こちらの社会人コースの講義資料です。
以前は生成AIによる情報システムへのインパクトというお題で講義して、情報システム開発のライフサイクルの各フェーズで生成AIが関係してくるのかのお話をして、主にバイブコーディングのデモやハンズオンを行いました。
今回はデータサイエンスということで、前回のものをベースにしていますが結構データサイエンス固有の話もあるんだなと思った次第です。
以下のアジェンダでお送りしました。
- Databricksのご紹介
- 生成AIとは
- Databricksと生成AIの融合
- データサイエンスプロセスの変革
- 生成AIを用いたデータサイエンスの実践
- まとめ
事前課題
Databricks Free Editionでアシスタントの使い方に慣れ親しんでいただきます。
Databricksのご紹介
Databricksが初めての方もいらっしゃるので会社紹介から。

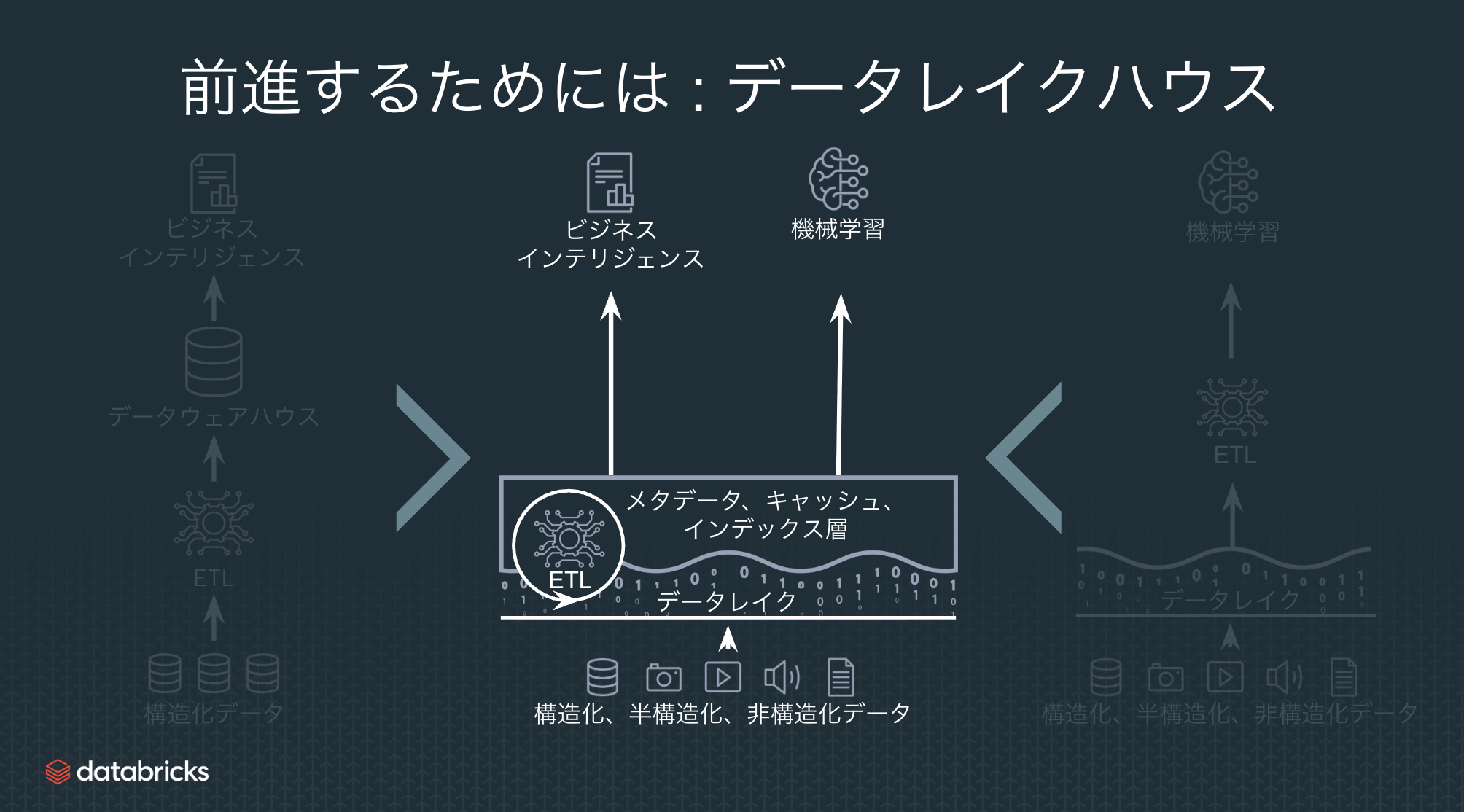
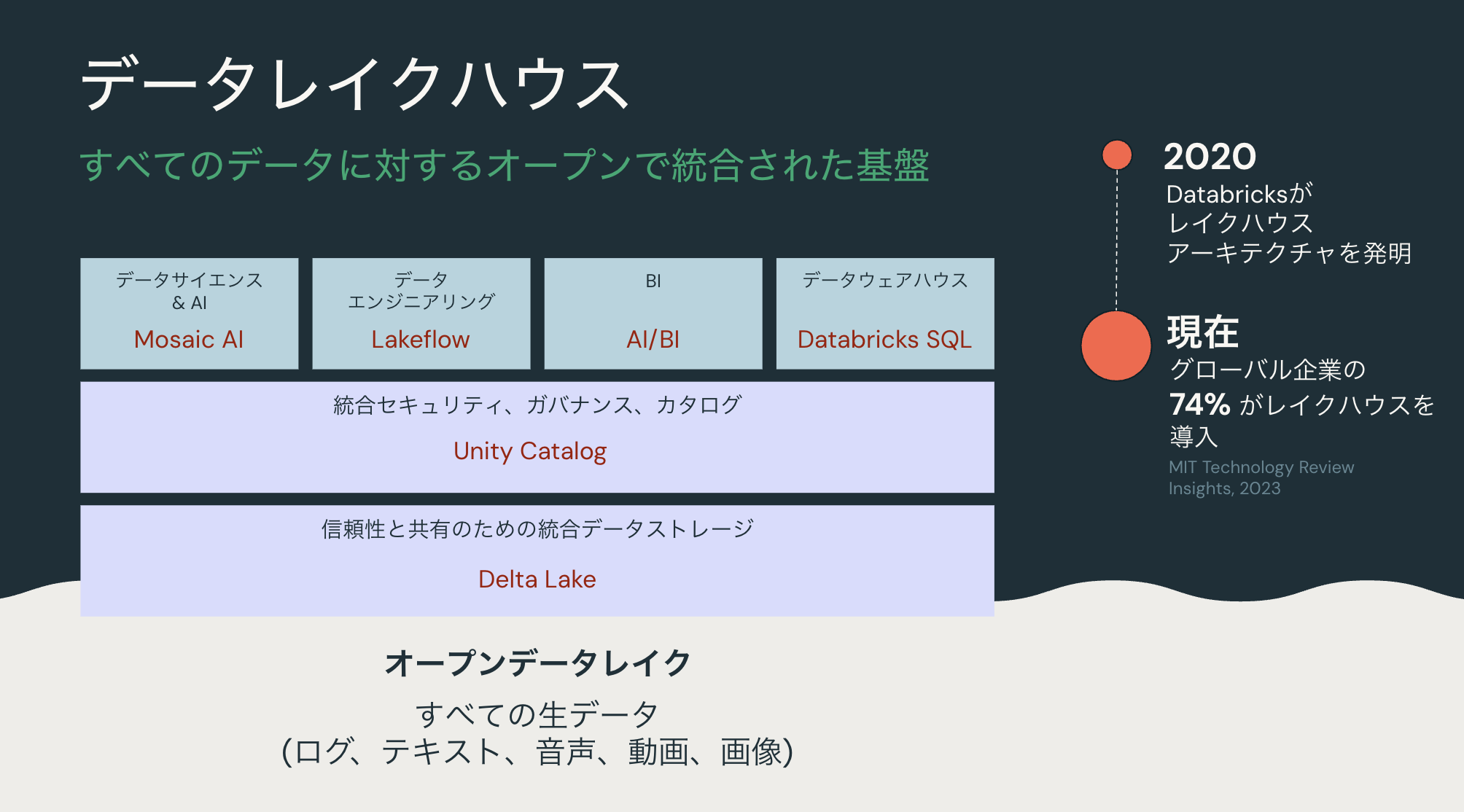
レイクハウスの説明。
生成AIとは
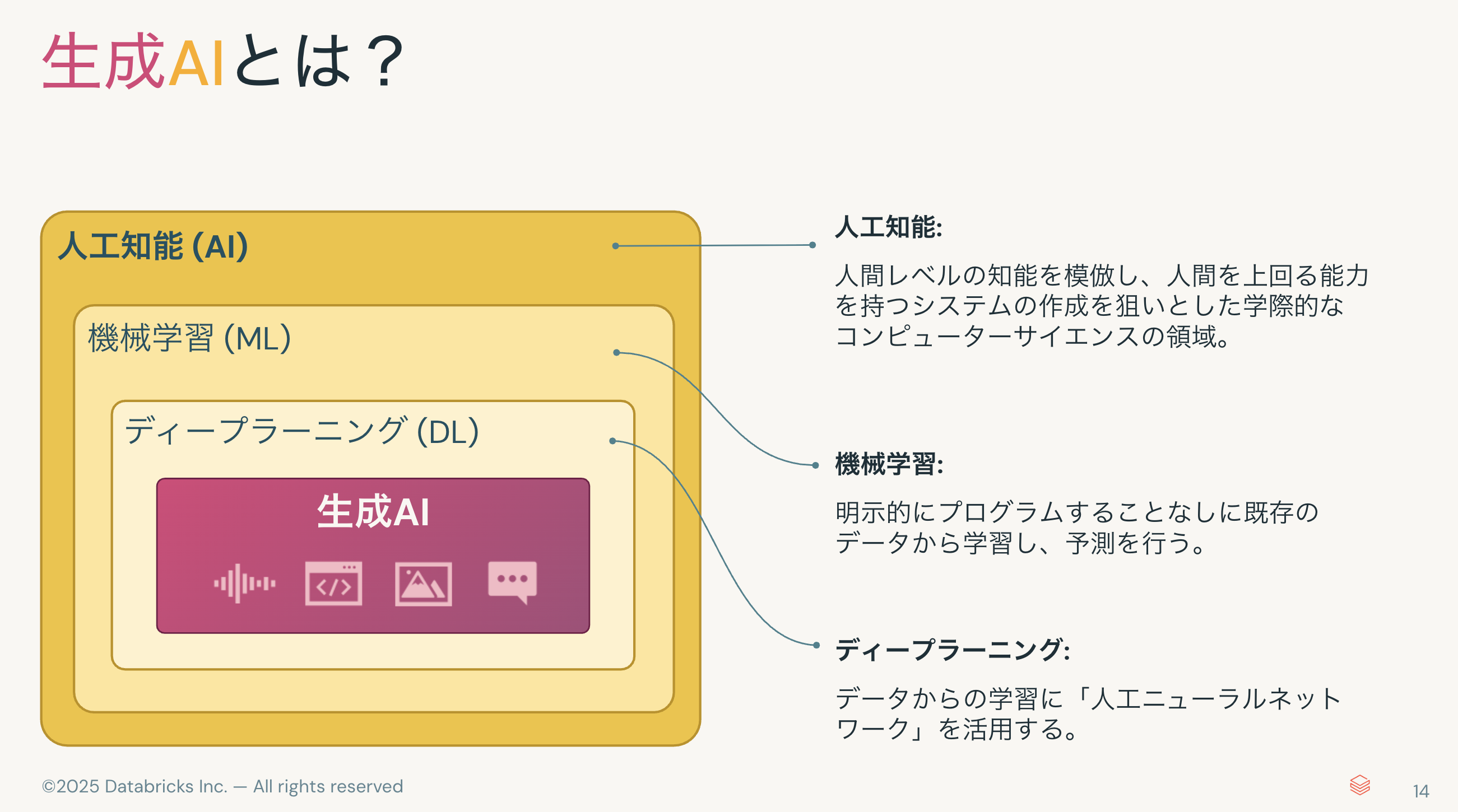
一般論から。
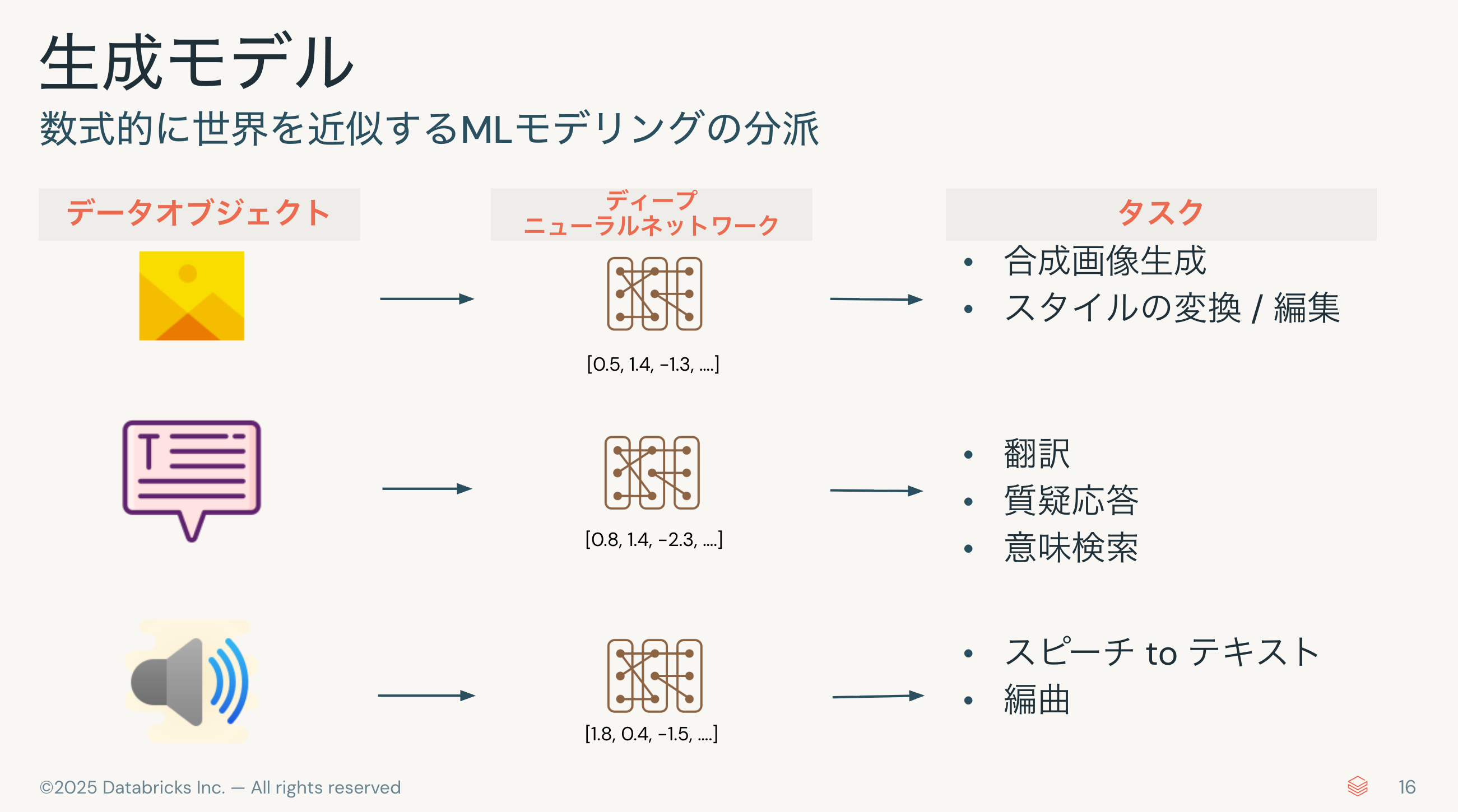
なぜ今、生成AIなのか。

