How to Detect At-risk Patients with Real World Data - The Databricks Blogの翻訳です。
顧客の病気を予測するためにDelta Lake上で、どのように機械学習ランタイムとMLflowを活用するのか
低コストのゲノムシーケンスと、AIを活用した医療画像解析によって、高精度医療に大きな関心が集まっています。高精度医療においては、データとAIを活用して、最適な治療法を発見することを目指します。希有な病気や癌と診断された患者に対して、高精度医療は改善された結果をもたらしましたが、高精度医療は受動的なものとなっています。高精度医療を受けるためには、患者は病気にかからなくてはなりません。
医療における費用と効果を見ると、そこには、肥満、心臓病、物質使用障害などの持病を防ぐことで、医療費と生活品質を改善する大きな機会があることに気づきます。アメリカにおいては、10人の死者に対して7人、医療費の85%が持病によるものであり、ヨーロッパ、東南アジアでも同じ傾向が確認されています。非感染症の病気は、患者の教育と、持病の原因となっている問題に取り組むことで対策することができます。これらの問題には、神経系の症状を引き起こす遺伝的リスクのような生物学的リスク要因や、環境汚染、健全な食品、予防ケアへのアクセスの欠如など社会経済的要因、喫煙、アルコール、座りっぱなしのライフスタイルのような行動リスクが含まれます。
高精度予防は、高リスク患者グループを特定するためにデータを活用し、病気のリスクを軽減するような介入をおこなうことにフォーカスしています。この介入には、高リスク患者をリモートで監視し、ライフスタイルや治療の提案を行うデジタルアプリや、病状モニタリングの強化、補助的予防ケアの提供が含まれます。しかし、これらの介入を実行に移すためには、まず高リスク患者を特定する必要があります。
高リスク患者を特定する最も強力なツールのひつとは、リアルワールドデータ(RWD)であり、これは、入院時の電子医療記録(EMR)や健康記録(EHR)、医療プラクティス、薬剤、医療プロバイダなどのヘルスケアのエコシステムから生成されるデータを包括的に指し示すものです。さらには、ゲノミクス、ソーシャルメディア、ウェアラブルデバイスからのデータも急激に増加しています。前回のブログで我々は、EHRデータからどのように医療データレイクを構築するのかをデモしました。この記事では、Databricksのレイクハウスプラットフォームを用いて、患者のジャーニーを追跡し、機械学習モデルを構築するために、この医療データレイク上に構築を行います。このモデルを用いて、特定の患者の来歴、デモグラフィック情報に対して、特定期間、特定症状における患者のリスクを評価することができます。この例は、物質使用障害による幅広い健康問題に関わる重要なトピックである、薬のオーバードーズを見ていきます。MLflowを用いてモデルをトラッキングすることで、患者ケアに対してモデルのデプロイプロセスに信頼性を高めつつ、時間経過を通じてモデルがどのように変化したのかを容易に追跡することができます。
機械学習を活用したDatabricksにおける疾病予測
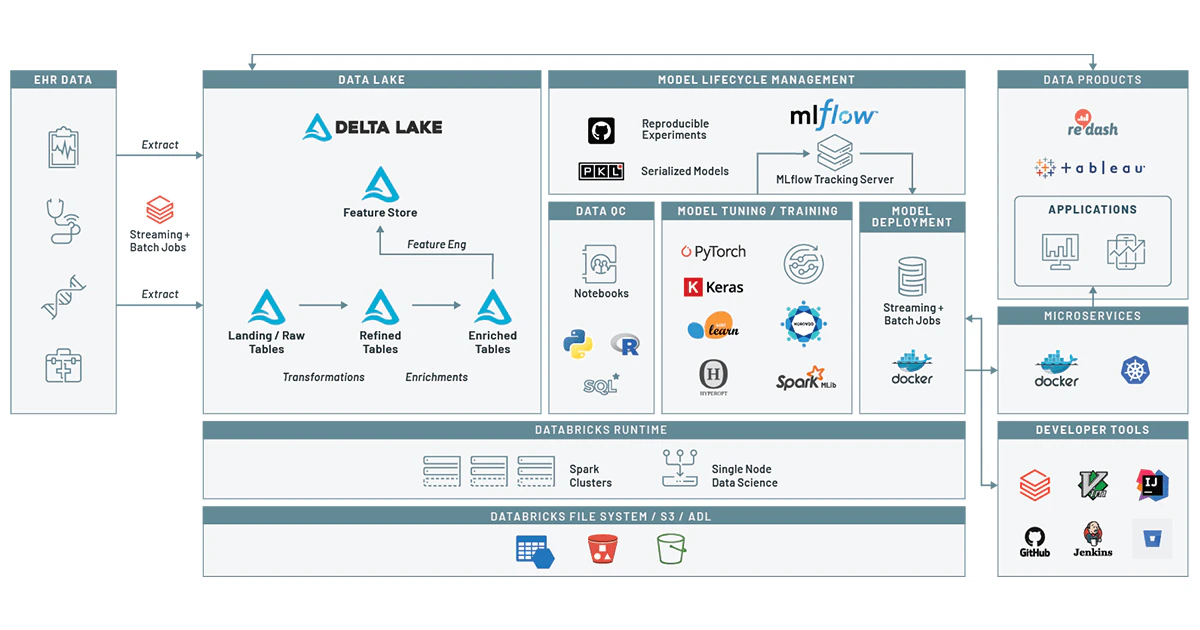
データ準備
特定のタイミングにおけるリスクを予測するモデルをトレーニングするために、患者に対する適切なデモグラフィック情報(診断時の年齢、人種など)、患者の診断履歴に関する時系列情報をキャプチャするデータセットが必要となります。患者が将来のある期間において病気と診断される可能性に影響を与える診断、デモグラフィックリスクを学習するモデルを、このデータを用いてトレーニングします。
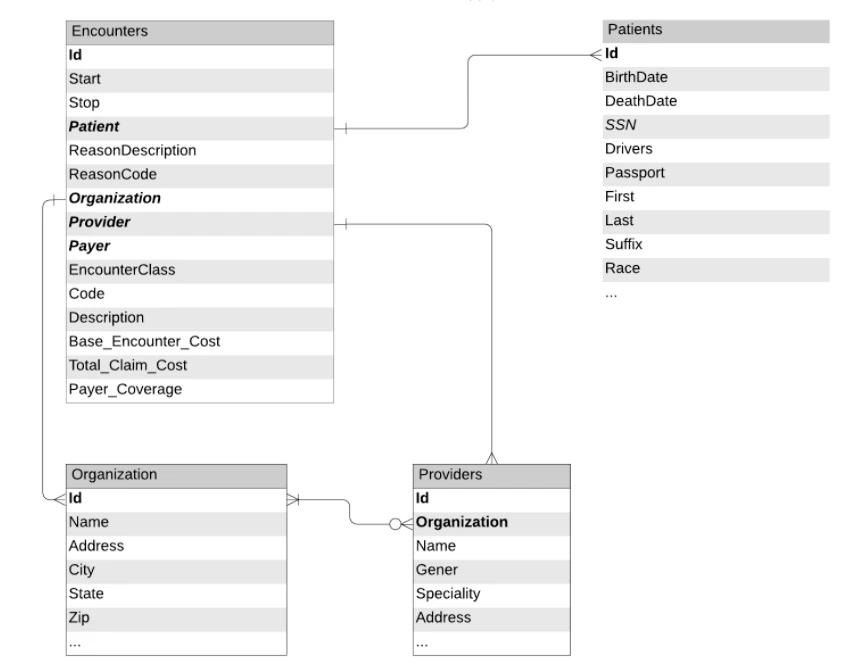
図1: EHRから抽出されたテーブル間のリレーションシップ、データスキーマ
