過去にこちらの動画をアップロードしました。音声なしです。
Sparkのデータ処理の仕組みを理解する上では、上でキャンディーの袋として表現されているパーティションを理解することがとても重要です。
ただ、正直なところ私自身も腹落ちできるほど理解できたかというとそうではありませんでした。Spark本を出しておきながら恥ずかしい限りです。
しかし、PySparkを使っているだけですと、Sparkがパーティションをどのように作成して、どのように処理しているのかどうかを体感することが難しいなと長年感じていました。理解するにはサンプルデータを用いるなどして、Spark UIを読み解く必要があるんだろうなと思いつつもなかなか手が出せず…。
そして、いろいろ探している中で非常に勉強になるコンテンツを見つけました。こちらのYoutubeチャネルです。
Githubでもコードを公開されています。
特にこちらのSpark Partitionsのサンプルがまさに自分の追い求めていたものでした。まずは、こちらをDatabricksに対応させつつ、日本語化しながら動かしてみます。
0. セットアップ
このノートブックの一般的なヒント:
- Spark UIはクラスター -> Spark UIでアクセス可能
- Spark UIの詳細な調査は後のエピソードで行います
-
sc.setJobDescription("Description")はSpark UIのアクションのジョブ説明を独自のものに置き換えます -
sdf.rdd.getNumPartitions()は現在のSpark DataFrameのパーティション数を返します -
sdf.write.format("noop").mode("overwrite").save()は、実際の書き込み中に副作用なしで変換を分析および開始するための良い方法です
4コアのクラスターを使用します。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
import pyspark
ダミーデータでSparkデータフレームを作成する関数
def sdf_generator1(num_iter: int = 1) -> "DataFrame":
d = [
{"a":"a", "b": 1},
{"a":"b", "b": 2},
{"a":"c", "b": 3},
{"a":"d", "b": 4},
{"a":"e", "b": 5},
{"a":"e", "b": 6},
{"a":"f", "b": 7},
{"a":"g", "b": 8},
{"a":"h", "b": 9},
{"a":"i", "b": 10},
]
data = []
for i in range(0, num_iter):
data.extend(d)
ddl_schema = "a string, b int"
return spark.createDataFrame(data, schema=ddl_schema)
20行からなるSparkデータフレームを作成します。
