EHR Analytics in Real Time Using Smolder, Apache Spark™, and Delta Lake - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
前回の記事では、電子健康記録(EHR)から得られる患者データを取り扱う2つの異なるワークフローを見ました。これらのワークフローでは、EHRデータに対する履歴的バッチ抽出にフォーカスしました。しかし、実世界においては、データは絶え間なくEHRに入力されていきます。敗血症予測やERの混雑検知のように重要な予測ヘルスケア分析の多くにおいては、EHRに流れ込む医療データを取り扱う必要があります。
実際にはEHRにどのようにデータが流れ込むのでしょうか?多くの場合、データ改善のために通過すべきパスがいくつか存在します。いくつかのEHR実装においては、データは最初にNoSQLスタイルのオペレーショナルストアにニアリアルタイムの形態で到着します。翌日には、このNoSQLストアの新規データはオペレーショナルストアから正規化され、次元を持つSQLストアへと移動されます。他のEHR実装では、異なるデータベース実装を持ちますが、データがバッチ分析に利用できるように最終的な「履歴」EHRレコードになるまでには依然として遅れが生じます。リアルタイムで医療データを分析するためには、プッシュベースのHL7メッセージフィードか、プルベースのFHIR APIエンドポイントにアクセスする必要があります。これらのフィードとエンドポイントには、さまざまな健康情報データが含まれています。例えば、Admission/Discharge/Transfer (ADT)メッセージは患者がユニット間をいつ行ったり来たりしたのかを追跡するために使用し、Order Entry(ORM)は、患者に対する酸素供給や特定の研究所の試験の実施などの指示の割り当て、変更、キャンセルのメッセージを表現します。フィードとリソースを組み合わせることで、患者と病院に対する包括的なビューを手にすることができます。
ヘルスケアチームと医療従事者は、EHRデータの上にリアルタイム分析システムを構築する際に数多くの疑問に直面します。FHIRとHL7のどちらを利用すべきか?どのようにレコードをパースするのか?どのようにデータを格納しマージするのか?この記事では、Apache Spark™を用いてEHRデータを取り扱うオープンソースライブラリであるSmolderをご紹介します。SmolderはHL7メッセージをApache Spark™データフレームに変換するSparkネイティブのデータローダーとAPIを提供します。操作、検証、メッセージのコンテンツの再マッピングをシンプルにするために、SmolderはメッセージフィールドにアクセスするためのSQL関数を追加します。最終的には、これによって、HAPIのような低レベルライブラリを学習する必要性を排除する使いやすい宣言型構文を提供しつつも、数分でHL7データを取り込み解析できるストリーミングパイプラインの構築を可能なものとします。これらのパイプラインは、Delta Lakeのようなオープンソーススタンダードを活用することでヘルスケアデータソースにまたがったデータを統合しつつも、ニアリアルタイムのレーテンシーを実現します。
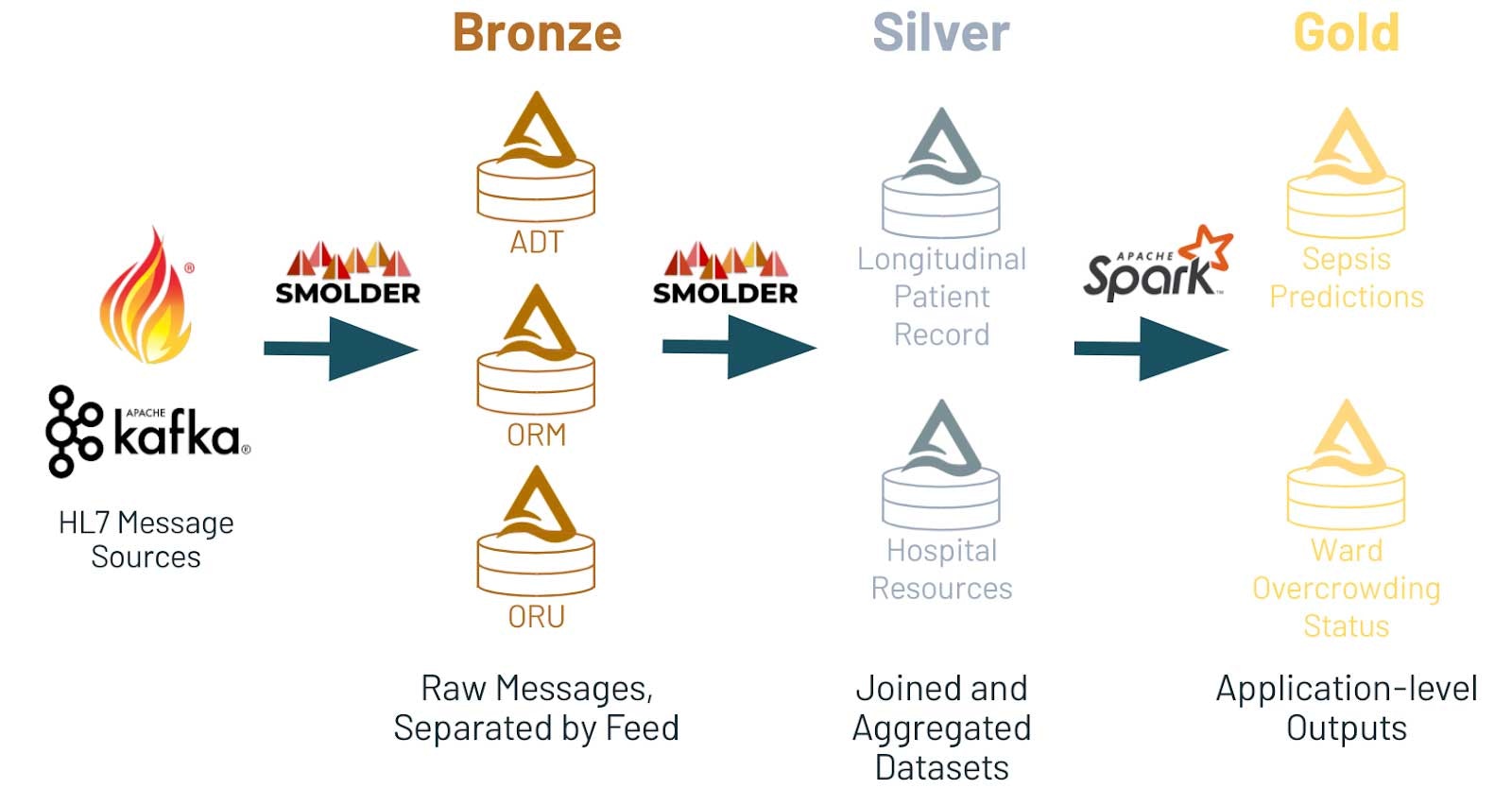