このモデルをトレーニングするために、電子医療記録(EHR)から利用できる患者の来歴とデモグラフィック情報を活用することができます。図1には、我々のワークフローで用いるテーブルを表現しています。これらのテーブルは、以前のブログで用いたノートブックを用いて準備しています。Delta Lakeから来歴、組織、患者データ(PII情報を含む)のロードに進み、患者のデモグラフィック情報を伴うすべての患者の来歴のデータフレームを作成します。
patient_encounters = (
encounters
.join(patients, ['PATIENT'])
.join(organizations, ['ORGANIZATION'])
)
display(patient_encounters.filter('REASONDESCRIPTION IS NOT NULL').limit(10))
ターゲットの症状に基づいて、トレーニングデータに含まれるべき患者のデータセットを選択します。すなわち、ケース、通院歴を通じて少なくとも一回その症状と診断された患者、および、同じ数のコントロール、病歴のない患者を含めます。
positive_patients = (
patient_encounters
.select('PATIENT')
.where(lower("REASONDESCRIPTION").like("%{}%".format(condition)))
.dropDuplicates()
.withColumn('is_positive',lit(True))
)
negative_patients = (
all_patients
.join(positive_patients,on=['PATIENT'],how='left_anti')
.limit(positive_patients.count())
.withColumn('is_positive',lit(False))
)
patients_to_study = positive_patients.union(negative_patients)
そして、検証に含める患者の来歴を制限します。
qualified_patient_encounters_df = (
patient_encounters
.join(patients_to_study,on=['PATIENT'])
.filter("DESCRIPTION is not NUll")
)
必要なレコードを取得できたので、次のステップでは特徴量を追加します。この予測タスクに対しては、デモグラフィック情報に加えて、ある症状、あるいは共存する症状(併存疾患)と診断された回数の合計、特定の訪問の履歴的文脈として以前の訪問回数の数を選択します。
多くの病気の併存疾患に関しては多くの文献が存在しますが、ターゲットの症状に関連する併存疾患を識別するためにリアルワールドのデータセットのデータを活用することができます。
comorbid_conditions = (
positive_patients.join(patient_encounters, ['PATIENT'])
.where(col('REASONDESCRIPTION').isNotNull())
.dropDuplicates(['PATIENT', 'REASONDESCRIPTION'])
.groupBy('REASONDESCRIPTION').count()
.orderBy('count', ascending=False)
.limit(num_conditions)
)
我々のコードは、含めるべき併存疾患の数と来歴を見る期間(日数)を指定するためにノートブックのウィジェットを使用しています。これらのパラメーターはMLflowのトラッキングAPIを用いて記録されます。

次に、それぞれの来歴に併存疾患の特徴量を追加する必要があります。それぞれの併存疾患に対して、対象となる症状が過去に診察された回数を示すカラムを追加します。
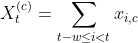
ここでは、
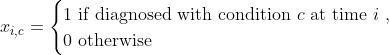
二つのステップでこれらの特徴量が追加されます。まず、併存疾患インジケーター関数を追加する関数を定義します。
