Databricks Vector Searchで、新しいFULL_TEXTクエリタイプを使用して、既存のVector Searchインデックスをクエリできるようになりました!
説明はこちらにあります。
ベータ版
全文検索はベータ機能として利用できます。全文検索を実行するには、パラメーターquery_typeをFULL_TEXTに設定します。 全文検索では、ベクター埋め込みを使用せずに、キーワードの一致に基づいて最大 200 件の結果を取得できます。
有効化
プレビューでVector Search Full Textをオンにします。

ウォークスルー
こちらのサンプルを変更して動作確認していきます。
%pip install --upgrade --force-reinstall databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient()
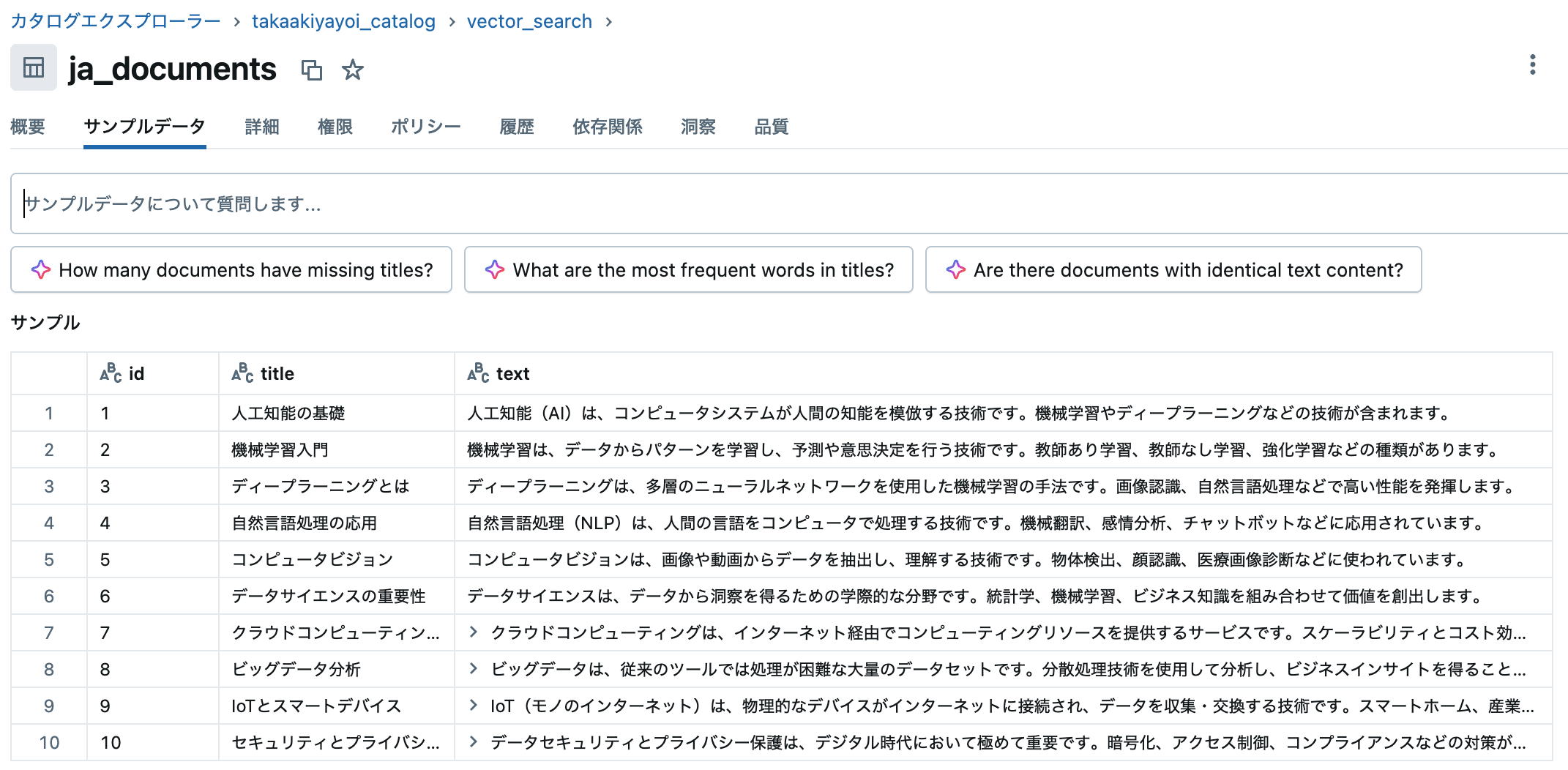
ダミーの日本語文書データを作成してソースDeltaテーブルに保存
以下では、ソースDeltaテーブルを作成します。
# 使用するカタログとスキーマを指定します。カタログに対するUSE_CATALOG権限、
# スキーマに対するUSE_SCHEMAおよびCREATE_TABLE権限が必要です。
# 必要に応じて、カタログとスキーマを変更してください。
catalog_name = "takaakiyayoi_catalog"
schema_name = "vector_search"
source_table_name = "ja_documents"
source_table_fullname = f"{catalog_name}.{schema_name}.{source_table_name}"
# ダミーの日本語文書データを作成
from pyspark.sql import Row
ja_documents = [
Row(id="1", title="人工知能の基礎", text="人工知能(AI)は、コンピュータシステムが人間の知能を模倣する技術です。機械学習やディープラーニングなどの技術が含まれます。"),
Row(id="2", title="機械学習入門", text="機械学習は、データからパターンを学習し、予測や意思決定を行う技術です。教師あり学習、教師なし学習、強化学習などの種類があります。"),