Databricksと生成AIの融合
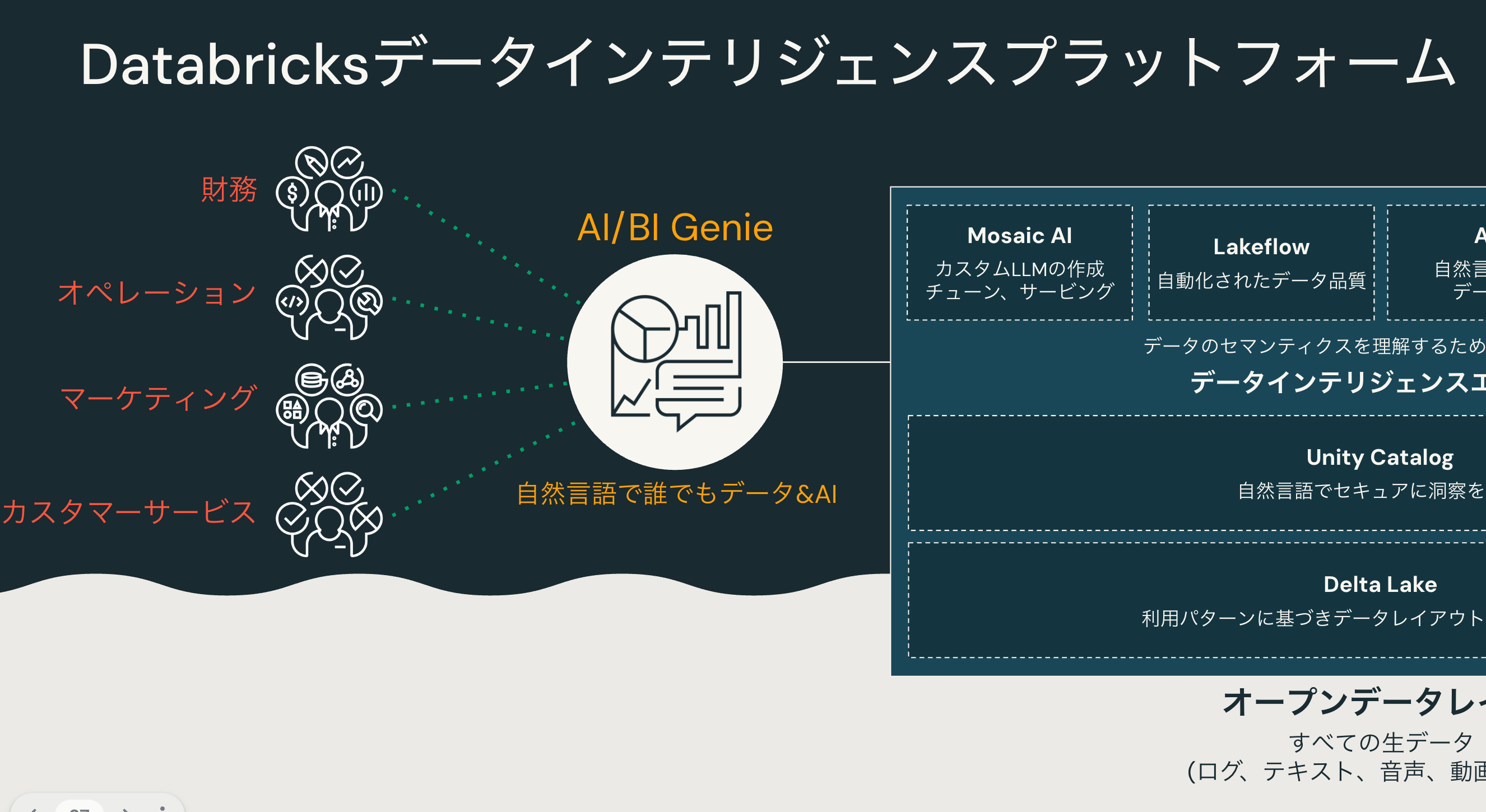
Databricksと生成AIの概要を説明した上でこれらの二つの関係性を説明します。
約2年前にDatabricksのレイクハウスに生成AIを組み込むという決断をしました。結果として名称もデータインテリジェンスプラットフォームに変更しています。

生成AIを組み込むということには2つの意味があります。
- 生成AIを活用したシステムを容易に構築できるようにする
- 生成AIを活用してデータ分析やデータ処理を効率的にする
前者はRAGやエージェントシステムの構築、運用の話ですが、今日は2つ目の観点がメインとなります。
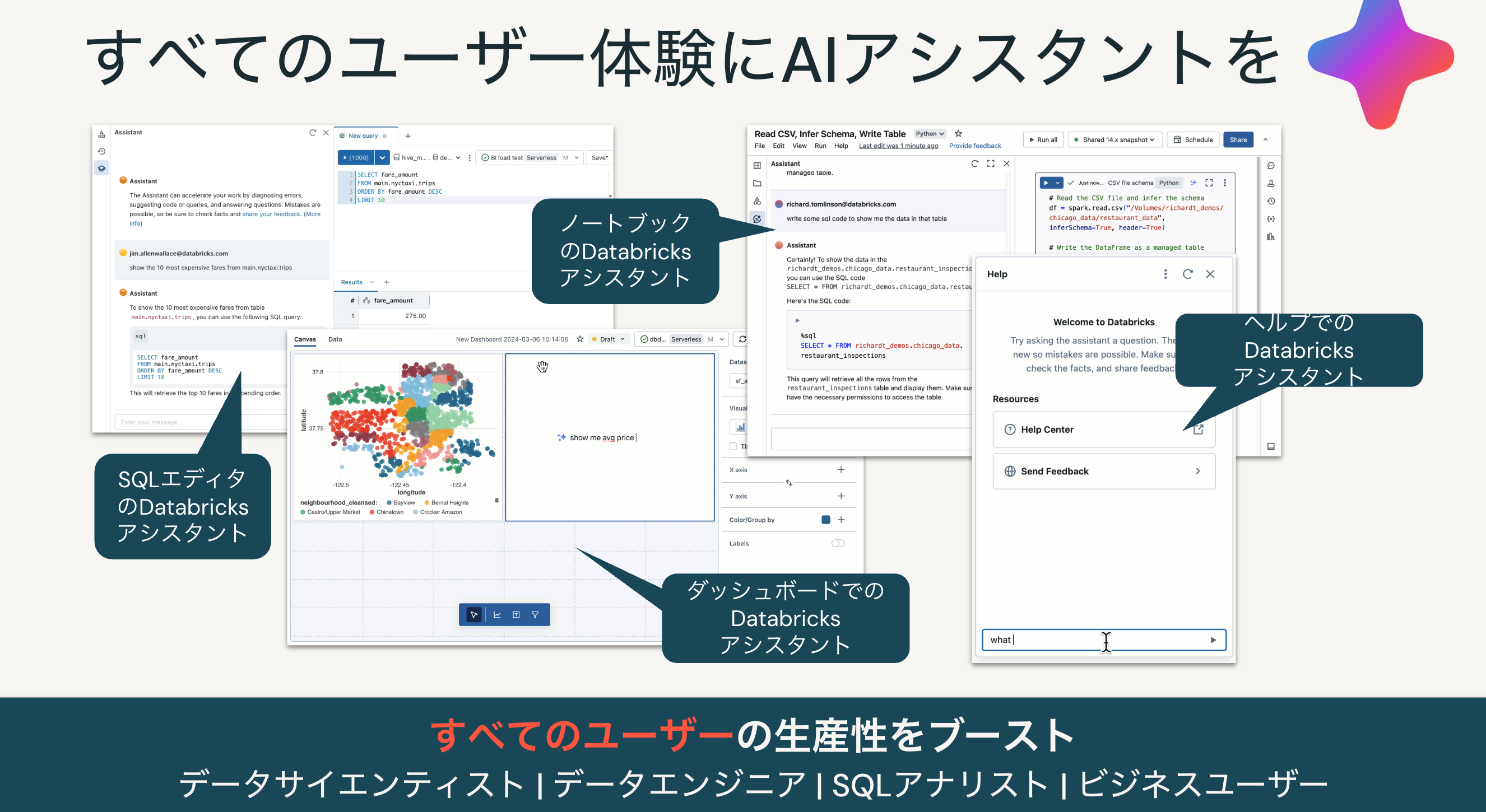
Databricksのプラットフォームのあらゆる場所に生成AIが組み込まれることで、これまでは困難だった日本語でのやり取りを通じたデータ分析が可能となっています。

