こちらのアップデートです。ついにテーブル更新トリガーがやってきました。
ジョブがソーステーブルの更新時にトリガーできるようになりました。
ソーステーブルが更新されたときにジョブを実行するトリガーを作成できるようになりました。「ソーステーブルが更新されたときにジョブをトリガーする」を参照してください。
マニュアルはこちらです。
概要
Databricksのテーブル更新トリガー機能は、ソーステーブルにデータが更新されたタイミングで自動的にジョブを実行する機能です。従来は継続的に実行中のクラスターを維持するか、定期的なスケジュール実行に頼る必要がありましたが、この機能により実際にデータが更新されたときだけ処理を実行できるようになりました。
Unity CatalogのDeltaテーブル、Icebergマネージドテーブル、外部テーブル、マテリアライズドビュー、ストリーミングテーブルなど幅広いテーブル形式に対応しており、複数テーブルの監視や更新タイミングの制御も可能です。追加コストはクラウドプロバイダーのストレージアクセス料金のみで、効率的なデータパイプラインの構築を実現します。
機能概要
テーブル更新トリガーは、Databricksジョブの実行タイミングをデータの更新に連動させる機能です。これまでのような時間ベースのスケジュール実行とは異なり、実際にデータが変更されたタイミングでのみジョブが起動します。
