本書ではDelta Live Tables(DLT)を使い始めると疑問に感じるポイントと、それに対する回答をまとめたものです。
本書でカバーされている以外の質疑に関しては、Delta Live TablesのFAQを参照ください。
Delta Live Tablesを利用するには申請が必要です。申請に関してはDatabricks担当者にお問い合わせください。
Delta Live Tablesのご紹介
Delta Live Tablesは、新鮮かつ高品質なデータを提供するデータパイプラインを容易に構築、管理できる機能を提供します。
-
パイプラインの容易な開発、維持
データパイプライン(バッチ、ストリーミング)を構築、管理するための記述ツール -
自動テスト
ビルトインの品質管理、データ品質モニタリング -
簡素化されたオペレーション
パイプラインオペレーションに対するディープな可視化を通じた自動エラーハンドリング
データパイプラインの容易な構築、維持
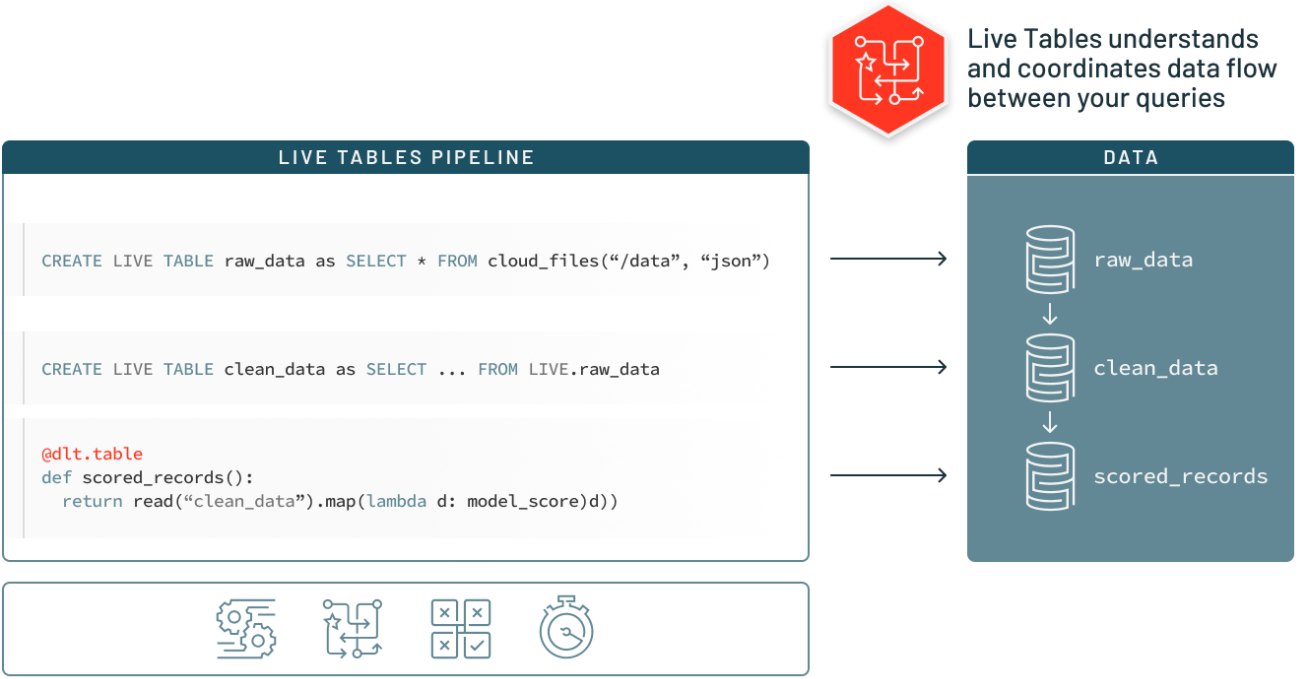
- ビジネスロジックとテーブルの依存関係をまとめて、宣言的にデータパイプラインを構築します。
- 構造化/非構造化データをバッチ、ストリーミングで実行します。
- 複数の環境(テスト/ステージング/プロダクション)でETLパイプラインを再利用できます
データに対する信頼性の確保
- Deltaのエクスペクテーション(データに対する期待をルールとして定義)により不正なデータがテーブルに流れ込むことを防ぎます。
- 事前定義されたエラーポリシー(失敗、欠損、警告、データ検疫)によってデータ品質エラーを回避、対策します。
- 長期にわたるデータ品質のトレンドをモニタリングします。
信頼性とオペレーションのシンプルさを維持しながらスケール
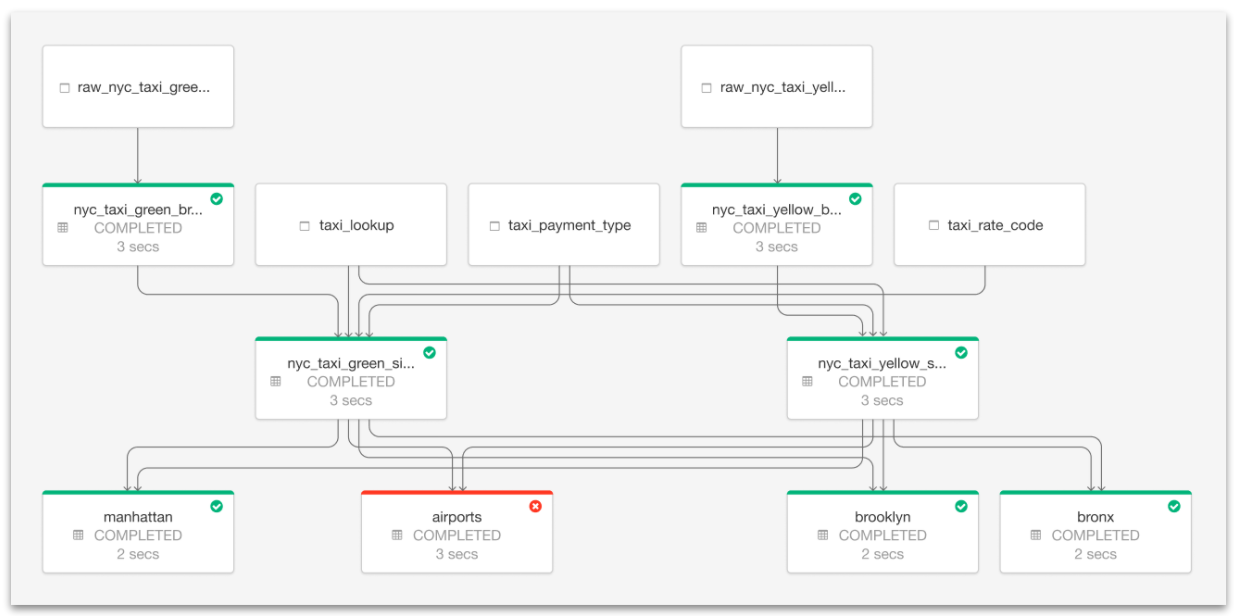
- オペレーションの状態とデータリネージュをビジュアルで追跡できるツールを用いることで、パイプラインオペレーションを深く理解することができます。
- 自動エラーハンドリングおよび容易なリトライによりダウンタイムを削減します。
- シングルクリックによるデプロイメント、アップグレードによりメンテナンスをスピードアップします。
Delta Live Tablesに対する疑問及び回答
Delta Live Tablesを使うことのメリットは?Databricksのジョブでいいのでは?
- 非常に高い柔軟性を必要するのであればジョブでもいいですが、DLTを使うと以下のメリットがあります。
