Delta Live TablesでUDF(ユーザー定義関数)を活用して、複雑な処理を組み込んだり、複雑な条件でデータチェックを行う方法を説明します。
Delta Live Tablesとは
Delta Live TablesはDelta LakeをベースとしたETLパイプライン開発・運用のためのツールです。
PythonあるいはSQLにおいて、宣言型の文法でデータパイプラインを定義し、ジョブのように実行する形を取ります。詳細は以下のリンク先をご覧ください。
例えば、Pythonであれば、以下のように記述を行うことでデータパイプラインを定義することができます。
from pyspark.sql.functions import *
from pyspark.sql.types import *
json_path = "/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json"
@create_table(
comment="The raw wikipedia click stream dataset, ingested from /databricks-datasets.",
table_properties={
"quality": "bronze"
}
)
def clickstream_raw():
return (
spark.read.json(json_path)
)
@create_table(
comment="Wikipedia clickstream dataset with cleaned-up datatypes / column names and quality expectations.",
table_properties={
"quality": "silver"
}
)
@expect("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
@expect_or_fail("valid_count", "click_count > 0")
def clickstream_clean():
return (
read("clickstream_raw")
.withColumn("current_page_id", expr("CAST(curr_id AS INT)"))
.withColumn("click_count", expr("CAST(n AS INT)"))
.withColumn("previous_page_id", expr("CAST(prev_id AS INT)"))
.withColumnRenamed("curr_title", "current_page_title")
.withColumnRenamed("prev_title", "previous_page_title")
.select("current_page_id", "current_page_title", "click_count", "previous_page_id", "previous_page_title")
)
@create_table(
comment="A table of the most common pages that link to the Apache Spark page.",
table_properties={
"quality": "gold"
}
)
def top_spark_referrers():
return (
read("clickstream_clean")
.filter(expr("current_page_title == 'Apache_Spark'"))
.withColumnRenamed("previous_page_title", "referrer")
.sort(desc("click_count"))
.select("referrer", "click_count")
.limit(10)
)
@create_table(
comment="A list of the top 50 pages by number of clicks.",
table_properties={
"quality": "gold"
}
)
def top_pages():
return (
read("clickstream_clean")
.groupBy("current_page_title")
