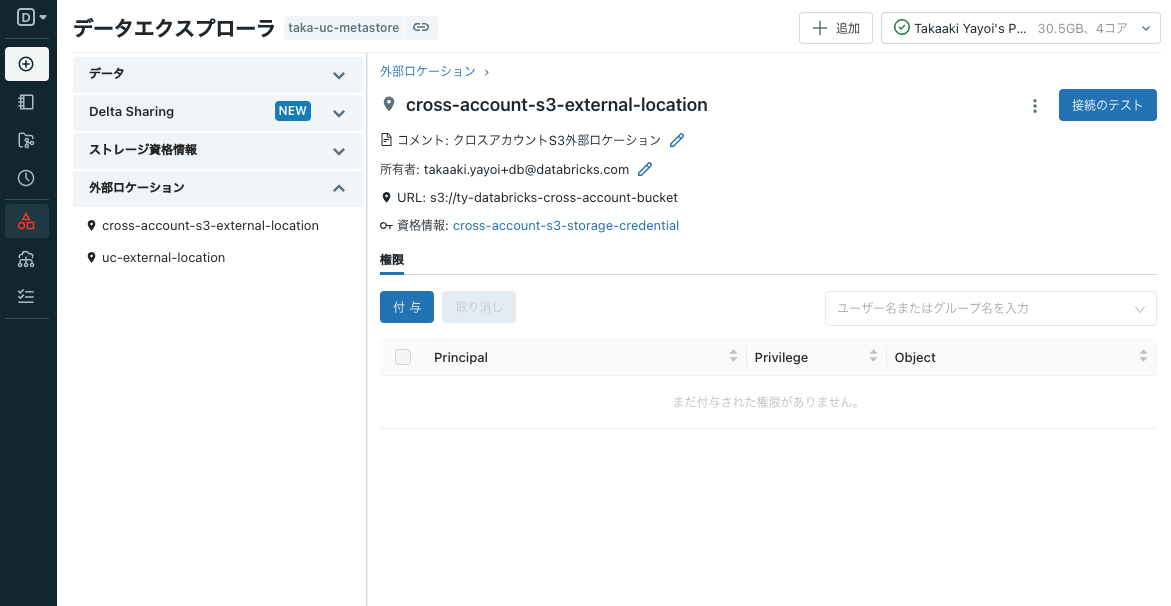
注意
外部ロケーションを作成する際には接続チェックが行われます。エラーになる場合にはIAMの設定を確認してください。
接続確認
-
Unity Catalogにアクセスするためのクラスターを作成します。パーソナルコンピュートがお手軽でおすすめです。
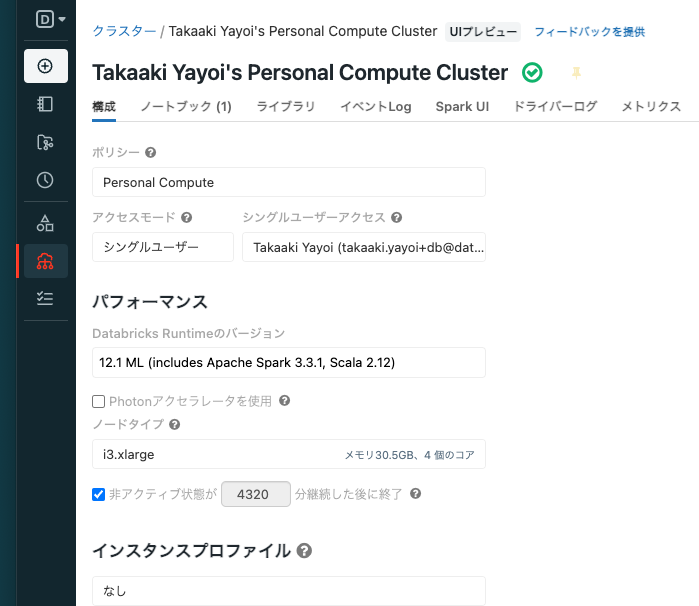
-
SQLノートブックを作成してクラスターにアタッチします。
-
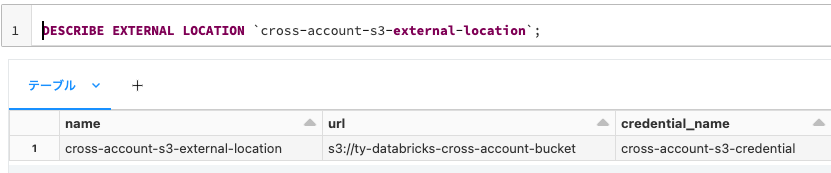
外部ロケーションの詳細を確認します。
SQLDESCRIBE EXTERNAL LOCATION `cross-account-s3-external-location`; -
メタデータを確認することができます。
-
外部ロケーションの中身を確認します。
SQLLIST 's3://ty-databricks-cross-account-bucket';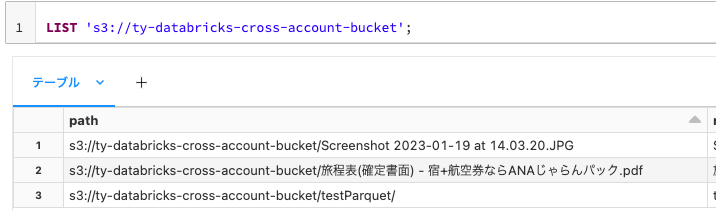
クロスアカウントの設定をするよりもお手軽です。
さらにこれを活用してテーブルを作成していきます。
外部テーブルの作成
データ読み込み元として上で作成した外部ロケーションを利用できることに加え、外部ロケーションにテーブルを作成することができます。