Row(id="3", title="ディープラーニングとは", text="ディープラーニングは、多層のニューラルネットワークを使用した機械学習の手法です。画像認識、自然言語処理などで高い性能を発揮します。"),
Row(id="4", title="自然言語処理の応用", text="自然言語処理(NLP)は、人間の言語をコンピュータで処理する技術です。機械翻訳、感情分析、チャットボットなどに応用されています。"),
Row(id="5", title="コンピュータビジョン", text="コンピュータビジョンは、画像や動画からデータを抽出し、理解する技術です。物体検出、顔認識、医療画像診断などに使われています。"),
Row(id="6", title="データサイエンスの重要性", text="データサイエンスは、データから洞察を得るための学際的な分野です。統計学、機械学習、ビジネス知識を組み合わせて価値を創出します。"),
Row(id="7", title="クラウドコンピューティング", text="クラウドコンピューティングは、インターネット経由でコンピューティングリソースを提供するサービスです。スケーラビリティとコスト効率に優れています。"),
Row(id="8", title="ビッグデータ分析", text="ビッグデータは、従来のツールでは処理が困難な大量のデータセットです。分散処理技術を使用して分析し、ビジネスインサイトを得ることができます。"),
Row(id="9", title="IoTとスマートデバイス", text="IoT(モノのインターネット)は、物理的なデバイスがインターネットに接続され、データを収集・交換する技術です。スマートホーム、産業自動化などに応用されています。"),
Row(id="10", title="セキュリティとプライバシー", text="データセキュリティとプライバシー保護は、デジタル時代において極めて重要です。暗号化、アクセス制御、コンプライアンスなどの対策が必要です。")
]
source_df = spark.createDataFrame(ja_documents)
display(source_df)
source_df.write.format("delta").option("delta.enableChangeDataFeed", "true").saveAsTable(source_table_fullname)
display(spark.sql(f"SELECT * FROM {source_table_fullname}"))
Vector Searchエンドポイントの作成