sdf_gen1 = sdf_generator1(2)
sdf_gen1.count()
20
sdf_gen1.show()
+---+---+
| a| b|
+---+---+
| a| 1|
| b| 2|
| c| 3|
| d| 4|
| e| 5|
| e| 6|
| f| 7|
| g| 8|
| h| 9|
| i| 10|
| a| 1|
| b| 2|
| c| 3|
| d| 4|
| e| 5|
| e| 6|
| f| 7|
| g| 8|
| h| 9|
| i| 10|
+---+---+
パーティション数を指定してSparkデータフレームを生成する関数
def sdf_generator2(num_rows: int, num_partitions: int = None) -> "DataFrame":
return (
spark.range(num_rows, numPartitions=num_partitions)
.withColumn("date", f.current_date())
.withColumn("timestamp",f.current_timestamp())
.withColumn("idstring", f.col("id").cast("string"))
.withColumn("idfirst", f.col("idstring").substr(0,1))
.withColumn("idlast", f.col("idstring").substr(-1,1))
)
sdf_gen2 = sdf_generator2(20)
sdf_gen2.count()
20
sdf_gen2.show()
+---+----------+--------------------+--------+-------+------+
| id| date| timestamp|idstring|idfirst|idlast|
+---+----------+--------------------+--------+-------+------+
| 0|2024-12-02|2024-12-02 05:02:...| 0| 0| 0|
| 1|2024-12-02|2024-12-02 05:02:...| 1| 1| 1|
| 2|2024-12-02|2024-12-02 05:02:...| 2| 2| 2|
| 3|2024-12-02|2024-12-02 05:02:...| 3| 3| 3|
| 4|2024-12-02|2024-12-02 05:02:...| 4| 4| 4|
| 5|2024-12-02|2024-12-02 05:02:...| 5| 5| 5|
| 6|2024-12-02|2024-12-02 05:02:...| 6| 6| 6|
| 7|2024-12-02|2024-12-02 05:02:...| 7| 7| 7|
| 8|2024-12-02|2024-12-02 05:02:...| 8| 8| 8|