対応するテーブル形式
| テーブル形式 | サポート状況 | 備考 |
|---|---|---|
| Unity Catalog Deltaテーブル | ✓ | マネージドテーブル対応 |
| Icebergマネージドテーブル | ✓ | Unity Catalog内で管理 |
| Delta Lake外部テーブル | ✓ | Unity Catalogでバックアップ |
| マテリアライズドビュー | ✓ | 更新監視可能 |
| ストリーミングテーブル | ✓ | リアルタイム処理に最適 |
| Delta Sharing共有テーブル | ✗ | 現在未対応 |
| ビュー (Delta Sharing経由) | ✗ | 現在未対応 |
監視対象の操作
トリガーは以下のデータ変更操作を検知します:
- INSERT (新規データの挿入)
- UPDATE (既存データの更新)
- MERGE (データの統合)
- DELETE (データの削除)
メリット、嬉しさ
1. コスト最適化
継続的に実行されるクラスターが不要になり、必要な時だけリソースを使用するため、クラウドコストを大幅に削減できます。追加料金はクラウドプロバイダーのストレージアクセス料金のみです。
2. 運用の簡素化
データ更新プロセスの詳細な知識がなくても、新しいデータが準備できたタイミングで自動的にジョブが実行されます。定期実行による無駄な処理や、データ到着の遅延による処理の失敗を防げます。