vector_search_endpoint_name = "dbdemos_vs_endpoint"
vsc.create_endpoint(
name=vector_search_endpoint_name,
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
endpoint = vsc.get_endpoint(
name=vector_search_endpoint_name)
endpoint
endpoint = vsc.get_endpoint(
name=vector_search_endpoint_name)
endpoint
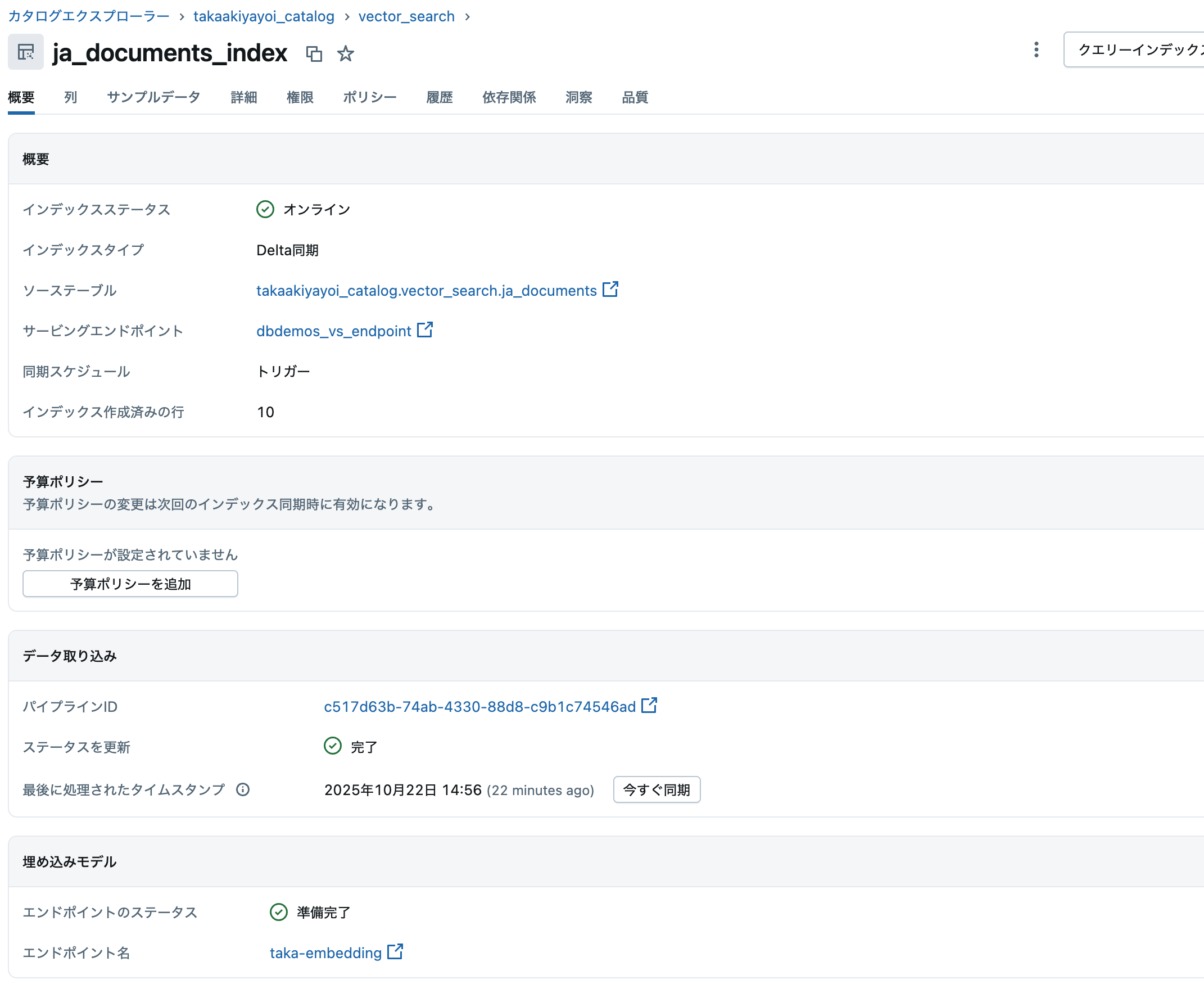
Vector Indexの作成
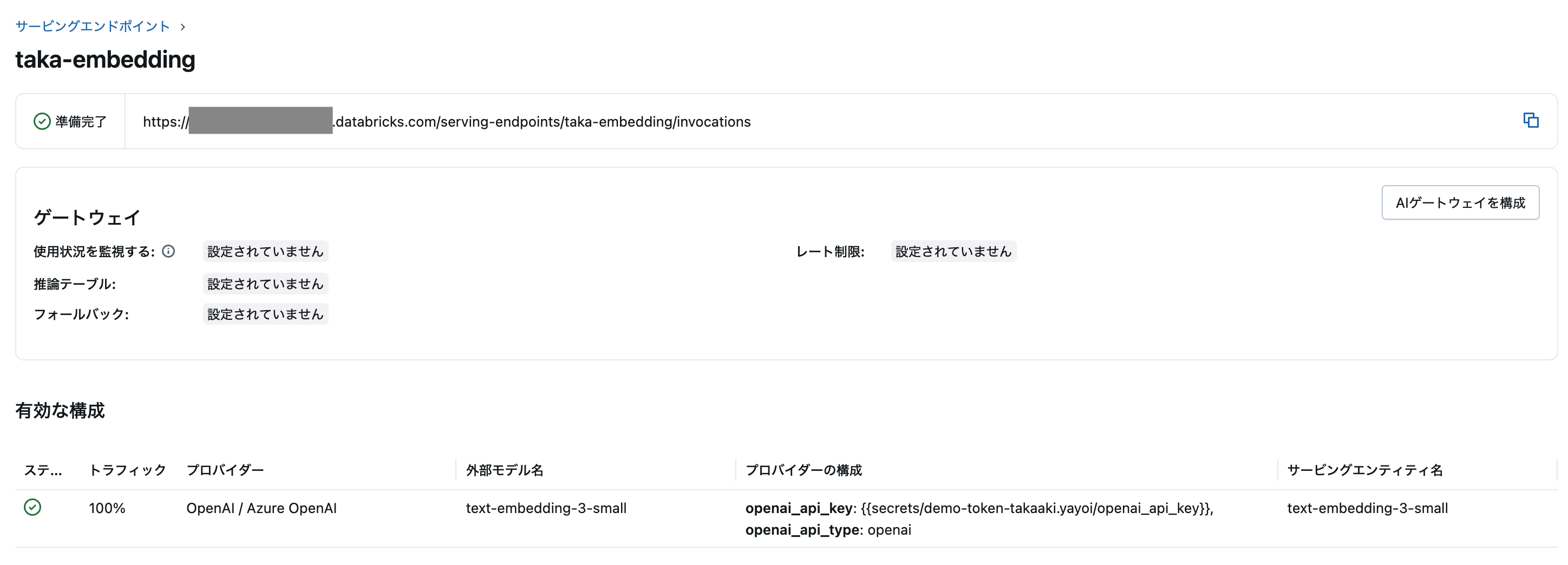
事前に日本語対応のエンべディングモデルのサービングエンドポイントを作成しておきます。
# Vector index
vs_index = "ja_documents_index"
vs_index_fullname = f"{catalog_name}.{schema_name}.{vs_index}"
embedding_model_endpoint = "taka-embedding"
index = vsc.create_delta_sync_index(
endpoint_name=vector_search_endpoint_name,
source_table_name=source_table_fullname,
index_name=vs_index_fullname,
pipeline_type='TRIGGERED',
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name=embedding_model_endpoint
)
index.describe()
少し待つとインデックスが出来上がります。
全文検索(ベータ機能)
全文検索はベータ機能として利用できます。query_typeをFULL_TEXTに設定することで、ベクター埋め込みを使用せずに、キーワードの一致に基づいて最大200件の結果を取得できます。
# 全文検索を実行 - query_typeをFULL_TEXTに設定
full_text_results = index.similarity_search(
query_text="機械学習",
columns=all_columns,