なお、以前はDBFSマウントを使用していた方もいらっしゃると思いますが、現状の外部ロケーションではマウントポイントではなく、直パスを指定する形になります。
元データの準備
ここでは、デモの目的もありサンプルデータを外部ロケーションに作成します。直パスs3://ty-databricks-cross-account-bucket/testParquetを指定して、Parquetを保存します。
%scala
case class MyCaseClass(key: String, group: String, value: Int, someints: Seq[Int], somemap: Map[String, Int])
val dataframe = sc.parallelize(Array(MyCaseClass("a", "vowels", 1, Array(1), Map("a" -> 1)),
MyCaseClass("b", "consonants", 2, Array(2, 2), Map("b" -> 2)),
MyCaseClass("c", "consonants", 3, Array(3, 3, 3), Map("c" -> 3)),
MyCaseClass("d", "consonants", 4, Array(4, 4, 4, 4), Map("d" -> 4)),
MyCaseClass("e", "vowels", 5, Array(5, 5, 5, 5, 5), Map("e" -> 5)))
).toDF()
// now write it to disk
dataframe.write.mode("overwrite").parquet("s3://ty-databricks-cross-account-bucket/testParquet")
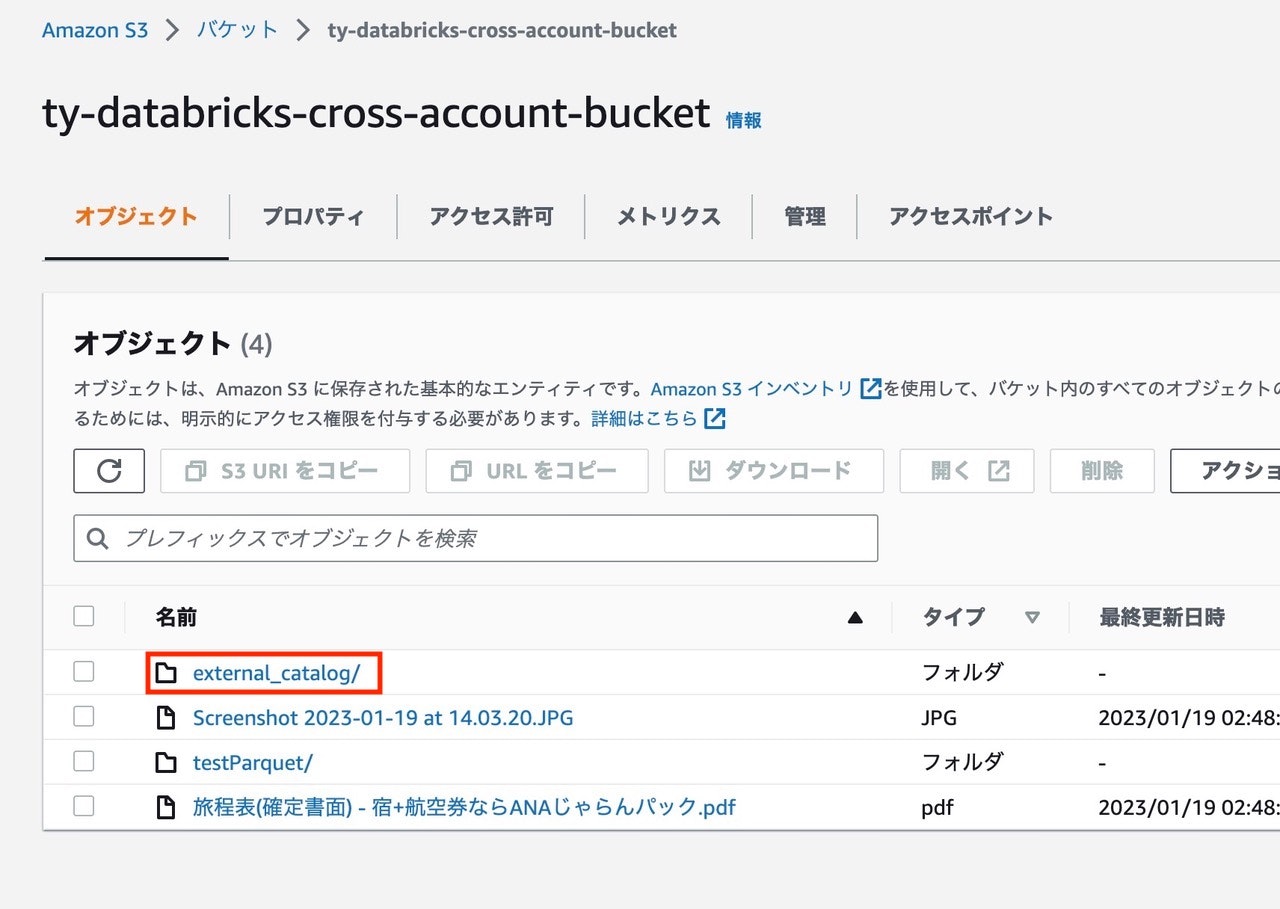
クロスアカウントのS3でディレクトリが作成されていることを確認できます。
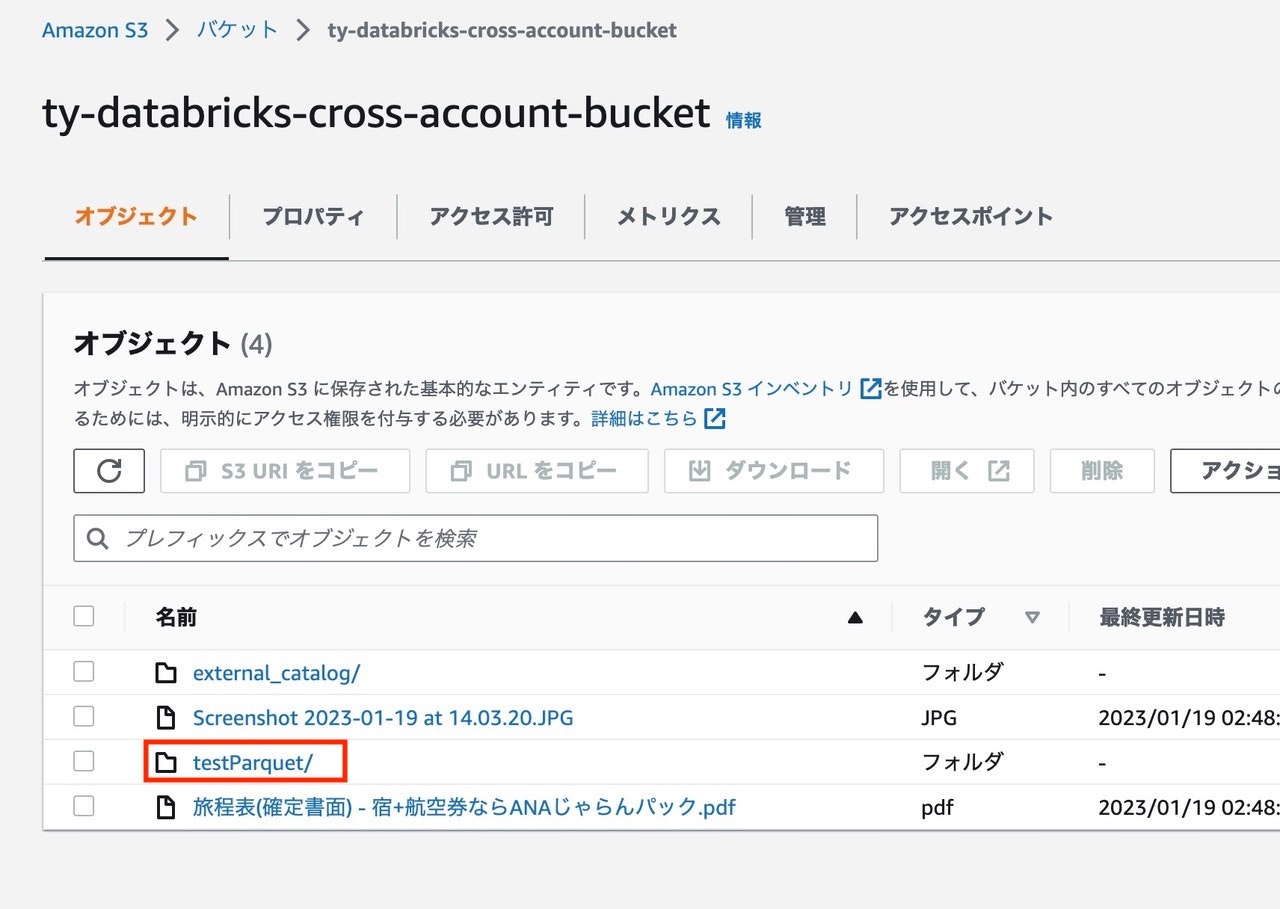
外部ロケーションに格納されているファイルに直接クエリーを行うことも可能です。
SELECT * FROM parquet.`s3://ty-databricks-cross-account-bucket/testParquet`
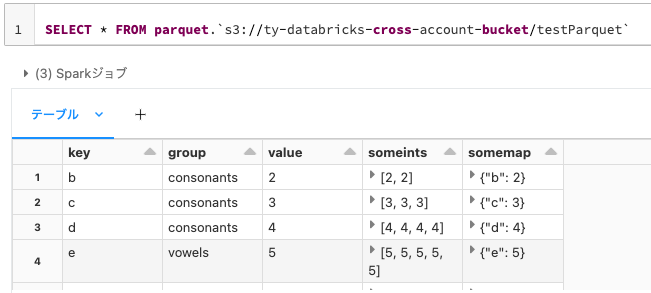
Python(PySpark)でも同じことができます。
%python
display(spark.read.format("parquet").load("s3://ty-databricks-cross-account-bucket/testParquet"))
SQLがメインのワークロードの場合、毎回直パスを指定するのは面倒ですし、可読性も低下します。DWHと同じようにデータベース、テーブルのパラダイムでデータを活用できるように、Unity Catalogにテーブルに登録します。DBMS同様、CREATE TABLE、行のインサートという流れになります。