3. 柔軟な実行制御
複数テーブルの監視では、以下の2つのモードから選択可能です:
トリガー実行モード:
├── ANY: いずれかのテーブルが更新されたら実行
└── ALL: すべてのテーブルが更新されたら実行
4. 動的パラメータの活用
ジョブ実行時に以下の情報を動的に取得し、処理に活用できます:
| パラメータ | 説明 | 使用例 |
|---|---|---|
{{job.trigger.table.updated_tables}} |
更新されたテーブルのJSONリスト | 処理対象の特定 |
{{job.trigger.table.<catalog.schema.table>.commit_timestamp.iso_datetime}} |
最新コミットのタイムスタンプ | 差分処理の基準時刻 |
{{job.trigger.table.<catalog.schema.table>.version}} |
最新コミットのバージョン | バージョン管理 |
使い方の流れ
ステップ1: 基本的な設定
- Databricksワークスペースの左側メニューからジョブとパイプラインをクリック
- トリガーを追加したいジョブを選択
- 右側パネルのスケジュールとトリガーからトリガーの追加をクリック
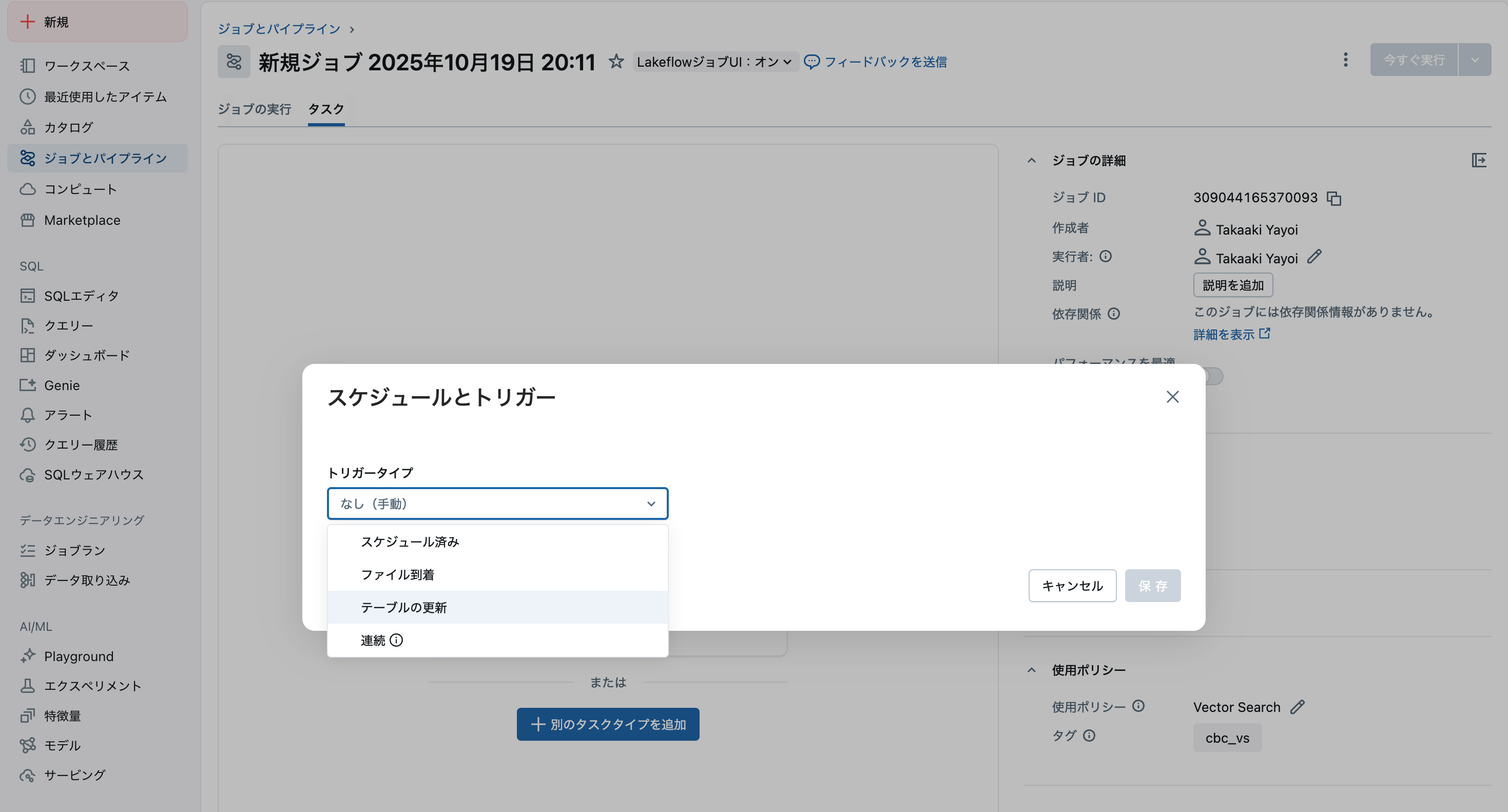
- トリガーの種類でテーブル更新を選択
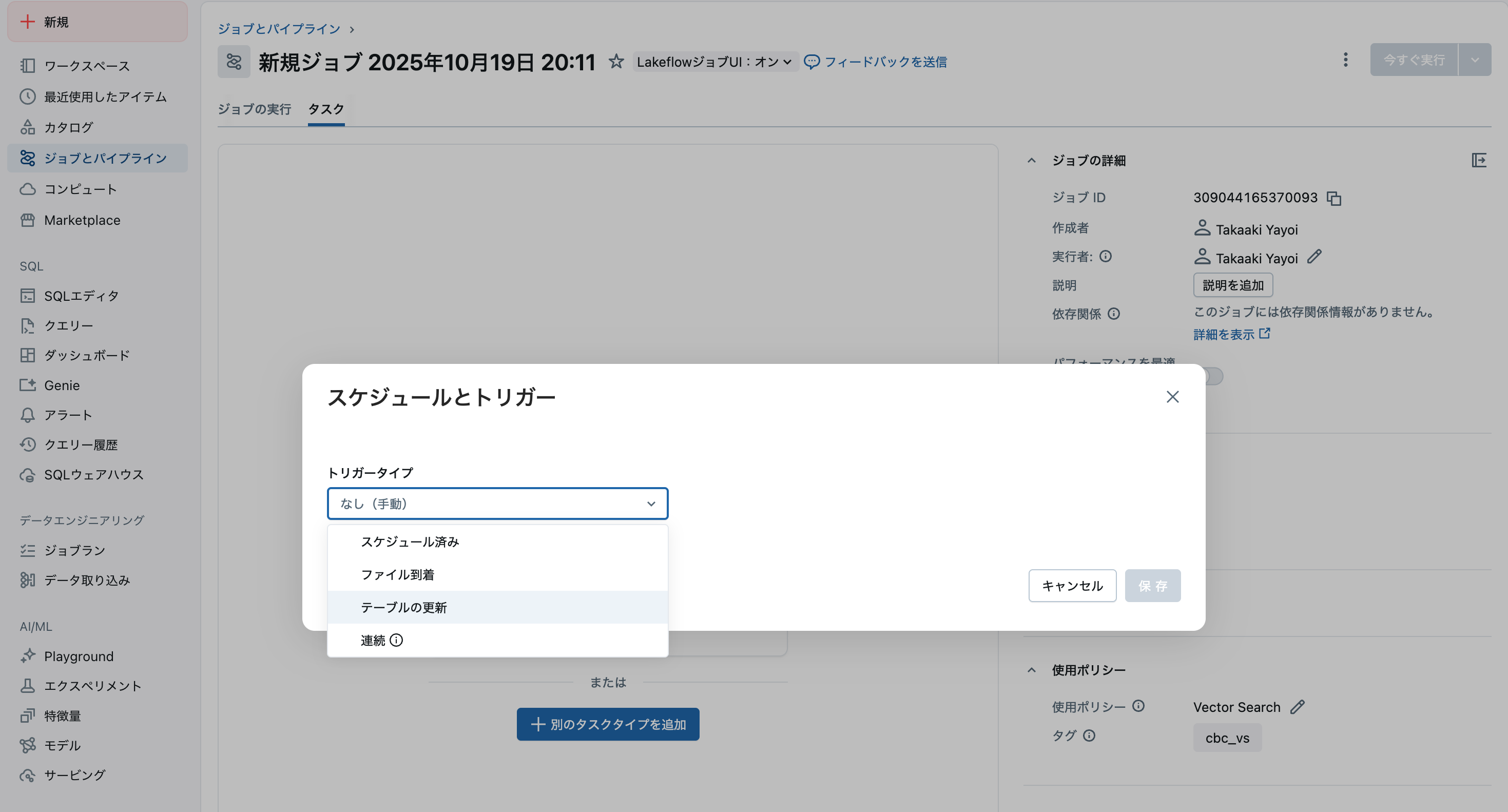
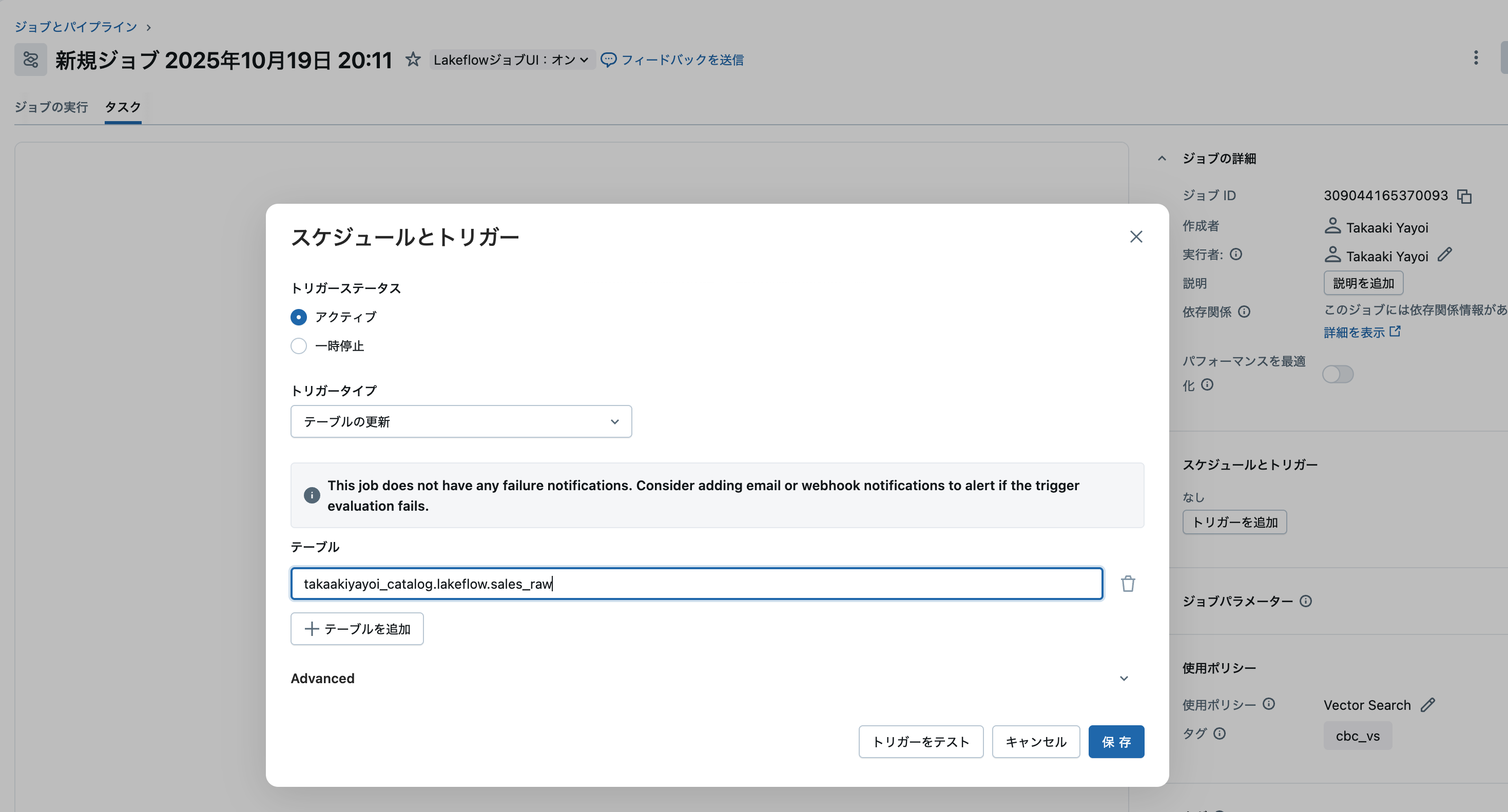
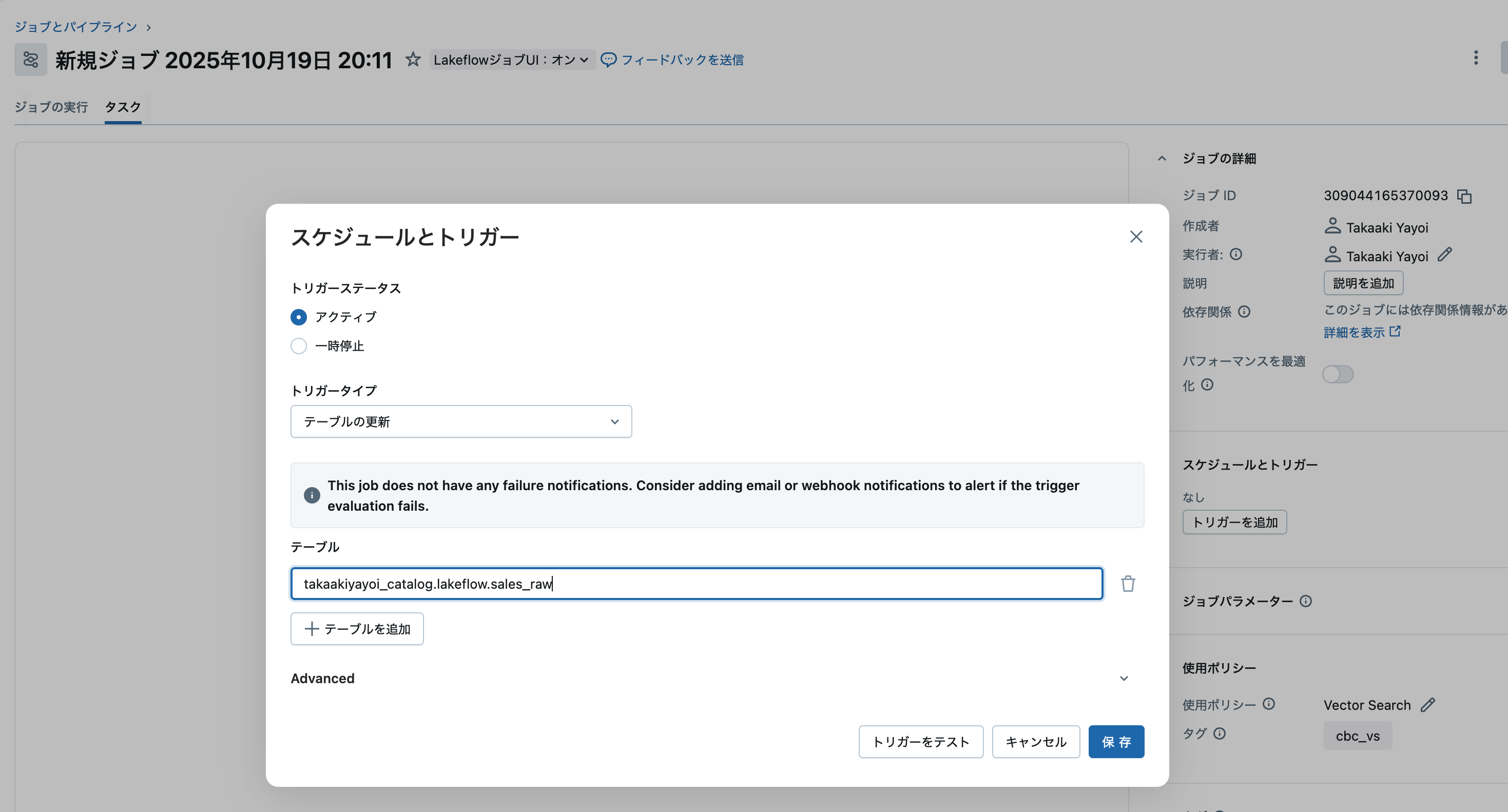
ステップ2: テーブルの選択と実行条件の設定
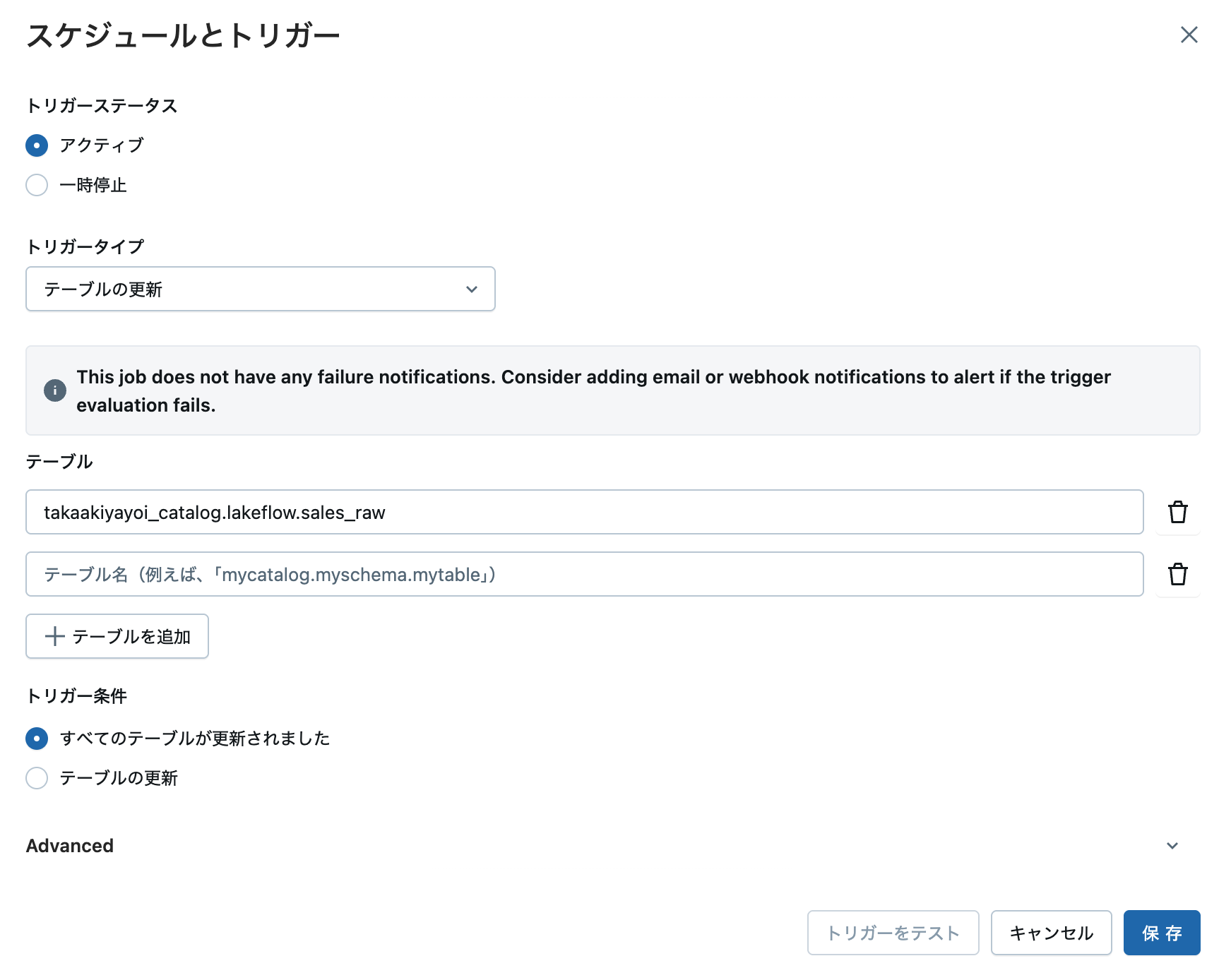
注意
トリガー条件の「テーブルの更新」は「いずれかのテーブルが更新された」です。間も無く修正されます。
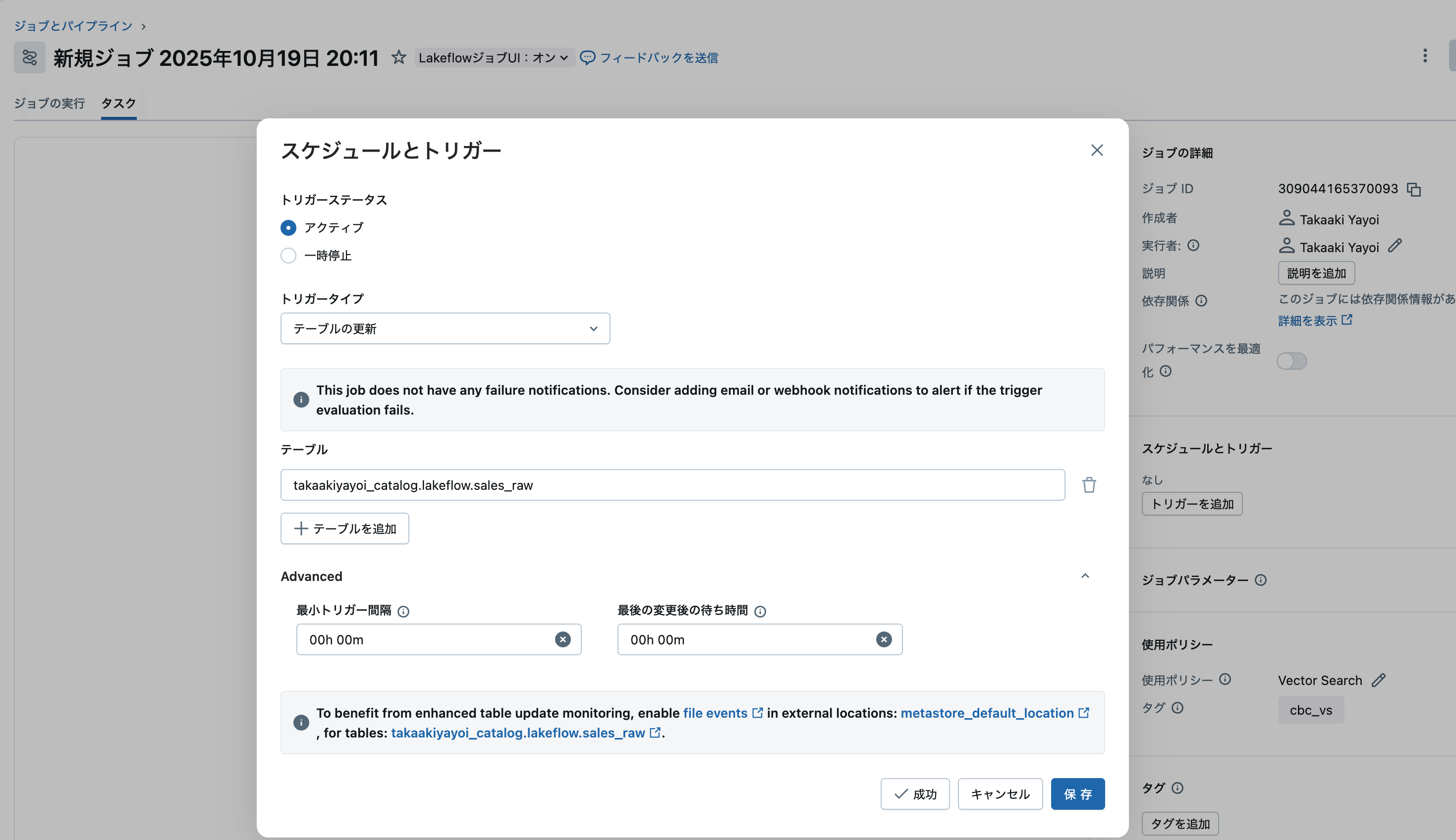
ステップ3: 詳細設定 (オプション)
高度な制御が必要な場合は、以下の設定を調整できます:
| 設定項目 | デフォルト | 説明 | 使用シーン |
|---|---|---|---|
| トリガー間の最小時間 | なし | 前回実行完了後の最小待機時間(秒) | 頻繁な更新による過度な実行を防ぐ |
| 最後の変更後の待機時間 | なし | 最終更新後の待機時間(秒) | バッチ更新の完了を待つ |
ステップ4: テストと保存
- 「テストトリガー」をクリックして設定を検証
- 問題がなければ「保存」をクリック