| 9|2024-12-02|2024-12-02 05:02:...| 9| 9| 9|
| 10|2024-12-02|2024-12-02 05:02:...| 10| 1| 0|
| 11|2024-12-02|2024-12-02 05:02:...| 11| 1| 1|
| 12|2024-12-02|2024-12-02 05:02:...| 12| 1| 2|
| 13|2024-12-02|2024-12-02 05:02:...| 13| 1| 3|
| 14|2024-12-02|2024-12-02 05:02:...| 14| 1| 4|
| 15|2024-12-02|2024-12-02 05:02:...| 15| 1| 5|
| 16|2024-12-02|2024-12-02 05:02:...| 16| 1| 6|
| 17|2024-12-02|2024-12-02 05:02:...| 17| 1| 7|
| 18|2024-12-02|2024-12-02 05:02:...| 18| 1| 8|
| 19|2024-12-02|2024-12-02 05:02:...| 19| 1| 9|
+---+----------+--------------------+--------+-------+------+
1. コアとデータ量に基づくパーティションサイズ(spark.CreateDataFrameを使用)
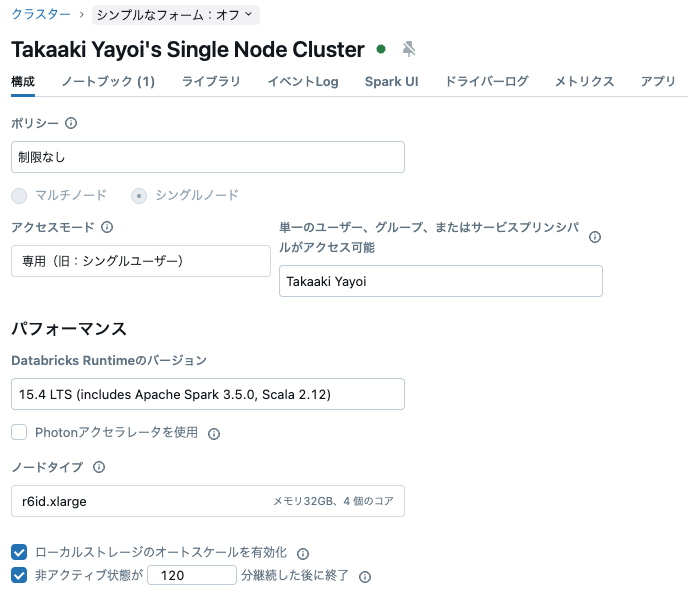
- Spark UIのExecutorsタブで、クラスターの利用可能なコア数を確認できます。今回の場合、Sparkセッションで設定されている通り4コアです。
- Sparkは、spark.createDataFrameでメモリ内に作成されたデータセットを利用可能なコア数に基づいて均等に分割します。そのため、パーティション数は4です。変数
spark.sparkContext.defaultParallelismを確認できます。 - コア数を減らすと、パーティション数も同様に減少します。
- 以下の行分布やSpark UIを見れば、均等な分布を確認できます。
- 狭い変換の最も効率的な方法は、均等なパーティションを持ち、パーティション数がコア数で割り切れることです。これにより、コアが未使用になるのを防ぎます。
- データのサイズは影響しません。サイズが大きすぎると、OOM(メモリ不足)やディスク不足エラーが発生するか、処理時間が長くなるだけです。これは重要なポイントです。
# コア数
spark.sparkContext.defaultParallelism
4
20行からなるデータフレームを作成し、パーティション数を確認します。コア数と同じ4になっているはずです。
sdf_gen1_1 = sdf_generator1(2)
sdf_gen1_1.rdd.getNumPartitions()
4
spark_partition_id()を用いることで、データフレームの各レコードがどのパーティションに属しているのかを確認することができます。
