こちらのサンプルノートブックをウォークスルーします。
クラスターは以下の指示に従ってシングルノードのGPUクラスターです。
Hugging Face Transformersを使用したテキスト分類モデルのチューニング
このノートブックは、基本モデルとして「distillibert-base-uncased」を使用して、単一GPUマシン上でSMSスパム分類器をトレーニングします。これは、🤗 Transformersライブラリを使用しています。
まず、小さなデータセットをダウンロードし、それをDBFSにコピーし、次にSpark DataFrameに変換します。Spark上でトークン化までの前処理が行われます。DBFSはドライバー上のローカルファイルとしてデータセットに直接アクセスするための便利な方法として使用されますが、DBFSの使用を避けるように変更することもできます。
SMSメッセージのテキストトークン化は、基本モデルとのトークン化の一貫性を持たせるために、transformersのモデルのデフォルトトークナイザーで行われます。このノートブックは、transformersライブラリのTrainerユーティリティを使用してモデルをファインチューニングします。このノートブックは、トークナイザーと訓練されたモデルをTransformersのpipelineにラップし、そのパイプラインをMLflowモデルとしてログします。
これにより、パイプラインをSpark DataFrameの文字列列に直接適用するUDFとして簡単に使用できます。
クラスターのセットアップ
このノートブックには、AWSのg4dn.xlargeやAzureのStandard_NC4as_T4_v3など、単一GPUクラスターが推奨されます。個人のコンピューティングポリシーを使用して、またはクラスターを作成する際に「シングルノード」を選択して、単一マシンクラスターを作成できます。このノートブックは、Databricks Runtime ML GPUバージョン11.1以降で動作します。Databricks Runtime ML GPUバージョン9.1から10.4は、次のコマンドを%pip install --upgrade transformers datasets evaluateに置き換えることで使用できます。
transformersライブラリは、Databricks Runtime MLにデフォルトでインストールされています。このノートブックでは、🤗 Datasetsと🤗 Evaluateも必要ですが、%pipを使用してインストールできます。
%pip install datasets evaluate
ノートブックのパラメータを設定します。
- 基本モデルとしてのDistilBERT base model (uncased)は、BERT base model (uncased)よりも小さく、速いですが、似たような振る舞いを提供します。このノートブックでは、この基本モデルをファインチューニングします。
-
tutorial_pathは、ノートブックがサンプルデータセットを書き込むためにDBFSで使用するパスを設定します。このノートブックの最後のコマンドによって削除されます。
base_model = "distilbert-base-uncased"
tutorial_path = "/FileStore/sms_tutorial_taka"
データのダウンロードと読み込み
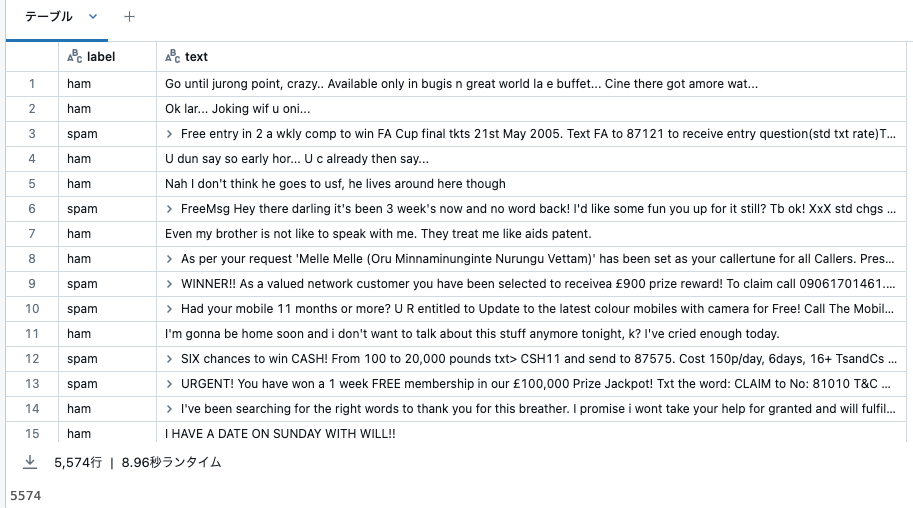
データセットをダウンロードしてSpark DataFrameに読み込みます。
SMS Spam Collection Datasetは、
UCI Machine Learning Repositoryから入手できます。
%sh wget -P /databricks/driver https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
ダウンロードしたアーカイブを解凍します。
%sh unzip /databricks/driver/smsspamcollection.zip -d /databricks/driver/sms
Archive: /databricks/driver/smsspamcollection.zip
inflating: /databricks/driver/sms/SMSSpamCollection