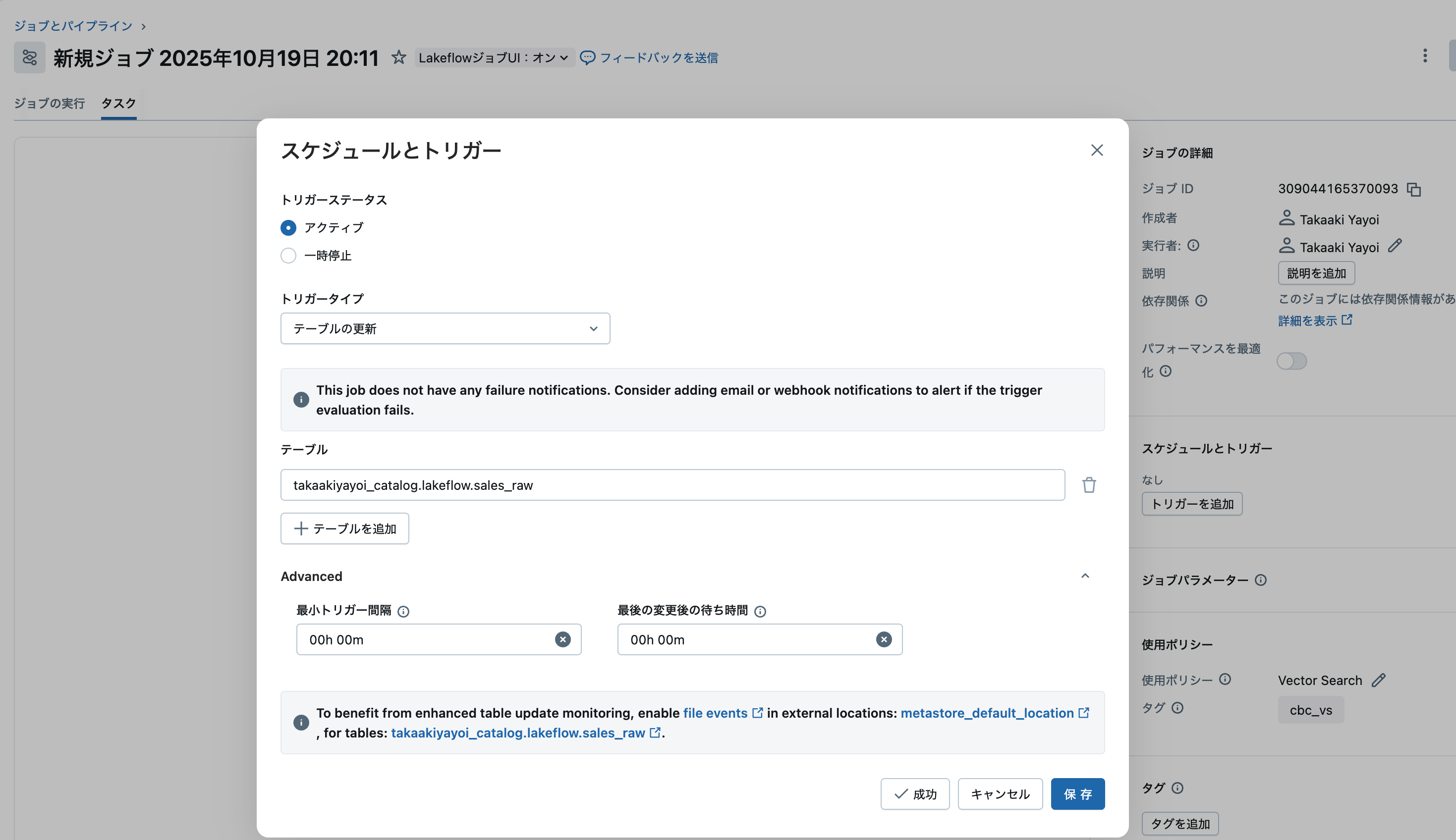
パフォーマンス最適化: ファイルイベントの有効化
最高のパフォーマンスを得るには、外部ロケーションでファイルイベントを有効化します:
設定フロー:
外部ロケーション設定
↓
ファイルイベント有効化
↓
クラウドプロバイダーの変更通知を利用
↓
高速かつ効率的な更新検知
サンプル: 売り上げデータの集計
テーブルの作成
監視対象のテーブルと監視対象テーブルが更新された結果に基づいて更新されるテーブルを定義します。
-- 売上データテーブル
CREATE TABLE takaakiyayoi_catalog.lakeflow.sales_raw (
sale_id INT,
amount DOUBLE
);
-- カウント結果テーブル
CREATE TABLE takaakiyayoi_catalog.lakeflow.sales_count (
total_count BIGINT,
updated_at TIMESTAMP
);
ジョブの作成
以下のような更新処理をノートブックで定義します。
from datetime import datetime
# 単純にレコード数をカウント
count = spark.table("takaakiyayoi_catalog.lakeflow.sales_raw").count()