さらにはGenieを活用することで、完全日本語でデータに対する問い合わせ、データの可視化も可能になっています。ただ、今日はノートブックとAIアシスタントの組み合わせを体験していただきます。
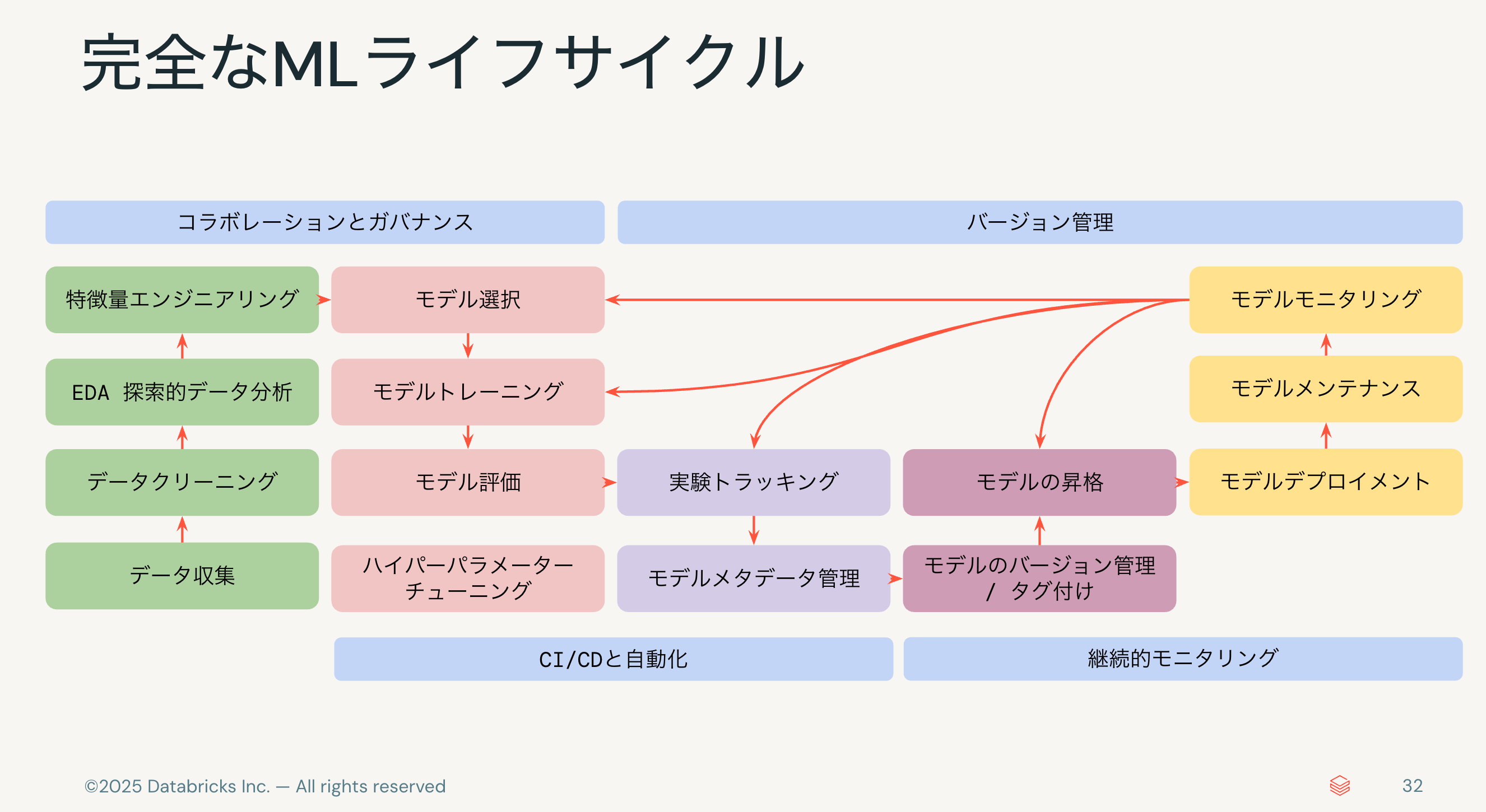
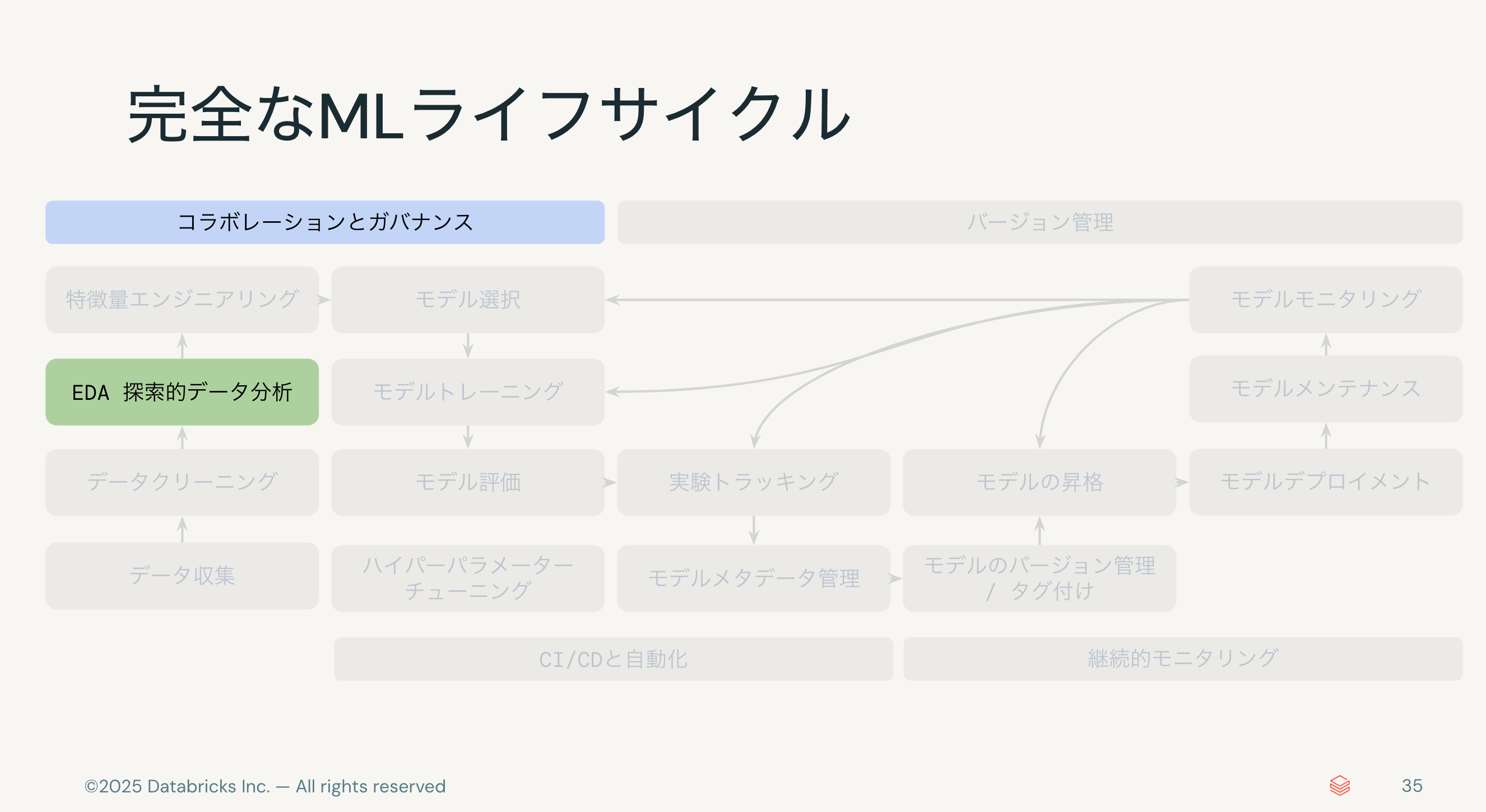
DatabricksではMLライフサイクル全体をサポートする機能を提供していますが、今日は左側のEDAやモデル構築あたりまでをカバーします。
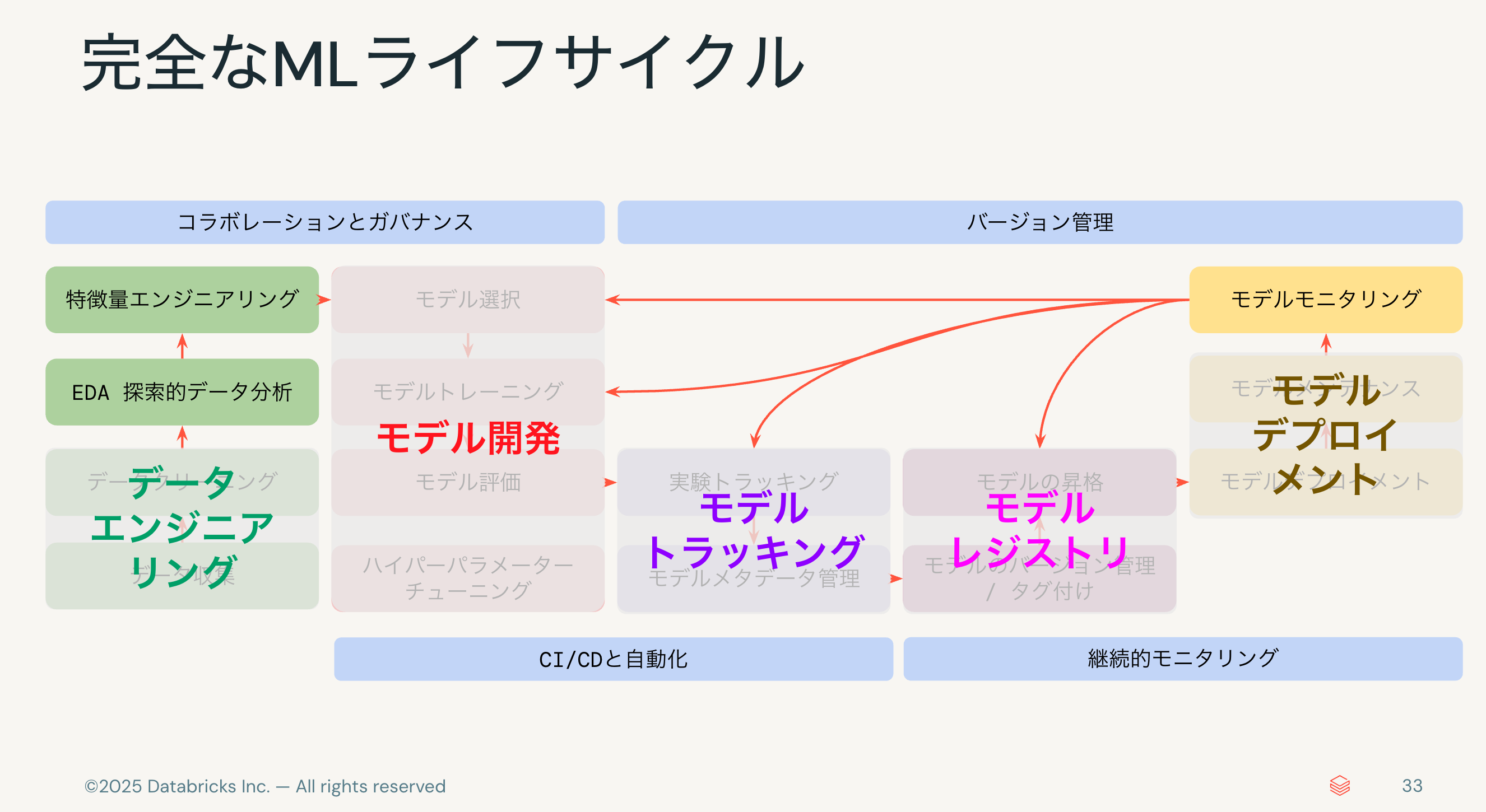
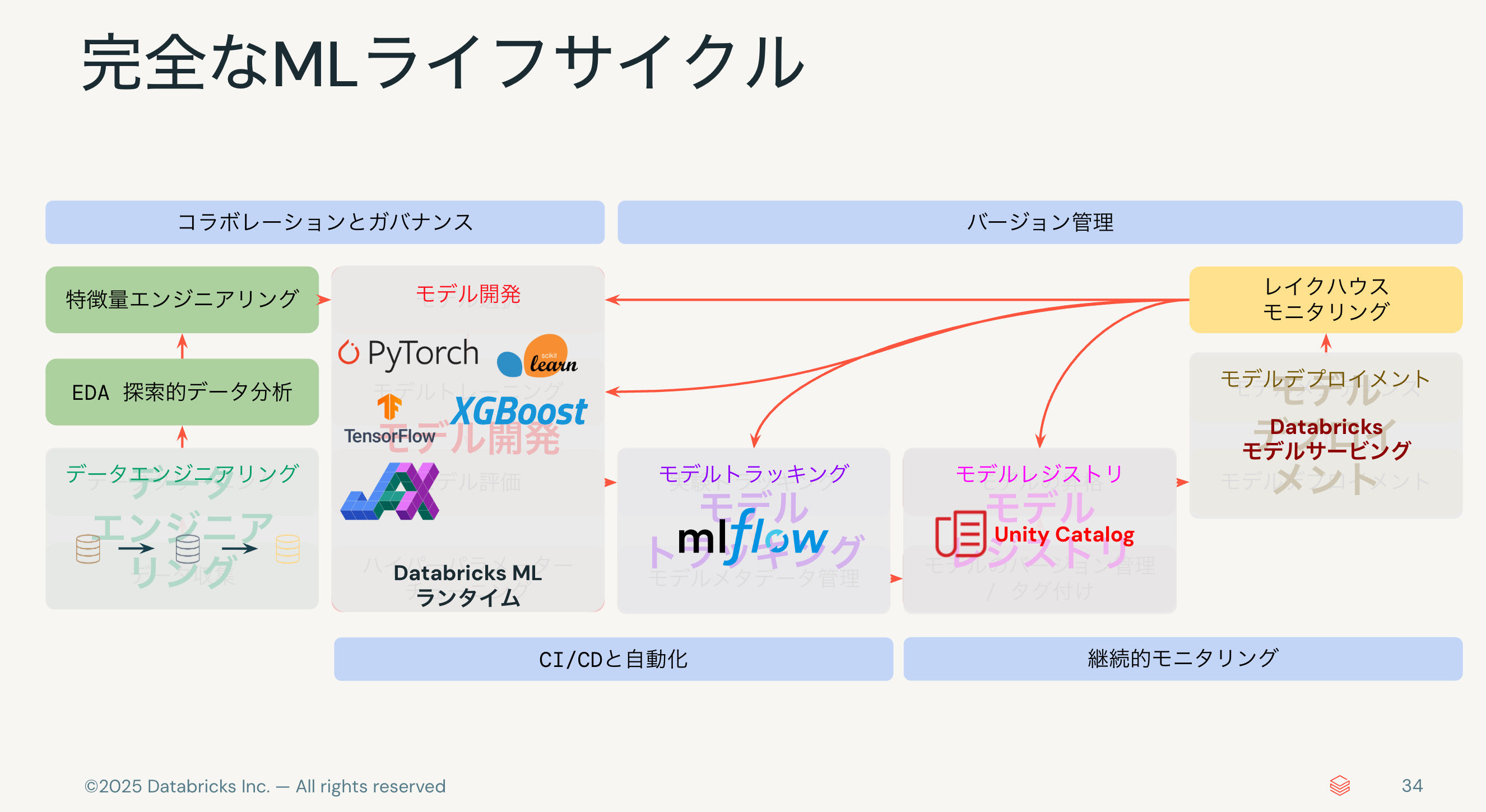
まずは、探索的データ探索(EDA)の部分から説明します。
DatabricksでEDAを行う際の主要なインタフェースがノートブックです。Google ColabやJuypter Notebookと似たインタフェースですが、いろいろな拡張が行われています。マルチ言語対応、複数ユーザーによる同時参照、同時編集、MLflow連携などです。