inflating: /databricks/driver/sms/readme
DBFSにファイルをコピーします。
dbutils.fs.mkdirs(f"dbfs:{tutorial_path}")
dbutils.fs.cp("file:/databricks/driver/sms/SMSSpamCollection", f"dbfs:{tutorial_path}/SMSSpamCollection.tsv")
データセットをDataFrameにロードします。ファイルはタブ区切りで、ヘッダーは含まれていないため、sepを使用してセパレーターを指定し、列名を明示的に指定します。
sms = spark.read.csv(f"{tutorial_path}/SMSSpamCollection.tsv", header=False, inferSchema=True, sep="\t").toDF("label", "text")
display(sms)
sms.count()
データの準備
transformersのトレーナーに渡されるテキスト分類のデータセットは、整数のラベル[0, 1]を持つ必要があります。
ラベルを収集し、ラベルからIDへのマッピングとその逆のマッピングを生成します。transformersモデルは、これらのマッピングを使用して整数値を人間が読めるラベルに正しく変換します。
labels = sms.select(sms.label).groupBy(sms.label).count().collect()
id2label = {index: row.label for (index, row) in enumerate(labels)}
label2id = {row.label: index for (index, row) in enumerate(labels)}
データフレームの文字列ラベルをIDで置換します。
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf('integer')
def replace_labels_with_ids(labels: pd.Series) -> pd.Series:
return labels.apply(lambda x: label2id[x])
sms_id_labels = sms.select(replace_labels_with_ids(sms.label).alias('label'), sms.text)
display(sms_id_labels)
spamが1、hamが0に変換されています。

Hugging Faceのdatasetsは、datasets.Dataset.from_sparkを使用してSpark DataFramesからの読み込みをサポートしています。from_spark()メソッドについては、Hugging Faceのドキュメントを参照してください。
Dataset.from_sparkはデータセットをキャッシュします。この例では、モデルはドライバ上でトレーニングされ、キャッシュされたデータはSparkを使用して並列化されるため、cache_dirはドライバとすべてのワーカーからアクセス可能である必要があります。Databricks File System (DBFS)のルート(AWS| Azure |GCP)またはマウントポイント(AWS | Azure | GCP)を使用できます。
DBFSを使用することで、モデルトレーニングに使用されるtransformers互換のデータセットを作成する際に、"local"パスを参照することができます。
(train_df, test_df) = sms_id_labels.persist().randomSplit([0.8, 0.2])
import datasets
train_dataset = datasets.Dataset.from_spark(train_df, cache_dir="/dbfs/cache/train")
test_dataset = datasets.Dataset.from_spark(test_df, cache_dir="/dbfs/cache/test")
