How to Build a Modern Clinical Health Data Lake with Delta Lake - The Databricks Blogの翻訳です。
ヘルスケア業界は、最大のデータ生産者の一つです。実際、平均的なヘルスケア企業は約9ペタバイトの医療データを保有しています。電子健康記録(EHR)、デジタル医療画像、ウェアラブルの増加が、このデータの爆発に拍車をかけています。例えば、大規模な医療機関におけるEHRシステムは、数百万の医療試験、診断のやり取り、処方された治療を管理します。そして、この規模の人口データから学習できるポテンシャルは膨大なものとなります。これらのデータセットに対して分析ダッシュボードと機械学習モデルを構築することで、ヘルスケア企業は、患者の体験を改善し、より優れた治療成果を得ることができます。以下に実際の事例を示します。
| 1 | 2 | 3 | 4 |
|---|---|---|---|
 |
|||
| 新生児敗血症の予防 詳細 | 持病の早期検知 詳細 | 人口グループにおける疾病の追跡 詳細 | 不正請求、悪用の予防 詳細 |
ヘルスケア企業におけるビッグデータの課題トップ3
分析と機械学習によって患者ケアを改善できる可能性があるにもかかわらず、ヘルスケア企業は古典的なビッグデータの課題に直面しています。
- バラエティ ケアのデリバリーは様々なデータソースからの多次元データを数多く生成します。ヘルスケアチームは、患者体験に対する包括的なビューを構築するために、患者、治療、設備、時間ウィンドウに跨がるクエリーを実行する必要があります。これは、レガシーな分析プラットフォームに多大なる計算能力を要求します。さらにい、ヘルスケアデータの80%は非構造化データ(例:診療ノート、医療画像、ゲノミクスなど)となっています。残念なことに、多くのヘルスケア企業の分析バックボーンとして提供されている従来型のデータウェアハウスは非構造化データをサポートしていません。
- ボリューム いくつかの企業は、ペタバイト規模の構造化データ、非構造化データを一緒に格納するためにヘルスケアデータレイクに投資し始めています。残念ながら、この規模のデータに対して従来型のクエリーエンジンは処理に苦慮しています。シンプルなアドホック分析は数時間、数日かかることもあります。リアルタイムの患者のニーズに対応するためには、これはあまりにも長い時間がかかってしまっています。