sdf_part1_1 = sdf_gen1_1.withColumn("partition_id", f.spark_partition_id())
sdf_part1_1.show()
+---+---+------------+
| a| b|partition_id|
+---+---+------------+
| a| 1| 0|
| b| 2| 0|
| c| 3| 0|
| d| 4| 0|
| e| 5| 0|
| e| 6| 1|
| f| 7| 1|
| g| 8| 1|
| h| 9| 1|
| i| 10| 1|
| a| 1| 2|
| b| 2| 2|
| c| 3| 2|
| d| 4| 2|
| e| 5| 2|
| e| 6| 3|
| f| 7| 3|
| g| 8| 3|
| h| 9| 3|
| i| 10| 3|
+---+---+------------+
row_count = sdf_gen1_1.count()
print(row_count)
20
パーティションごとのレコードの比率を計算します。
sdf_part_count1_1 = sdf_part1_1.groupBy("partition_id").count()
sdf_part_count1_1 = sdf_part_count1_1.withColumn("count_perc", 100*f.col("count")/row_count)
sdf_part_count1_1.show()
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 5| 25.0|
| 1| 5| 25.0|
| 2| 5| 25.0|
| 3| 5| 25.0|
+------------+-----+----------+
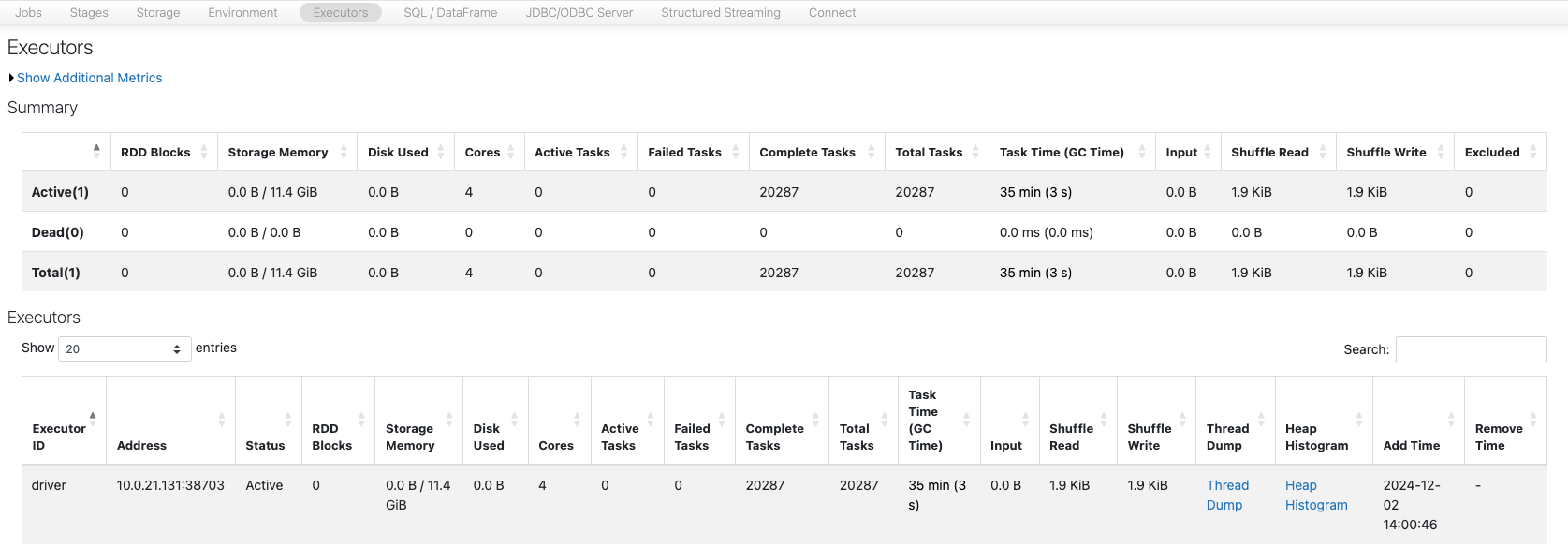
SparkジョブGen1_Exp1として実行し、Spark UIからジョブの詳細を確認します。
sc.setJobDescription("Gen1_Exp1")
sdf_gen1_1.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
SparkジョブGen1_Exp1をクリックして、タスクまでドリルダウンします。
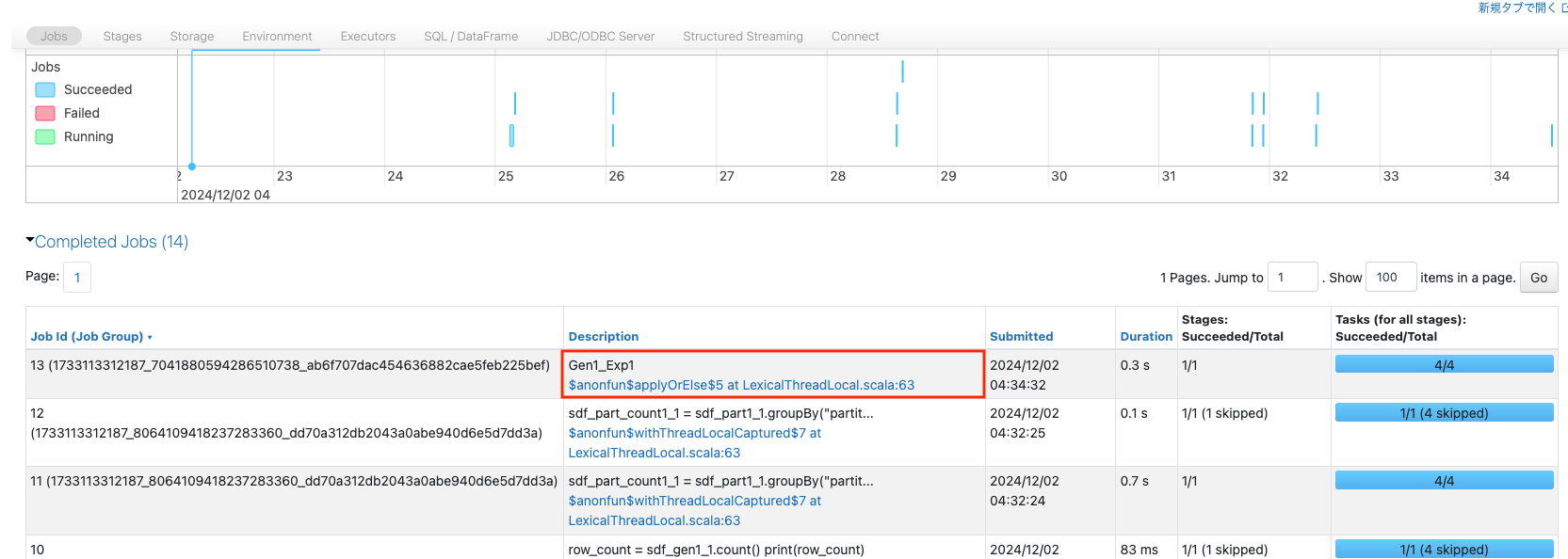
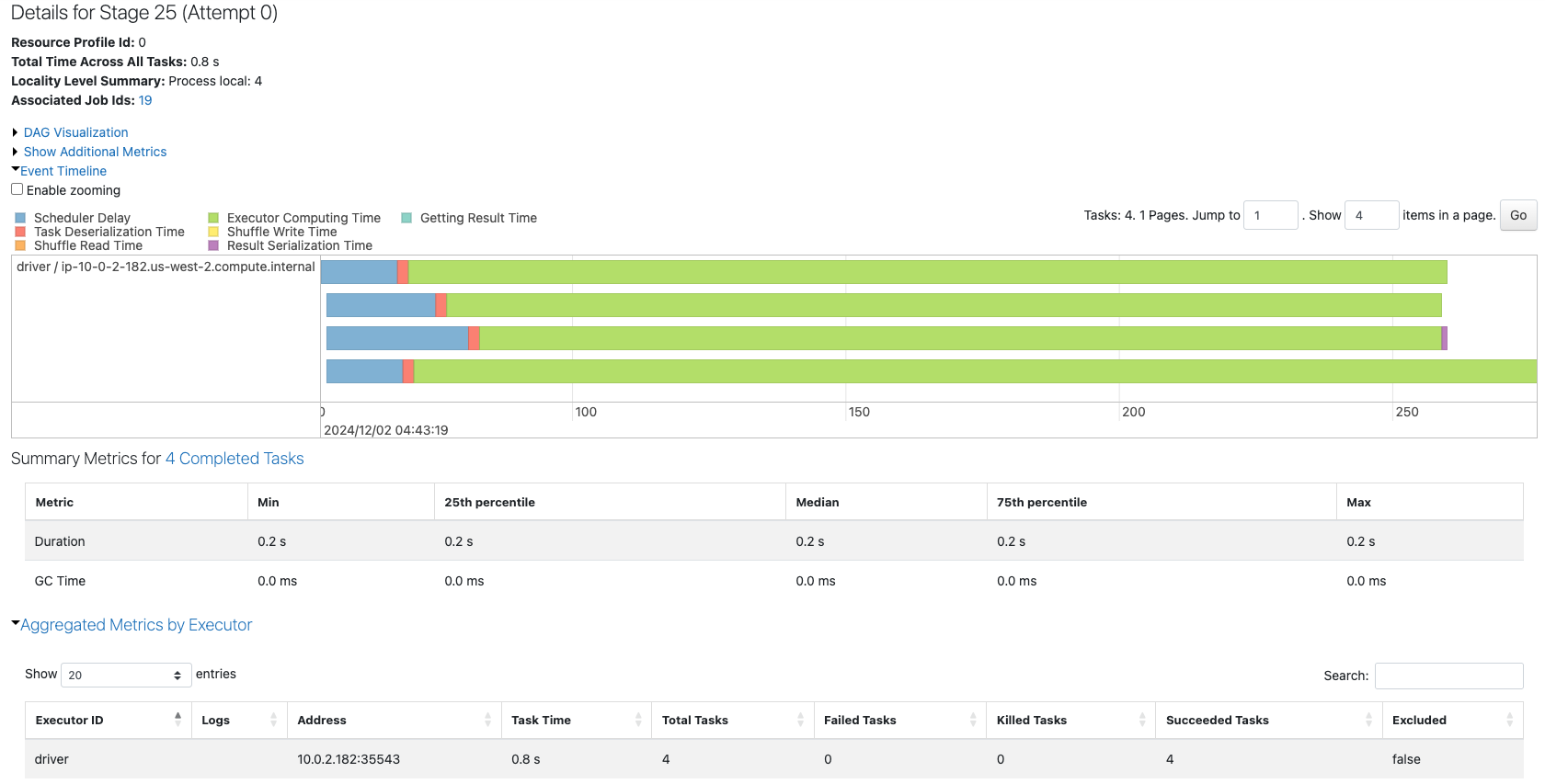
上の赤枠からわかるように4つのコアが効率的に使用され、下の赤枠からは4つのタスクはほぼ同じ処理時間(0.2s)で完了していることがわかります。
行数を増やして実験を行なっていきます。
sdf_gen1_2 = sdf_generator1(2000)
sdf_gen1_2.rdd.getNumPartitions()
sdf_part1_2 = sdf_gen1_2.withColumn("partition_id", f.spark_partition_id())