トークン化してデータセットをシャッフルします。Trainerはトークン化されていないtext列をトレーニングに必要としないため、ノートブックはデータセットからそれらを削除します。これは必須ではありませんが、列を削除しないとトレーニング中に警告が表示されます。
このステップでは、datasetsは変換されたデータセットをローカルディスクにキャッシュし、モデルトレーニング中の高速な後続の読み込みを可能にします。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
def tokenize_function(examples):
return tokenizer(examples["text"], padding=False, truncation=True)
train_tokenized = train_dataset.map(tokenize_function, batched=True).remove_columns(["text"])
test_tokenized = test_dataset.map(tokenize_function, batched=True).remove_columns(["text"])
train_dataset = train_tokenized.shuffle(seed=42)
test_dataset = test_tokenized.shuffle(seed=42)
モデルのトレーニング
モデルのトレーニングでは、このノートブックでは主にデフォルトの動作を使用しています。ただし、Trainerで使用可能なメトリクスやパラメータの全範囲を使用して、モデルのトレーニング動作を調整することができます。
評価メトリックを作成してログに記録します。損失はログに記録されますが、精度などの他のメトリックを追加することで、モデルのパフォーマンスをより理解しやすくすることができます。
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
デフォルトのトレーニング引数を構築します。ここでは、学習率などの多くのトレーニングパラメータを設定します。
設定できる引数の全範囲については、transformersのドキュメントを参照してください。
from transformers import TrainingArguments, Trainer
training_output_dir = "/databricks/driver/sms_trainer"
training_args = TrainingArguments(output_dir=training_output_dir, evaluation_strategy="epoch")
ベースモデルからトレーニング用のモデルを作成し、ラベルのマッピングとクラスの数を指定します。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(base_model, num_labels=2, label2id=label2id, id2label=id2label)
データコレータを使用して、トレーニングと評価のデータセットで入力をバッチ処理します。デフォルト設定でのDataCollatorWithPaddingの使用は、テキスト分類のための良いベースライン性能を提供します。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer)
上記で作成したモデル、引数、データセット、コレータ、メトリクスを使用してトレーナーオブジェクトを構築します。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics,
data_collator=data_collator,
)
MLflowラッパークラスを構築して、モデルをパイプラインとして保存します。このモデルは、CUDAが利用可能な場合にGPUを使用してパイプラインをロードします。このモデルは、transformersパイプラインで使用するバッチサイズを固定しています。推論に使用するハードウェアを念頭に置いて、これを設定する必要があります。
import mlflow
from tqdm.auto import tqdm
import torch
pipeline_artifact_name = "pipeline"
class TextClassificationPipelineModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