- ETLイベントログが自動で記録されます。ジョブの場合、Pythonなどでロギングのロジックを組む必要があります。
- 宣言型でETLロジックを組める(最初のテーブルはこうである、次のテーブルはこうである)ので処理の見通しがよくなります。PySparkやSQLで全てのロジックを記述することはできますが、見通しを確保するには職人芸が必要です。
- ETL処理をモジュール化できるというメリットもあると思います。
Delta Live Tablesはどのように動作するのですか?
- 内部で動いているのはSparkの構造化ストリーミングとDelta Lakeです。
- DLTパイプラインの定義に基づいて構造化ストリーミングが動作し、Delta Lakeに中間データ、最終データ、イベントログが書き込まれます。これによって、パイプラインの途中でエラーが起きてもパイプライン全体のロールバックが可能となっています。ストリーミング処理のチェックポイントも生成されます。
- このため、入力データのスキーマ変更の影響範囲も構造化ストリーミングの仕様に依存します。
IncrementalテーブルとCompleteテーブルの違いは?
- 実行の都度、総洗い替えになるのがComplete、差分のみを処理するのがIncrementalです。すべてをCompleteテーブルで構成してバッチで実行するのがDLTで一番シンプルな構成になります。
- Incrementalテーブルがある場合でも、全てのデータを再処理する際にはFull Refreshを実行します。
Delta Live Tablseでスキーマエボリューションはサポートされていますか?
はい。Auto Loaderが読み込むファイルのスキーマが変更された場合、下流に変化が伝播します。
パイプラインのロジックを複数のノートブックに分割できますか?
できます。パイプラインのlibrariesでノートブックを複数指定できます。ノートブックの順序は問いません。
パイプライン内でロジックを共有できますか?
UDF(ユーザー定義関数)を使います。UDFで定義されたロジックは他のDLTノートブックからも使用できます。エクスペクテーションからもUDFを呼び出せるので、柔軟にロジックを記述することができます。
複数のノートブック、複数のパイプラインで変数や関数を共有できますか?
ReposのFiles機能を使います。Reposに登録された.pyファイルはDLTパイプラインノートブックから参照することができます。
DLTの処理をスケジューリングできますか?
ジョブのタスクでパイプラインを指定してください。
DLTのログはどのように活用すればいいのですか?
