How To Build Data Pipelines With Delta Live Tables - The Databricks Blogの翻訳です。
多くのIT企業は、従来型の抽出、変換、ロード(ETL)プロセス - レポーティング目的でソースデータを従来型のデータウェアハウスやデータマートに移動し、変換するために定義された一連のプロセス - に慣れ親しんでいます。しかし、企業がより一層データドリブンになったことで、インタラクション、IoT、モバイルデータの様な多種多様かつ大量なデータが、企業におけるデータのランドスケープを一変させました。レイクハウスアーキテクチャを導入することで、IT企業はあらゆるデータを管理できる仕組みを手に入れることができ、アナリティクスや機械学習のためにバッチやリアルタイムで到着する大量データを処理できるようになります。
従来のETLの課題
概念的には、「従来型のデータウェアハウス実装でデータエンジニアが長年実行してきた何か」と言う様に、ETLパイプラインの構築は簡単に見えます。しかし、現在のモダンデータ要件によって、今やデータエンジニアはETLパイプラインの開発運用に加え、エンドツーエンドのETLのライフサイクル維持にも責任を持っています。彼らはデータパイプラインが全てのメンテナンス観点をクリアするようにするための、面倒かつ手動のタスクに対して責任を持っています。テスト、エラーハンドリング、復旧、再処理です。このことは、データエンジニアリングチームが信頼性の高いデータを利用するユースケースに応える際に直面する課題を明らかにします。
- 複雑なパイプラインの開発: データエンジニアは、テーブルの依存関係、復旧、バックフィル、リトライ、エラー条件を取り扱うETLライフサイクルの管理に多くの時間を費やしており、ビジネスロジックに時間を費やす時間がありません。シンプルなETLプロセスであっても、複雑なデータパイプラインの実装が必要になってしまいます。