device = 0 if torch.cuda.is_available() else -1
self.pipeline = pipeline("text-classification", context.artifacts[pipeline_artifact_name], device=device)
def predict(self, context, model_input):
texts = model_input[model_input.columns[0]].to_list()
pipe = tqdm(self.pipeline(texts, truncation=True, batch_size=8), total=len(texts), miniters=10)
labels = [prediction['label'] for prediction in pipe]
return pd.Series(labels)
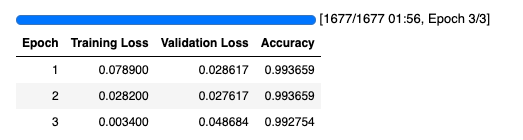
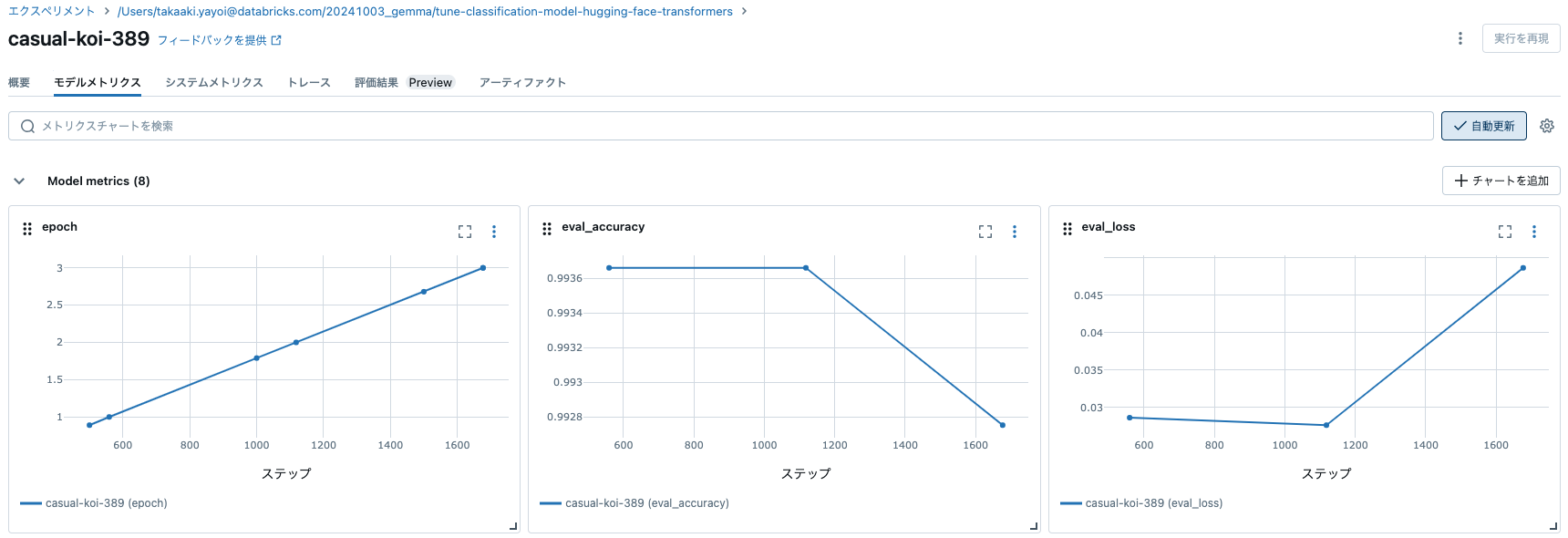
モデルをトレーニングし、メトリクスと結果をMLflowに記録します。BERTベースのモデルでは、このタスクは非常に簡単です。評価の正確性が1または1に近い場合に驚かないでください。
from transformers import pipeline
model_output_dir = "/databricks/driver/sms_model"
pipeline_output_dir = "/databricks/driver/sms_pipeline"
model_artifact_path = "sms_spam_model"
with mlflow.start_run() as run:
trainer.train()
trainer.save_model(model_output_dir)
pipe = pipeline("text-classification", model=AutoModelForSequenceClassification.from_pretrained(model_output_dir), batch_size=8, tokenizer=tokenizer)
pipe.save_pretrained(pipeline_output_dir)
mlflow.transformers.log_model(transformers_model=pipe,
artifact_path=model_artifact_path,
input_example="Hi there!",
)
トレーニングが完了すると、モデルがMLflowエクスペリメントに記録され、各種メトリクスを確認することができます。

バッチ推論
MLflowを使用してモデルをUDFとしてロードし、バッチスコアリングに使用します。
logged_model = "runs:/{run_id}/{model_artifact_path}".format(run_id=run.info.run_id, model_artifact_path=model_artifact_path)
# モデルをSpark UDFとしてロードします。モデルがdouble値を返さない場合は、result_typeをオーバーライドします。
sms_spam_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='string')
test = test_df.select(test_df.text, test_df.label, sms_spam_model_udf(test_df.text).alias("prediction"))
display(test)
テストデータに対するバッチ推論が実行されます。
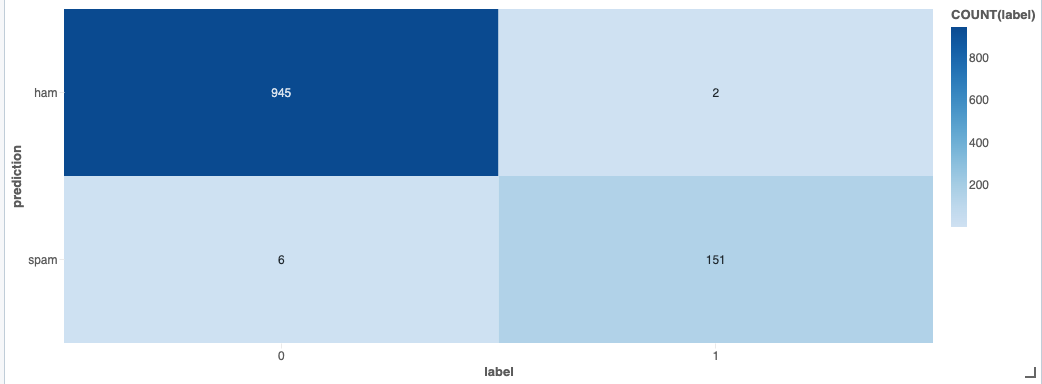
ヒートマップで簡易に混同行列(Confusion Matrix)を作成してみます。高い精度で分類できていることがわかります。
クリーンアップ
DBFSに配置されたファイルを削除します。
dbutils.fs.rm(f"dbfs:{tutorial_path}", recurse=True)