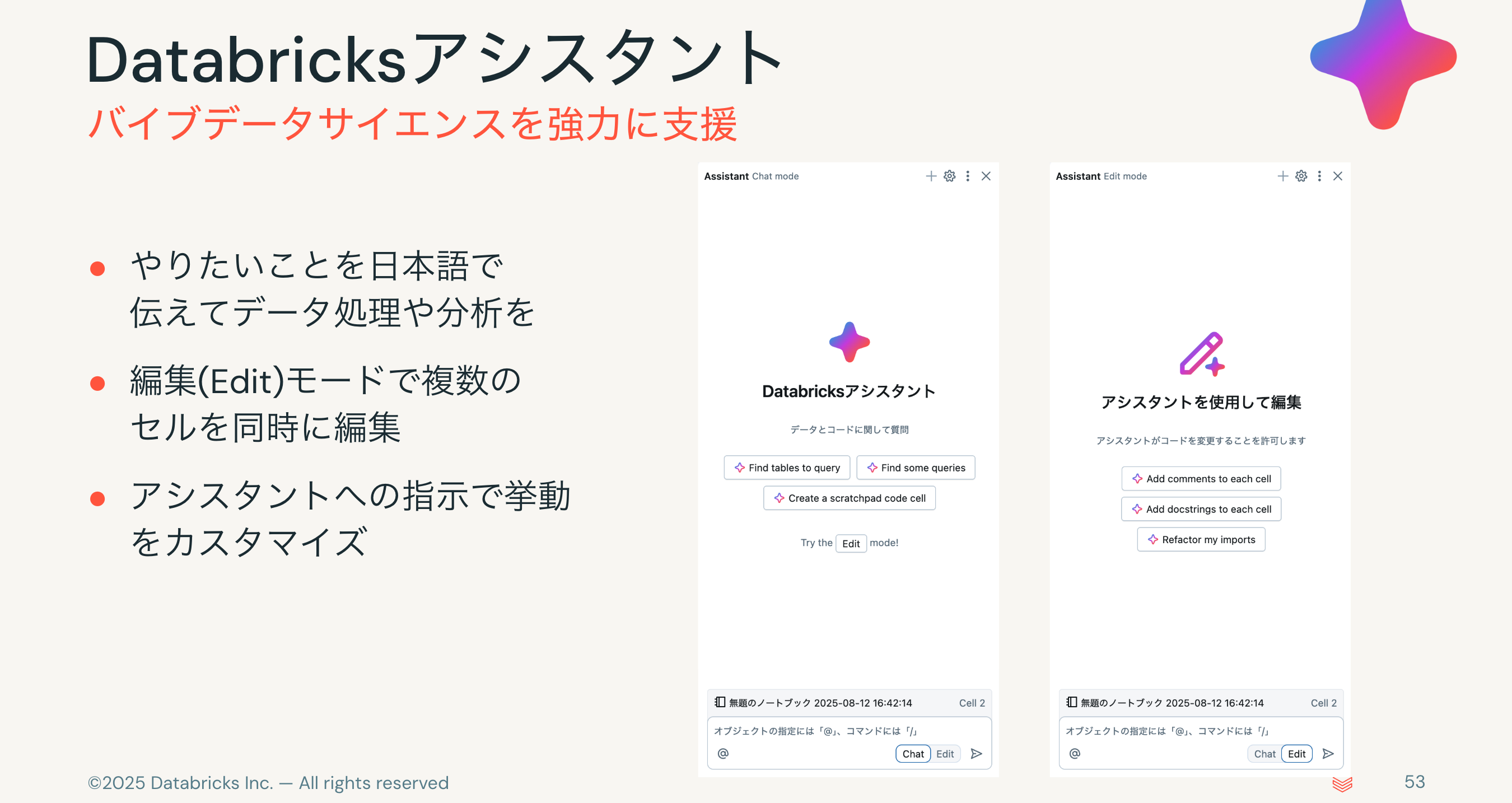
そして、生成AIの文脈での大きな追加機能がDatabricksアシスタントです。
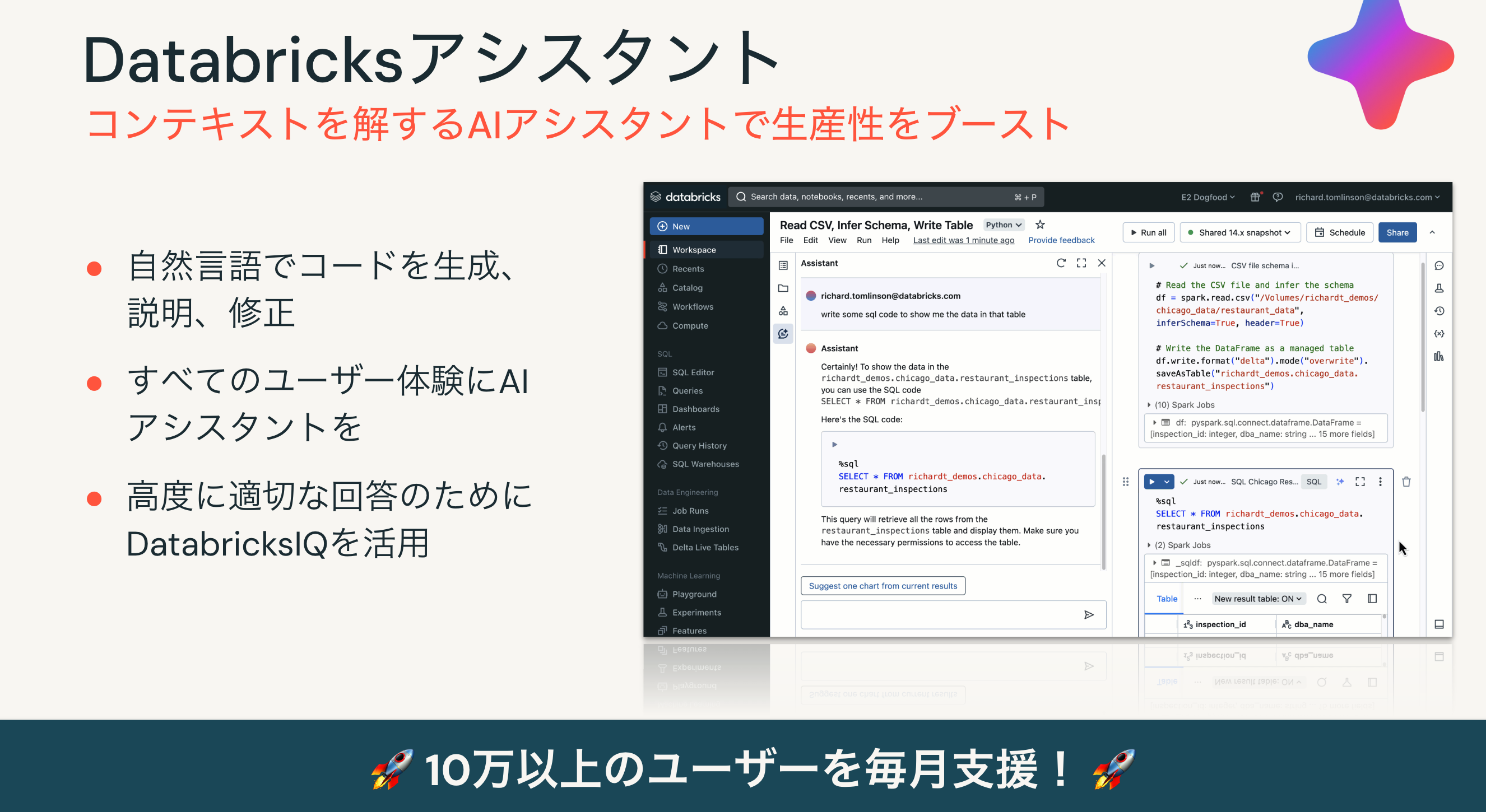
今日はノートブックからの利用がメインとなりますが、実際には様々なシーンでアシスタントが手助けしてくれます。
データサイエンスプロセスの変革
ここからが本論です。このようにデータ分析環境と生成AIが結びつくことで、データサイエンスはどのように変化するのでしょうか。
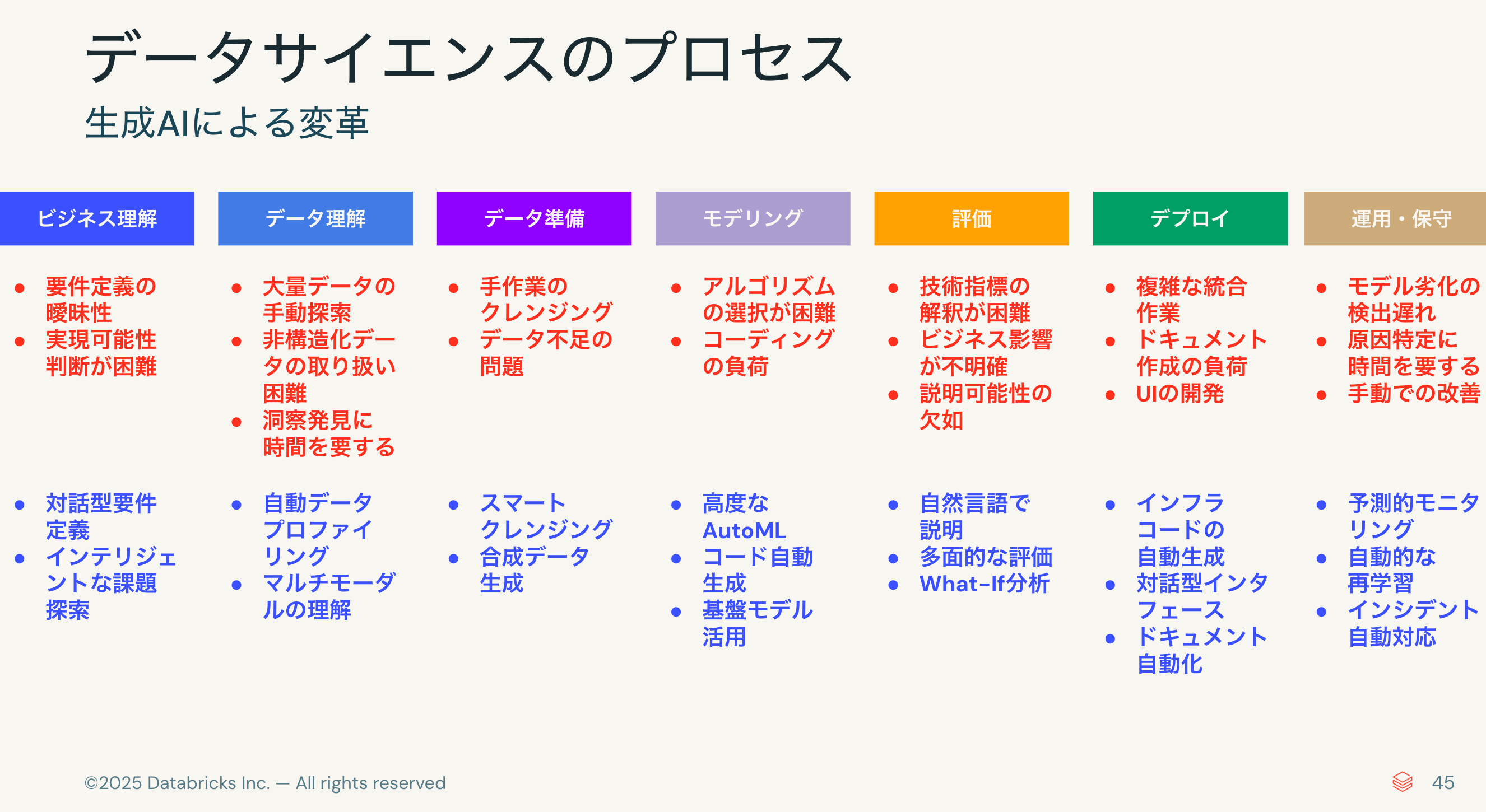
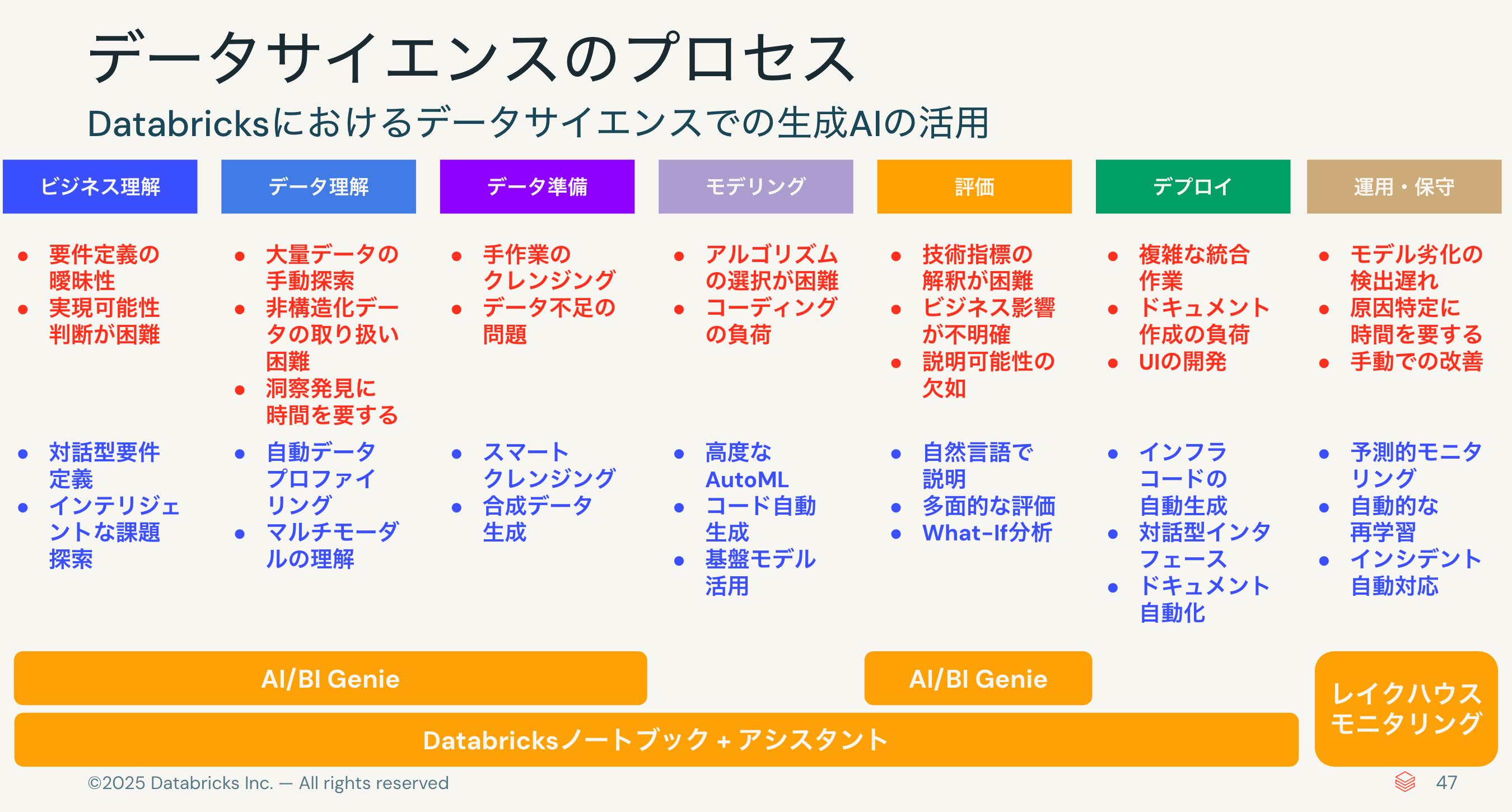
定石に従って、データマイニングのプロセスを定義するCRISP-DMを見てみます。ビジネス理解から運用・保守に至る7つのプロセスから構成されていますが、これはデータサイエンスにも共通しています。

