簡単そうに見えなくもないですが、いくつか選択肢があるのでそれぞれの良し悪し含めてウォークスルーしていきます。
マニュアルはこちらですが、それほど親切ではありません(すみません、あとで修正します)。
以下の2つの観点で選択肢を検討する必要があります。
- DatabricksからS3へのアクセス方法
- S3からDatabricksへの取り込み
S3の準備
AWSのコンソールからS3バケットを作成します。ここではtaka-uc-external-location-bucketという名前にしています。

適当なCSVファイルをアップロードしておきます。

DatabricksからS3へのアクセス
Databricksから既存のS3バケットにアクセスするには以下の設定が必要です。
- ストレージ認証情報: DatabricksからS3へのアクセスを許可するIAMロールをラッピングするオブジェクトです。
- 外部ロケーション: アクセスを許可するS3のパスと上記のストレージ認証情報をラッピングするオブジェクトです。
そして、アクセスの方法としては上記の外部ロケーション経由でアクセスするか、ボリュームとして設定してアクセスするかの選択肢があります。
外部ロケーションの作成
まずは、外部ロケーションから作成します。
Databricksカタログエクスプローラでの作業
カタログエクスプローラの外部データ > 外部ロケーションにアクセスし、右上のロケーションを作成をクリックします。

AWSクイックスタートを選択して、次のページをクリックします。

注意
AWSクイックスタートの方法の場合には、ストレージ認証情報の作成をスキップできます。手動の場合は、ご自身でストレージ認証情報を作成する必要があります。
バケット名にs3://taka-uc-external-location-bucketを指定して、下にある新規トークンを生成をクリックします。

表示されるパーソナルアクセストークンをコピーしておきます。この後のCloudFormationテンプレートで指定します。
警告
- パーソナルアクセストークンは厳重に管理してください。
- このパーソナルアクセストークンは60分で無効になるので、それまでに次のステップを完了してください。
クイックスタートで開始をクリックします。
AWSコンソールでの作業
AWSコンソールにログインしていない場合にはログインします。

CloudFormationのテンプレートが表示されます。
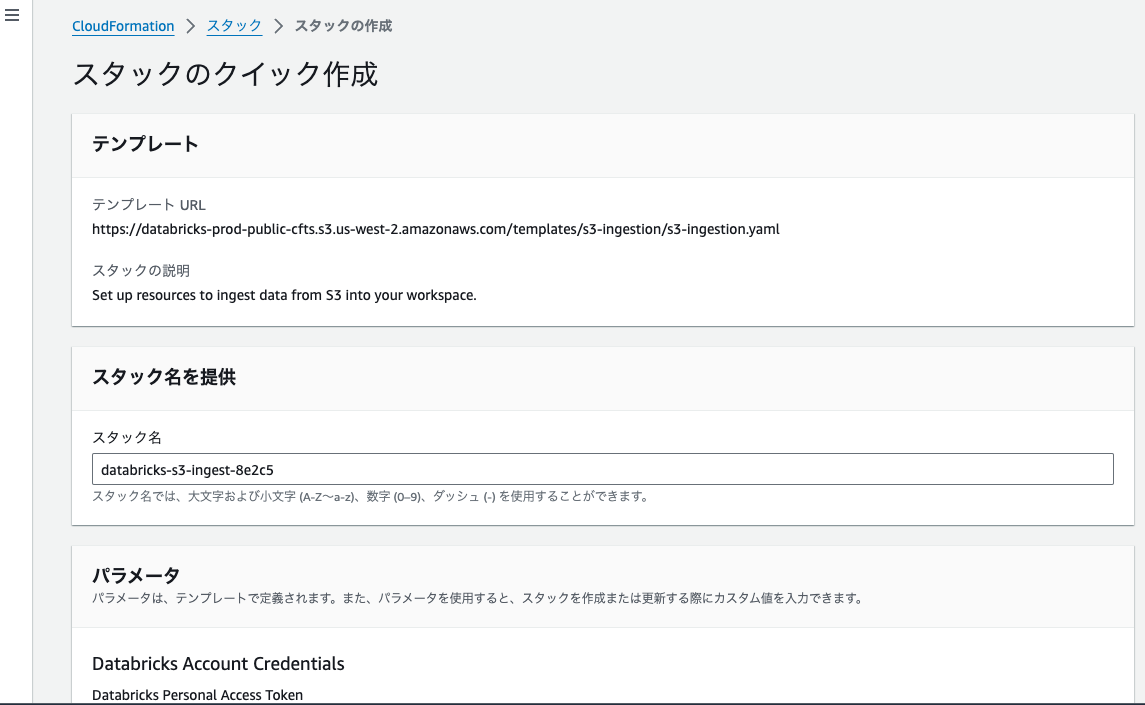
Databricks Personal Access Tokenに上のステップでコピーしたパーソナルアクセストークンを貼り付けます。


機能の部分のチェックをつけて、スタックの作成をクリックするとスタックの構築がスタートします。

CREATE_COMPLETEになるまで待ちます。

Databricksカタログエクスプローラでの動作確認
CREATE_COMPLETEになったら、Databricksのカタログエクスプローラに戻ってOKをクリックします。

