こちらの記事のリポジトリのコードを翻訳しながら動かしてみます。
オリジナルのリポジトリはこちら。
翻訳版はこちら。
構成
全体の流れはこちらです。
ユーザークエリ
↓
LangGraphエージェント(MCP利用)
↓
├── Managed MCP: Genie Space(query_spaceツール)
│ ↓
│ データをJSONで返却
│
├── Managed MCP: UC関数(genie_to_chart)
│ ↓
│ JSON→Plotlyチャートに変換
│
└── 可視化をユーザーに返却
この記事の構成(Databricksエージェントエンドポイント+マネージドMCP)のメリットをまとめます。
この構成のメリット
1. エンドツーエンドのマネージドインフラ
- MCPサーバーの自動管理: GenieスペースやUC関数を作成すると、Databricksが自動的にMCPサーバー経由で利用可能にしてくれる
- 認証の自動化: WorkspaceClientが認証を自動処理するため、複雑な認証設定が不要
-
デプロイメントの簡素化:
agents.deploy()一発でモデルサービングエンドポイントが構築できる
2. ツールの柔軟な組み合わせ
- Genie(Text-to-SQL): 自然言語をSQLに変換し、データウェアハウスにクエリー
- UC関数(カスタムロジック): Plotlyによる可視化などのカスタム処理をPython関数として定義し、依存関係も指定可能
- LangGraphによるオーケストレーション: ツール呼び出しの流れを柔軟に制御
3. 本番運用を見据えた機能
- MLflowによるトレーシング: エージェントの動作を追跡・デバッグ可能
- レビューアプリ: 専門家がフィードバックを提供する仕組みが標準装備
- AI Playground: デプロイ前のテストが容易
4. セキュリティとガバナンス
- Unity Catalogとのネイティブ統合: データアクセス権限がそのまま適用される
- ユーザー認証: Databricks Appsでエンドユーザーの認証を自動処理
5. 開発効率
- SQLの知識不要でデータ分析: ビジネスユーザーが自然言語で質問可能
- 可視化の自動生成: チャートの設定を手動で行う必要がない
- 会話のコンテキスト保持: マルチターンの対話に対応
要するに、MCPをDatabricksがマネージドで提供することで、インフラ構築・認証・デプロイの複雑さを排除しつつ、本番品質のAIエージェントを迅速に構築できる点が最大のメリットです。
事前の準備
MCP経由でアクセスするGenieスペースを作成しておきます。
GenieスペースのIDをコピーしておきます。URLのrooms/と?の間の文字がIDとなります。

01-uc-plotting-function
ライブラリのインストールとPython再起動
%pip install -qqqq -U unitycatalog-ai[databricks] databricks-agents databricks-mcp
dbutils.library.restartPython()
このノートブックは、データ分析や機械学習のプロジェクトを実行するための環境を提供します。以下に、ノートブックの概要と使い方を説明します。
概要
- データの読み込み、前処理、分析、可視化、モデルの構築と評価を行うためのコードが含まれています。
- Pythonの主要なライブラリ(Pandas、NumPy、Matplotlib、Scikit-learnなど)を使用しています。
使い方
- データの読み込み: 最初に、分析したいデータセットを読み込みます。CSVファイルやExcelファイルなど、さまざまな形式に対応しています。
- データの前処理: 欠損値の処理やデータの変換を行います。必要に応じて、データのクリーニングを行います。
- データの分析: データの基本的な統計量を計算したり、相関関係を調べたりします。
- データの可視化: MatplotlibやSeabornを使用して、データの可視化を行います。グラフやチャートを作成して、データの理解を深めます。
- モデルの構築と評価: 機械学習モデルを構築し、評価指標を用いてモデルの性能を評価します。
このノートブックを使用することで、データ分析のプロセスを効率的に進めることができます。
ノートブックのセットアップと警告の非表示
%load_ext autoreload
%autoreload 2
import warnings
warnings.simplefilter(action="ignore")
データベースカタログとスキーマのウィジェット設定
dbutils.widgets.text(name="catalog", defaultValue="catalog", label="カタログ")
dbutils.widgets.text(name="schema", defaultValue="schema", label="スキーマ")
dbutils.widgets.text(name="space_id", defaultValue="space", label="スペースID")
Databricks関数クライアントの設定
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = dbutils.widgets.get("catalog")
SCHEMA = dbutils.widgets.get("schema")
SPACE_ID = dbutils.widgets.get("space_id")
Genie MCPレスポンスをPlotlyチャートへ変換
def genie_to_chart(genie_response_json: str, chart_type: str) -> str:
"""
Genie MCPのレスポンスをPlotlyチャートに変換します。
この関数はGenieのネストされたJSON形式からデータ抽出と変換を行います。
引数:
genie_response_json (str): Genie MCPのquery_spaceツールからの生JSON文字列
chart_type (str): チャートタイプ - "bar", "line", "pie"
戻り値:
str: Plotly用JSON文字列(Plotlyで直接レンダリング可能)
"""
import json
import plotly.express as px
import pandas as pd
# Genieレスポンスのパース(ラッパー有無両対応)
genie_data = json.loads(genie_response_json)
# 'content'フィールドがあればパース(二重パース対応)
if "content" in genie_data:
content_data = (
json.loads(genie_data["content"])
if isinstance(genie_data["content"], str)
else genie_data["content"]
)
else:
# すでにcontent(ラッパーなし)
content_data = genie_data
# statement_responseからカラムと行を抽出
columns_info = content_data["statement_response"]["manifest"]["schema"]["columns"]
column_names = [col["name"] for col in columns_info]
data_array = content_data["statement_response"]["result"]["data_array"]
rows = [[value["string_value"] for value in row["values"]] for row in data_array]
# DataFrame作成
df = pd.DataFrame(rows, columns=column_names)
# すべてのカラムを適切な型に変換
for col in df.columns:
df[col] = pd.to_numeric(df[col], errors="ignore")
# カラム選択:Xは文字列型、Yは最後の数値型
string_cols = df.select_dtypes(include=["object", "string"]).columns
numeric_cols = df.select_dtypes(include="number").columns
x_col = string_cols[0] if len(string_cols) > 0 else df.columns[0]
y_col = numeric_cols[-1] if len(numeric_cols) > 0 else df.columns[-1]
# チャート生成
chart_functions = {
"bar": lambda: px.bar(df, x=x_col, y=y_col, title=f"{y_col} by {x_col}"),
"line": lambda: px.line(