しかし、これまではこれらのプロセスのほとんどをデータサイエンティスト(やデータエンジニア)が人手で回していました。結果として、いろいろな課題があったのも事実です。要件定義の曖昧性やデータの手動探索、コーディングの負荷や説明可能性の欠如などなど。

このような課題に対して生成AIは様々な側面から支援をしてくれます。支援どころか代行してくれもします。
結果として、生成AIはデータサイエンスのプロセスを変革し、様々なメリットをもたらします。

- 民主化の加速 専門知識がなくてもデータサイエンスに参加可能。より多くの人がデータ活用に関われる時代へ
- 開発速度の加速 従来数ヶ月かかっていたプロジェクトが数週間・数日で完了。高速プロトタイピングが可能に
- 品質と信頼性向上 自動チェック、ベストプラクティスの適用、包括的テストによる高品質なソリューション構築
- 新たな可能性 非構造化データ活用、リアルタイム適応学習、人間とAIの協調など、従来不可能だった手法が実現可能に
そして、Databricksの様々な機能がデータサイエンスプロセスの変革を支援します。
生成AIを用いたデータサイエンスの実践
ここまでの話でバイブコーディングを想像した方もいるかもしれません。今日お話ししている内容は、バイブコーディングの考え方をデータサイエンスに適用したものとも言えます。
バイブコーディング
「雰囲気」や「意図」を伝えるだけでコードを生成する開発スタイル
プログラマーが厳密な仕様やアルゴリズムを定義するのではなく、「こんな感じで動いてほしい」という大まかな意図を自然言語で伝え、AIが適切なコードを生成する開発手法。

バイブデータサイエンス
「ビジネスゴール」や「欲しい洞察」を伝えるだけで分析を実行するデータサイエンス
データサイエンティストが統計手法や機械学習アルゴリズムを選択するのではなく、「この課題を解決したい」「こんなインサイトが欲しい」という要望を伝え、AIが適切な分析を実行する手法。

バイブコーディングでは、求められるスキルがプログラミング言語の習得からAIとのコミュニケーション能力に軸足を移しているのと同様に、バイブデータサイエンスではビジネス理解を踏まえたAIとのやりとりが重要になると考えています。

そして、データサイエンスのそれぞれのプロセスにおいては、これまで手動で行なっていたことのほとんどがAIによって代行されます。人間はビジネス判断など要所要所での判断を求められることになります。