sdf_part1_2.show()
+---+---+------------+
| a| b|partition_id|
+---+---+------------+
| a| 1| 0|
| b| 2| 0|
| c| 3| 0|
| d| 4| 0|
| e| 5| 0|
| e| 6| 0|
| f| 7| 0|
| g| 8| 0|
| h| 9| 0|
| i| 10| 0|
| a| 1| 0|
| b| 2| 0|
| c| 3| 0|
| d| 4| 0|
| e| 5| 0|
| e| 6| 0|
| f| 7| 0|
| g| 8| 0|
| h| 9| 0|
| i| 10| 0|
+---+---+------------+
only showing top 20 rows
2万行のデータフレームです。
row_count = sdf_gen1_2.count()
print(row_count)
20000
パーティション3は若干レコードが少ないですが、ほぼ均等に分配されています。
sdf_part_count1_2 = sdf_part1_2.groupBy("partition_id").count()
sdf_part_count1_2 = sdf_part_count1_2.withColumn("count_perc", 100*f.col("count")/row_count)
sdf_part_count1_2.show()
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 5120| 25.6|
| 1| 5120| 25.6|
| 2| 5120| 25.6|
| 3| 4640| 23.2|
+------------+-----+----------+
SparkジョブGen1_Exp2として実行し、Spark UIからジョブの詳細を確認します。
sc.setJobDescription("Gen1_Exp2")
sdf_gen1_2.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
2. コアとデータ量に基づくパーティションサイズ(spark.rangeを使用)
- spark.createDataFrameのカウントと同じ結果が得られますが、これはデータを返すspark関数です
sdf_gen2_1 = sdf_generator2(2000000)
sdf_gen2_1.rdd.getNumPartitions()
4
sdf_part2_1 = sdf_gen2_1.withColumn("partition_id", f.spark_partition_id())
sdf_part2_1.show()
+---+----------+--------------------+--------+-------+------+------------+
| id| date| timestamp|idstring|idfirst|idlast|partition_id|