def add_comorbidities(qualified_patient_encounters_df,comorbidity_list):
output_df = qualified_patient_encounters_df
idx = 0
for comorbidity in comorbidity_list:
output_df = (
output_df
.withColumn("comorbidity_%d" % idx, (output_df['REASONDESCRIPTION'].like('%' + comorbidity['REASONDESCRIPTION'] + '%')).cast('int'))
.withColumn("comorbidity_%d" % idx,coalesce(col("comorbidity_%d" % idx),lit(0))) # replacing null values with 0
.cache()
)
idx += 1
return(output_df)
そして、Spark SQLのウィンドウ関数に対する強力なサポートを活用して、隣接する期間に対してこれらのインジケーター関数を結合します。
def add_recent_encounters(encounter_features):
lowest_date = (
encounter_features
.select('START_TIME')
.orderBy('START_TIME')
.limit(1)
.withColumnRenamed('START_TIME', 'EARLIEST_TIME')
)
output_df = (
encounter_features
.crossJoin(lowest_date)
.withColumn("day", datediff(col('START_TIME'), col('EARLIEST_TIME')))
.withColumn("patient_age", datediff(col('START_TIME'), col('BIRTHDATE')))
)
w = (
Window.orderBy(output_df['day'])
.partitionBy(output_df['PATIENT'])
.rangeBetween(-int(num_days), -1)
)
for comorbidity_idx in range(num_conditions):
col_name = "recent_%d" % comorbidity_idx
output_df = (
output_df
.withColumn(col_name, sum(col("comorbidity_%d" % comorbidity_idx)).over(w))
.withColumn(col_name,coalesce(col(col_name),lit(0)))
)
return(output_df)
併存疾患の特徴量を追加した後で、未来のあるタイムウィンドウ(例:現在の訪問の後の一ヶ月)において対象の症状と診断された患者かどうかを示すターゲット変数を追加する必要があります。このオペレーションのロジックは、タイムウィンドウが将来のイベントをカバーしている違いがありますが、以前のステップと非常に類似しています。将来的に対象とする症状が診断されるか否かを示す2値のみを使います。
def add_label(encounter_features,num_days_future):
w = (
Window.orderBy(encounter_features['day'])
.partitionBy(encounter_features['PATIENT'])
.rangeBetween(0,num_days_future)
)
output_df = (
encounter_features
.withColumn('label', max(col("comorbidity_0")).over(w))
.withColumn('label',coalesce(col('label'),lit(0)))