この記事の残りの部分では、高度治療の活用を必要とする患者を特定するために、EHRデータをニアリアルタイムで分析するためにSmolderライブラリを使用します。最初に、HL7v2スタンダードにディープダイブし、動作原理、何を意味するのかを見ていきます。そして、Smoloderの開発をガイドした設計原理を議論します。最後に、どのようにApache Sparkの構造化ストリーミングAPIとSmolderライブラリを用いて、リアルタイムでDelta Lakeにデータをロードするのかをお見せします。
HL7メッセージを取り扱う
HL7v2
HL7はヘルスケアにおける相互運用性を定義する国際標準団体であるHealth Level 7の略です。ここでは、ヘルスケアデータの効果のためのREST APIとJSONスキーマを定義するFHIRヘルスケアデータ交換標準や、XMLベースの医療ドキュメントアーキテクチャ(CDAとC-CDA)標準、そしてオリジナルのHL7v2標準を維持管理しています。これらの標準は異なる目的を持っています。FHIRはアプリケーション開発に有用なAPIエンドポイントを定義し、C-CDAは患者に関する履歴情報の交換にベストな標準を定義し、HL7v2はEHRに存在する状態とデータをリアルタイムの更新を捕捉するメッセージ方言です。アプリケーション開発において最近はFHIRが注目を集めていますが、HL7v2は広く導入されていることから分析の利用においては、HL7v2が一般的には最も適切な標準となります。多くの機関では現在HL7フィードを活用しているレガシーシステムを持っています。このため、すべてのシステムがFHIRをサポートするのを待つ必要なしに、大量のデータに踏み込み、分析の豊富のベースを作り出すのが容易となります。また、HL7フィード自体、通常はTCP/IPをベースとしたデータストリームなので、イベントベースのストリーミングアーキテクチャに非常に綺麗に収まります。
MSH|^~\&|||||20201020150800.739+0000||ADT^A03^ADT_A03|11374301|P|2.4
EVN|A03|20170820074419-0500
PID|||d40726da-9b7a-49eb-9eeb-e406708bbb60||Heller^Keneth||||||140 Pacocha Way Suite 52^^Northampton^Massachusetts^^USA
PV1||a|^^^COOLEY DICKINSON HOSPITAL INC THE|ambulatory||||49318f80-bd8b-3fc7-a096-ac43088b0c12^THE^COOLEY||||||||||||||||||||||||||||||||||||20170820074419-05\
00
コード: これはサンプルのHL7メッセージです。このメッセージはADT_A03メッセージであり、退院した患者に関する情報を提供しています。我々はこのデータをオープンソースのSynthea医療レコードシミュレーターで作成しました。