+---+----------+--------------------+--------+-------+------+------------+
| 0|2024-12-02|2024-12-02 05:02:...| 0| 0| 0| 0|
| 1|2024-12-02|2024-12-02 05:02:...| 1| 1| 1| 0|
| 2|2024-12-02|2024-12-02 05:02:...| 2| 2| 2| 0|
| 3|2024-12-02|2024-12-02 05:02:...| 3| 3| 3| 0|
| 4|2024-12-02|2024-12-02 05:02:...| 4| 4| 4| 0|
| 5|2024-12-02|2024-12-02 05:02:...| 5| 5| 5| 0|
| 6|2024-12-02|2024-12-02 05:02:...| 6| 6| 6| 0|
| 7|2024-12-02|2024-12-02 05:02:...| 7| 7| 7| 0|
| 8|2024-12-02|2024-12-02 05:02:...| 8| 8| 8| 0|
| 9|2024-12-02|2024-12-02 05:02:...| 9| 9| 9| 0|
| 10|2024-12-02|2024-12-02 05:02:...| 10| 1| 0| 0|
| 11|2024-12-02|2024-12-02 05:02:...| 11| 1| 1| 0|
| 12|2024-12-02|2024-12-02 05:02:...| 12| 1| 2| 0|
| 13|2024-12-02|2024-12-02 05:02:...| 13| 1| 3| 0|
| 14|2024-12-02|2024-12-02 05:02:...| 14| 1| 4| 0|
| 15|2024-12-02|2024-12-02 05:02:...| 15| 1| 5| 0|
| 16|2024-12-02|2024-12-02 05:02:...| 16| 1| 6| 0|
| 17|2024-12-02|2024-12-02 05:02:...| 17| 1| 7| 0|
| 18|2024-12-02|2024-12-02 05:02:...| 18| 1| 8| 0|
| 19|2024-12-02|2024-12-02 05:02:...| 19| 1| 9| 0|
+---+----------+--------------------+--------+-------+------+------------+
only showing top 20 rows
row_count = sdf_gen2_1.count()
print(row_count)
2000000
sdf_part_count2_1 = sdf_part2_1.groupBy("partition_id").count()