)
return(output_df)
次に、これらの特徴量をDelta Lakeの特徴量ストアに格納します。再現性を確保するために、特徴量ストアのカラムとしてMLflowのエクスペリメントIDとランIDを追加します。このアプローチの利点は、さらなるデータを入手した際に、将来的に特徴量を参照し、再利用できるように特徴量に新たな特徴量を追加できるというものです。
データにおける品質問題への対処
トレーニングタスクに進む前に、クラス間で異なるラベルがどのように分布しているのかを見てみます。多くの2値分類のアプリケーションにおいては、例えば病気の予測において、一方がレアであるケースがありえます。このクラスの不均衡は学習プロセスに悪影響を与えます。推定プロセスにおいて、モデルはレアなイベントよりも多数派のクラスにフォーカスする傾向があります。さらに、評価プロセスも影響を受けてしまいます。例えば、0/1のラベルが95%、5%に分布している不均衡なデータセットにおいては、モデルは常に0と予測し、結果として精度は95%となってしまいます。ラベルに不均衡がある場合、これを修正する一般的なテクニックの一つを適用する必要があります。
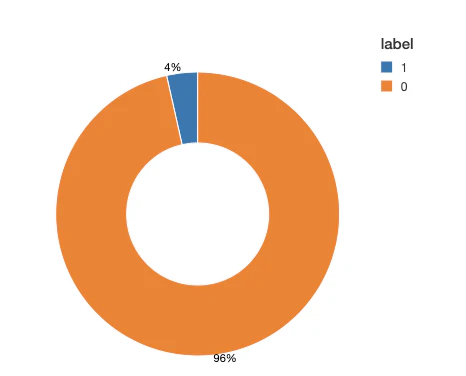
図2: トレーニングデータセットの分布
トレーニングデータを見てみると、非常にバランスの悪いデータセットとなっていることがわかります。タイムウィンドウの95%以上が診断の根拠を示していません。この不均衡を調整するために、コントロールクラスのをダウンサンプルするか、合成サンプルを生成します。この選択肢は、データセットのサイズと特徴量の数に依存します。この例では、バランスの取れたデータセットを得るために多数派のクラスをダウンサンプルします。実際には、これらの方法を組み合わせるという選択肢、例えば多数派のクラスをダウンサンプルし、トレーニングアルゴリズムにおいてクラスの重みを割り当てることも可能です。
df1 = dataset_df.filter('label==1')
n_df1=df1.count()
df2 = dataset_df.filter('label==0').sample(False,0.9).limit(n_df1)
training_dataset_df = df1.union(df2).sample(False,1.0)
display(training_dataset_df.groupBy('label').count())
モデルのトレーニング
モデルをトレーニングするために、症デモグラフィックと併存疾患の特徴量のサブセットで症状を拡張し、それぞれの観測結果にラベルを適用し、このデータを後段のトレーニングにおけるモデルに入力します。例えば、Encounterクラス(例:予防ケアによるアポイントメントか、ER訪問によるものか)、訪問のコストで最近診断された併存疾患を拡張し、デモグラフィック情報に関しては、種族、性別、ZIP、訪問時の患者の年齢を選択しました。
多くの場合、オリジナルの医療データはテラバイト規模になり、追加、除外の基準に基づいてレコードの制限、フィルタリングを行った後で、一台のマシンでトレーニングできるデータセットにする必要があります。必要なアルゴリズムに応じてモデルをトレーニングするために、容易にSparkデータフレームをpandasデータフレームに変換することができます。DatabricksのML(機械学習)ランタイムを使う際には、幅広いオープンMLライブラリにアクセスすることができます。
あらゆる機械学習アルゴリズムは一連のパラメーター(ハイパーパラメーター)を必要とし、入力パラメーターに基づいてスコアが変動します。さらに、あるケースにおいては間違ったパラメーターやアルゴリズムは過学習を引き起こします。モデルが適切に動作するように、我々はハイパーパラメーターチューニングを用いてベストなモデルアーキテクチャを選択し、このステップで得られたパラメーターを指定して最終的なモデルをトレーニングします。