ここまでで、HL7v2に慣れ親しんできたので、HL7v2メッセージの中身を見ていきましょう。上の図では、マルチライン、パイプ区切りの単一のHL7v2メッセージを示しています。XMLバージョンの仕様も存在します。FHIRはJSONベースの仕様です。メッセージタイプ、セグメントタイプごとのスキーマはHL7v2の仕様で定められています。メッセージのそれぞれの行セグメントであり、最初のカラムはそのセグメントに対するスキーマが何であるのかを示す「セグメント記述子」です。上のADT_A03メッセージをパースする際、患者のIDに関する情報を含む「PID」セグメント識別子と、退院することとになった患者の訪問に関する情報を含む「PV1」です。患者IDセグメントでは、2つ目のフィールドが患者のIDであり、4つ目のフィールドが指名という形になります。
それでは、このデータをどのように取り扱いますか?我々は数多くのお客様がApache Sparkのストリーミング機能を用いてHL7データをDatabricksに取り込むお手伝いをしてきました。これまでには、お客さまが自身のEHRとApache Kafka™️やKinesis、EventHubsのようなストリーミングサービスの間にパイプを接続するのを見てきました。そして、テキストのデータフレームを生み出すApache Sparkにこれらのパイプを接続します。最後には、手書きのパーサーかHAPIのような低レベルライブラリを用いてこのテキストをパースします。
このアプローチはいくつかのお客様ではうまくいきましたが、手書きのパーシングライブラリあるいはオーバーヘッドを伴うHAPIのようなライブラリに依存しなくてはならず、課題を引き起こしていました。データレイクの重要なメリットの一つに、パイプラインでの検証を後回しにできるというものがあります。通常、我々はこれをdー得たの生の状態で取り込み、格納するブロンズレイヤーにあるといいます。これによって、お使いのデータのサイズや形態に対して、いかなる選択をすることなしに、観測された履歴データを維持できる柔軟性を手に入れることができます。
これは、ビジネスに直面するユースケースに取り組む前に、過去データの検証や分析をこなう必要がある際に特に有用です。例えば、プライマリケアプロバイダー(PCP)フィールドを検証するケースを考えてみます。ヘルスケアシステムがケアチームの別の外科医とPCPを取り替えてしまっていることに気づいた場合、これらすべてのレコードに対して過去に遡って修正したいと考えるでしょう。Smolderは設計上、この場パラダイムに従っています。
HAPIと異なり、Smolderはメッセージを適切なHL7メッセージであること以上の検証を行わないstructsにブレークダウンします。これによって、シルバーレイヤーにデータを投入し、クエリーできるようにしつつも、観測されたデータを捕捉できるようになります。
Apache SparkでHL7を取り扱うオープンソースライブラリであるSmolderのデザイン
HL7v2メッセージを処理する際のニアリアルタイムのレーテンシーを達成する使いやすいシステムを提供し、データサイエンスと可視化のために大規模なエコシステムがデータにアクセスできるようにすることを目的としてSmolderの開発をスタートしました。このために、我々は以下のアプローチを選択しました。
- 1行のコードでHL7メッセージをデータフレームに変換: データフレームは、Pandas、R、Sparkに関係なく、データサイエンスで広く利用されており、SQLのように広くアクセスされている宣言型プログラミングフレームワークを通じて使用することができます。1行のコードでHL7メッセージをデータフレームにロードできるのであれば、HL7メッセージを取り扱うことのできる後段の場所を劇的に増やすことができます。