- データ品質の欠如: 今では、データドリブンの意思決定においてデータは重要な戦略的企業資産となっています。しかし、単にデータを提供するだけでは、正しい意思決定ができるとは言えません。ETLプロセスはビジネス要件に応じたデータ品質を満たさなくてはなりません。多くのデータエンジニアは元の信頼性の低いデータに対応することなしに、アナリティクスや機械学習のためのデータを提供することに苦慮しており、結果として不正確な洞察、偏った分析、一貫性のないレコメンデーションを引き起こしています。
- エンドツーエンドのデータパイプラインのテスト: データエンジニアはデータパイプラインにおけるデータ変換のテストに責任を持ちます。エンドツーエンドのETLテストは、全ての適切な仮説と入力データの順番を取り扱う必要があります。データ変換のテストを適用することで、データパイプラインがスムースに実行されることが保証され、全てのソースデータのバリエーションに対してコードが適切に動作することを確認でき、コードの変更があった際のレグレッションを回避することができます。
- 異なるレーテンシーのデータ処理: データが生成されるスピードは、データエンジニアに対してデータパイプランをバッチで実装するか、連続的なストリーミングで実装するのかに対する決断を迫ります。入力データとビジネス要件に応じて、データエンジニアはデータパイプラインを書き直す必要なしに、柔軟にレーテンシーを変更できる柔軟性を必要とします。
- データパイプラインのオペレーション: データの規模や複雑性が増加し、ビジネスロジックが変化する際には、新たなバージョンのデータパイプラインがデプロイされる必要があります。データチームは、データ処理インフラストラクチャのセットアップ、スケールさせるためのコードの手動での作成、インフラストラクチャの再起動、パッチ適用、アップデートのサイクルに時間を費やします。これらすべては時間とコストの増加につながります。データ処理が失敗した際、データエンジニアはエラーを理解するために手動でログを走査し、データのクリーンアップ、リスタートポイントの特定を行います。これらの手動かつ時間を浪費するアクティビティは高価なものとなり、データパイプラインの再起動、アップグレードに関わる開発コストを増加させ、後段でのデータ活用のSLAを引き下げることになります。