モデルのチューニングを実行するために、データの前処理が必要となります。このデータセットにおいては、数値の特徴量(例えば、最近の併存疾患の数)に加え、カテゴリ変数であるデモグラフィックデータが含まれています。カテゴリ変数のデータに対するベストなアプローチはone-hotエンコーディングです。ベストであると言える理由2つあります。まず、多くの分類器(この場合はロジスティック回帰)は数値の特徴量を取り扱います。次に、シンプルにカテゴリ変数を数値のインデックスに変換すると、データに順番性を持ち込み分類器をミスリードします。例えば、カリフォルニアを5、ニューヨークを23というように州名をインデックスに変換すると、ニューヨークはカリフォルニアより「大きい」ということになります。これはそれぞれの州名のインデックスをアルファベット順に並び替えたものですが、我々のモデルの文脈においては、この順番は何の意味もありません。One-hotエンコーディングはこのような影響を除外します。
ここでの前処理のステップは、あらゆる入力パラメーターを必要とせず、ハイパーパラメーターは分類器にのみ影響を与え、前処理には影響を与えません。このため、前処理を別で実行し、得られるデータセットをモデルチューニングに使用します。
from sklearn.preprocessing import OneHotEncoder
import numpy as np
def pre_process(training_dataset_pdf):
X_pdf=training_dataset_pdf.drop('label',axis=1)
y_pdf=training_dataset_pdf['label']
onehotencoder = OneHotEncoder(handle_unknown='ignore')
one_hot_model = onehotencoder.fit(X_pdf.values)
X=one_hot_model.transform(X_pdf)
y=y_pdf.values
return(X,y)
次に、モデルに対するベストなパラメーターを選択します。この分類においては、elastic net penalizationを伴うLogisticRegressionを用います。One-hotエンコーディングを適用した後は、対象のカテゴリ変数のカーディナリティに基づいて、サンプル数を上回る大量の特徴量を取得する場合があることに注意してください。このような問題による加賀州を回避するために、目的関数にペナルティを適用します。elastic net正則化の利点は、二つの罰則化テクニック(LASSO、Ridge Regression)を組み合わせており、ハイパーパラメーターチューニングの過程で組み合わせの自由度を単一の変数で制御できるというものです。
モデルを改善するために、ベストなパラメーターを見つけ出すためにhyperoptを用いてハイパーパラメーターのグリッドを検索します。さらに、hyperoptのSparkTrialsモードを使用して、並列でハイパーパラメーター検索を行います。このプロセスにおいては、DatabricksのマネージドMLflowを活用して、それぞれのハイパーパラメーターの試行におけるパラメーターとメトリクスを自動的に記録します。それぞれのパラメーターセットを検証するために、モデルを評価するメトリクスとしてF1スコアを用いて、k-fold交差検証を行います。k-fold交差検証は複数の値を生成するため、スコアの最小値(最悪のシナリオ)を選択し、hyperoptを用いる際にはこれを最大化するようにトライします。

from math import exp
def params_to_lr(params):
return {
'penalty': 'elasticnet',
'multi_class': 'ovr',
'random_state': 43,
'n_jobs': -1,
'solver': 'saga',
'tol': exp(params['tol']), # exp() here because hyperparams are in log space