sdf_part_count2_1 = sdf_part_count2_1.withColumn("count_perc", 100*f.col("count")/row_count)
sdf_part_count2_1.show()
+------------+------+----------+
|partition_id| count|count_perc|
+------------+------+----------+
| 0|500000| 25.0|
| 1|500000| 25.0|
| 2|500000| 25.0|
| 3|500000| 25.0|
+------------+------+----------+
sc.setJobDescription("Gen2_Exp1")
sdf_gen2_1.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
どれだけ行数を増やしたとしても、挙動自体は変わりません。
sdf_gen2_2 = sdf_generator2(2000000000000000000)
sdf_gen2_2.rdd.getNumPartitions()
4
3. Sparkパーティションがパフォーマンスに与える影響
- 各ジョブステージのステージ詳細内で、パーティションの数が使用するコアの数で割り切れる場合、利用可能なキャパシティを最適に活用できることがわかります。
- 比較的小さなデータセットでパーティションの数を増やすと、未使用ファイルのクリーンアップとスケジューラーの時間を管理するGC(ガベージコレクション)時間が大幅に増加し、プロセスが大幅に遅くなることがわかります。
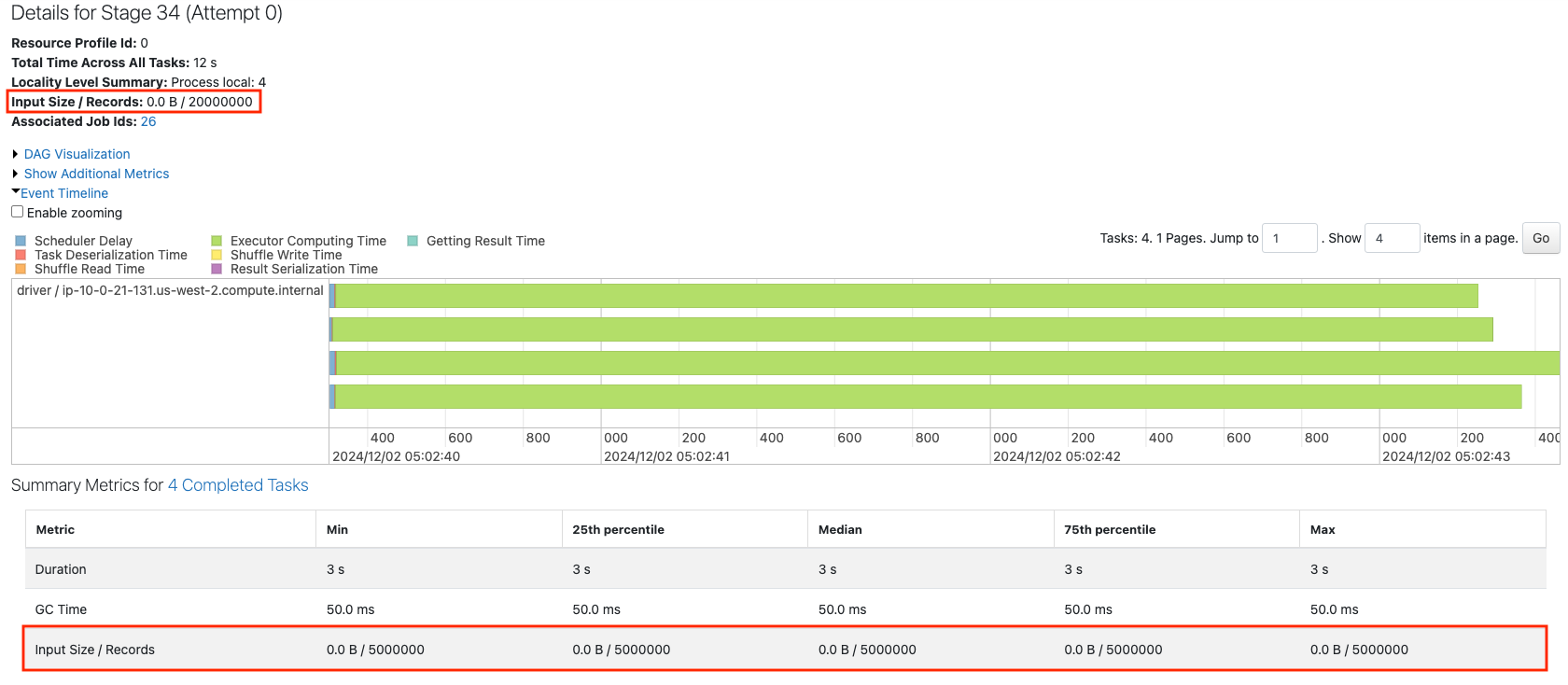
4つのパーティションから構成される2000万レコードのデータフレームのジョブを確認します。
sdf1 = sdf_generator2(20000000, 4)
print(sdf1.rdd.getNumPartitions())
sc.setJobDescription("Part Exp1")
sdf1.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
Recordsからは、上の赤枠では全レコード数、下の赤枠ではタスクにおける入力レコード数、すなわち、各パーティションのレコード数を確認することができます。均等に1/4されています。
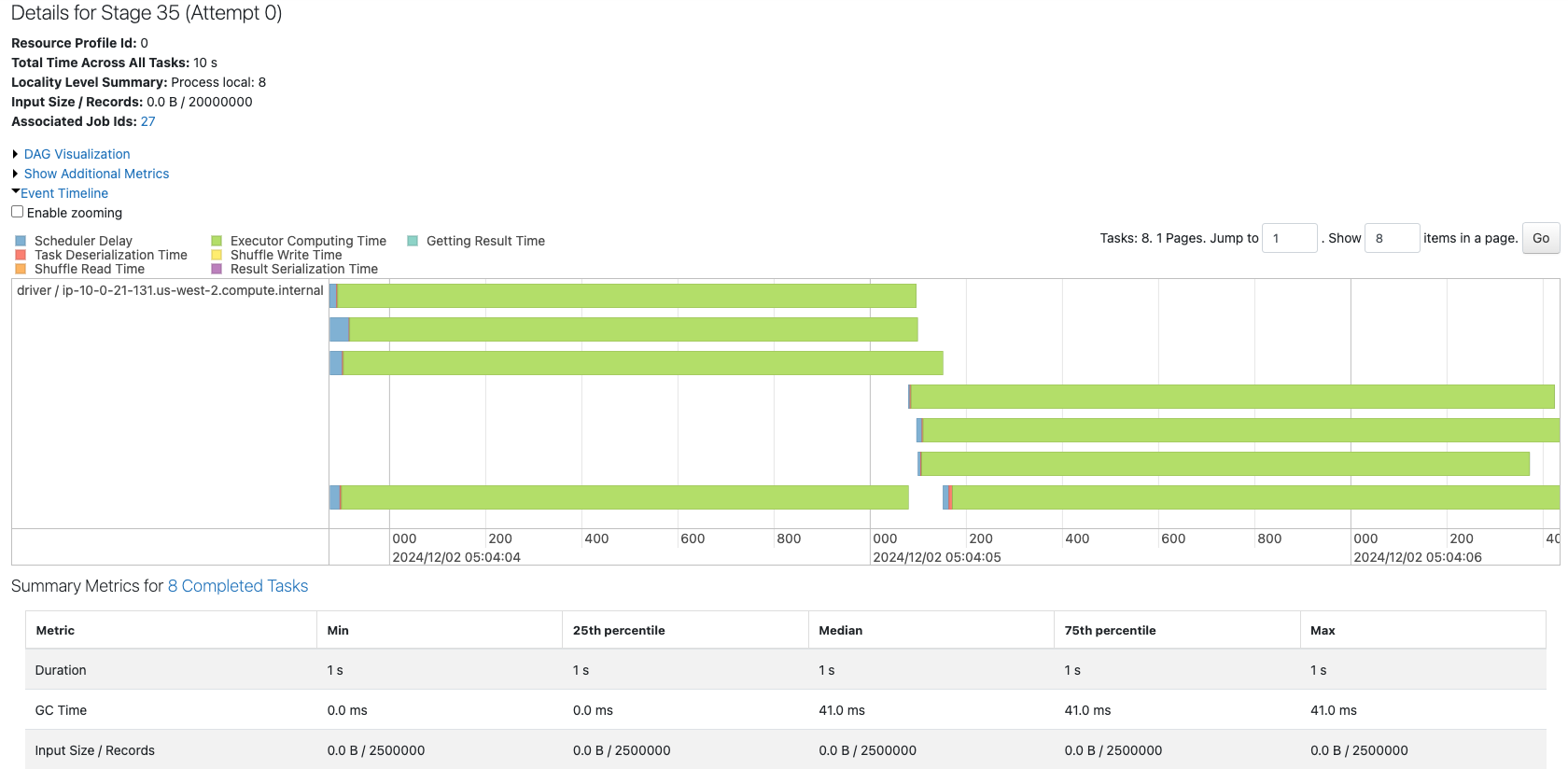
8つのパーティションから構成されるデータフレームのジョブを確認します。
sdf2 = sdf_generator2(20000000, 8)
print(sdf2.rdd.getNumPartitions())
sc.setJobDescription("Part Exp2")
sdf2.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
4つのコアで8つのパーティションを処理している様子が確認できます。パーティションの数が増えたことで、タスクごとのレコード数は1/8になっています。