- メッセージからデータを抽出するためにシンプルかつ宣言型のAPIを活用: HAPIのようなライブラリはHL7v2メッセージを取り扱うためのAPIを提供しますが、これらのAPIは複雑であり、非常にオブジェクト指向で、HL7v2メッセージングフォーマットに関する多くの知識を必要とします。代わりに、1行のSQLライクの関数を人々に提供できるのであれば、彼らは新しく複雑なAPIを学ぶ必要なしにHL7メッセージのデータを理解することができるようになります。
- ソースに関係なしにHL7メッセージに対して一貫性のあるスキーマとセマンティクスを提供: Smolderでは、HL7v2メッセージの直接取り込みと、Apache Kafkaのようなオープンソースツールや、AWSのKinesisやAzureのEventHubsのようなクラウド固有サービスからの別のストリーミングソースからやってくるHL7v2メッセージテキストの取り込みの両方をサポートしています。ソースに関係なく、メッセージは常に同じスキーマにパーシングされます。Apache Sparkの構造化ストリーミングセマンティクスと組み合わせることで、バッチやストリーミングデータ処理を通じて同じように容易に検証実行できるポータブルかつプラットフォーム中立なコードを実現することができます。
究極的には、このアプローチによってSmolderは容易に学習し使え、かつ大規模HL7メッセージに対する厳しいSLAをサポートする軽量なライブラリになりました。それでは、SmolderのAPIの詳細と、病院の入院のパターンを分析するダッシュボードをどのように構築するのかを見ていきましょう。
Smolderを用いたHL7メッセージのパーシング
Apache Spark™の構造化ストリーミングAPIを用いることで、Spark SQL APIの拡張を用いてストリーミングデータを処理できるようになります。Smolderライブラリと組み合わせることで、生のHL7v2メッセージのバッチ読み込みにSmolderを使うか、別のストリーミングソースからやってくるHL7v2メッセージテキストをパースするのにSmolderを使うことで、HL7v2メッセージをデータフレームにロードすることができます。例えば、ロードすべきメッセージのバッチがある場合、シンプルにhl7リーダーを呼び出します。
scala> val df = spark.read.format("hl7").load("path/to/hl7/messages")
df: org.apache.spark.sql.DataFrame = [message: string, segments: array<struct<id:string,fields:array>>]
返却されるスキーマには、メッセージカラムにメッセージのヘッダーを含んでいます。メッセージのセグメントはsegmentsカラムでネストされており、2つのネストされたフィールドを含む配列となっています。セグメントに対する文字列のid(例:患者識別セグメントのPID)とsegmentフィールドの配列です。
また、生のメッセージテキストにSmolderを使用することができます。これは、HL7メッセージが中間のソース(Kafkaストリームなど)に最初に到着した際に起こり得ます。これを行うためには、Smolderのparse_hl7_messageヘルパー関数を使用します。最初に、HL7メッセージテキストを持つデータフレームからスタートします。
scala> val textMessageDf = ...