'C': exp(params['C']),
'l1_ratio': exp(params['l1_ratio'])
}
def tune_model(params):
with mlflow.start_run(run_name='tunning-logistic-regression',nested=True) as run:
clf = LogisticRegression(**params_to_lr(params)).fit(X, y)
loss = - cross_val_score(clf, X, y,n_jobs=-1, scoring='f1').min()
return {'status': STATUS_OK, 'loss': loss}
探索空間における検索を改善するために、logspaceにおけるパラメーターグリッドを選択し、hyperoptによって提案されるパラメーターを変換するための関数を定義します。このアプローチの見通しを良くするために、ハイパーパラメーターの探索空間を以下のように定義しました。詳細に関しては、DatabricksにおけるエンドツーエンドのMLライフサイクルをどのように管理するのかをカバーしている、こちらのトークをご覧になってください。
from hyperopt import fmin, hp, tpe, SparkTrials, STATUS_OK
search_space = {
# use uniform over loguniform here simply to make metrics show up better in mlflow comparison, in logspace
'tol': hp.uniform('tol', -3, 0),
'C': hp.uniform('C', -2, 0),
'l1_ratio': hp.uniform('l1_ratio', -3, -1),
}
spark_trials = SparkTrials(parallelism=2)
best_params = fmin(fn=tune_model, space=search_space, algo=tpe.suggest, max_evals=32, rstate=np.random.RandomState(43), trials=spark_trials)
このラン(試行)によって、交差検証におけるF1スコアに基づきベストなパラメーターが得られています。
params_to_lr(best_params)
Out[46]: {'penalty': 'elasticnet',
'multi_class': 'ovr',
'random_state': 43,
'n_jobs': -1,
'solver': 'saga',
'tol': 0.06555920596441883,
'C': 0.17868321158011416,
'l1_ratio': 0.27598949120226646}
次にMLflowのダッシュボードを見てみましょう。MLflowは自動的にhyperoptの全ての実行結果をグルーピングし、損失関数におけるそれぞれのハイパーパラメーターのインパクトを調査するために図3のような様々なプロットを表示することができます。これは、モデルの振る舞いとハイパーパラメーターの影響をより理解するためには非常に重要なこととなります。例えば、正則化の強さの逆数であるCの値が低い場合に、F1の値が高くなっていることに気づくことができます。
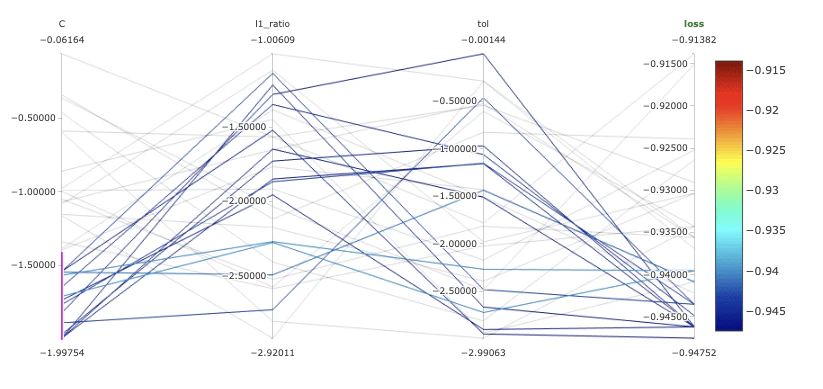
図3: MLflowにおけるモデルのパラレルコーディネートプロット
最適なパラメーターの組み合わせを見つけることで、最適なパラメーターを用いて分類器をトレーニングし、MLflowを用いてモデルを記録することができます。MLflowのモデルAPIを用いることで、トレーニングに用いたライブラリに関係なく、後ほどモデルのスコアリングに利用できるようにPythonの関数として容易にモデルを格納することができます。モデルを検索しやすくするように、対象の症状がわかるような名前をつけてモデルを記録します(このケースにおいては、"drug-overdose"など)。