なお、Unity Catalogにおいては3レベルの名前空間を使用します。カタログ.スキーマ(データベース).テーブルという形式でテーブルにアクセスします。
カタログの作成
- サイドメニューのデータをクリックして、データエクスプローラに移動します。

-
カタログを作成をクリックしてカタログの情報を入力します。
- カタログ名は
external_catalogとします。 -
マネージドロケーションには、カタログに格納されるテーブルデータを格納するロケーションを指定します。ここでは、上のステップで作成した外部ロケーションのパスを指定します。

- カタログ名は
-
作成をクリックするとカタログが外部ロケーションに作成されます。

カタログを作成すると、その配下にデフォルトスキーマ(データベース)defaultが作成されるので、以降ではこちらを使用します。なお、別途スキーマを作成することも可能です。
テーブルの作成
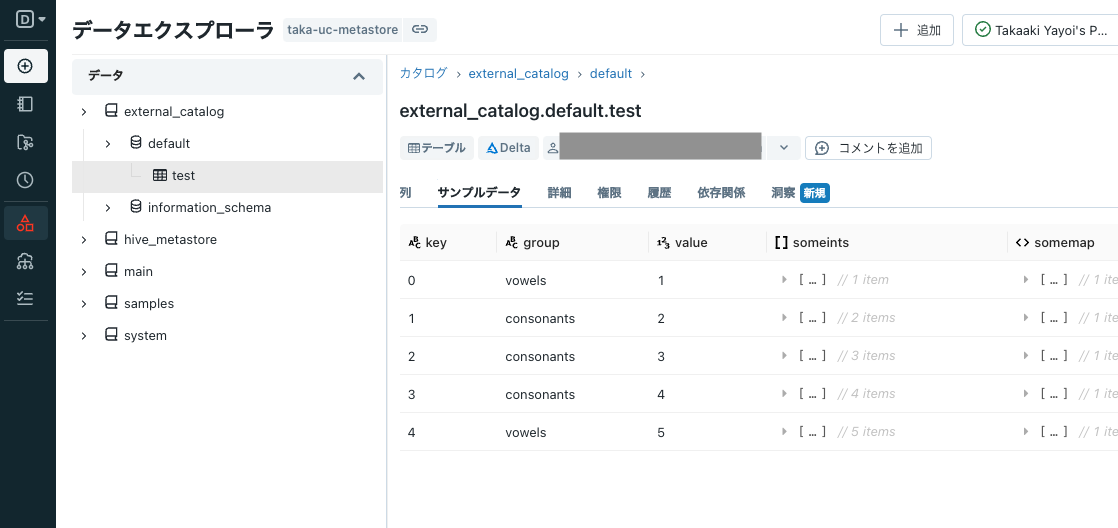
ノートブックに戻って、以下のコマンドを実行します。testという空のテーブルがexternal_data.defaultに作成されます。
CREATE TABLE external_catalog.default.test;
以下のCOPY INTOコマンドを実行することで、s3://ty-databricks-cross-account-bucket/testParquetをテーブルexternal_catalog.default.testに読み込みます。