df, x=x_col, y=y_col, title=f"{y_col} by {x_col}", markers=True
),
"pie": lambda: px.pie(
df, names=x_col, values=y_col, title=f"{y_col} by {x_col}"
),
}
chart_type_key = chart_type.lower().strip()
if chart_type_key not in chart_functions:
raise ValueError(f"未対応のチャートタイプです: {chart_type}")
fig = chart_functions[chart_type_key]()
# Plotly JSONで構造化レスポンスを返す
response = {
"plotly_json": json.loads(fig.to_json()),
"chart_type": chart_type_key,
}
return json.dumps(response)
# 関数を作成し、依存関係をPyPI形式で指定
client.create_python_function(
func=genie_to_chart,
catalog=CATALOG,
schema=SCHEMA,
replace=True,
dependencies=["plotly", "pandas"],
)
02-langgraph-mcp-tool-calling-agent
Mosaic AIエージェントフレームワーク:MCPツールコールLangGraphエージェントの作成とデプロイ
このノートブックでは、Databricks上でホストされているMCPサーバーに接続するLangGraphエージェントの作成方法を説明します。Databricks管理のMCPサーバー、DatabricksアプリとしてホストされたカスタムMCPサーバー、または両方を同時に利用できます。詳細はMCP on Databricksをご覧ください。
このノートブックは、Mosaic AIの機能と互換性のあるResponsesAgentインターフェースを使用します。以下の内容を学びます:
- MCPツールを呼び出すLangGraphエージェント(
ResponsesAgentでラップ)を作成 - エージェントの手動テスト
- Mosaic AI Agent Evaluationによるエージェント評価
- エージェントのログとデプロイ
Mosaic AI Agent Frameworkを使ったエージェント作成の詳細は、Databricksドキュメント(AWS | Azure)をご覧ください。
前提条件
- このノートブック内の
TODOをすべて対応してください。
Databricksパッケージのインストールとアップデート
%pip install -U -qqqq databricks-langchain databricks-mcp langgraph==0.5.3 uv databricks-agents mlflow-skinny[databricks]
dbutils.library.restartPython()
エージェントコードの定義
下のセルでエージェントコードを一括定義します。%%writefileマジックコマンドを使ってローカルPythonファイルに書き出し、後でログやデプロイに利用できます。
このセルでは、Databricks MCPサーバーとMosaic AI Agent Frameworkを統合した柔軟なツール利用エージェントを作成します。概要は以下の通りです:
-
MCPツールラッパー
LangChainツールがDatabricks MCPサーバーと連携できるようにカスタムラッパークラスを定義します。Databricks管理MCP、カスタムMCP、両方に接続可能です。 -
ツールの自動検出と登録
指定したMCPサーバーから利用可能なツールを自動検出し、スキーマをPythonオブジェクト化してLLMに準備します。 -
LangGraphエージェントロジックの定義
エージェントワークフローを定義します:- エージェントはメッセージ(会話履歴)を読み取ります。
- ツール(関数)コールが要求された場合、適切なMCPツールを実行します。
- 必要に応じて複数回ツールコールを行い、最終回答が準備できるまでループします。
-
ResponsesAgentでLangGraphエージェントをラップ
Mosaic AI互換のためResponsesAgentでラップします。 -
MLflow自動トレーシング
MLflowの自動ロギングを有効化します。
カタログ・スキーマ・スペースIDのウィジェット入力
dbutils.widgets.text(name="catalog", defaultValue="catlog", label="カタログ")
dbutils.widgets.text(name="schema", defaultValue="schema", label="スキーマ")
dbutils.widgets.text(name="space_id", defaultValue="space", label="スペースID")
ウィジェットからカタログ・スキーマ・スペースIDを取得
CATALOG = dbutils.widgets.get("catalog")
SCHEMA = dbutils.widgets.get("schema")
SPACE_ID = dbutils.widgets.get("space_id")
Databricksエージェント設定のセットアップ
%%writefile agent.py
import asyncio
import mlflow
import os
import json
from uuid import uuid4
from pydantic import BaseModel, create_model
from typing import Annotated, Any, Generator, List, Optional, Sequence, TypedDict, Union
from databricks_langchain import (
ChatDatabricks,
UCFunctionToolkit,
VectorSearchRetrieverTool,
)
from databricks_mcp import DatabricksOAuthClientProvider, DatabricksMCPClient
from databricks.sdk import WorkspaceClient
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
convert_to_openai_messages,
)
from langchain_core.tools import BaseTool, tool
from langgraph.graph import END, StateGraph
from langgraph.graph.message import add_messages
from langgraph.graph.state import CompiledStateGraph
from langgraph.prebuilt.tool_node import ToolNode
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client as connect
from mlflow.entities import SpanType
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
import nest_asyncio
nest_asyncio.apply()
############################################
## Databricksエージェント構成セットアップ
## (このagent.pyファイルにエージェントロジックを定義します)
############################################
# TODO: モデルサービングエンドポイント名を指定してください
LLM_ENDPOINT_NAME = "databricks-claude-sonnet-4"
llm = ChatDatabricks(endpoint=LLM_ENDPOINT_NAME)
# TODO: システムプロンプトを必要に応じて編集してください
system_prompt = """
あなたはデータのクエリやチャート作成ができる有能なアシスタントです。
ワークフロー:
1. ユーザーがデータやチャートを求めた場合、query_space_01f0ab8c079d17b8a00584e70d2ac18cを呼び出してデータを取得してください
2. ユーザーがチャートを希望した場合、chat_app_demo__dev__genie_to_chartを必ず1回だけ呼び出してください:
- genie_response_json: query_spaceからの生のJSONレスポンス全体
- chart_type: "bar", "line", "pie"