- ベロシティ 患者は常に病院に訪問し続けています。定常的なデータフローが生じるため、コードのエラーを修正した際には、EHRレコードが更新される必要があるかと思います。このため、トランザクションモデルは更新を許容できることが重要です。
これらの課題だけでも大変であることに加え、データストアは、患者の縦断的なビューを得るなどのアドホックなデータ変換や、機械学習を用いた予測モデルを構築するデータサイエンティストをサポートすべきです。
幸運なことに、ビッグデータワークロードに対してACIDトランザクションを導入するオープンソースストレージレイヤーであるDelta Lakeや、Apache SparkTMを用いることで、様々なデータに対する多次元クエリーを高速に実行できるトランザクション対応ストレージと、豊富なデータサイエンス向け機能を提供し、これらの課題の解決をサポートします。Delta LakeとApache Sparkを用いることで、ヘルスケア企業は、分析や機械学習に使えるスケーラブルな医療データレイクを構築することができます。
このブログシリーズは、シンプルな例を通じて、ヘルス、医療データに対するアドホック分析を行うためにDelta Lakeをどのように活用できるのかをウォークスルーするところからスタートします。今後の記事では、HL7/FHIRのストリーミングデータセットを処理する際に、どのようにDelta LakeとSparkを組み合わせて活用できるのかを見ていきます。最後に、Delta Lakeで構築したヘルスケアデータレイクの上で実行される様々なユースケースを見ます。
Delta Lakeによる併存疾患ダッシュボードの構築
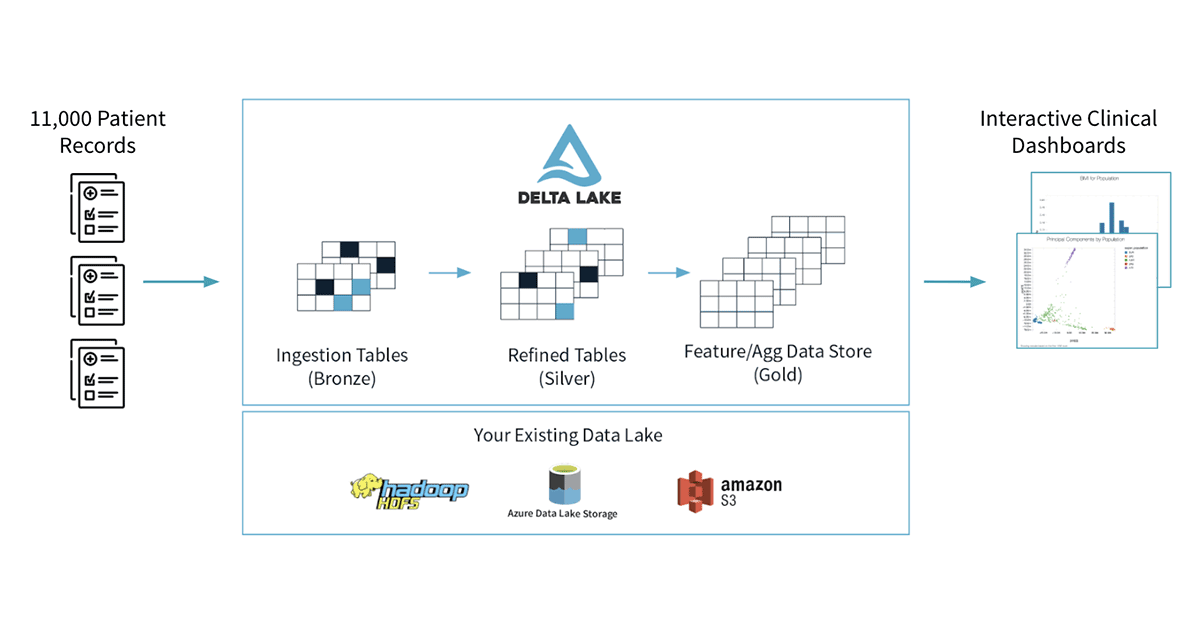
大規模医療データセットを容易に取り扱えるようにするために、どのようにDelta Lakeを活用するのかをデモンストレーションするために、シンプルですがパワフルなユースケースからスタートします。併存疾患の条件(同じ人同じタイミングで起こる一つ以上の症状あるいは疾患)を特定するためのダッシュボードを構築します。このためには、Databricksデータセット(AWS|Azure)にSynthea simulatorを適用して生成した、合成EHRデータセットを使用します。このデータセットは、マサチューセッツの約11,000人の患者グループを表現しており、12個のCSVファイルとして格納されています。このCSVファイルをロードし、保護ヘルスケア情報(PHI)をマスキングし、後段のクエリーで必要となるデータ表現を得るためにテーブルを結合します。データの整形後は、データセットに対してインタラクティブな探索と、共通的な医療統計情報を計算するためのダッシュボードを構築するためにSparkRを使用します。