自動インテリジェントETLに対するモダンアプローチ
データエンジニアリングチームは、上記の課題に対処し、適切なタイミングで高品質なデータを信頼性高く提供するために、ETLのライフサイクルを再考する必要があります。すなわち、高速で移動し続けるデータ要件に応えるためには、自動かつインテリジェントなETLに対する近代化アプローチが重要となります。
インテリジェントETLを自動化するために、データエンジニアはDelta Live Tables(DLT)を活用することができます。大規模データパイプラインの構築、テスト、運用を行うための高信頼ETLフレームワークを提供するDatabricksのレイクハウスプラットフォームにおける新たなクラウドネイティブなマネージドサービスです。
自動インテリジェントETLに対するDelta Live Tablesのメリット
ETLパイプラインの構築アプローチをシンプルかつモダンにすることで、Delta Live Tablesは以下のことを実現します。
- 宣言型ETLパイプライン: 低レベル言語でETLロジックを手書きするのではなく、データエンジニアは宣言型パイプラインを構築するためにSQL、Pythonを活用することができ、「どのようにする」ではなく「何をする」簡単に定義することができます。DLTを用いることで、DLTがパイプラインの全ての依存関係を管理しつつも、データ絵ジニアはどの様に変換を行い、どの様にビジネスロジックを適用するのかを指定することができます。これによって、連続的あるいはスケジュール処理によって、全てのテーブルに適切にデータが投入されることになります。例えば、テーブルのアップデートは後段の全てのテーブルのアップデートをトリガーします。