import mlflow.sklearn
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from mlflow.models.signature import infer_signature
## since we want the model to output probabilities (risk) rather than predicted labels, we overwrite
## mlflow.pyfun's predict method:
class SklearnModelWrapper(mlflow.pyfunc.PythonModel):
def __init__(self, model):
self.model = model
def predict(self, context, model_input):
return self.model.predict_proba(model_input)[:,1]
def train(params):
with mlflow.start_run(run_name='training-logistic-regression',nested=True) as run:
mlflow.log_params(params_to_lr(params))
X_arr=training_dataset_pdf.drop('label',axis=1).values
y_arr=training_dataset_pdf['label'].values
ohe = OneHotEncoder(handle_unknown='ignore')
clf = LogisticRegression(**params_to_lr(params)).fit(X, y)
pipe = Pipeline([('one-hot', ohe), ('clf', clf)])
lr_model = pipe.fit(X_arr, y_arr)
score=cross_val_score(clf, ohe.transform(X_arr), y_arr,n_jobs=-1, scoring='accuracy').mean()
wrapped_lr_model = SklearnModelWrapper(lr_model)
model_name= '-'.join(condition.split())
mlflow.log_metric('accuracy',score)
mlflow.pyfunc.log_model(model_name, python_model=wrapped_lr_model)
displayHTML('The model accuracy is: %s '%(score))
return(mlflow.active_run().info)
次に、以前のステップで得られたベストなパラメーターを指定してモデルをトレーニングします。
モデルトレーニングにおいては、sklearnパイプラインの一部に前処理(one-hotエンコーディング)を含めており、エンコーダーと、分類器を一つのモデルとして記録しています。次のステップでは、シンプルに患者データに対してモデルを呼び出し、彼らのリスクを評価します。
モデルのデプロイメント、本格運用
モデルをトレーニングしMLflowに記録した後、次のステップは新たなデータに対してモデルを用いてスコアリングすることになります。MLflowの機能の一つとして、異なるタグに基いてエクスペリメントを検索することができます。例えば、トレーニングモデルのアーティファクトURIを取得するためにランの名前を使用します。その後、キーとなるメトリクスに基づいて取得したエクスペリメントを並び替えます。
import mlflow
best_run=mlflow.search_runs(filter_string="tags.mlflow.runName = 'training-logistic-regression'",order_by=['metrics.accuracy DESC']).iloc[0]