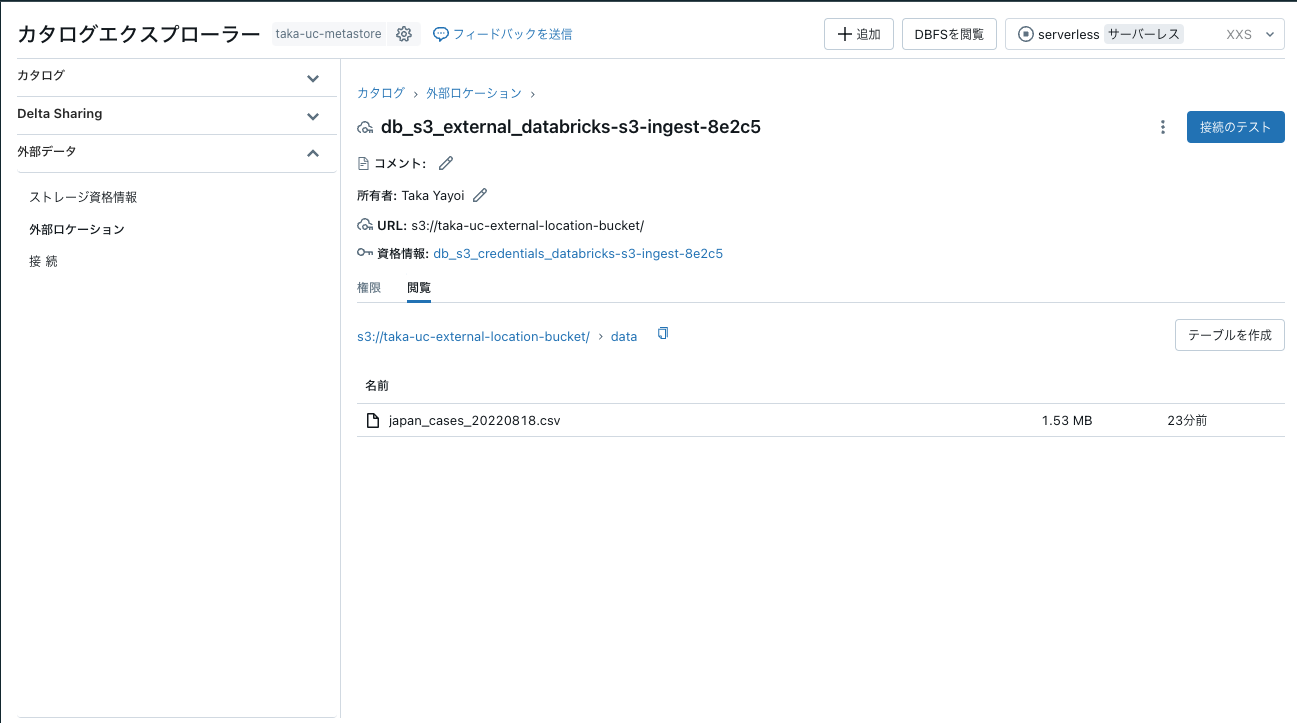
これで外部ロケーションが作成されました。

接続のテストをクリックします。

テストが通過したらOKです。

閲覧タブでもCSVファイルを確認できるはずです。
この時点でもノートブックからCSVにアクセスすることは可能です。
df = spark.read.csv("s3://taka-uc-external-location-bucket/data/japan_cases_20220818.csv", header=True)
display(df)

ただ、外部ロケーションの場合、s3://のプレフィクスを用いてアクセスするので、pandasやシェルからはアクセスできません。そこでボリュームの出番です。外部ロケーションを外部ボリュームとして設定することで、以下のようなメリットを享受できます。
- 言語やAPIを問わずに統一されたパスでファイルにアクセスできるようになります。
- カタログエクスプローラのUIから簡単にファイルを追加することができます。
- ファイルの格納場所をUnity Catalogのカタログ、スキーマの枠組みで整理できます。
ボリュームの作成
カタログエクスプローラで適当なカタログ、スキーマを選択します。右上の作成 > ボリュームを作成をクリックします。

ボリュームの名称を入力し、外部ボリュームを選択します。

上のステップで作成した外部ロケーションを選択します。

作成をクリックします。これで外部ボリュームが作成されました。なお、ボリュームには/Volumes/<カタログ名>/<スキーマ(データベース)名>/<ボリューム名>/というパスでアクセスできます。

CSVファイルも確認できます。

カタログエクスプローラからファイルの追加も可能です。

追加されたファイルはAWSのコンソールでも確認できます。

S3からDatabricksへの取り込み
ここまでのステップで、DatabricksからCSVを格納しているS3にボリューム経由でアクセスできるようになりました。
df = spark.read.csv("/Volumes/main/ingested_s3/csv_volume/data/japan_cases_20220818.csv", header=True)
display(df)

しかし、この状態では常にパスを意識する必要がありますし、SQLを使うのも困難です。おすすめはカタログにテーブルとして登録するというものになります。これによって、リネージ、行列レベルのアクセス権、モニタリングなどのUnity Catalogの様々な機能を活用できるようになります。
df = spark.read.csv("/Volumes/main/ingested_s3/csv_volume/data/japan_cases_20220818.csv", header=True)
df.write.saveAsTable("main.ingested_s3.covid_data")
これでカタログにテーブルが登録されましたので、SQLでも容易にアクセスできるようになります。

df = spark.sql("SELECT * FROM main.ingested_s3.covid_data")
display(df)
%sql
SELECT * FROM main.ingested_s3.covid_data

まとめ
| 観点 | おすすめ |
|---|---|
| DatabricksからS3へのアクセス方法 | ボリューム経由でのアクセス |
| S3からDatabricksへの取り込み | カタログ配下のテーブルとして取り込み |
ご活用ください!