COPY INTO external_catalog.default.test
FROM (
SELECT *
FROM 's3://ty-databricks-cross-account-bucket/testParquet'
)
FILEFORMAT = parquet COPY_OPTIONS ("mergeSchema" = "true");
クロスアカウントのS3バケットを確認すると、ディレクトリが作成されていることを確認することができます。
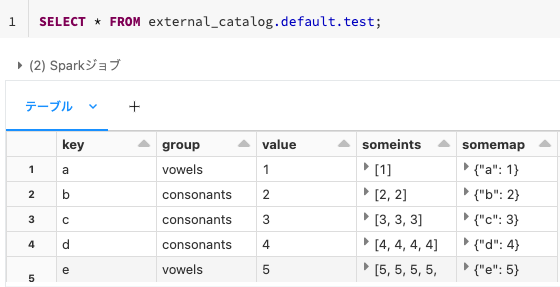
これで、external_catalog.default.testでテーブルにアクセスできるようになります。
SELECT * FROM external_catalog.default.test;
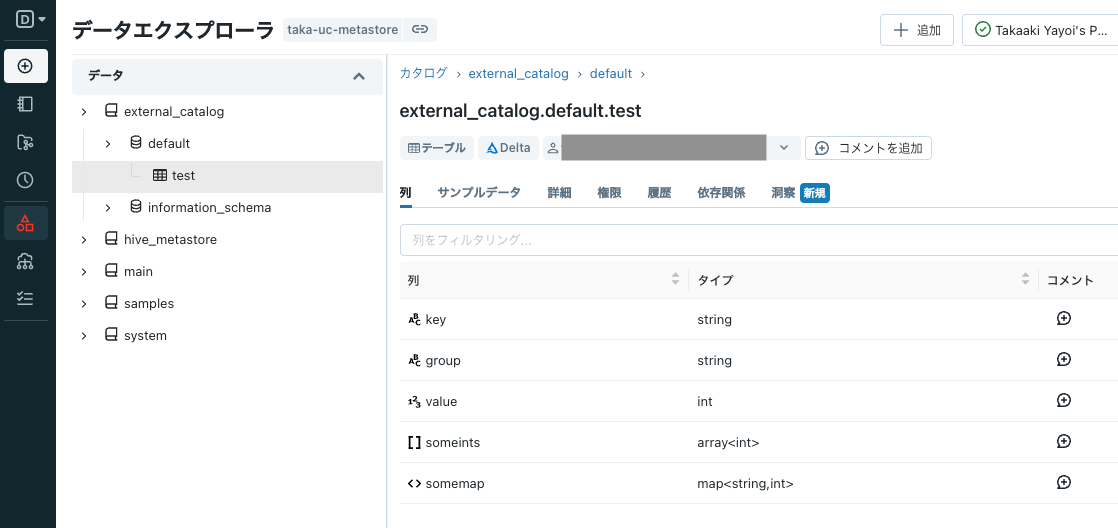
データエクスプローラでも確認できます。
権限の設定
この状態では作成したテーブルに他のユーザーがアクセスできません。
- カタログを選択し、権限を開き、付与をクリックします。

- ここではすべてのユーザーに読み取り権限を与えるものとします。ユーザーとグループではaccount usersを選択し、権限プリセットではデータリーダーを選択します。

-
付与をクリックすることで権限が付与されます。