3. genie_to_chartを呼び出したら即座に停止し、簡単な要約を返してください
重要なルール:
- ツール名は必ず正確に: query_space_01f0ab8c079d17b8a00584e70d2ac18c, chat_app_demo__dev__genie_to_chart
- genie_to_chartは1リクエストにつき1回のみ呼び出してください。複数回呼び出してはいけません
- genie_to_chartの返却後はツール呼び出しを終了してください(チャートは既に作成済みです)
- データ再取得やチャート再作成は不要です。1つのチャートで十分です"""
###############################################################################
## エージェント用MCPサーバーの設定
## このセクションでサーバー接続を設定し、エージェントがデータ取得やアクションを実行できるようにします。
###############################################################################
# TODO: MCPサーバー接続方式を選択してください。
# ----- シンプル: 管理MCPサーバー(追加設定不要) -----
# Databricksワークスペース設定とPAT認証を利用します。
workspace_client = WorkspaceClient()
CATALOG = "takaakiyayoi_catalog"
SCHEMA = "plotting_agent"
GENIE_SPACE_ID = "01f0e9f8d07b12dcb3675343a4fa97bf"
# 管理MCPサーバー: デフォルト設定ですぐ利用可能
host = workspace_client.config.host
MANAGED_MCP_SERVER_URLS = [
f"{host}/api/2.0/mcp/functions/{CATALOG}/{SCHEMA}",
f"{host}/api/2.0/mcp/genie/{GENIE_SPACE_ID}",
]
# ----- 上級者向け(任意): カスタムMCPサーバー(OAuth必須) -----
# Databricks AppsでカスタムMCPサーバーを利用する場合は、サービスプリンシパルによるOAuth認証が必要です。
# 必要な場合のみ下記をアンコメントし、設定してください。
#
# import os
# workspace_client = WorkspaceClient(
# host="<DATABRICKS_WORKSPACE_URL>",
# client_id=os.getenv("DATABRICKS_CLIENT_ID"),
# client_secret=os.getenv("DATABRICKS_CLIENT_SECRET"),
# auth_type="oauth-m2m", # マシン間OAuthを有効化
# )
# カスタムMCPサーバー: 必要に応じてURLを追加(上記OAuth設定必須)
CUSTOM_MCP_SERVER_URLS = [
# 例: "https://<custom-mcp-url>/mcp"
]
#####################
## MCPツール生成
#####################
# MCPサーバー呼び出し用LangChainツールのカスタムクラス
class MCPTool(BaseTool):
"""MCPサーバー機能をラップするカスタムLangChainツール"""
def __init__(
self,
name: str,
description: str,
args_schema: type,
server_url: str,
ws: WorkspaceClient,
is_custom: bool = False,
):
# ツール初期化
super().__init__(name=name, description=description, args_schema=args_schema)
# MCPサーバーURL、ワークスペースクライアント、カスタムサーバーフラグを保持
object.__setattr__(self, "server_url", server_url)
object.__setattr__(self, "workspace_client", ws)
object.__setattr__(self, "is_custom", is_custom)
def _run(self, **kwargs) -> str:
"""MCPツールを実行"""
if self.is_custom:
# カスタムMCPサーバーは非同期メソッドを利用(OAuth必須)
return asyncio.run(self._run_custom_async(**kwargs))
else:
# 管理MCPサーバーは同期呼び出し
mcp_client = DatabricksMCPClient(
server_url=self.server_url, workspace_client=self.workspace_client
)
response = mcp_client.call_tool(self.name, kwargs)
return "".join([c.text for c in response.content])
async def _run_custom_async(self, **kwargs) -> str:
"""カスタムMCPツールを非同期実行"""
async with connect(
self.server_url, auth=DatabricksOAuthClientProvider(self.workspace_client)
) as (
read_stream,
write_stream,
_,
):
# サーバーと非同期セッションを作成しツールを呼び出す
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
response = await session.call_tool(self.name, kwargs)
return "".join([c.text for c in response.content])
# カスタムMCPサーバーからツール定義を取得(OAuth必須)
async def get_custom_mcp_tools(ws: WorkspaceClient, server_url: str):
"""カスタムMCPサーバーからツール一覧を取得"""
async with connect(server_url, auth=DatabricksOAuthClientProvider(ws)) as (
read_stream,
write_stream,
_,
):
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
tools_response = await session.list_tools()
return tools_response.tools
# 管理MCPサーバーからツール定義を取得
def get_managed_mcp_tools(ws: WorkspaceClient, server_url: str):
"""管理MCPサーバーからツール一覧を取得"""
mcp_client = DatabricksMCPClient(server_url=server_url, workspace_client=ws)
return mcp_client.list_tools()
# MCPツール定義からLangChainツールを生成
def create_langchain_tool_from_mcp(
mcp_tool, server_url: str, ws: WorkspaceClient, is_custom: bool = False
):
"""MCPツール定義からLangChainツールを生成"""
schema = mcp_tool.inputSchema.copy()
properties = schema.get("properties", {})
required = schema.get("required", [])
# JSONスキーマ型→Python型マッピング
TYPE_MAPPING = {"integer": int, "number": float, "boolean": bool}
field_definitions = {}
for field_name, field_info in properties.items():
field_type_str = field_info.get("type", "string")
field_type = TYPE_MAPPING.get(field_type_str, str)
if field_name in required:
field_definitions[field_name] = (field_type, ...)