Delta形式で保存されるイベントログはそのままでも参照できますが、詳細情報が含まれているdetail列にはJSON文字列が入っているのでパーシングが必要です。
以下のサンプルを参考にしてください。
var json_parsed = spark.read.json(spark.table("<DLTログテーブル>").select("details").as[String])
var json_schema = json_parsed.schema
import org.apache.spark.sql.functions._
val parsed_event_log = spark.table("dlt_takaaki_yayoi_databricks_com_db.event_log_raw").withColumn("details_parsed", from_json($"details", json_schema))
parsed_event_log.write.format("delta").option("optimizeWrite", "true").saveAsTable("<パース済みDLTログテーブル>")
select *
from <パース済みDLTログテーブル>
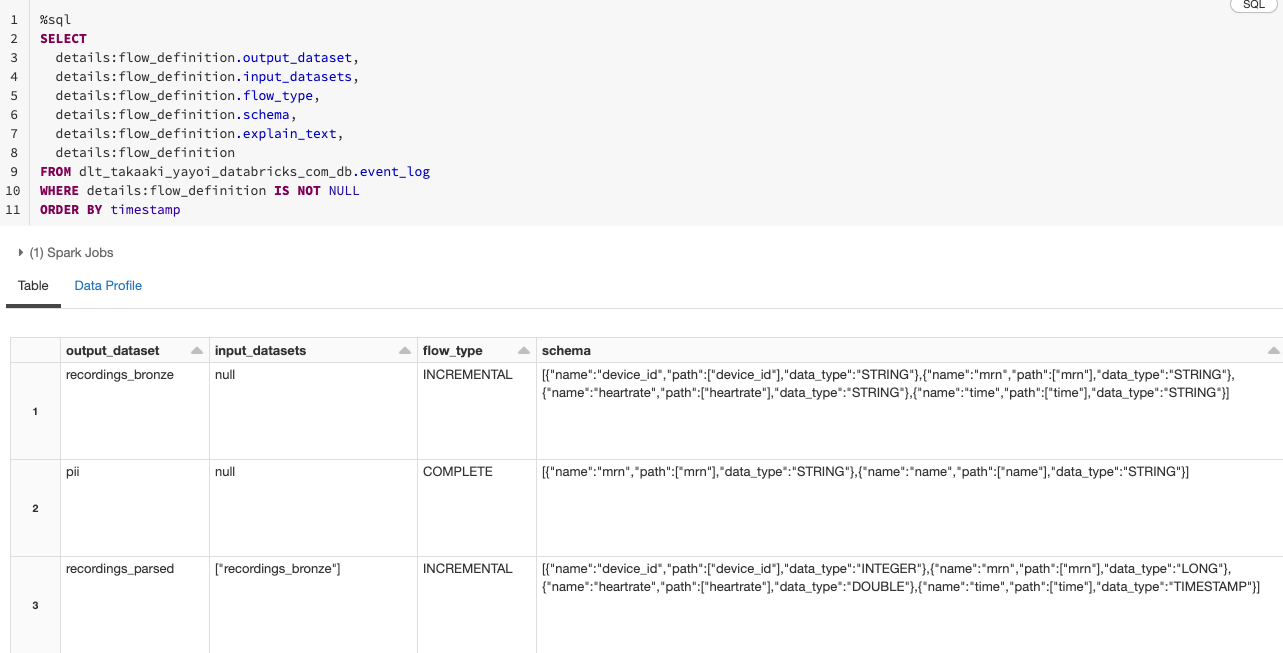
SELECT
details:flow_definition.output_dataset,
details:flow_definition.input_datasets,
details:flow_definition.flow_type,
details:flow_definition.schema,
details:flow_definition.explain_text,
details:flow_definition
FROM <パース済みDLTログテーブル>
WHERE details:flow_definition IS NOT NULL
ORDER BY timestamp
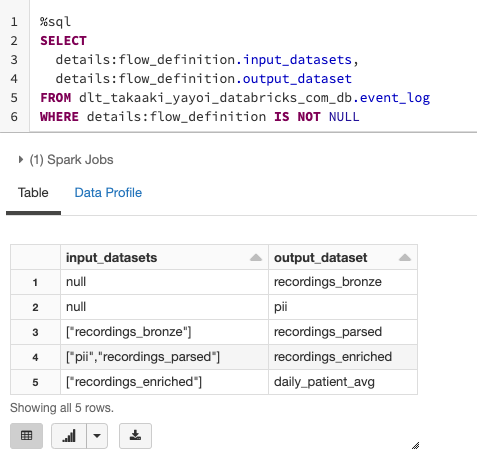
以下の様に、入力のデータセット、出力のデータセットのペアから構成されるリネージュを取得することができます。
SELECT
details:flow_definition.input_datasets,
details:flow_definition.output_dataset
FROM dlt_takaaki_yayoi_databricks_com_db.event_log
WHERE details:flow_definition IS NOT NULL
DLTのクラスターはどのように動作しますか?
- DLTのクラスターはDLT向けにカスタマイズされたクラスターです。クラスターライブラリは使用できないので、ライブラリをインストールするにはDLTノートブック内で
%pipしてください。 - クラスター自動停止の挙動はパイプラインのモード(Development/Production)で変わるので注意してください。Productionの場合Jobsクラスターと同じ挙動(ジョブが終了するとすぐに停止)となりますが、Developmentの場合は2時間のアイドル状態の後に停止されます。なので、ジョブにDLTを組み込む際には、必ずProductionモードになっていることを確認してください。