それでは、ここまでの話を実感いただくためにDatabricksアシスタントを活用したバイブデータサイエンスを実施してみましょう。
最近実装されたEditモードを活用することで、AIエディタCursorなどと同じような体験でデータサイエンスを行うことができます。
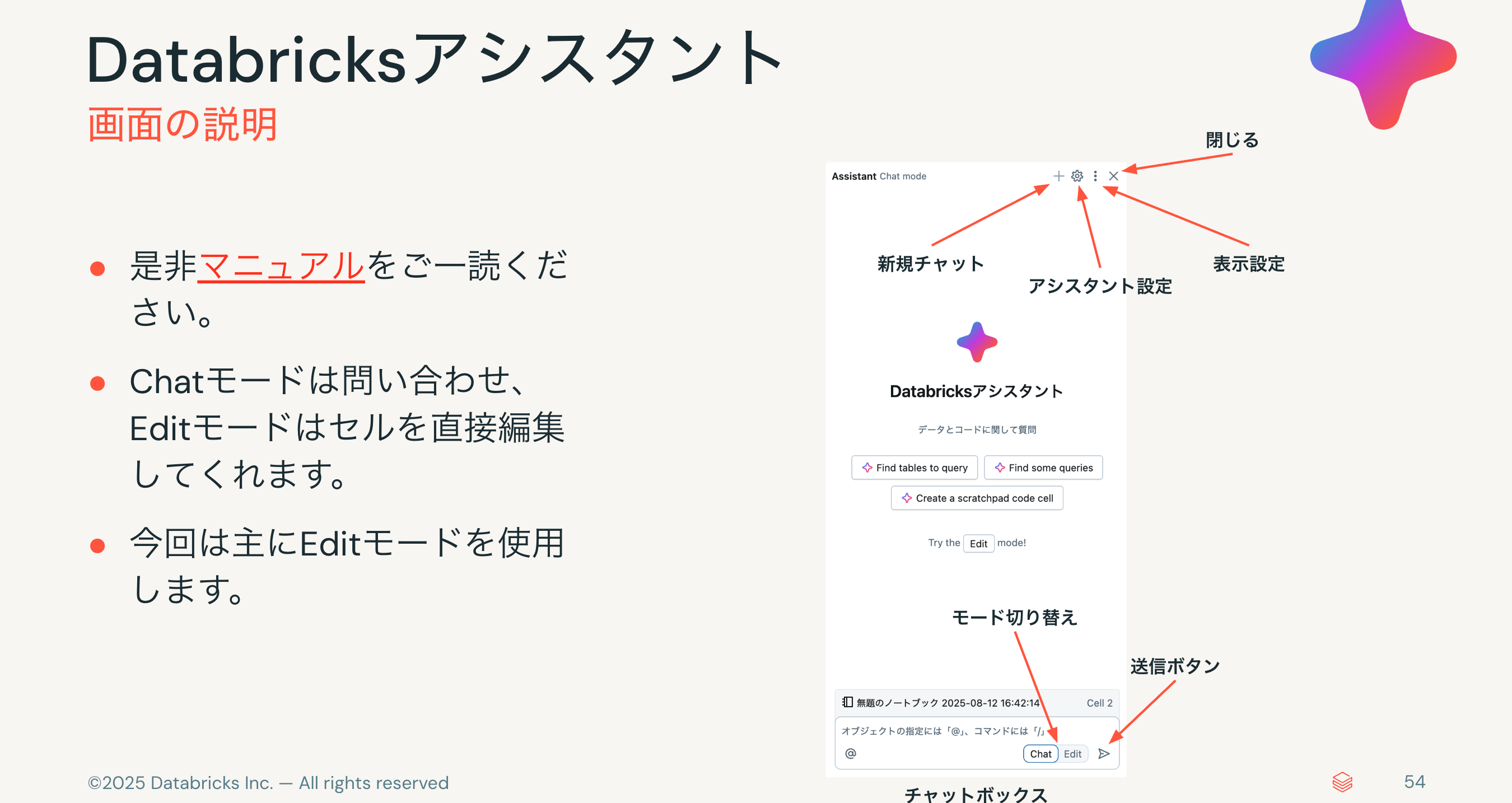
各機能に慣れておくことで効率的にバイブデータサイエンスを行うことができます。是非、マニュアルをご一読ください。
バイブデータサイエンスのデモ
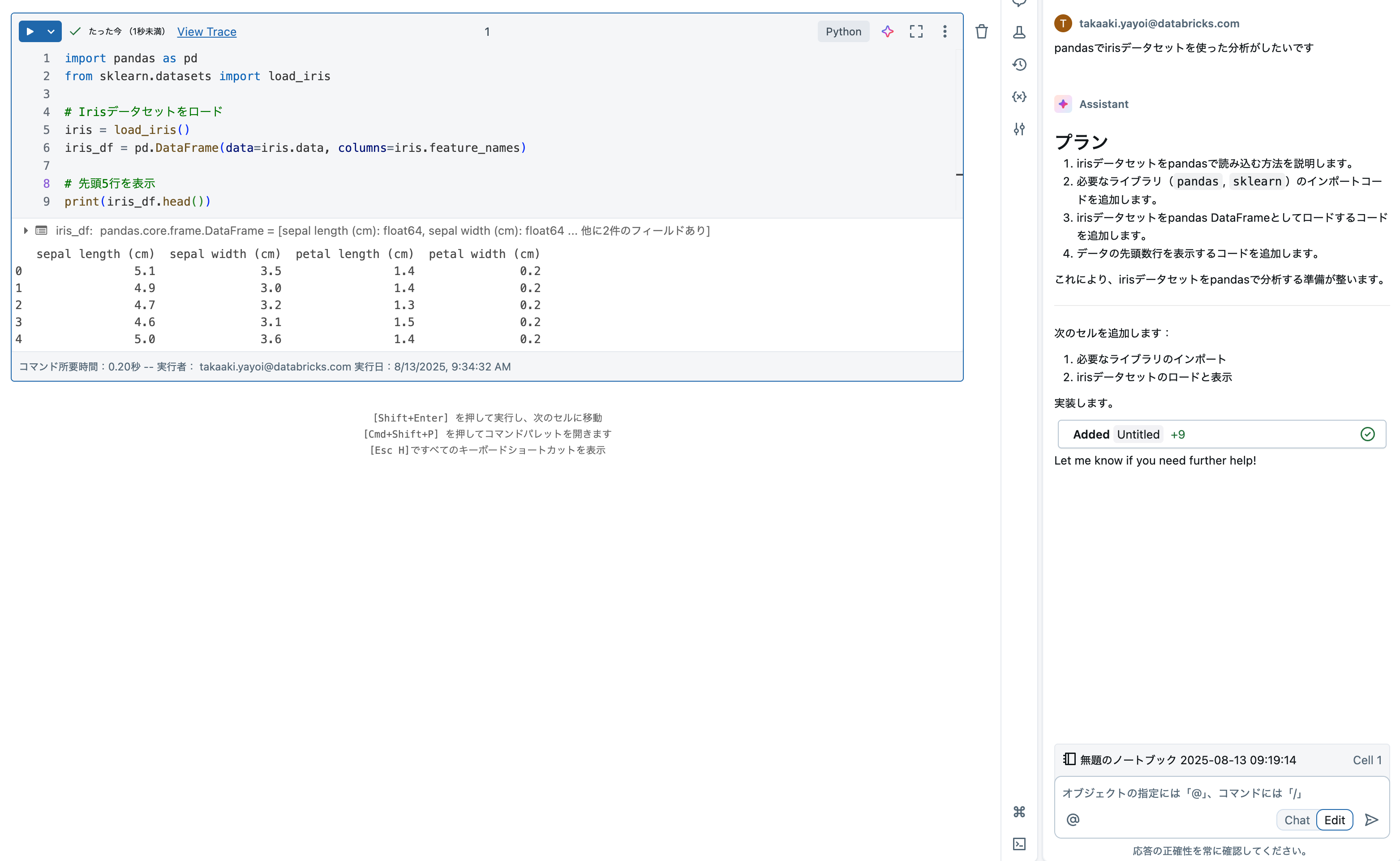
ノートブックを作成します。
画面右上のボタンを押してアシスタントを呼び出します。
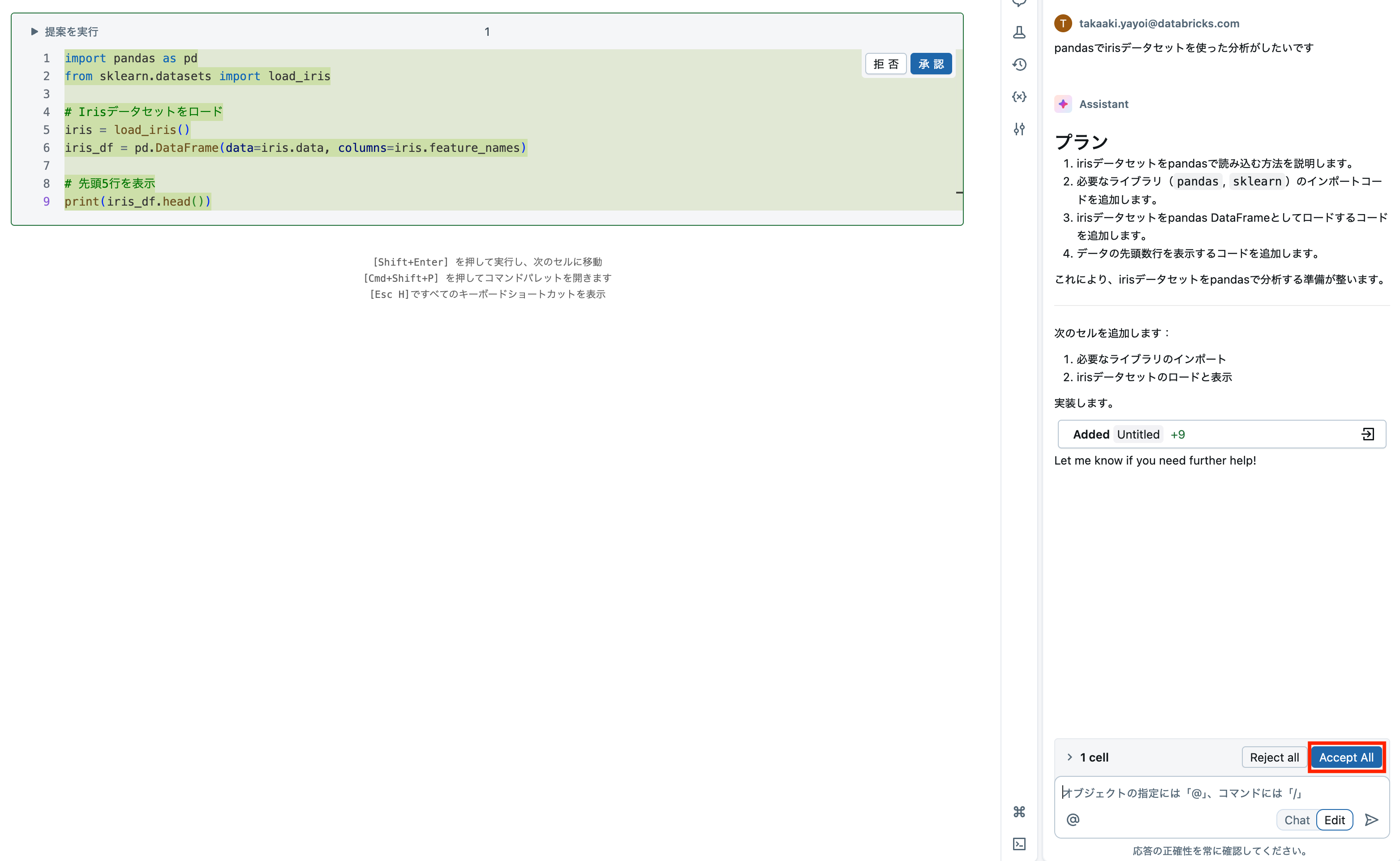
ここからはまさにバイブデータサイエンスの時間です!思うがままに指示してみましょう。
可視化のコードも自動で生成してくれます。一昔前はmatplotlibの使い方を覚えて自分でグラフ描いていたのですけどね。
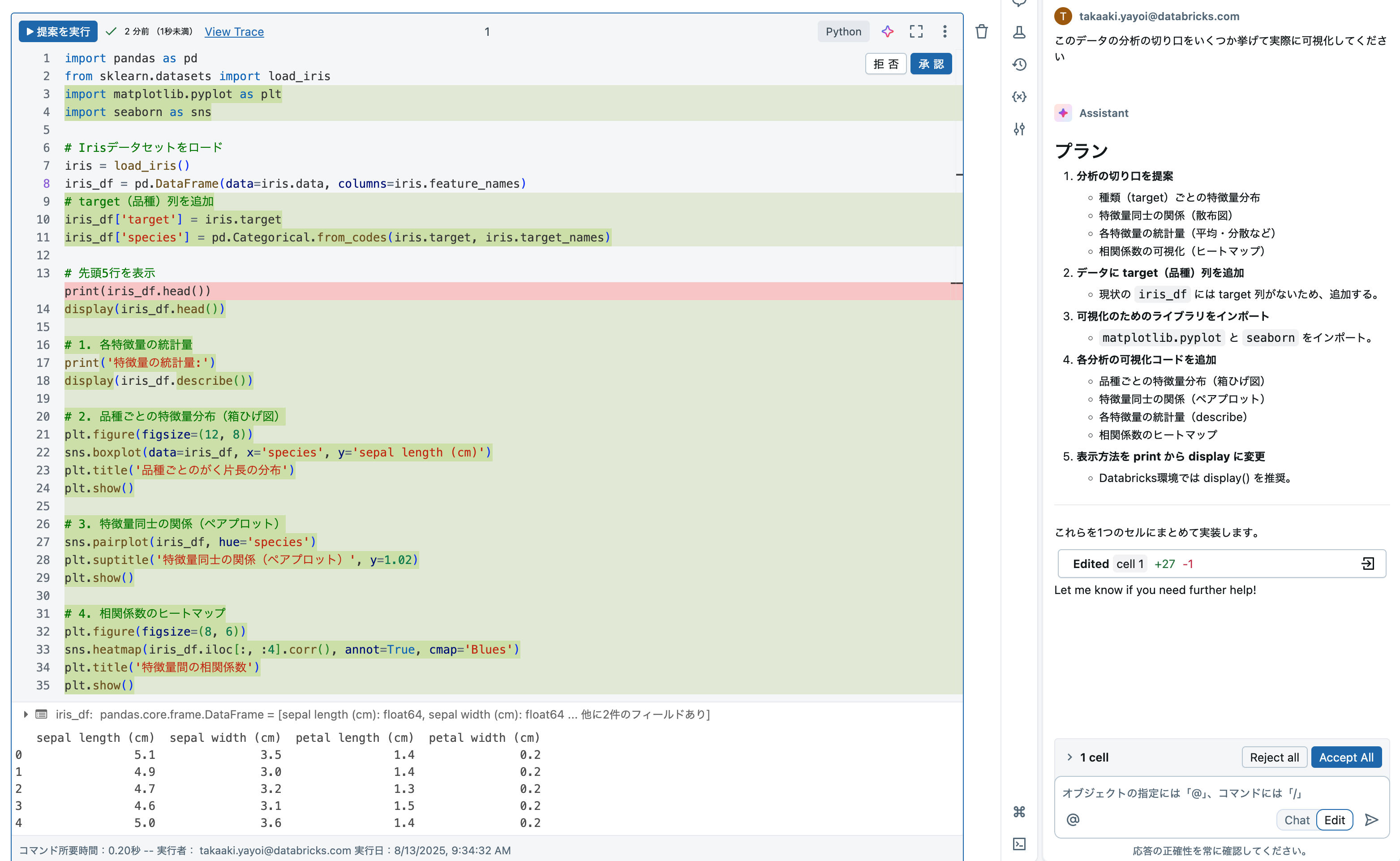
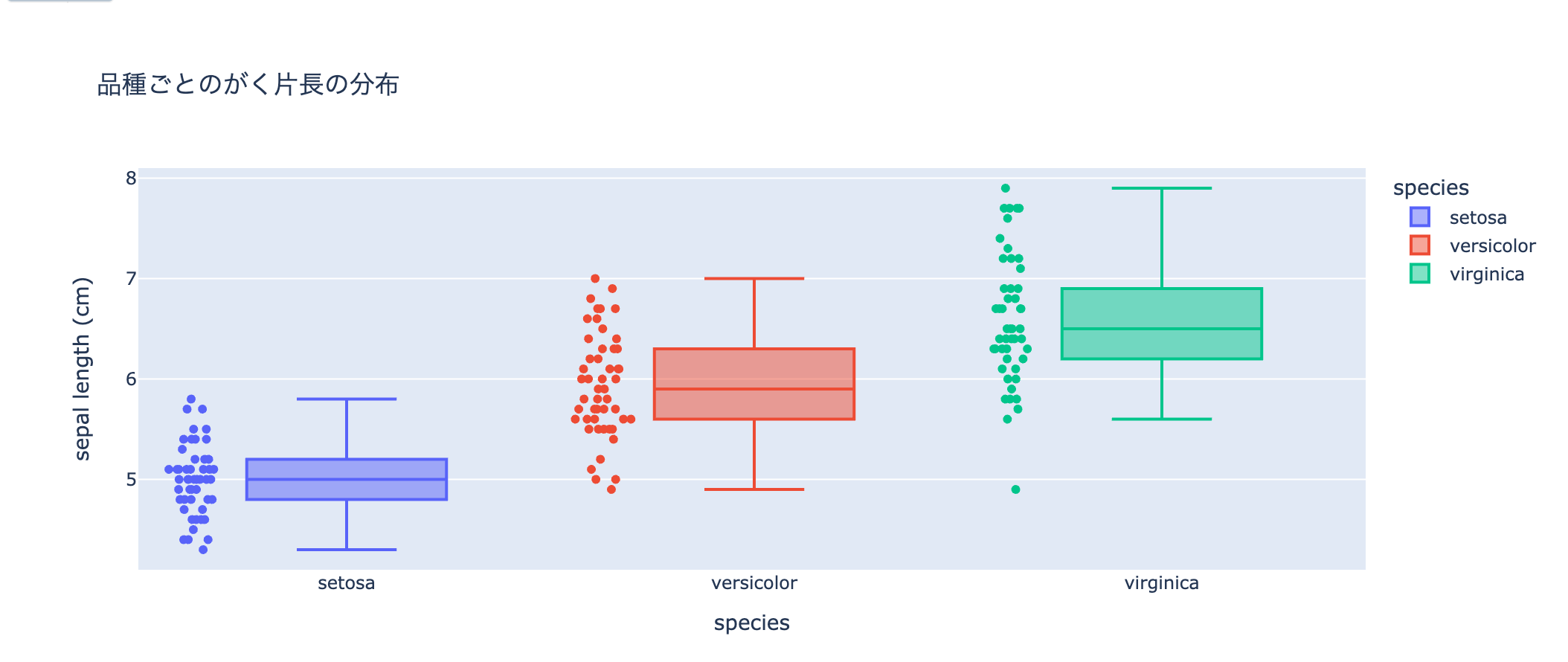