このユースケースはスタート地点としては非常に一般的なものです。医療の環境においては、患者の病気の深刻度の増加リスクを理解する方法として、併存疾患を見ることにします。医療事務と財務の観点においては、併存疾患を見ることで、払い戻しに影響を与える共通的な医療事務問題の特定に役立ちます。薬品の研究において、共通する遺伝的根拠とともに併存疾患を調査することで、遺伝子の機能に対する深い理解が可能となります。
しかし、基盤となる分析アーキテクチャを検討する際にも、我々はスタート地点にいると言えます。大規模バッチでデータをロードするのではなく、リアルタイム分析を実現するためにEHRデータをストリーミングでロードしたいと考えるかもしれません。シンプルな洞察を提供するダッシュボードを使うのではなく、病気の進行を予測するために、最近の患者の訪問から得られるデータを用いて機械学習モデルをトレーニングするような機械学習ユースケースに足を進めるのかもしれません。患者の状況が改善しているのか悪化しているのかをリアルタイムで予測するために、ストリーミングデータと機械学習を活用できる緊急医療の場において、これは非常に強力な武器となります。
この記事の残りでは、ダッシュボードの実装をウォークスルーしていきます。最初にApache SparkとDelta Lakeを用いて、シミュレートしたEHRデータセットのETLを行います。データを分析できるように準備できたら、データセットから併存疾患を特定するためのノートブックを作成します。Databricksにビルトインされている機能(AWS|Azure)を用いることで、ノートブックを直接ダッシュボードに変換します。
診療データに対するDelta LakeのETL
まず初めに、CSVデータを分析ワークロードで利用できるように、一貫性のあるデータ表現に変換する必要があります。Delta Lakeを用いることで、後段で実行する数多くのクエリーを高速化することができます。Delta Lakeは複数次元にまたがるデータのクエリーを効率的にするZ-orderingをサポートしています。我々は、患者、日付、治療設備、症状、その他の条件に基づきデータを操作したいので、EHRデータを取り扱う際にこの機能は重要となります。加えて、Databricksで提供されるマネージドのDelta Lakeでは、データセットに対する探索的クエリーを加速させるために、さらなる最適化が行われています。