- データ品質: DLTはデータの品質、ビジネスルールへの準拠を確実インするために定義されるエクスペクテーション(期待)によってパイプラインを流れるデータフローを検証します。DLTは全ての品質チェックの結果を記録しレポートします。
- エラーハンドリング、リカバリー: DLTは一時的なエラーをハンドリングし、パイプラインのオペレーションで起きる一般的なエラーの大部分から復旧することができます。
- 継続、常時稼働プロセッシング: DLTを用いることで、複雑なストリーム処理や復旧ロジックを実装することなしに、ターゲットのテーブルをあらゆるレーテンシーでアップデートすることができます。
- パイプラインの可視化: DLTはグラフダッシュボード 上でパイプライン資産の全体的なステータスをモニターし、パフォーマンス、品質、ステータス、レーテンシーなどエンドツーエンドのパイプラインの健康状態を可視化します。これによって、パフォーマンス上のボトルネックやパイプラインの挙動を理解するために、実行時のデータトレンドを追跡することができます。
- シンプルなデプロイメント: DLTはクリック一つでパイプラインを実運用にデプロイしたり、ロールバックすることができるので、CI/CDプロセスを導入できる様にダウンタイムを最小化することができます。
5つのステップでデータエンジニアがインテリジェントデータパイプラインを実装する方法
自動化されたインテリジェントETLを達成するために、データエンジニアがDLTを用いてデータパイプランを実装するのに必要な5つのステップを見ていきましょう。
ステップ1: レイクハウスへのデータ取り込みの自動化
データエンジニアが直面する最も重要な課題は、構造化データ、非構造化データ、準構造化データのような様々なデータタイプのデータを、効率的かつ即時にレイクハウスに取り込むと言うものです。Databricksにおいては、トリガーや手動のスケジュールなどの追加の設定を行わずに、バッチやストリーミングモードを用い、レイクハウスにデータを低コスト、低レーテンシーで取り込むためにオートローダーを活用することができます。