query_type="FULL_TEXT",
num_results=5)
full_text_results
日本語でも動いていますね。
[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True.
{'manifest': {'column_count': 4,
'columns': [{'name': 'id'},
{'name': 'title'},
{'name': 'text'},
{'name': 'score'}]},
'result': {'row_count': 5,
'data_array': [['2',
'機械学習入門',
'機械学習は、データからパターンを学習し、予測や意思決定を行う技術です。教師あり学習、教師なし学習、強化学習などの種類があります。',
3.04528],
['6',
'データサイエンスの重要性',
'データサイエンスは、データから洞察を得るための学際的な分野です。統計学、機械学習、ビジネス知識を組み合わせて価値を創出します。',
1.6300061],
['1',
'人工知能の基礎',
'人工知能(AI)は、コンピュータシステムが人間の知能を模倣する技術です。機械学習やディープラーニングなどの技術が含まれます。',
1.4929942],
['3',
'ディープラーニングとは',
'ディープラーニングは、多層のニューラルネットワークを使用した機械学習の手法です。画像認識、自然言語処理などで高い性能を発揮します。',
1.4496725],
['4',
'自然言語処理の応用',
'自然言語処理(NLP)は、人間の言語をコンピュータで処理する技術です。機械翻訳、感情分析、チャットボットなどに応用されています。',
0.6211651]]},
'debug_info': {'response_time': 38.0, 'ann_time': 29.0}}
フィルタと併用します。
# 全文検索でフィルタを使用
full_text_results = index.similarity_search(
query_text="データ",
columns=all_columns,
query_type="FULL_TEXT",
filters={"id NOT": ("1", "2")},
num_results=5)
full_text_results
フィルタも効いています。
[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True.