.agg(sum("click_count").alias("total_clicks"))
.sort(desc("total_clicks"))
.limit(50)
)
このノートブックをDelta Live Tablesのパイプラインとして登録し、実行すると以下のようなDAGが表示され処理が行われます。

Delta Live TablesにおけるUDFの活用
PythonやSQLを用いることで、柔軟にロジックを記述することはできるのですが、どうしても処理を共通化したい、SQLで表現できない条件をPythonで定義して呼び出したい、というようなニーズが出てきます。このような場合、UDF(User Defined Function)を定義することで、これらのニーズに応えることができます。
例えば、以下のようにPythonノートブック(呼び出し先)でUDFを定義します。最初の関数は計算を行うUDF、後者は判定を行うUDFとなります。UDFを登録する際には、戻り値の型を指定していることに注意してください。
from pyspark.sql.types import IntegerType
def square(i: int) -> int:
"""
指定されたパラメーターを二乗するシンプルなUDF
:param i: Pyspark/SQLのカラム
:return: パラメーターの二乗
"""
return i * i
spark.udf.register("makeItSquared", square, IntegerType()) # Spark SQLで使用する二乗計算udfを登録
from pyspark.sql.types import BooleanType
def is_even(i: int) -> bool:
"""
偶数かどうかを判定するシンプルなUDF
:param i: Pyspark/SQLのカラム
:return: 偶数の場合True
"""
if i % 2 == 0:
return True
else:
return False
spark.udf.register("passOnlyEven", is_even, BooleanType()) # Spark SQLで使用する偶数判定udfを登録
そして、UDFの呼び出しを行うパイプライン(呼び出し元)を定義します。
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
@dlt.table
def raw_data():
return spark.sql("SELECT id, makeItSquared(id) AS numSquared FROM RANGE(10)")
@dlt.table
@dlt.expect_or_drop("even_only", "passOnlyEven(numSquared) = True")
def squared_even():
return (
dlt.read("raw_data")
)
こちらはSQLバージョンです。
CREATE LIVE TABLE raw_data
AS SELECT id, makeItSquared(id) AS numSquared FROM RANGE(10);
CREATE LIVE TABLE squared_even
(CONSTRAINT even_only EXPECT (passOnlyEven(numSquared) = True) ON VIOLATION DROP ROW)
AS SELECT id, makeItSquared(id) AS numSquared FROM live.raw_data
今回のケースでは、本データのidを二乗したものをnumSquaredとし、numSquaredが偶数のレコードのみを通過させるというパイプラインを構築しています。
パイプラインを作成する際には、呼び出し先と呼び出し元のノートブックの両方をNotebook Librariesに追加する必要があります。
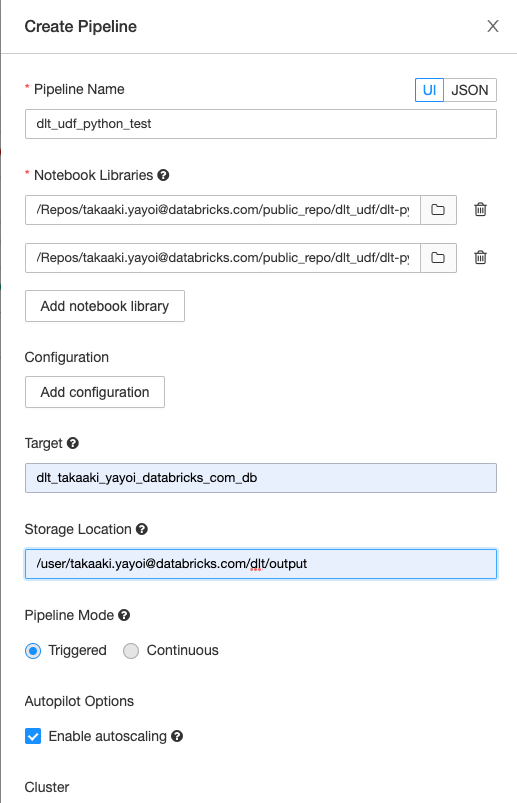
このようにすることで、UDFの柔軟性、モジュール性を活用して複雑なパイプラインを構築することが可能となります。
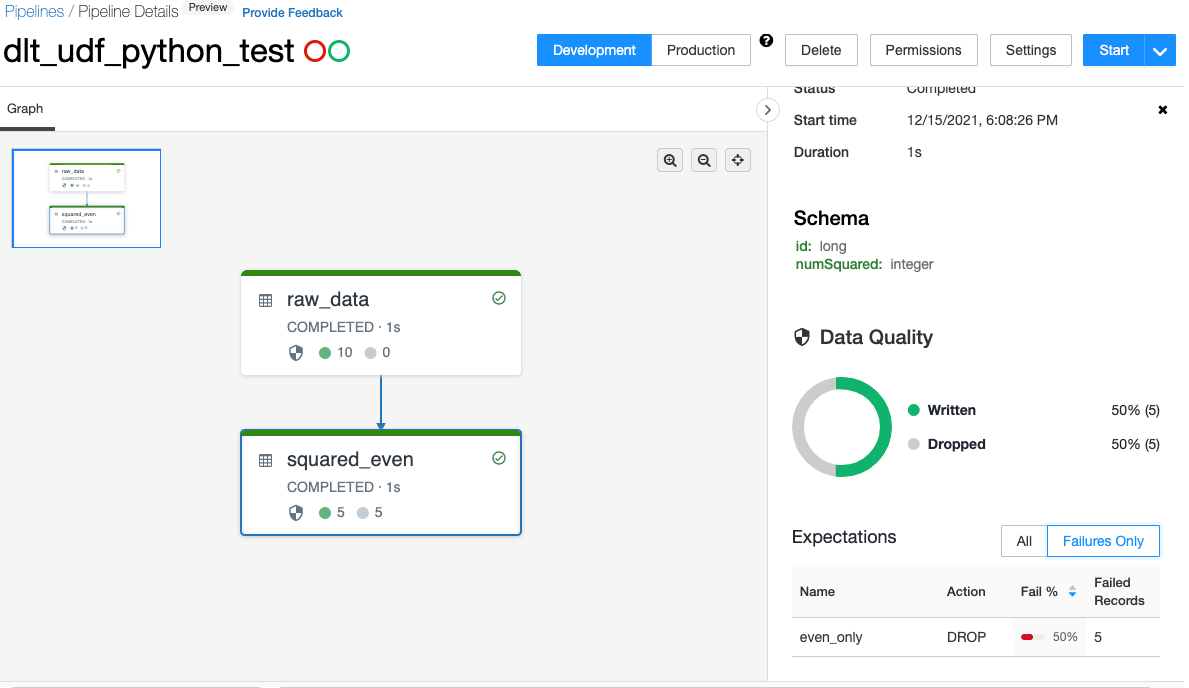
パイプラインの終端のテーブルを確認すると、期待通りのデータになっていることがわかります。
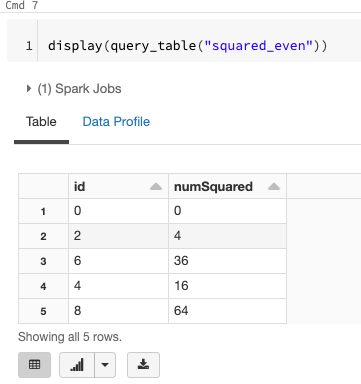
サンプルノートブック