洞察の抽出すらAIにお願いできます。

エラーが起きてもAIに直してもらいましょう。
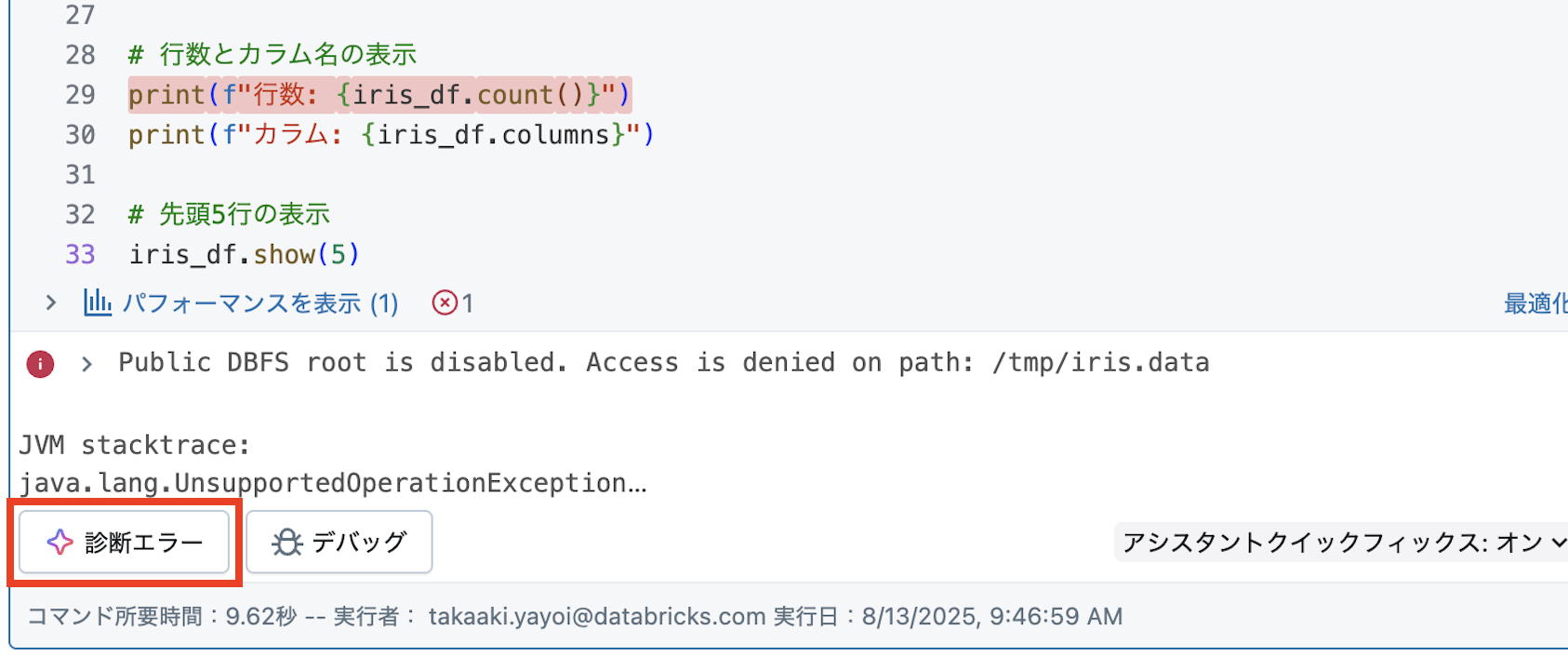
事前課題はここまででしたが、デモではさらに推し進めます。分類に有用とのことですので、以下のプロンプトを指示します。
これらを分類することはできますか
すると、ロジスティック回帰を用いた分類モデルを構築してくれます。アルゴリズムの選択すらお任せです。