オートローダーでは、データの到着を自動で検知し、インクリメンタルに新規ファイルを処理するcloudFilesと言うシンプルな文法を使用します。
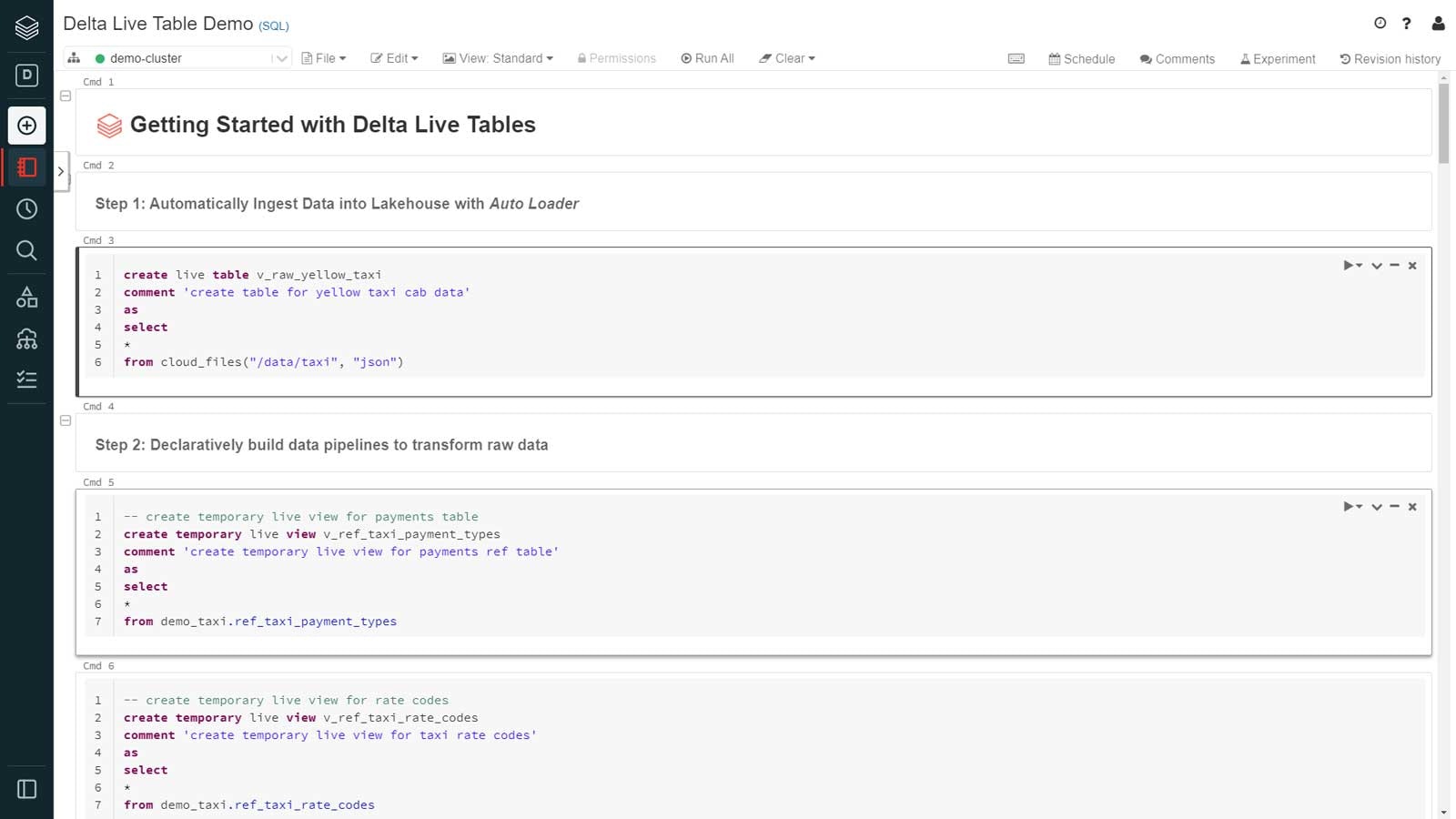
オートローダーは、到着データの構造に対する変更を自動で検知するので、スキーマの変更を追跡・対応する必要はありません。例えば、到着するデータが定期的に新たなカラムを追加している場合、レガシーなETLツールを使用しているデータエンジニアは多くの場合、パイプラインを停止し、コードを更新し再度デプロイする必要がありました。オートローダーを用いることで、スキーマエボリューションを活用でき、スキーマ更新のワークロードを処理することができます。
ステップ2: レイクハウスにおけるデータの変換
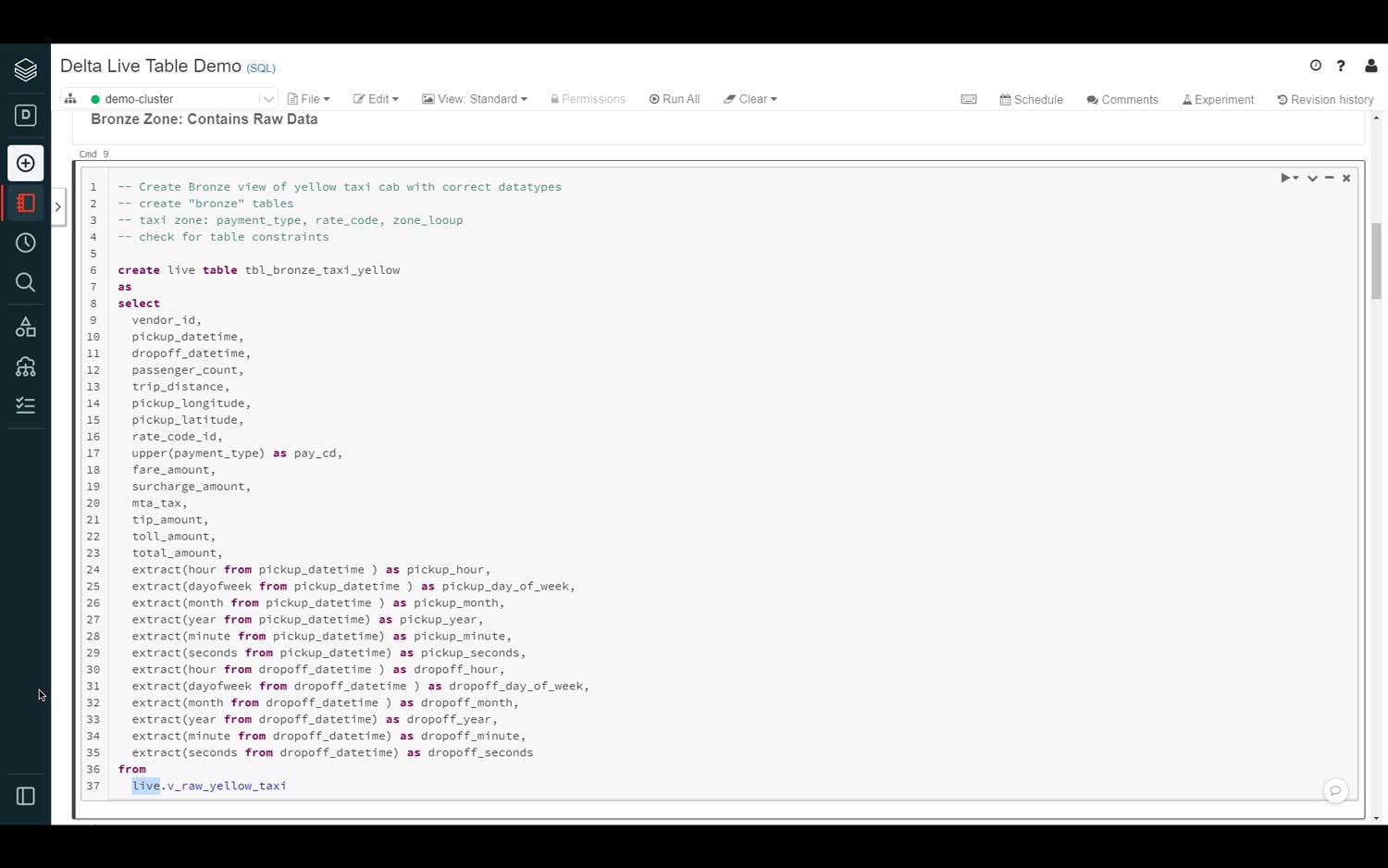
レイクハウスにデータを取り込んだので、データエンジニアは到着データに対して変換、あるいはビジネルロジックを適用する必要があります。分析、データサイエンス、機械学習に使える様に、生のデータを構造化データに変換します。
DLTでは、テーブル、ビューに生のデータをロードする前に変換を行う際、SQLやPythonの全てのパワーを活用することができます。データの変換には、いくつかのデータセットの結合、集計処理、ソート、新規カラムの追加、データフォーマットの変換、検証ルールの適用など複数のステップが含まれる場合があります。
ステップ3: レイクハウスにおけるデータ品質、完全性の保証
データ品質と完全性は、レイクハウスにおけるデータの全体的な一貫性を確保する際に重要となります。DLTにおいては、データエンジニアはカラムの値チェックの適用の様なDelta Expectationを指定することでデータパイプラインのデータ品質、データ完全性を定義することが可能になります。
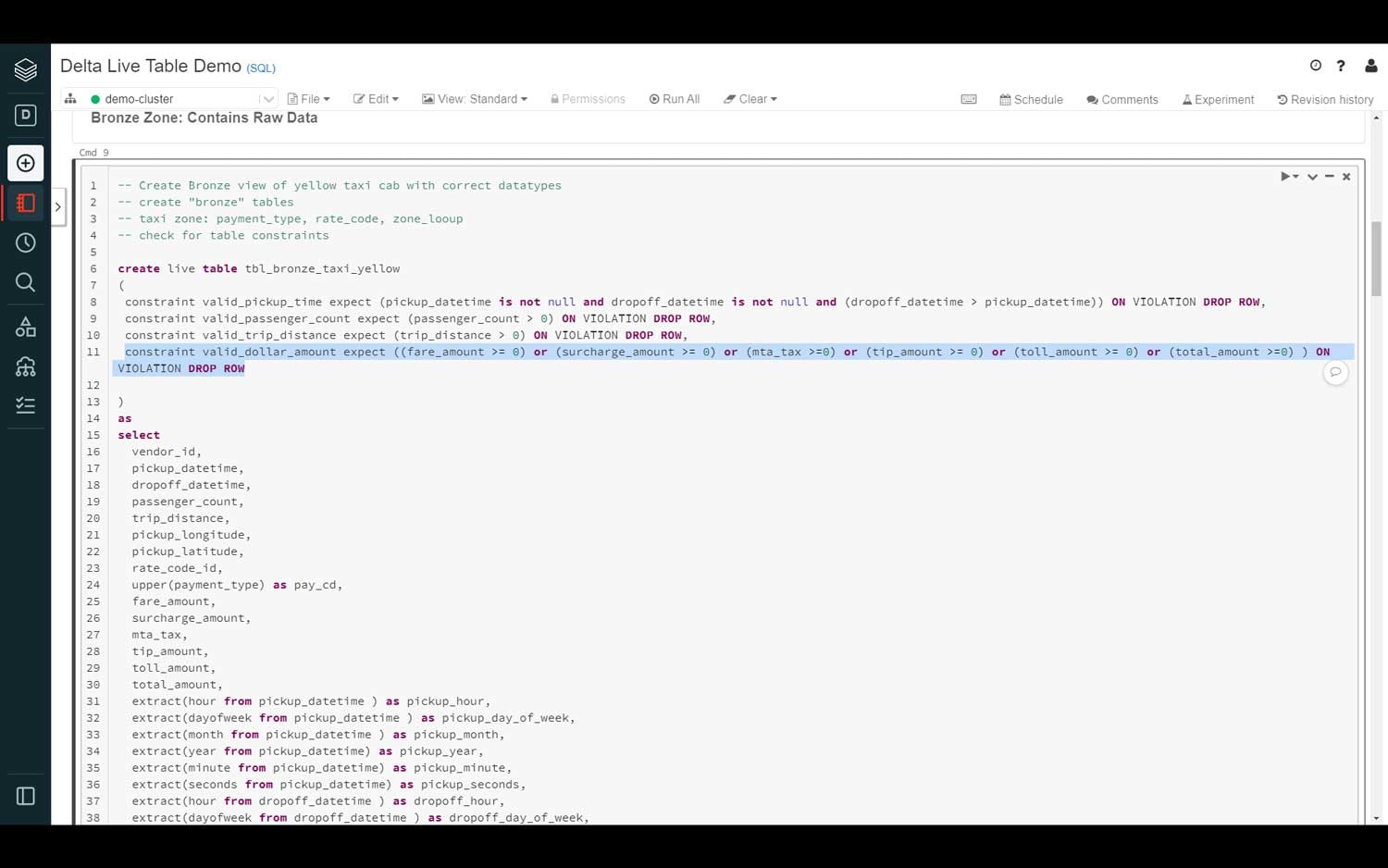