else:
field_definitions[field_name] = (field_type, None)
# Pydanticスキーマを動的生成
args_schema = create_model(f"{mcp_tool.name}Args", **field_definitions)
# MCPToolインスタンスを返す
return MCPTool(
name=mcp_tool.name,
description=mcp_tool.description or f"Tool: {mcp_tool.name}",
args_schema=args_schema,
server_url=server_url,
ws=ws,
is_custom=is_custom,
)
# 管理・カスタムMCPサーバーから全ツールを収集
async def create_mcp_tools(
ws: WorkspaceClient,
managed_server_urls: List[str] = None,
custom_server_urls: List[str] = None,
) -> List[MCPTool]:
"""管理・カスタムMCPサーバーからLangChainツールを生成"""
tools = []
if managed_server_urls:
# 管理MCPツールをロード
for server_url in managed_server_urls:
try:
mcp_tools = get_managed_mcp_tools(ws, server_url)
for mcp_tool in mcp_tools:
tool = create_langchain_tool_from_mcp(
mcp_tool, server_url, ws, is_custom=False
)
tools.append(tool)
except Exception as e:
print(f"管理サーバー{server_url}からのツール取得エラー: {e}")
if custom_server_urls:
# カスタムMCPツールを非同期ロード
for server_url in custom_server_urls:
try:
mcp_tools = await get_custom_mcp_tools(ws, server_url)
for mcp_tool in mcp_tools:
tool = create_langchain_tool_from_mcp(
mcp_tool, server_url, ws, is_custom=True
)
tools.append(tool)
except Exception as e:
print(f"カスタムサーバー{server_url}からのツール取得エラー: {e}")
return tools
#####################
## エージェントロジック定義
#####################
# エージェントワークフローの状態(会話履歴やカスタムデータを保持)
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
custom_inputs: Optional[dict[str, Any]]
custom_outputs: Optional[dict[str, Any]]
# ツールコール可能なLangGraphエージェントを定義
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolNode, Sequence[BaseTool]],
system_prompt: Optional[str] = None,
):
model = model.bind_tools(tools) # モデルにツールをバインド
# 最後のメッセージに応じて継続/終了を判定
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
# 関数(ツール)コールがあれば継続、なければ終了
if isinstance(last_message, AIMessage) and last_message.tool_calls:
return "continue"
else:
return "end"
# 必要に応じてシステムプロンプトを会話履歴に前置
if system_prompt:
preprocessor = RunnableLambda(
lambda state: [{"role": "system", "content": system_prompt}]
+ state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model # 前処理とモデルを連結
# ワークフロー内でモデルを呼び出す関数
def call_model(
state: AgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(AgentState) # エージェントの状態遷移グラフ
workflow.add_node("agent", RunnableLambda(call_model)) # エージェントノード(LLM)
workflow.add_node("tools", ToolNode(tools)) # ツールノード
workflow.set_entry_point("agent") # エントリポイント
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools", # モデルがツールコールを要求したらtoolsノードへ
"end": END, # それ以外は終了
},
)
workflow.add_edge("tools", "agent") # ツール実行後はagentノードへ戻る
# コンパイルして返す
return workflow.compile()
# Mosaic AI Responses API互換のためResponsesAgentでラップ
class LangGraphResponsesAgent(ResponsesAgent):
def __init__(self, agent):
self.agent = agent
# LangChainメッセージ→Responses形式辞書に変換
def _langchain_to_responses(
self, messages: list[BaseMessage]
) -> list[dict[str, Any]]:
"""LangChainメッセージをResponses出力アイテム辞書に変換"""
for message in messages:
message = message.model_dump() # モデル→辞書
role = message["type"]
if role == "ai":
if tool_calls := message.get("tool_calls"):
# ツールコールがあればfunction callアイテムを返す
return [
self.create_function_call_item(
id=message.get("id") or str(uuid4()),
call_id=tool_call["id"],
name=tool_call["name"],
arguments=json.dumps(tool_call["args"]),
)
for tool_call in tool_calls