分類結果の可視化もお願いしてみます。
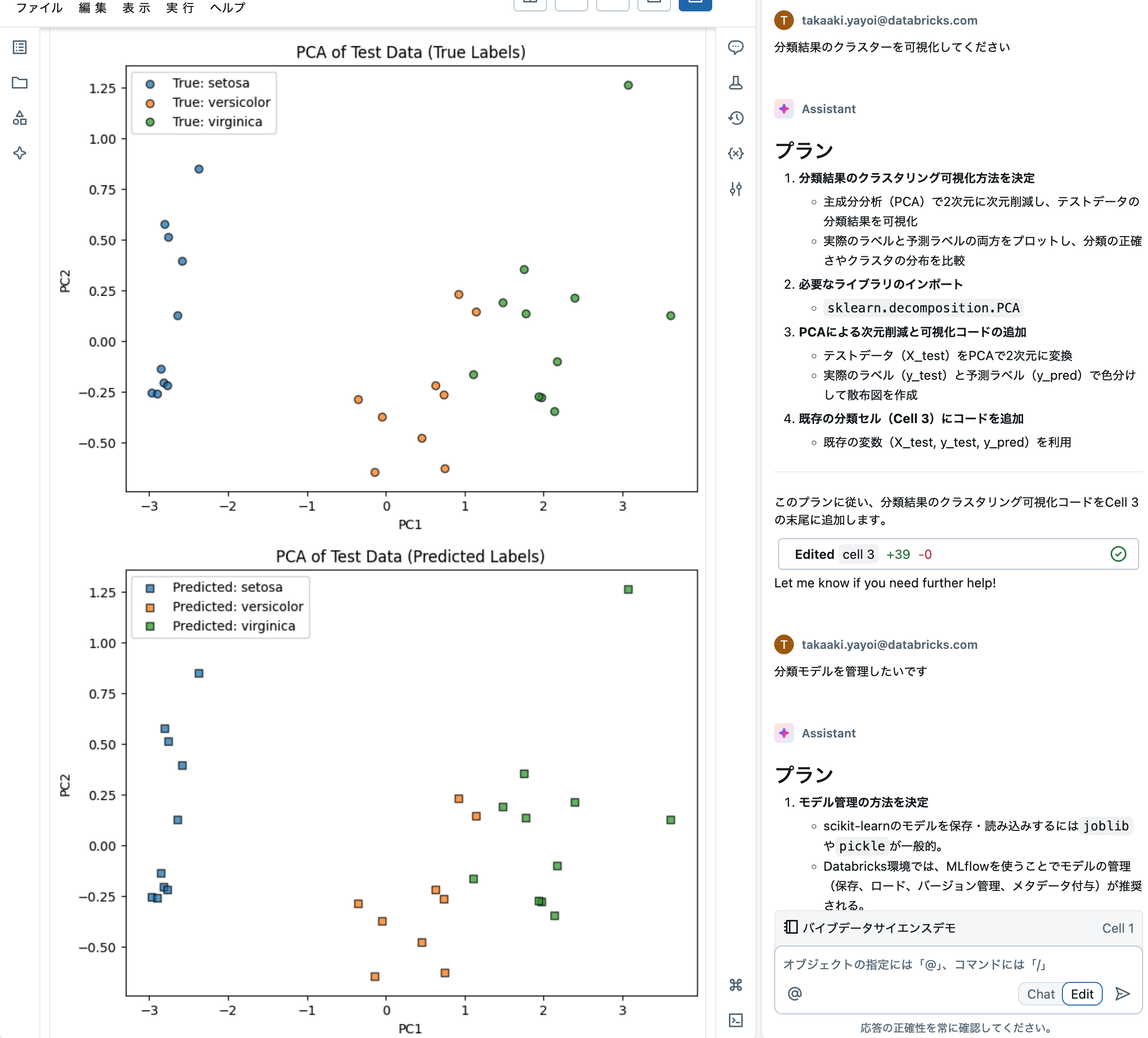
分類結果のクラスターを可視化してください
そうすると、多次元の特徴量を2次元にプロットできるように主成分分析(PCA)を行なって可視化を行ってくれます。
そして、さらには構築した機械学習モデルの管理もお願いしてみます。
分類モデルを管理したいです
そうすると、途中で触れたMLflowを活用してモデルを記録してくれるようになりました。
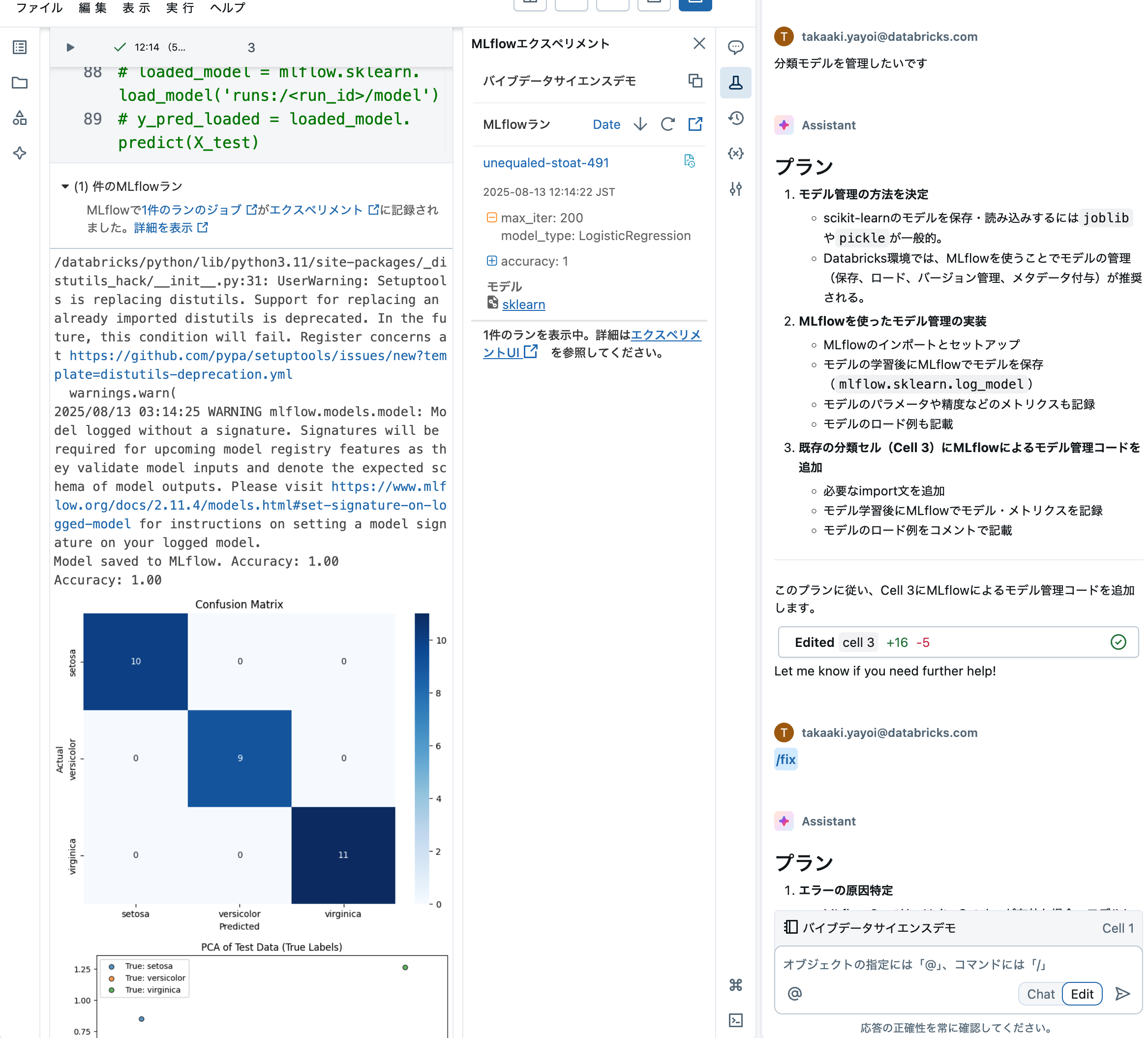
ここまで、1行のPythonを書くことなしに、データの読み込みからデータの可視化を通じたEDA、モデルのトレーニング、管理までを行うことができました。
バイブデータサイエンスのハンズオン
ここまででアシスタントを活用したバイブデータサイエンスの流れを体験いただけたと思うので、自由にデータを選択して、ご自身の観点でバイブデータサイエンスをトライしてみてください。
- 前提: Databricks Free Editionアカウント作成済み
- ゴール: AIアシスタントを活用してデータ分析を実践
- 手順:
- データを取得するプロンプトを入力します。以下のプロンプトではscikit-learnが提供するカリフォルニアの住宅価格のサンプルデータを取得するように指示しています。
- fetch_california_housing()でデータを取得
- 他の例: load_iris()、load_breast_cancer()、こちらに一覧がありますので好きなデータで試してみてください。
事前課題やデモでお見せしたプロンプトを活用して自身の感覚でデータサイエンスを行ってみてください。
- プロンプトの例
- fetch_california_housing()でデータを取得
- 可視化してください
- 地図にプロットできますか
- 可視化結果からどのような洞察が得られますか
- それぞれの特徴量を説明してください
- 物件価格を予測するモデルを作ってください
- データ取得、EDA、モデル構築という順序にセルを整理してください。適切な粒度でセルを分割してマークダウンセルによる説明を追加してください
- ダミーデータを使う必要はないので読み込んだデータのみを使ってください。
- データを取得するプロンプトを入力します。以下のプロンプトではscikit-learnが提供するカリフォルニアの住宅価格のサンプルデータを取得するように指示しています。
デモと同様に、Pythonを書くのではなく「何が必要か」をAIに伝えてデータサイエンスを実行できるはずです。
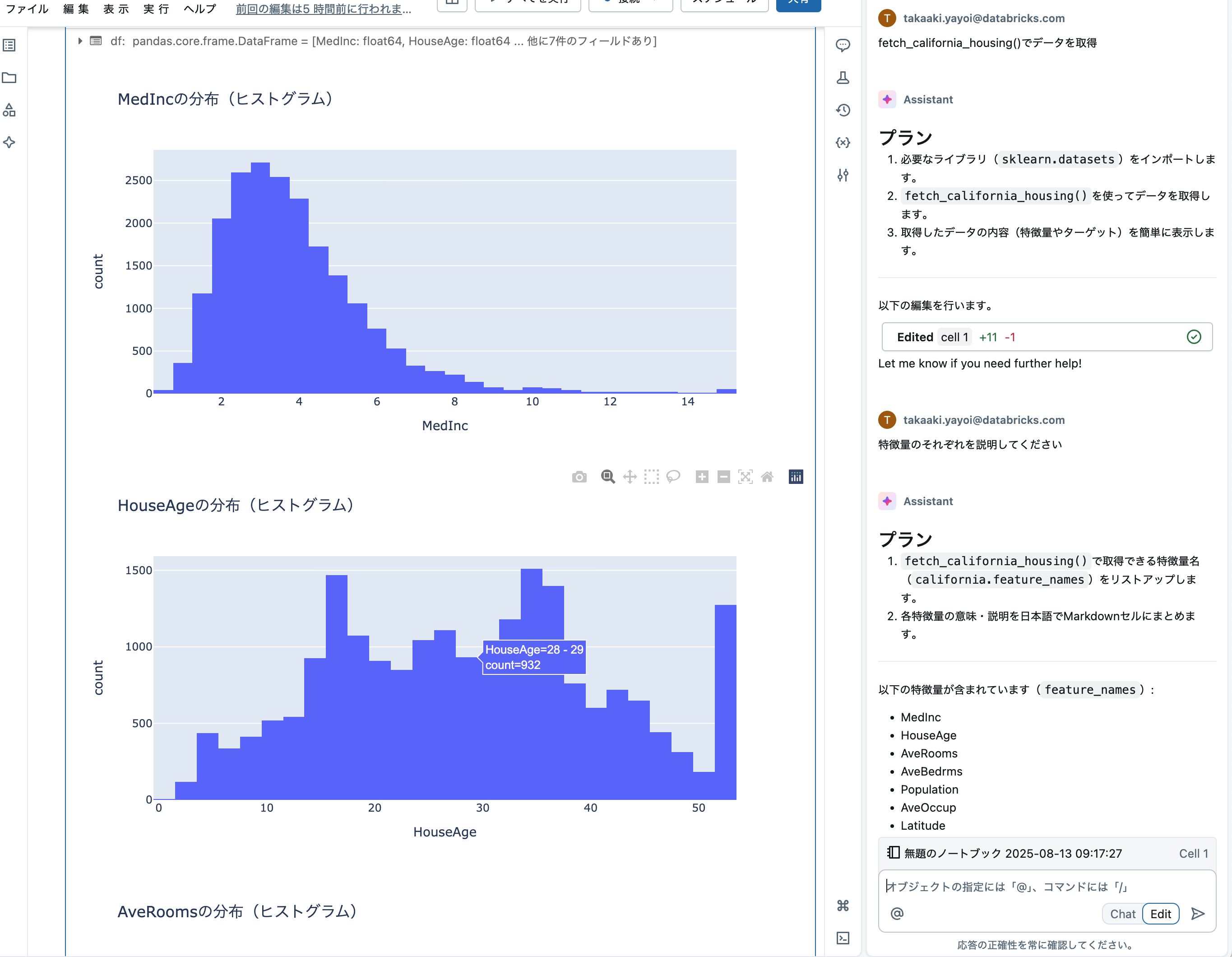
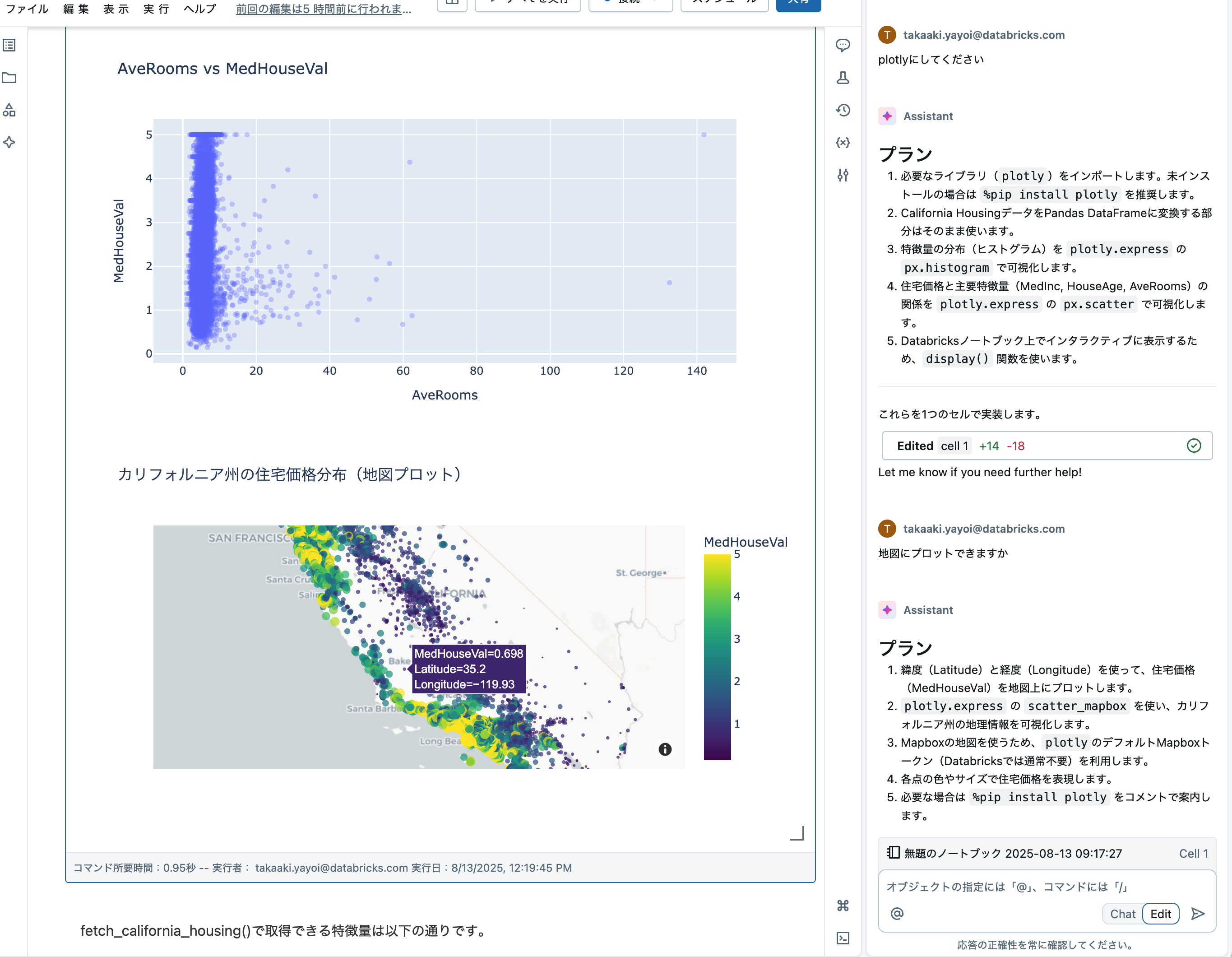
重要なのはHow(どのようにPythonを記述するのか)ではなくWhat(どのようなアウトプット、洞察を得たいのか)です。
まとめ
私の意見としては、データサイエンスの領域も生成AIが今まさに変革していると思います。従来の人手主体のデータサイエンスから大部分を生成AIで自動化できるバイブデータサイエンスにシフトする材料は十分に揃っています。
今後は以下のような流れがさらに加速していくと考えています。
- 自然言語で分析を実行
- 開発期間を大幅に短縮
- HOWではなくWHATにフォーカス
- 必要なスキルは技術力よりも対話力に (当面は技術力も重要だと思いますが)
- データサイエンスは専門家の仕事から誰もが活用できるツールへ
私からの説明は以上となります。ありがとうございました。