# 結果を保存
spark.sql(f"""
INSERT OVERWRITE takaakiyayoi_catalog.lakeflow.sales_count
VALUES ({count}, CURRENT_TIMESTAMP())
""")
print(f"件数: {count}件")
print(f"更新時刻: {datetime.now()}")
ジョブを作成し、トリガーでテーブルの更新を選択します。
上で作成したテーブルtakaakiyayoi_catalog.lakeflow.sales_rawを監視対象として指定します。
動作確認やトリガーのタイミングを指定することができます。
上で作成したノートブックを選択してジョブを作成します。
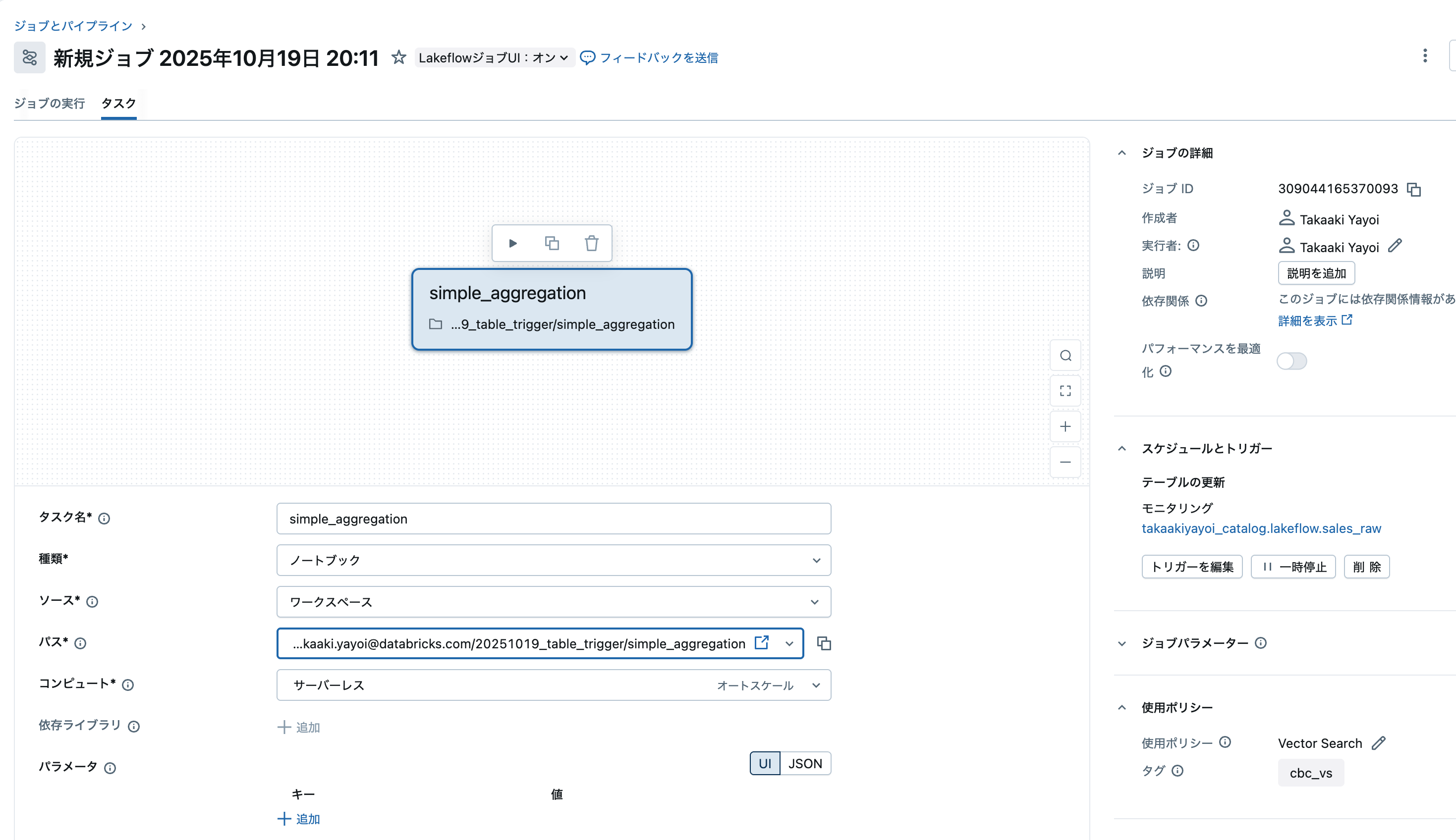
この時点では監視対象テーブルは空です。
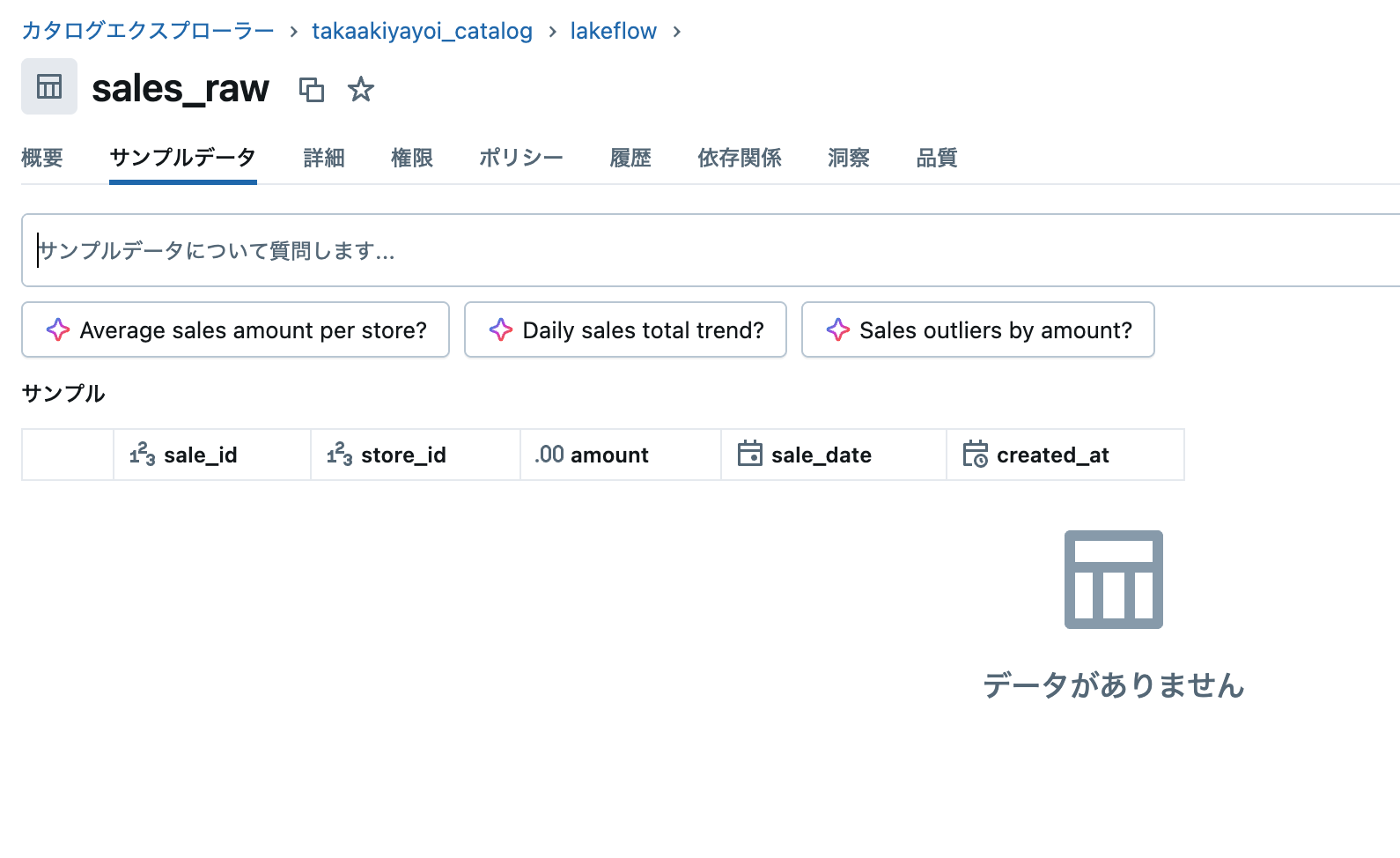
テーブルを更新してジョブをトリガー
テーブルにレコードを追加します。
-- データ追加(ジョブが自動起動)
INSERT INTO takaakiyayoi_catalog.lakeflow.sales_raw
VALUES
(1, 1000),
(2, 2000),
(3, 3000);
すると、作成したジョブが起動します!