例えば、データエンジニアは入力日付カラムに対して、not nullそして一定の日付レンジに含まれる様に制約を作成することができます。この評価基準に合致しない場合、レコードは削除されます。以下の文法では、pickup_datetimeとdropoff_datetimeカラムはnot nullであることが期待され、dropoff_datetimeがpickup_datetimeより大きい場合、当該の行は削除されます。
データと検証の重要度に応じて、データエンジニアはパイプラインに対して、行の削除、行の許可、パイプラインの処理自体の停止を指示したいと考える場合があります。
constraint valid_pickup_time expect (pickup_datetime is not null and dropoff_datetime is not null and (dropoff_datetime > pickup_datetime)) ON VIOLATION DROP ROW
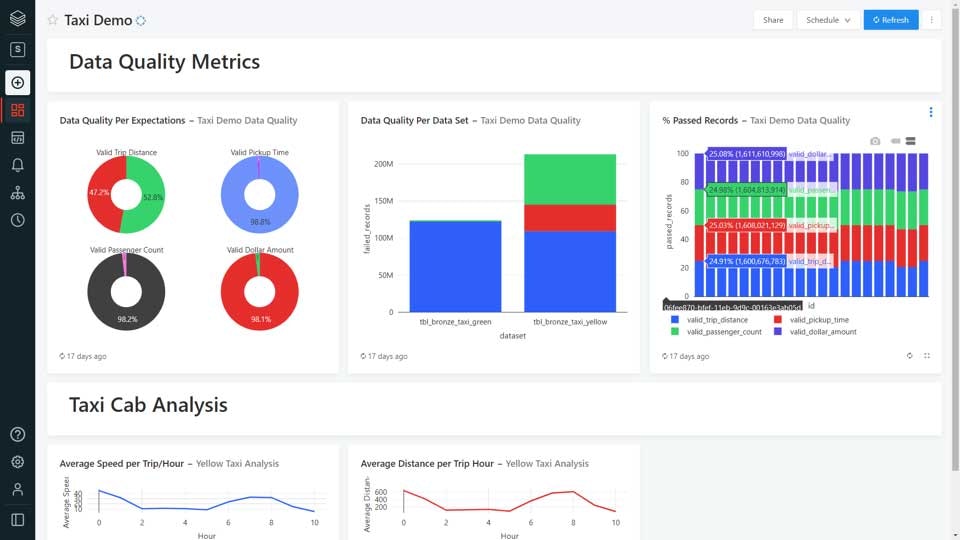
全てのデータ品質のメトリクスはデータパイプラインのイベントログに記録されるので、データパイプライン全体のデータ品質を追跡、レポートすることができます。可視化ツールを用いることで、データセットの品質、データ品質チェックをどれだけのレコードが通過したのか、除外されたのかを理解するために、レポートを作成することができます。
ステップ4: 自動化されたETLのデプロイおよびオペレーション
現在のデータ要件においては、本格運用へのデプロイをアジャイルかつ自動で行うことが重要となります。データチームは車輪の再発明を行うのではなく、適切なデータを用い、パイプラインをテンプレート化し、成長し続けるビジネス要件に応えるために低レベルの手書きのコードを書かずにすむ様に抽象化を行います。