]
else:
# 通常のAIテキストメッセージ
return [
self.create_text_output_item(
text=message["content"],
id=message.get("id") or str(uuid4()),
)
]
elif role == "tool":
# ツール実行結果
return [
self.create_function_call_output_item(
call_id=message["tool_call_id"],
output=message["content"],
)
]
elif role == "user":
# ユーザーメッセージはそのまま
return [message]
# エージェントの単発予測
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
outputs = [
event.item
for event in self.predict_stream(request)
if event.type == "response.output_item.done" or event.type == "error"
]
return ResponsesAgentResponse(
output=outputs, custom_outputs=request.custom_inputs
)
# エージェントのストリーム予測
def predict_stream(
self,
request: ResponsesAgentRequest,
) -> Generator[ResponsesAgentStreamEvent, None, None]:
cc_msgs = self.prep_msgs_for_cc_llm([i.model_dump() for i in request.input])
# エージェントグラフからイベントをストリーム
for event in self.agent.stream(
{"messages": cc_msgs}, stream_mode=["updates", "messages"]
):
if event[0] == "updates":
# ワークフローノードからの更新メッセージをストリーム
for node_data in event[1].values():
if "messages" in node_data:
for item in self._langchain_to_responses(node_data["messages"]):
yield ResponsesAgentStreamEvent(
type="response.output_item.done", item=item
)
elif event[0] == "messages":
# 生成テキストメッセージチャンクをストリーム
try:
chunk = event[1][0]
if isinstance(chunk, AIMessageChunk) and (content := chunk.content):
yield ResponsesAgentStreamEvent(
**self.create_text_delta(delta=content, item_id=chunk.id),
)
except:
pass
# MCPツール・ワークフローを初期化
def initialize_agent():
"""MCPツール付きエージェントを初期化"""
# 設定済みサーバーからMCPツールを生成
mcp_tools = asyncio.run(
create_mcp_tools(
ws=workspace_client,
managed_server_urls=MANAGED_MCP_SERVER_URLS,
custom_server_urls=CUSTOM_MCP_SERVER_URLS,
)
)
# LLM・ツール・システムプロンプトでエージェントグラフを生成
agent = create_tool_calling_agent(llm, mcp_tools, system_prompt)
return LangGraphResponsesAgent(agent)
mlflow.langchain.autolog()
AGENT = initialize_agent()
mlflow.models.set_model(AGENT)
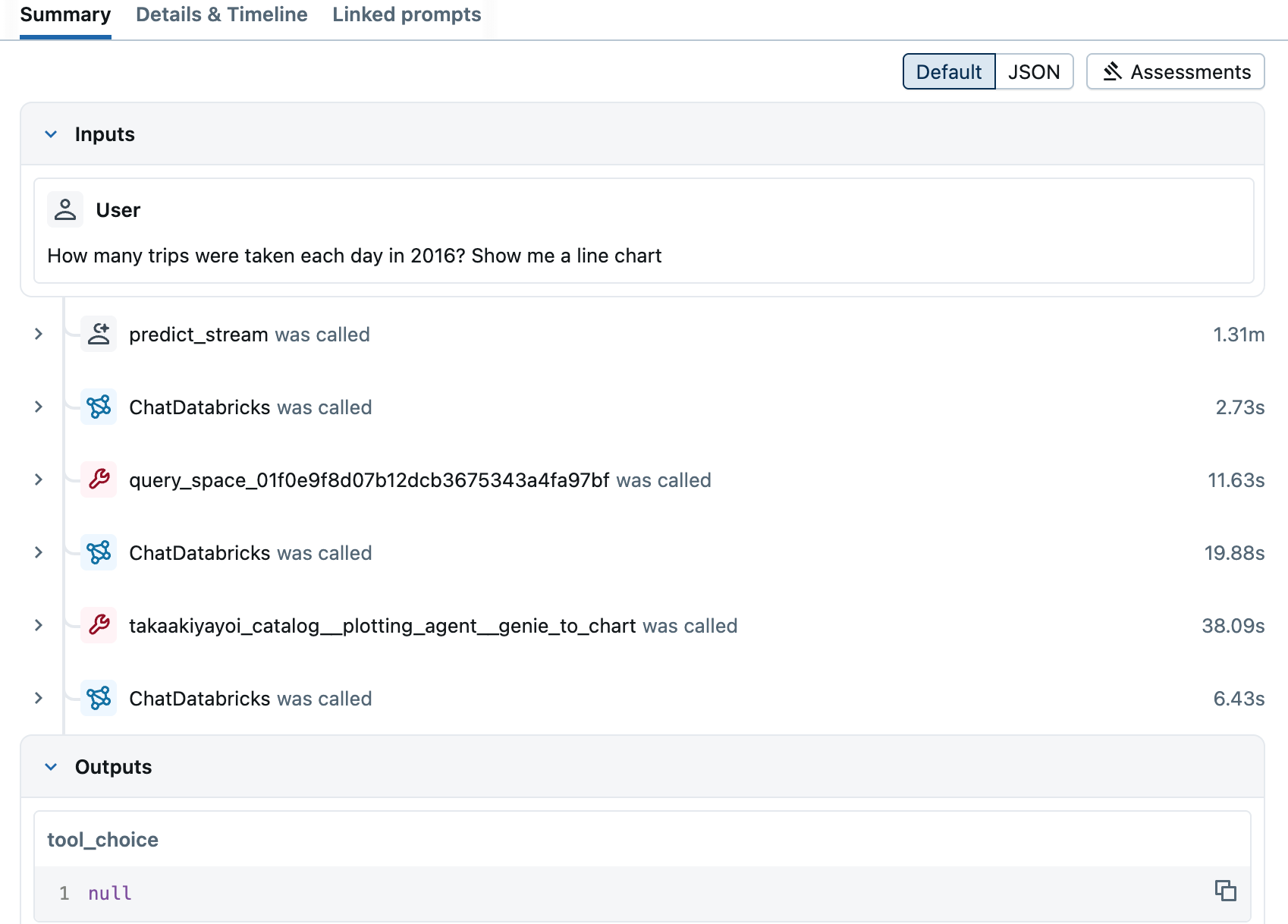
エージェントのテスト
エージェントと対話して、出力やツールコール機能をテストします。mlflow.langchain.autolog()を呼び出しているため、各ステップのトレースを確認できます。
dbutils.library.restartPython()
from agent import AGENT
AGENT.predict(
{
"input": [
{
"role": "user",
"content": "How many trips were taken each day in 2016? Show me a line chart",
}
]
}
)
エージェントをMLflowモデルとしてログ
agent.pyファイルのコードをMLflowモデルとしてログします。詳細はDatabricks MCPサーバーに接続するエージェントのデプロイをご覧ください。
# 上でPythonカーネルを再起動しているので再度ウィジェットから値を取得
CATALOG = dbutils.widgets.get("catalog")
SCHEMA = dbutils.widgets.get("schema")
SPACE_ID = dbutils.widgets.get("space_id")
DatabricksエージェントのMLflow構成セットアップ
import mlflow
from agent import LLM_ENDPOINT_NAME
from mlflow.models.resources import (
DatabricksServingEndpoint,
DatabricksFunction,
DatabricksGenieSpace,
DatabricksTable,
)
from mlflow.models.auth_policy import AuthPolicy, SystemAuthPolicy, UserAuthPolicy
from pkg_resources import get_distribution
# MLflowリソースの定義
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
DatabricksFunction(function_name=f"{CATALOG}.{SCHEMA}.genie_to_chart"),
DatabricksGenieSpace(genie_space_id=SPACE_ID),
DatabricksTable(table_name="samples.nyctaxi.trips"),
]
# システムポリシー: システム認証情報でリソースにアクセス
system_policy = SystemAuthPolicy(resources=resources)
# ユーザーポリシー: OBOアクセス用APIスコープ
api_scopes = [
"sql.statement-execution",
"mcp.genie",
"mcp.external",