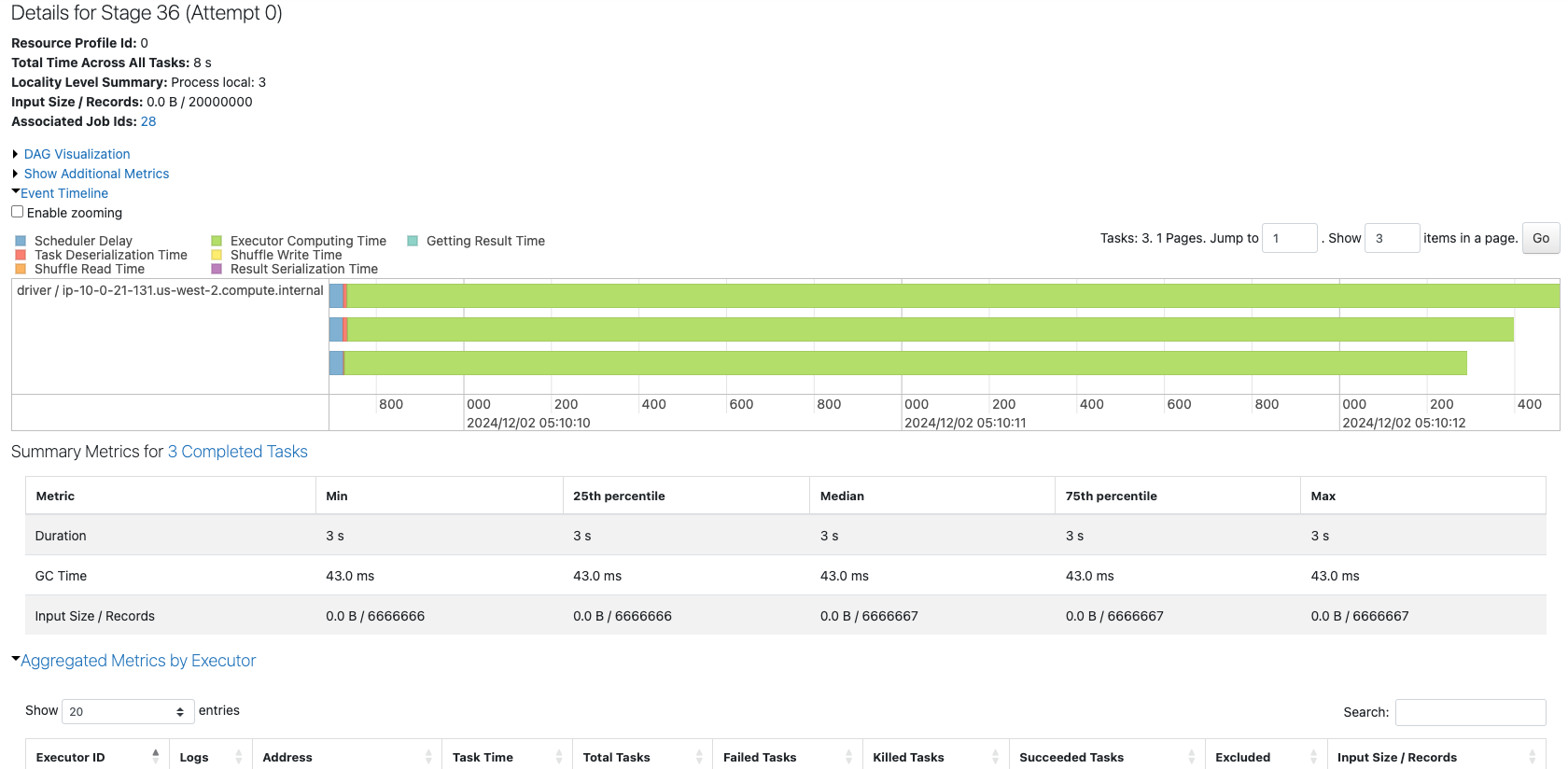
3つのパーティションから構成されるデータフレームのジョブを確認します。
sdf3 = sdf_generator2(20000000, 3)
print(sdf3.rdd.getNumPartitions())
sc.setJobDescription("Part Exp3")
sdf3.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
コアが4つあるにも関わらず、3つのタスクしか実行されていません。これでは、リソースを有効に活用しているとは言えません。
6つのパーティションから構成されるデータフレームのジョブを確認します。
sdf4 = sdf_generator2(20000000, 6)
print(sdf4.rdd.getNumPartitions())
sc.setJobDescription("Part Exp4")
sdf4.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
パーティション数がコア数(4)の倍数になっていないため、後半では2つのコアが遊んでしまっています。
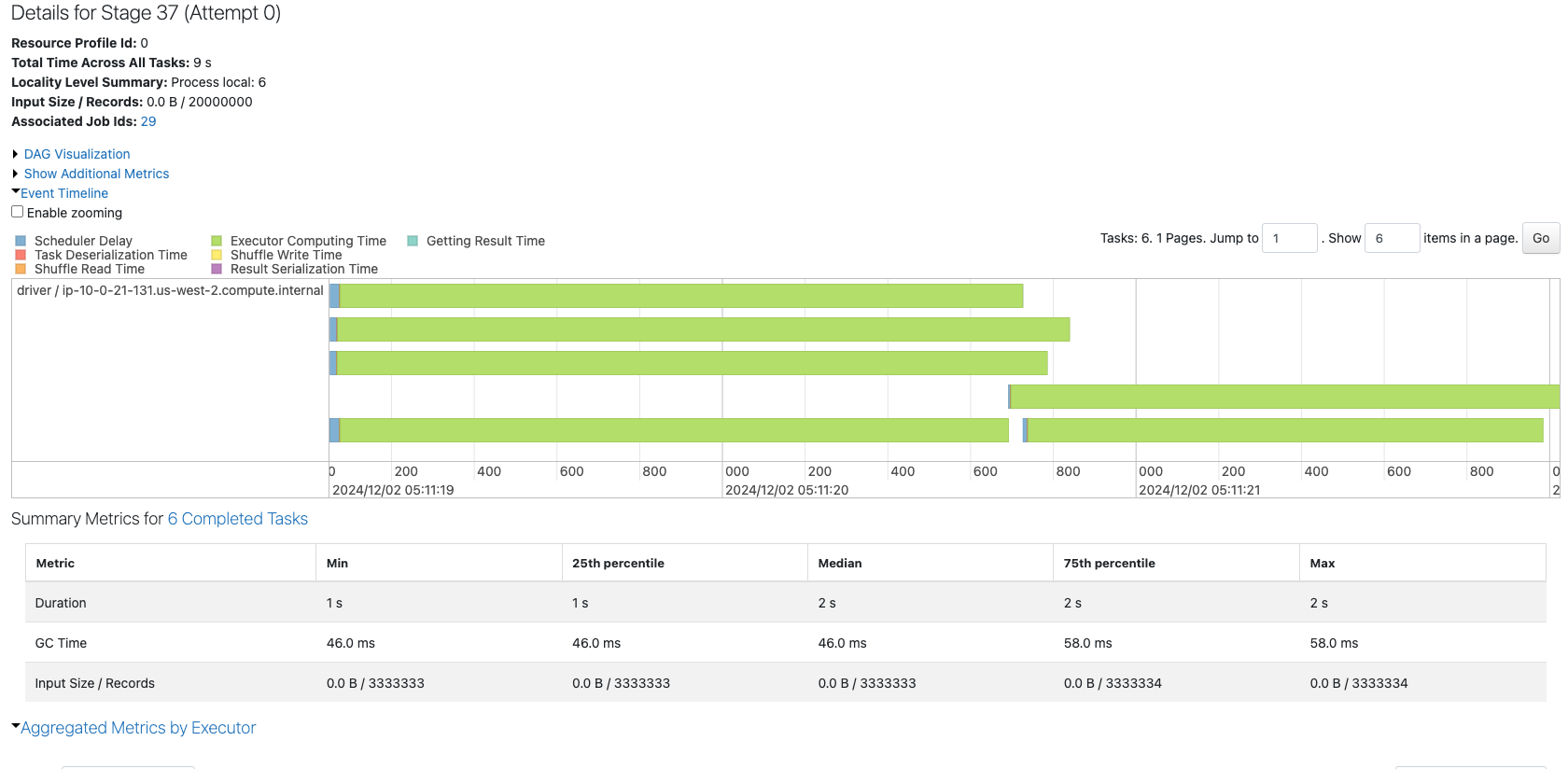
200のパーティションから構成されるデータフレームのジョブを確認します。
sdf5 = sdf_generator2(20000000, 200)
print(sdf5.rdd.getNumPartitions())
sc.setJobDescription("Part Exp5")
sdf5.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
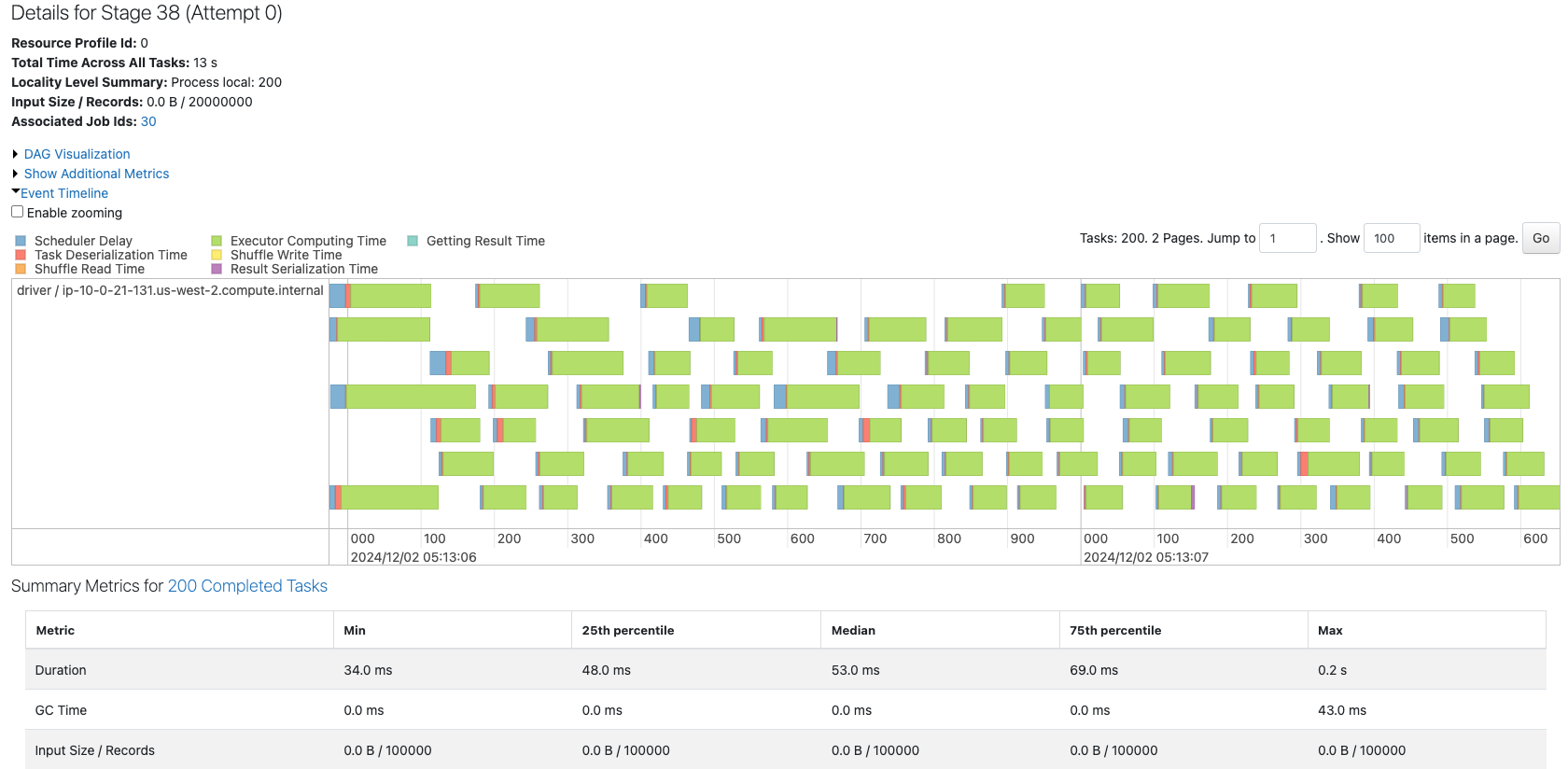
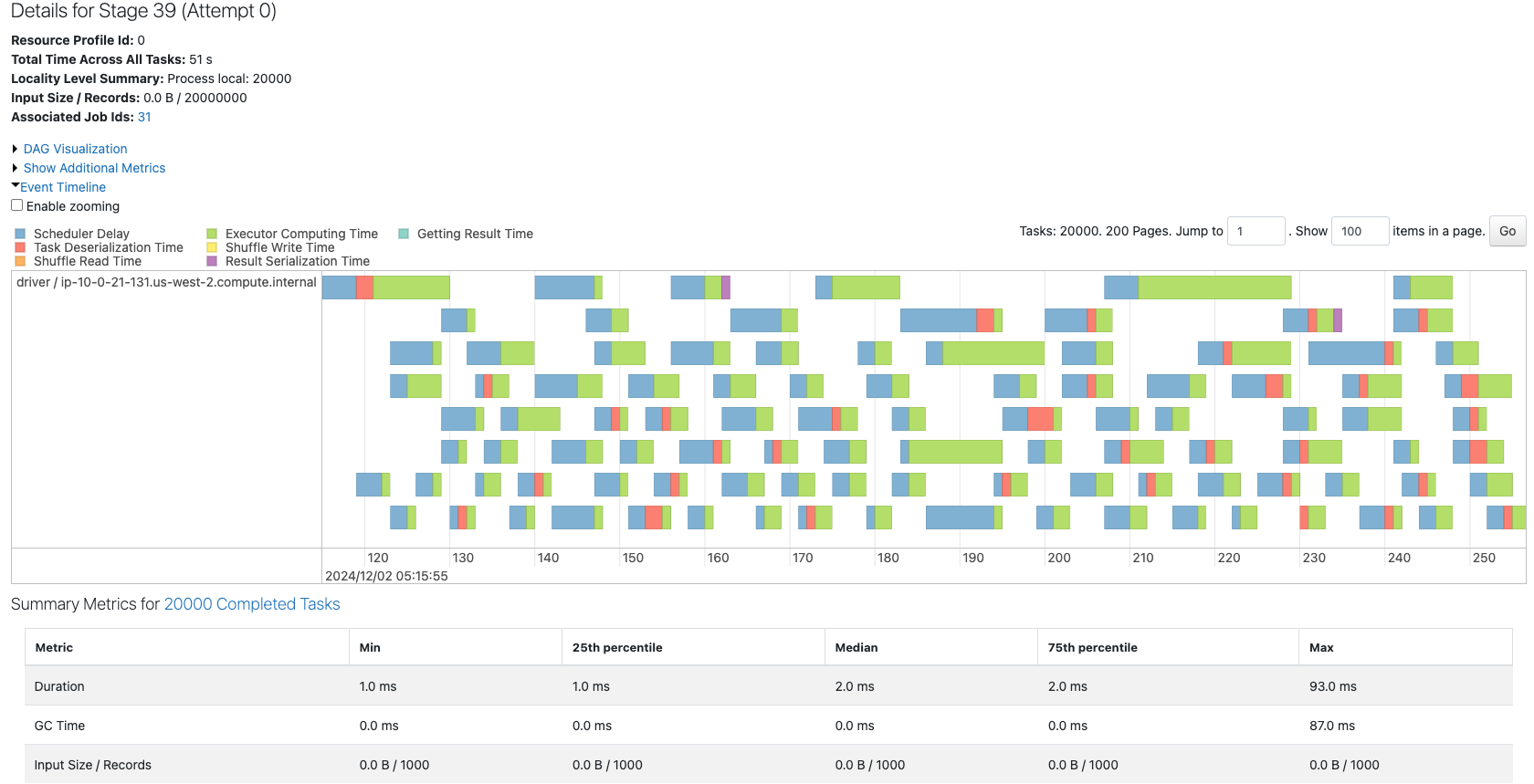
20000のパーティションから構成されるデータフレームのジョブを確認します。
sdf6 = sdf_generator2(20000000, 20000)
print(sdf6.rdd.getNumPartitions())
sc.setJobDescription("Part Exp6")
sdf6.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
ここまでくると、コア数に対してパーティションが多すぎるせいか、スケジューラーによる遅延(Scheduler Delay)が顕著になってきています。
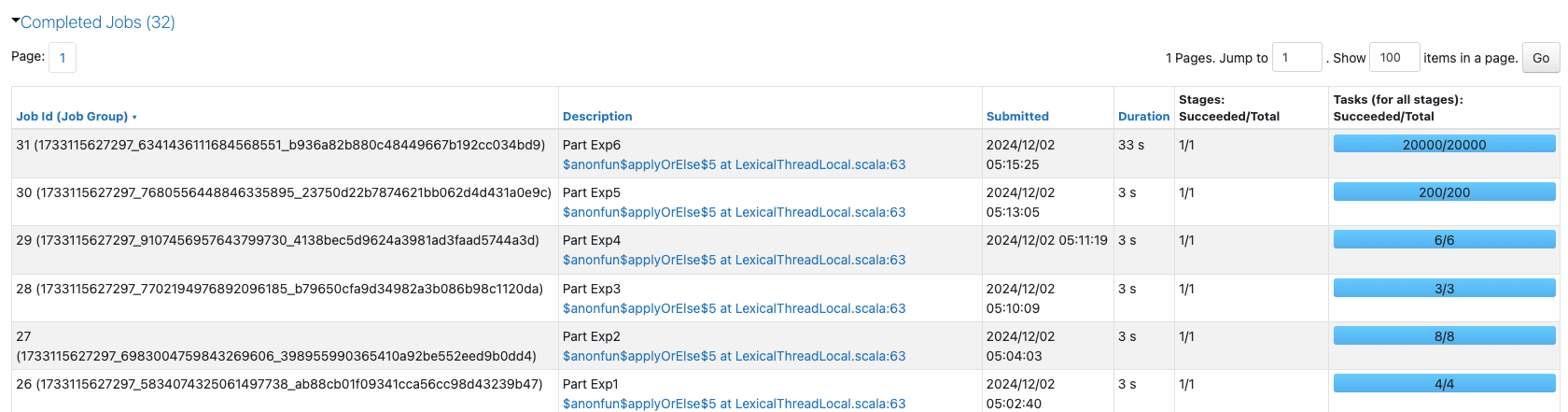
ここまでのジョブの一覧を見ると、タスクとパーティションの関係、パーティションの数と性能との関係性が少しづつですが理解できてきました。
次回以降は、これらパーティションの数を動的に変更するにはどのような方法があるのかをカバーします。
こちらに続きます。