データパイプラインをデプロイする際には、DLTはパイプラインで定義されたテーブル、ビューの意味を理解し、表示するためのグラフを生成します。このグラフは、どの様にデータが流れ、どの様にインパクト分析に使用されるのかを示す、高品質、高精度のリネージュダイアグラムを生成します。さらに、DLTはエラー、依存関係の欠如、文法エラーをチェックし、データパイプラインで定義されたテーブル、ビューのリンクを自動で作成します。
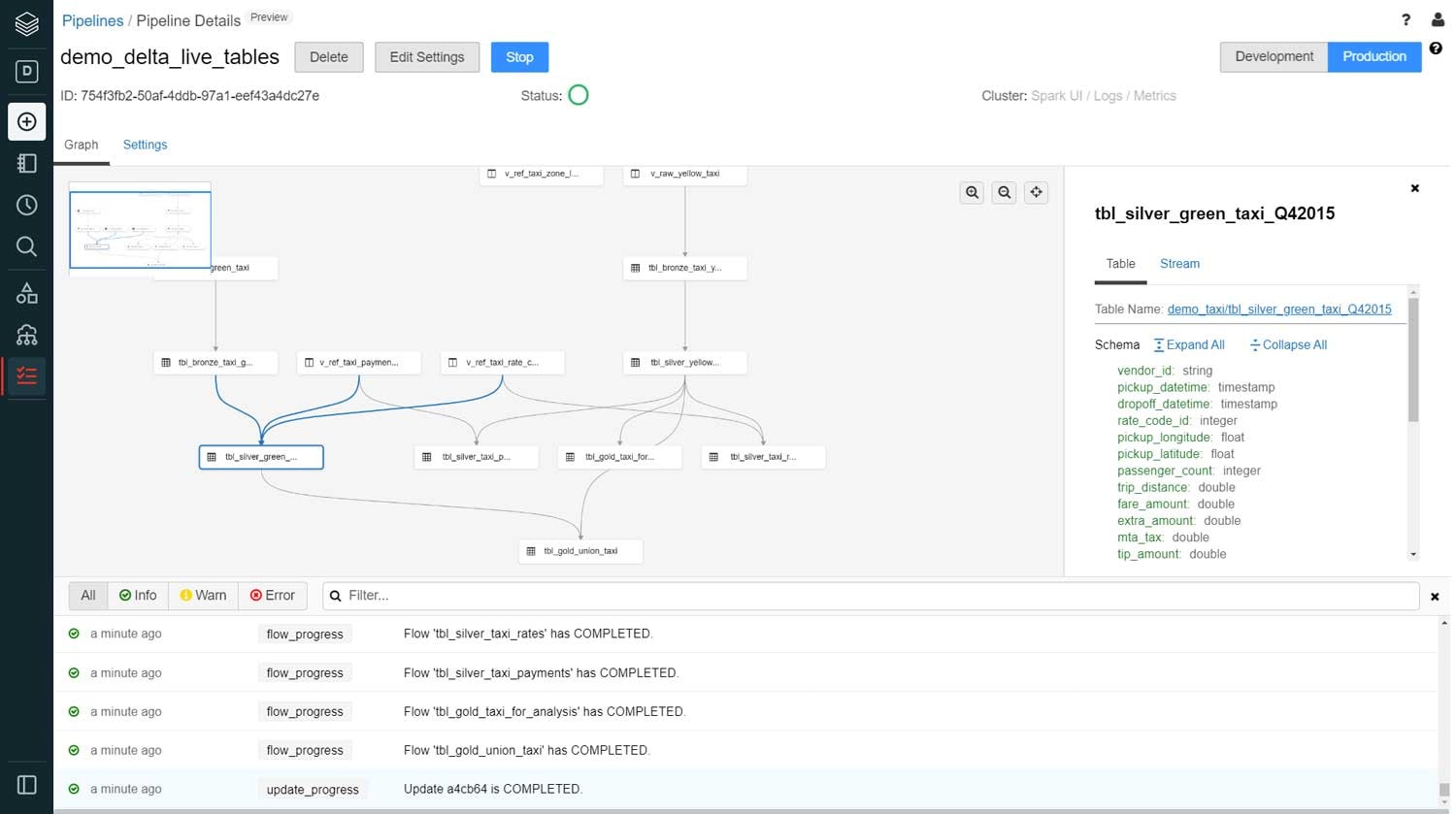
検証が完了すると、DLTは高性能、スケーラブルなApache Spark™互換の計算エンジン上でパイプラインを実行します。大規模ETLワークロードの実行に必要な最適化クラスターの作成を自動化します。そして、DLTは最新のデータを用いてETLで定義されたテーブル、ビューを作成・更新します。
ワークロードの実行の際、DLTはパイプラインの詳細、パイプラインの性能、ステータスをイベントログテーブルに行レベルで記録します。処理されたレコード数、パイプラインのするイープっと、環境設定などの詳細は、データエンジニアリングチームによってクエリー可能なイベントログに格納されます。
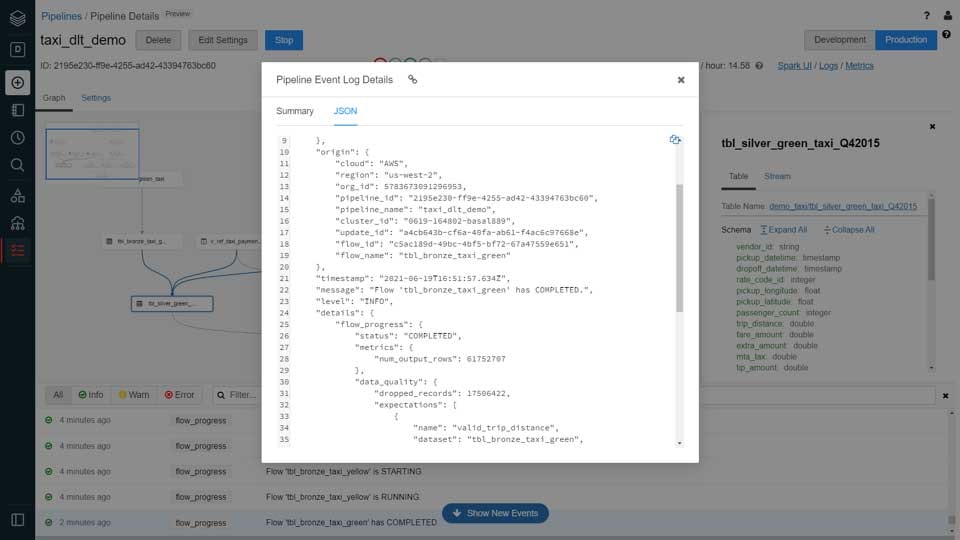
システム障害のイベントにおいては、DLTは自動でパイプラインを停止・起動します。データパイプラインのオペレーションを手動で管理したり、チェックポイントを作成するコードを作成する必要はありません。DLTはデータパイプラインの再起動、バックフィル、最初からのパイプラインの再実行や新規バージョンのパイプラインのデプロイに必要となる全ての複雑な事柄を自動で管理します。
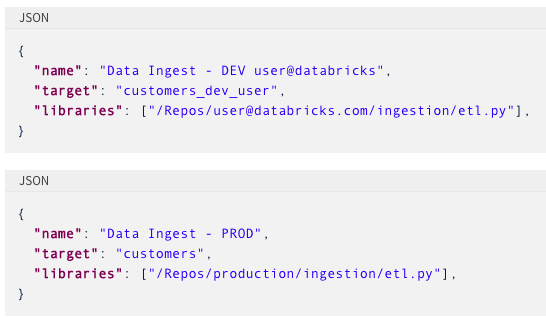
ある環境から別の環境にDLTパイプラインをデプロイする際、例えば、開発環境から、テスト環境、本番運用に移行する際、ユーザーはデータパイプラインのパラメータ化を活用することができます。設定ファイルを用いることで、デプロイされる環境固有のパラメータを指定することができるので、同じパイプライン、変換ロジックを再利用できます。