Delta Lakeは将来の使用に耐えうるものになっています:現状ストリーミングデータを取り扱っていないとしても、将来的にはEHRシステムからのライブストリームを取り扱うことになるかもしれません。そして、Delta LakeのACIDトランザクション(AWS|Azure)によって、ストリームの取り扱いがシンプルかつ信頼性のあるものになります。
我々のワークフローは、以下の図で示すようにいくつかのステップを踏みます。8つの異なるCSVファイルから生(ブロンズ)データをロードすることからスタートし、テーブルにあるPHIをマスクします。そして、一連のシルバーテーブルとして書き出します。さらに、後段のクエリーで使いやすい形になるようにシルバーテーブルを結合します。
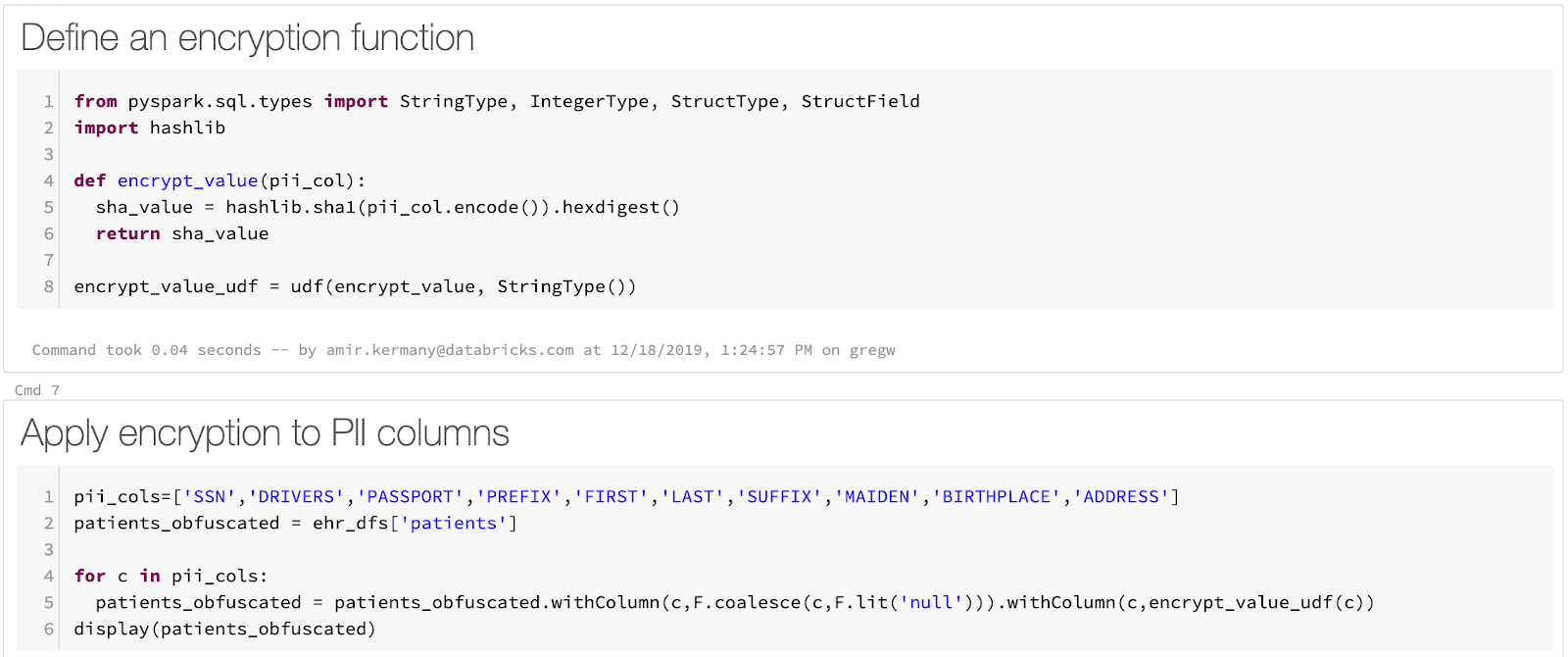
生のCSVのDelta Lakeテーブルへのロードは単純なプロセスです。Apache SparkはCSVのロードをネイティブでサポートしており、ファイルごとに1行のコードでファイルをロードすることができます。SparkはPHIをマスキングするビルトインの機能を提供していませんが、PHIやPIIをマスキングするための任意の関数を定義するために、Sparkの豊富なユーザー定義関数(UDF、AWS|Azure)を活用することができます。我々のサンプルノートブックでは、SHA1ハッシュを計算するためのPython関数を使用します。最後に、1行のコードでデータをDelta Lakeに保存します。
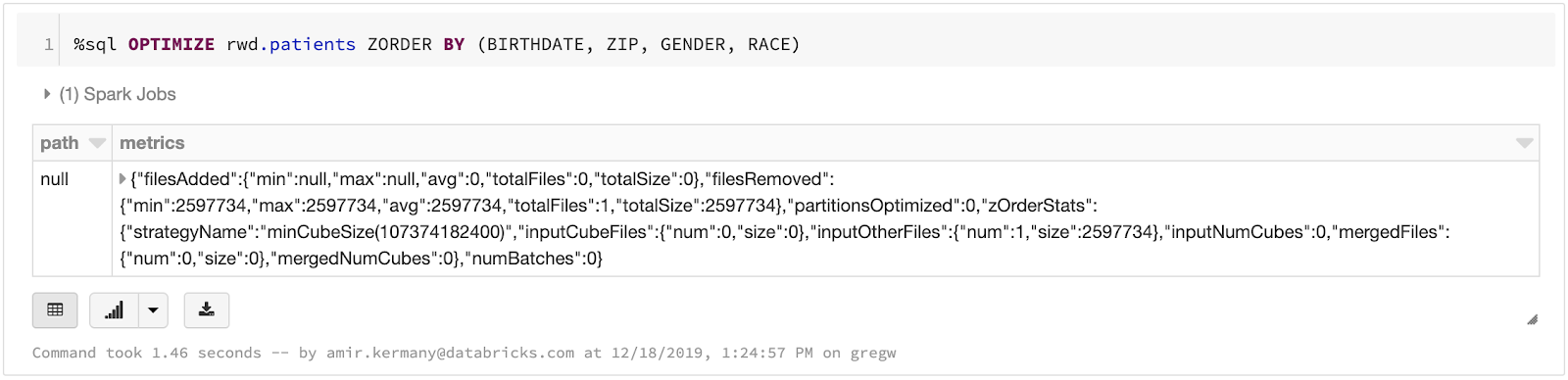
データをDeltaにロードした後で、シンプルなSQLを実行することでテーブルを最適化することができます。我々の併存症状予測エンジンでは、患者IDと評価された症状の両方に対して迅速にクエリーを実行したいと思います。Delta LakeのZ-orderingコマンドを実行することで、それぞれの次元に対するクエリーが迅速に実行されるように最適化を行うことができます。ダッシュボードで必要となるデータ表現を構築するために、複数のシルバーテーブルを結合することで生成した最終的なゴールドテーブルに対して最適化を行っています。
併存疾患ダッシュボードの構築
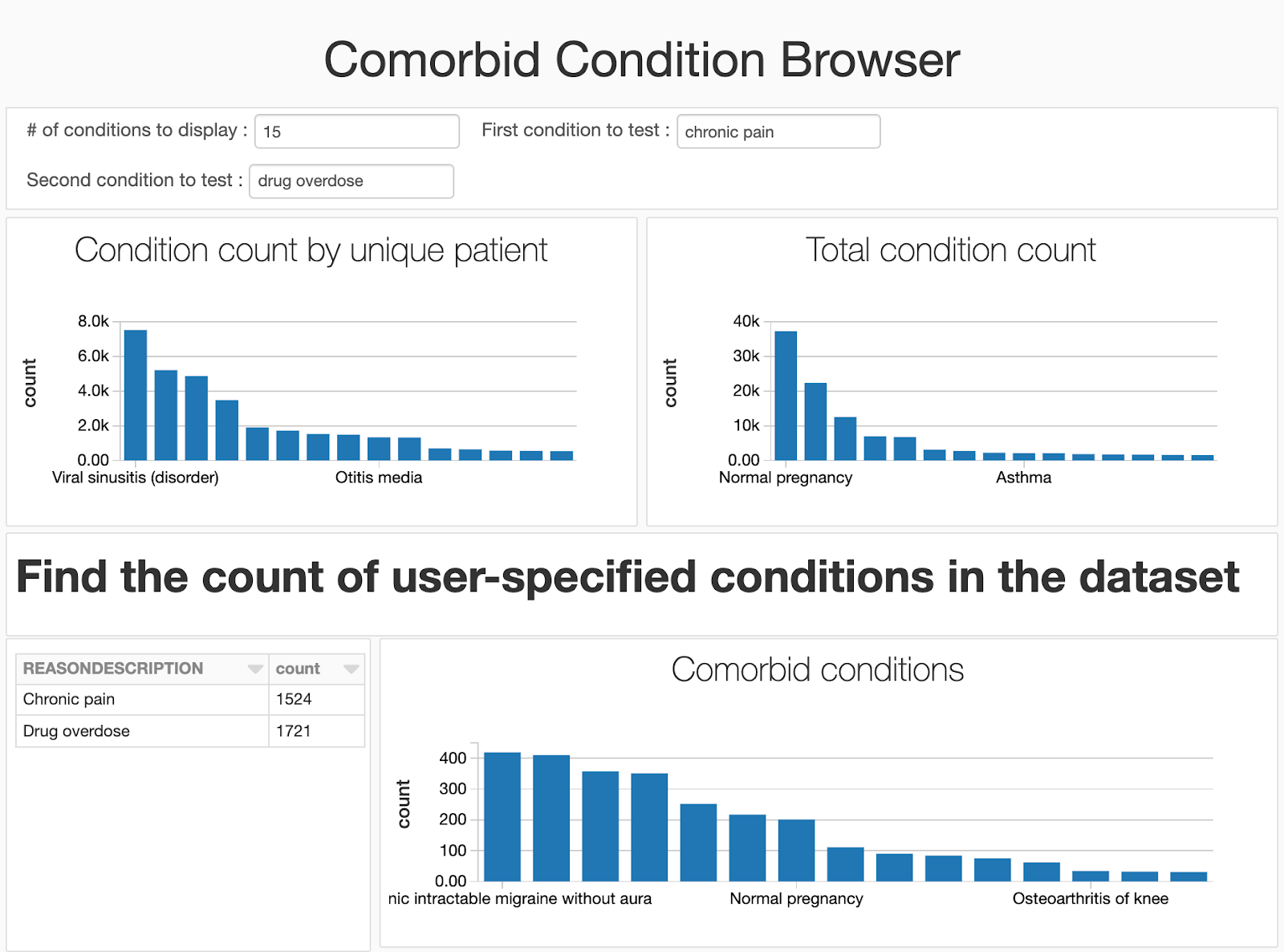