textMessageDf: org.apache.spark.sql.DataFrame = [value: string]
scala> textMessageDf.show()
+--------------------+
| value|
+--------------------+
|MSH|^~\&|||||2020...|
+--------------------+
次に、com.databricks.labs.smolder.functionsオブジェクトからparse_hl7_messageメッセージをインポートし、パースしたいカラムにこれを適用します。
scala> import com.databricks.labs.smolder.functions.parse_hl7_message
import com.databricks.labs.smolder.functions.parse_hl7_message
scala> val parsedDf = textMessageDf.select(parse_hl7_message($"value").as("message"))
parsedDf: org.apache.spark.sql.DataFrame = [message: struct>>>]
これによって、hl7データソースと同じスキーマを得ることができます。
Smolderを用いたHL7v2メッセージセグメントからのデータ抽出
SmolderはHL7メッセージに対して使いやすいスキーマを提供しますが、メッセージセグメントからサブフィールドを抽出するためのヘルパー関数をcom.databricks.labs.smolder.functionsで提供しています。例えば、患者ID(PID)セグメントの5番目のフィールドである患者の名前を抽出したいとします。segment_field関数を用いることでこれを抽出することができます。
scala> import com.databricks.labs.smolder.functions.segment_field
import com.databricks.labs.smolder.functions.segment_field
scala> val nameDf = df.select(segment_field("PID", 4).alias("name"))
nameDf: org.apache.spark.sql.DataFrame = [name: string]
scala> nameDf.show()
+-------------+
| name|
+-------------+
|Heller^Keneth|
+-------------+
患者のファーストネームを取得したい場合には、subfield関数を使います。
scala> import com.databricks.labs.smolder.functions.subfield
import com.databricks.labs.smolder.functions.subfield
scala> val firstNameDf = nameDf.select(subfield($"name", 1).alias("firstname"))
firstNameDf: org.apache.spark.sql.DataFrame = [firstname: string]
scala> firstNameDf.show()
+---------+
|firstname|
+---------+
| Keneth|
+---------+
- ブロンズレイヤーには生のメッセージフィード(ADP、ORM、ORUのフィードごとのテーブルなど)が格納されます。
- シルバーレイヤーでは後段のアプリケーション(時間経過を示す患者レコード、病院のリソースに関する集計など)で有用なテーブルにこの情報が集約されます。
- ゴールドレイヤーにはアプリケーションレベルのデータ(病棟、病院レベルの専有率などによる病院混雑のアラートシステムなど)が格納されます。
どうして、Delta Lake上に構築するのでしょうか?そもそも、Deltaは多くの分析システムから容易位にアクセスできることを保証するオープンフォーマットであり、Apache Sparkを通じてデータサイエンスのエコシステムやSynapseのようなデータウェアハウスシステムからアクセスすることができます。さらに、Delta Lakeはカスケーディングのストリームをサポートするように設計されており、データがブロンズレイヤーからシルバーレイヤ、そして最終的にはゴールドレイヤーにストリーミングされることを意味します。加えて、Delta Lakeは、クエリー性能を改善するためのテーブルの最適化に対する数多くの手法を提供しています。例えば、頻繁にクエリーが実行されるフィールドである患者IDと来院日に対するクエリーを高速にしたいと考えるかもしれません。以前の記事で議論したように、Z-orderingを活用することができます。Delta Lakeは、これら両方のクエリーパターンにおける優れた性能を提供するために、多次元データクラスタリングを行うZ-orderingをサポートしています。
Smolderを用いてヘルスケアデータレイクの構築を始めてみる
この記事では、EHRから患者データをロードするためのApache 2ライセンスのライブラリであるSmolderを紹介しました。プロジェクトのドキュメントを読むところからスタートし、コードに貢献するためにリポジトリのフォークを作成することができます。医療データセットを格納し処理するためにDelta Lakeの利用についてマンびたいのであれば、リアルワールドの医療データセットの取り扱いに関する無料のeBookをダウンロードしてください。この記事で紹介したノートブックを用いてフリートライアルをスタートすることもできます。