"catalog.connections",
"mcp.vectorsearch",
"vectorsearch.vector-search-indexes",
"iam.current-user:read",
"sql.warehouses",
"dashboards.genie",
"serving.serving-endpoints",
"iam.access-control:read",
"apps.apps",
"mcp.functions",
"vectorsearch.vector-search-endpoints",
]
user_policy = UserAuthPolicy(api_scopes=api_scopes)
# 入力例
input_example = {
"input": [
{
"role": "user",
"content": "How many trips were taken each day in 2016? Show me a line chart",
}
]
}
# MLflowモデルのログ
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
name="agent",
python_model="agent.py",
input_example=input_example,
resources=resources,
pip_requirements=[
"databricks-mcp",
f"langgraph=={get_distribution('langgraph').version}",
f"mcp=={get_distribution('mcp').version}",
f"databricks-langchain=={get_distribution('databricks-langchain').version}",
],
# 認証ポリシーを設定する場合は下記を有効化
# auth_policy=AuthPolicy(
# system_auth_policy=system_policy, user_auth_policy=user_policy
# ),
)
デプロイ前のエージェント検証
エージェントを登録・デプロイする前に、mlflow.models.predict() APIで事前チェックを行います。詳細はDatabricksドキュメント(AWS | Azure)をご覧ください。
mlflow.models.predict(
model_uri=f"runs:/{logged_agent_info.run_id}/agent",
input_data={
"input": [
{
"role": "user",
"content": "How many trips were taken each day in 2016? Show me a line chart",
}
]
},
env_manager="uv",
)
Unity Catalogへのモデル登録
エージェントをデプロイする前に、MLflowモデルをUnity Catalogに登録してください。
-
TODO 下記の
catalog、schema、model_nameを更新して、MLflowモデルをUnity Catalogに登録してください。
mlflow.set_registry_uri("databricks-uc")
# TODO: UCモデル用のカタログ、スキーマ、モデル名を定義してください
model_name = "managed-mcp-model"
UC_MODEL_NAME = f"{CATALOG}.{SCHEMA}.{model_name}"
# モデルをUnity Catalogに登録
uc_registered_model_info = mlflow.register_model(
model_uri=logged_agent_info.model_uri, name=UC_MODEL_NAME
)
エージェントのデプロイ
from databricks import agents
agents.deploy(
UC_MODEL_NAME,
uc_registered_model_info.version,
# ==============================================================================
# TODO: 下記のenvironment_varsセクションは、カスタムMCPサーバー(OAuth/サービスプリンシパル利用時)のみ設定してください。
# 管理MCP(デフォルト)の場合はコメントアウトのままにしてください。
# ==============================================================================
#environment_vars={
# "DATABRICKS_HOST": "{{secrets/dbdemos/DATABRICKS_HOST}}",
# "DATABRICKS_CLIENT_ID": "{{secrets/dbdemos/DATABRICKS_CLIENT_ID}}",
# "DATABRICKS_CLIENT_SECRET": "{{secrets/dbdemos/DATABRICKS_CLIENT_SECRET}}",
#},
tags={"endpointSource": "docs"},
)
from databricks import agents
# 個別ユーザーやグループを指定可能です。
agents.set_permissions(
model_name=UC_MODEL_NAME,
users=["users"],
permission_level=agents.PermissionLevel.CAN_QUERY,
)
次のステップ
エージェントのデプロイ後は、AIプレイグラウンドで追加チェックを行ったり、社内のSMEに共有してフィードバックを得たり、プロダクションアプリケーションに統合したりできます。詳細はDatabricksドキュメント(AWS | Azure)をご覧ください。
# エンドポイントのデプロイ状態監視
import time
from databricks.sdk.service.serving import EndpointStateReady, EndpointStateConfigUpdate
from databricks.sdk import WorkspaceClient
endpoint_name: str = f"agents_{CATALOG}-{SCHEMA}-{model_name}"
print("\nエンドポイントのデプロイを待機中です(10〜20分かかる場合があります)", end="")
w = WorkspaceClient()
while (
w.serving_endpoints.get(endpoint_name).state.ready == EndpointStateReady.NOT_READY
or w.serving_endpoints.get(endpoint_name).state.config_update
== EndpointStateConfigUpdate.IN_PROGRESS
):
print(".", end="")
time.sleep(30)
エンドポイントのデプロイを待機中です(10〜20分かかる場合があります).............