これでデータセットの準備ができましたので、併存症状、すなわち、一人の患者で共通して発生する症状を探索するためのダッシュボードを構築します。ある時には、これらは前兆、リスク要因となりえます。例えば、高血圧は心筋梗塞や他の心臓結果に関する疾病のリスク要因としてよく知られています。併存症状や健康に関する統計情報を発見、モニタリングを行うことで、リスクを特定し、予防策を患者へアドバイスすることで患者のケアを改善することができます。最終的には、併存疾患を特定は件数をカウントするエクササイズになります!症状Aと症状Bを両方持つ患者のセットを特定する必要があります。これはSpark SQLを用いて全てをSQLで処理することができます。我々のダッシュボードでは、シンプルな3つのプロセスを踏みます。
- 最初に症状を保持するデータフレームを作成し、症状を持つ患者の数でランク付けを行います。これによって、データセットにおいて最も共通した症状の相対的な頻度を容易に可視化することができます。

- 比較したい二つの症状を指定するためにユーザーウィジェットを作成します。Spark SQLを使うことで、症状があった患者のフルセットを特定することができます。

- ここでは、SparkRを用いてSpark SQLで処理をしているので、容易に患者数をカウントしたり、重要度を計算するためにカイ2乗検定を利用することができます。
データセットのトレンドを理解するために高速に繰り返し作業を行うデータサイエンティストはノートブックでの作業を好む傾向がありますが、分析で使用するコードにあまり興味がない何人かのユーザー(医師、公共ヘルスケア期間、研究者、オペレーション分析者、請求分析者)に遭遇するかもしれません。ビルトインのダッシュボード機能を活用することで、コードを非表示にし、生成する可視化にフォーカスすることができます。我々のノートブックにはウィジェットを追加しているので、コードを非表示にしてもユーザーはノートブックで比較する疾病を指定することができます。
医療データレイクの構築を始める
この記事では、Delta Lakeとシンプルな併存疾患ダッシュボードを用いてスケーラブルな医療データレイクを構築するための基礎をご説明しました。医療データセットを格納し、処理するためにどのようにDelta Lakeを活用するのを学びたい場合には
- リアルワールドの医療データセットを取り扱っているeBookをダウンロードください。
- この記事でハイライトしているETL、ダッシュボードのノートブックを実験するためにDatabricks 無料トライアルにサインアップしてください。