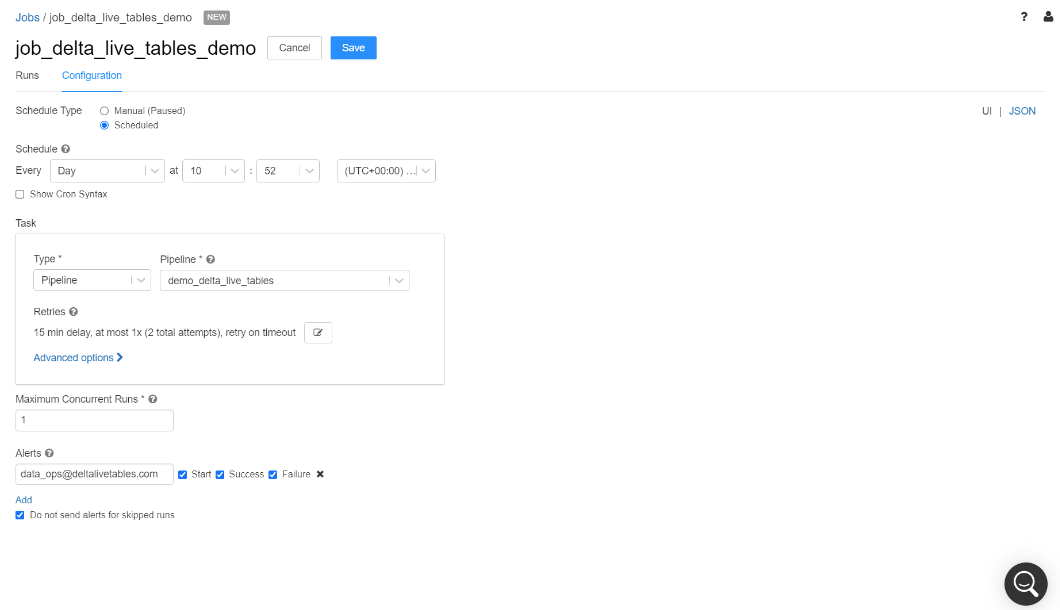
ステップ5: データパイプラインのスケジューリング
最後に、データエンジニアはETLワークロードをオーケストレーションする必要があります。DLTパイプラインはDatabricksのジョブでスケジューリングすることができるので、エンドツーエンド、プロダクションレディのパイプラインの実行の完全自動化をサポートしています。Databricksのジョブでは、データエンジニアがETLワークロードを定期的にスケジュールできる様になっており、ジョブが成功・失敗した際に通知を行う様に設定することができます。
振り返り
企業がデータドリブンになることを渇望するにつれ、データエンジニアリングは成功のための重要な鍵となっています。信頼性のあるデータを提供するために、データエンジニアはエンドツーエンドのETLライフサイクルを手動で開発、維持するために時間を費やすべきではありません。データエンジニアリングチームは、ETLの開発をシンプルにし、データの信頼性を改善し、オペレーションを管理するための、効率的、スケーラブルな方法を必要としています。
Delta Live Tablesは全てのデータの依存関係を自動で管理することで、自動リカバリーを含むパイプラインオペレーションに対する深い可視性、モニタリングを伴うビルトインの品質コントロールを活用し、ETLライフサイクルの管理に伴う複雑な事柄を抽象化します。これにより、データエンジニアリングチームは、アナリティクス、データサイエンス、機械学習に高価値のデータをバッチ・ストリーミングで提供するために、SQL・Pythonのみを用いて容易かつ迅速に信頼性の高いエンドツーエンド、プロダクションレディのデータパイプラインの構築にフォーカスすることができます。
次のステップ
いくつかのリソースをチェックいただき、準備ができたら、以下のリンクからDLTサービスを申し込んでください。