{'manifest': {'column_count': 4,
'columns': [{'name': 'id'},
{'name': 'title'},
{'name': 'text'},
{'name': 'score'}]},
'result': {'row_count': 3,
'data_array': [['5',
'コンピュータビジョン',
'コンピュータビジョンは、画像や動画からデータを抽出し、理解する技術です。物体検出、顔認識、医療画像診断などに使われています。',
0.40049824],
['6',
'データサイエンスの重要性',
'データサイエンスは、データから洞察を得るための学際的な分野です。統計学、機械学習、ビジネス知識を組み合わせて価値を創出します。',
0.3930394],
['9',
'IoTとスマートデバイス',
'IoT(モノのインターネット)は、物理的なデバイスがインターネットに接続され、データを収集・交換する技術です。スマートホーム、産業自動化などに応用されています。',
0.3930394]]},
'debug_info': {'response_time': 20.0, 'ann_time': 11.0}}
複数キーワードはOR検索されます。
# 複数のキーワードで全文検索
full_text_results = index.similarity_search(
query_text="セキュリティ プライバシー",
columns=all_columns,
query_type="FULL_TEXT",
num_results=5)
full_text_results
[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True.
{'manifest': {'column_count': 4,
'columns': [{'name': 'id'},
{'name': 'title'},
{'name': 'text'},
{'name': 'score'}]},
'result': {'row_count': 1,
'data_array': [['10',
'セキュリティとプライバシー',
'データセキュリティとプライバシー保護は、デジタル時代において極めて重要です。暗号化、アクセス制御、コンプライアンスなどの対策が必要です。',
2.0346112]]},
'debug_info': {'response_time': 16.0, 'ann_time': 9.0}}
# 複数のキーワードで全文検索
full_text_results = index.similarity_search(
query_text="データ ビッグ 機械学習",
columns=all_columns,
query_type="FULL_TEXT",
num_results=5)
full_text_results
[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True.
{'manifest': {'column_count': 4,
'columns': [{'name': 'id'},
{'name': 'title'},
{'name': 'text'},
{'name': 'score'}]},
'result': {'row_count': 5,
'data_array': [['2',
'機械学習入門',
'機械学習は、データからパターンを学習し、予測や意思決定を行う技術です。教師あり学習、教師なし学習、強化学習などの種類があります。',
3.04528],
['6',
'データサイエンスの重要性',
'データサイエンスは、データから洞察を得るための学際的な分野です。統計学、機械学習、ビジネス知識を組み合わせて価値を創出します。',
2.0230455],
['1',
'人工知能の基礎',
'人工知能(AI)は、コンピュータシステムが人間の知能を模倣する技術です。機械学習やディープラーニングなどの技術が含まれます。',
1.4929942],
['3',
'ディープラーニングとは',
'ディープラーニングは、多層のニューラルネットワークを使用した機械学習の手法です。画像認識、自然言語処理などで高い性能を発揮します。',
1.4496725],
['4',
'自然言語処理の応用',
'自然言語処理(NLP)は、人間の言語をコンピュータで処理する技術です。機械翻訳、感情分析、チャットボットなどに応用されています。',
0.6211651]]},
'debug_info': {'response_time': 134.0, 'ann_time': 125.0}}
純粋なキーワード検索の精度を求めるお客様や、カスタムハイブリッド検索ソリューションを構築する必要があるお客様に最適です。ご活用ください!