# Databricksエンドポイントへのクエリ実行例
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
endpoint_name: str = f"agents_{CATALOG}-{SCHEMA}-{model_name}"
response = w.serving_endpoints.query(
name=endpoint_name,
dataframe_records=[
{
"input": [
{
"role": "user",
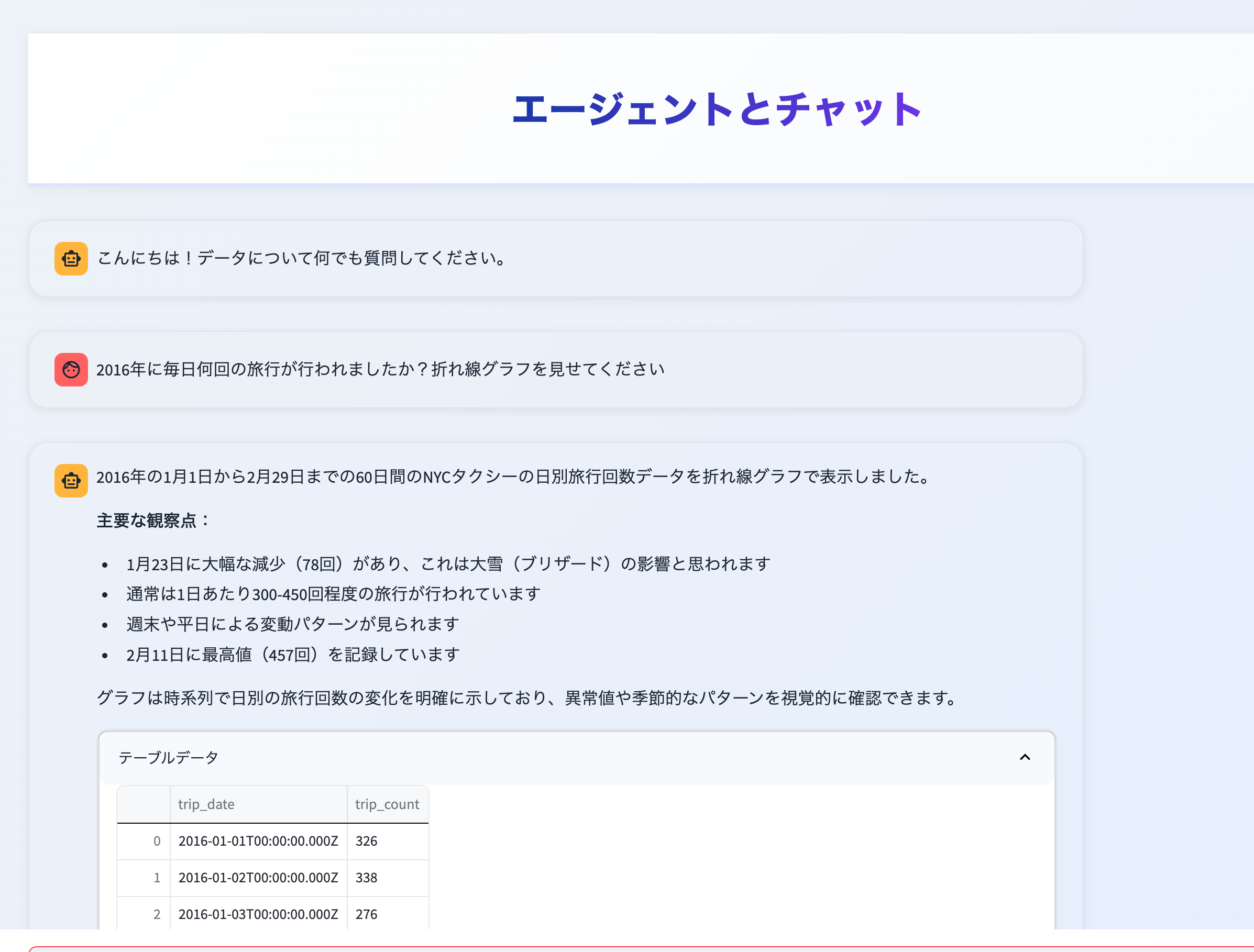
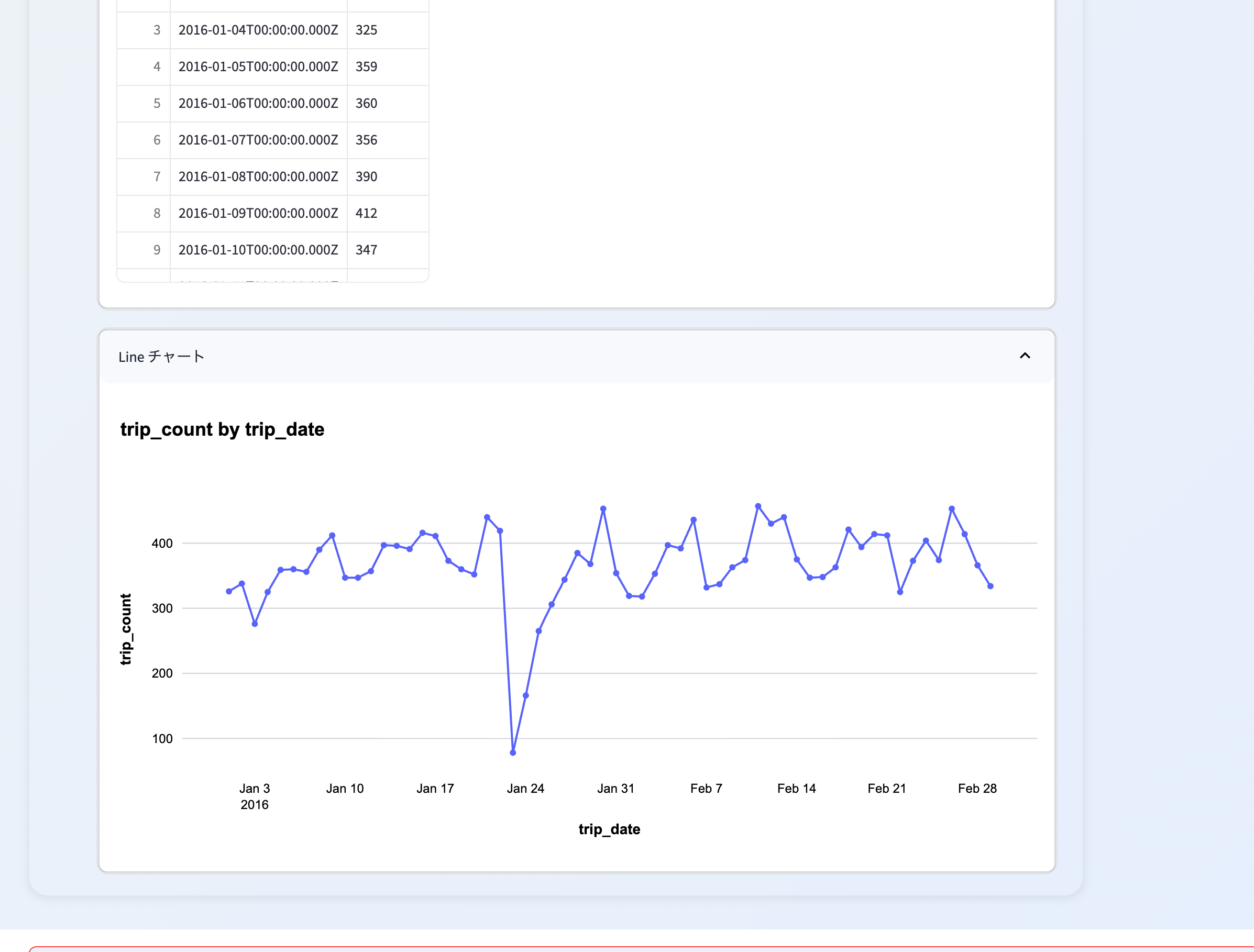
"content": "2016年に毎日何回の旅行が行われましたか?折れ線グラフを見せてください",
}
]
}
],
temperature=0.1,
)
# クエリ結果の表示
response
03-deploy-run-databricks-app
Databricksアプリのデプロイ - Databricks SDK for Python
-
appのデプロイにはDatabricks Asset Bundlesも利用できます。
最新のDatabricks SDKバージョンをインストール
%pip install -qqqq -U databricks-sdk
dbutils.widgets.text("app_name", "managed-mcp-plotting-app", "app_name")
dbutils.widgets.text(
"source_code_path",
"/Workspace/Users/takaaki.yayoi@databricks.com/plotting-uc-function-managed-mcp/databricks_apps/databricks_chat_app",
"source_code_path",
)
アプリ名のウィジェット初期値を設定
dbutils.widgets.text("app_name", "managed-mcp-plotting-app", "app_name")
dbutils.widgets.text(
"source_code_path",
"/Workspace/Users/takaaki.yayoi@databricks.com/plotting-uc-function-managed-mcp/databricks_apps/databricks_chat_app",
"source_code_path",
)
Databricks SDKからWorkspaceClientを初期化
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
Databricksアプリの作成とデプロイ完了まで待機
from databricks.sdk.service.apps import App
app = App(
name=dbutils.widgets.get("app_name"),
description="Databricksアプリの例",
# user_api_scopes=["serving.serving-endpoints"],
)
w.apps.create_and_wait(app=app)
# Databricksアプリのソースコードをデプロイ
from databricks.sdk.service.apps import AppDeployment
# source_code_pathは自身のパスに置き換えてください
app_deployment = AppDeployment(
source_code_path=dbutils.widgets.get("source_code_path")
)
w.apps.deploy_and_wait(
app_name=dbutils.widgets.get("app_name"), app_deployment=app_deployment
)