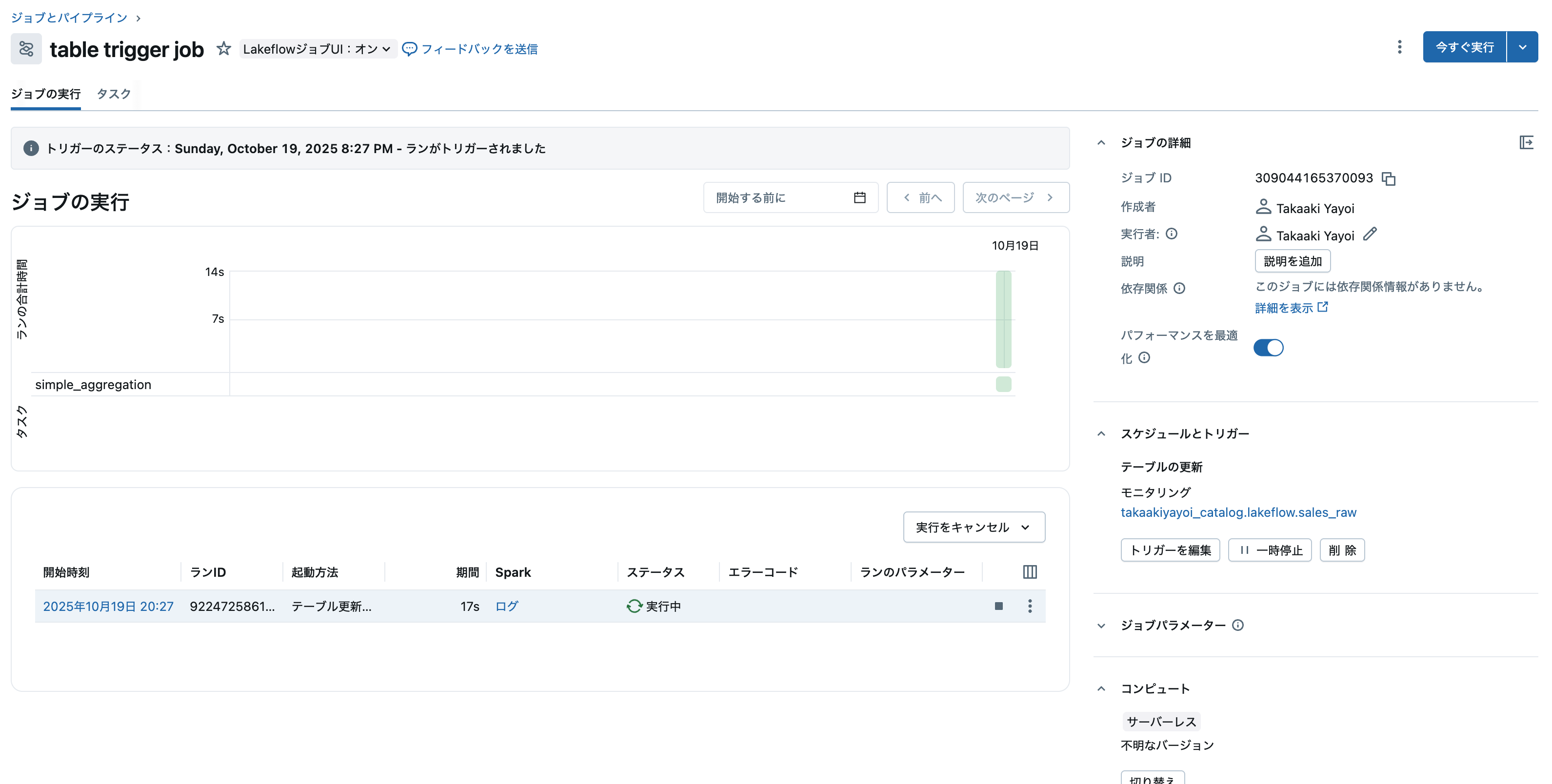
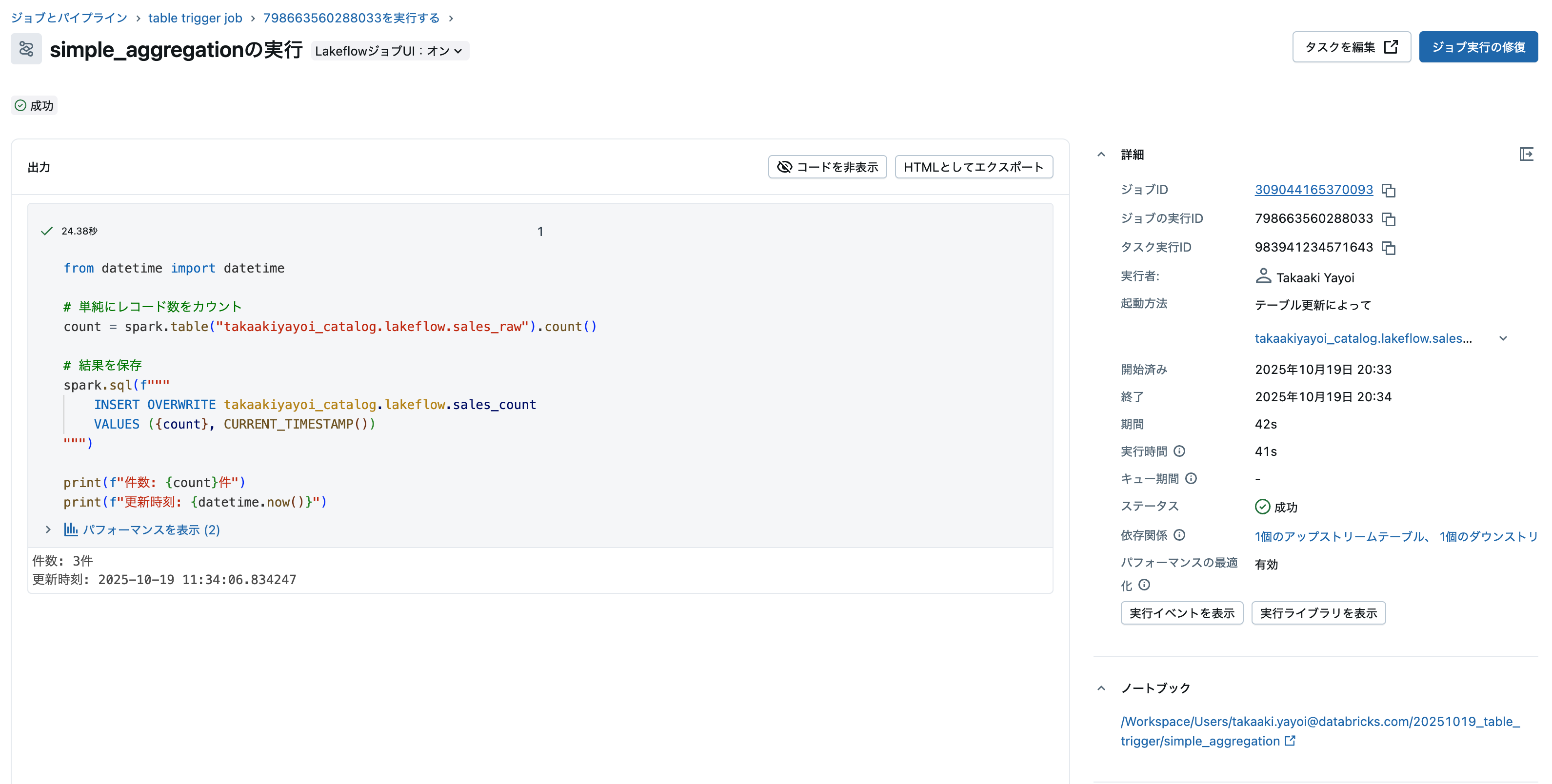
ジョブが成功しました。
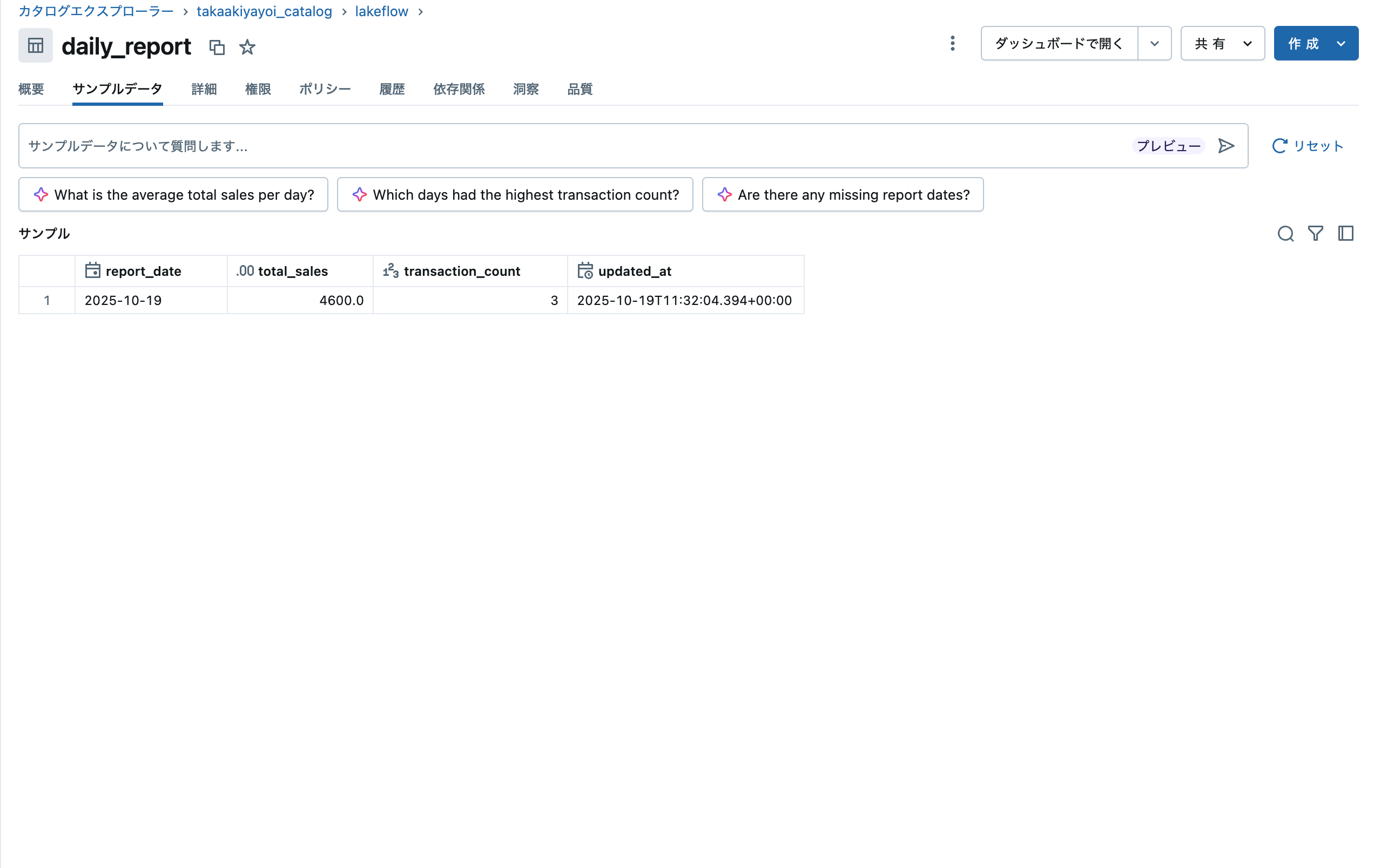
集計結果テーブルも更新されました。
注意点
1. 制限事項
- ワークスペースごとの上限: 最大1000個のテーブル更新トリガー
- トリガーごとの監視テーブル数: 最大10個
- Delta Sharing経由のテーブル/ビュー: 現在サポート対象外
2. 待機時間設定の相互作用
「トリガー間の最小時間」と「最後の変更後の待機時間」を両方設定した場合、両方の条件を満たすまで実行されません。
例:
- トリガー間の最小時間: 120秒
- 最後の変更後の待機時間: 60秒
- 結果: 最短でも120秒待機し、さらに最後の更新から60秒経過後に実行
3. エラー通知の設定
テーブル更新トリガーの評価が失敗した場合に備えて、ジョブ失敗時の通知設定を行うことを推奨します。メールやシステム宛先への通知を構成することで、問題を迅速に検知できます。
4. メタストアルートレベルのテーブル
メタストアのルートレベルストレージにあるテーブルは、まず外部ロケーションに変換してからファイルイベントを有効化する必要があります。
まとめ
Databricksのテーブル更新トリガー機能は、データ駆動型のジョブ実行を実現する強力な機能です。従来の時間ベースのスケジューリングから、実際のデータ更新に基づく効率的な処理へと移行することで、コスト削減と運用の簡素化を同時に実現できます。
Unity Catalogの様々なテーブル形式に対応し、複数テーブルの監視や柔軟な実行制御も可能です。ファイルイベントの有効化によるパフォーマンス最適化や、動的パラメータを活用した高度な処理ロジックの実装により、より洗練されたデータパイプラインを構築できます。制限事項や待機時間の設定に注意しながら、適切に設定することで、リアルタイムに近いデータ処理基盤を効率的に構築できるでしょう。是非ご活用ください!