model_name='drug-overdose'
clf=mlflow.pyfunc.load_model(model_uri="%s/%s"%(best_run.artifact_uri,model_name))
clf_udf=mlflow.pyfunc.spark_udf(spark, model_uri="%s/%s"%(best_run.artifact_uri,model_name))
特定のモデルを選択した後で、モデルのURIや名前を指定することでモデルをロードすることができます。

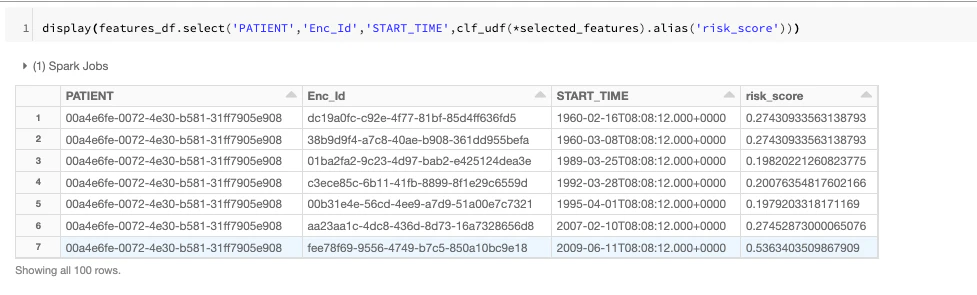
モデルのバージョン、運用ステータスを管理し、モデルサービングを活用するためにDatabricksのモデルレジストリを利用することもできます。
疾病予測を高精度予防に結びつける
この記事では、持病の初期症状につながる医療、デモグラフィックの共変量を特定するための高精度予防システムに対するニーズをウォークスルーしました。そして、薬のオーバードーズのリスクが高い患者を特定するために、EHRから生成されたデータを用いたエンドツーエンドの機械学習ワークフローを見ました。ワークフローの最後では、MLflowからトレーニングしたMLモデルをエクスポートすることができ、患者データの新たなストリームに適用することができます。
このモデルは有益な示唆を提供しますが、実践しない限りインパクトを引き起こすものではありません。リアルワールドでの実践では、我々は多くのお客様と協働することで、これと同様なシステムを実運用にまで持って行きました。例えば、Medical University of South Carolinaにおいては、敗血症のリスクがある患者を特定するために、EHRデータを処理するライブストリーミングのパイプラインをデプロイしました。これによって、8時間前に敗血症に関係する患者の減少を検知することができました。INTEGRIS Healthにおける類似システムにおいては、褥瘡の兆候を検知するためにEHRのデータがモニタリングされました。両方のケースにおいて、患者が識別された際には、ケアチームに症状がアラートされます。生命保険のケースでは、同様のモデルをデプロイするためにOptumと協働しました。9つの異なる一平領域に対して適切な一般化を行い、病気の進行を識別するための長期、短期のアーキテクチャでリカレントニューラルネットワークを用いた疾病予測エンジンを構築することができました。このモデルは、患者に予防ケアのロードマップを割り当てるために用いられ、持病を持つ患者の予後および治療費を改善しました。
我々の記事の多くはヘルスケア領域における疾病予測アルゴリズムの活用にフォーカスしていますが、これらのモデルを製薬領域にデプロイする強力なオポチュニティがあります。疾病予測モデルは、薬の販売後どのように用いられているのかに対する洞察を提供し、これまでは検知されていなかった防御作用を検知し、ラベル表記の拡大につなげるすることも可能となりました。加えて、疾病予測モデルは、稀有あるいはこれまで診断さていなかった疾病に対する臨床試験を検討する際にも有用です。希少疾患の診断を受ける前に誤診された患者を検知するモデルを構築することで、一般的な誤診パターンに関して、研修医を教育する教育素材を作成することができ、望ましくは、試験登録数、効率を高めるための試験参加の指標を作成することができます。
医療Delta Lakeで高精度予防を始めてみる
この記事では、持病の兆候において高リスクの患者を識別するために、どのようにリアルワールドデータに対して機械学習を用いるのかをデモンストレーションしました。医療データセットを格納、処理するためのDelta Lakeの使い方に関しては、リアルワールド医療データセットを取り扱っているフリーのeBookをダウンロードしてください。この記事で触れられている患者リスクのスコアリングノートブックを利用することもできます。