こちらの二つの記事のまとめとなります。
こちらのノートブックで、動画はこちら。
0. セットアップ
このノートブックの一般的なヒント:
- Spark UIはクラスター -> Spark UIでアクセス可能
- Spark UIの詳細な調査は後のエピソードで行います
-
sc.setJobDescription("Description")はSpark UIのアクションのジョブ説明を独自のものに置き換えます -
sdf.rdd.getNumPartitions()は現在のSpark DataFrameのパーティション数を返します -
sdf.write.format("noop").mode("overwrite").save()は、実際の書き込み中に副作用なしで変換を分析および開始するための良い方法です
今回も4コアのクラスターを使います。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
import pyspark
# AQEをオフにする。ここではジョブが増えると混乱する可能性があるため。
spark.conf.set("spark.sql.adaptive.enabled", "false")
# データフレームをキャッシュしないようにする。これにより、結果が再現可能でない場合がある。
spark.conf.set("spark.databricks.io.cache.enabled", "false")
パーティション数と行数を指定してSparkデータフレームを作成する関数。
def sdf_generator(num_rows: int, num_partitions: int = None) -> "DataFrame":
return (
spark.range(num_rows, numPartitions=num_partitions)
.withColumn("date", f.current_date())
.withColumn("timestamp",f.current_timestamp())
.withColumn("idstring", f.col("id").cast("string"))
.withColumn("idfirst", f.col("idstring").substr(0,1))
.withColumn("idlast", f.col("idstring").substr(-1,1))
)
sdf_gen = sdf_generator(20)
sdf_gen.count()
20
sdf_gen.show()
+---+----------+--------------------+--------+-------+------+
| id| date| timestamp|idstring|idfirst|idlast|
+---+----------+--------------------+--------+-------+------+
| 0|2024-12-03|2024-12-03 11:14:...| 0| 0| 0|
| 1|2024-12-03|2024-12-03 11:14:...| 1| 1| 1|
| 2|2024-12-03|2024-12-03 11:14:...| 2| 2| 2|
| 3|2024-12-03|2024-12-03 11:14:...| 3| 3| 3|
| 4|2024-12-03|2024-12-03 11:14:...| 4| 4| 4|
| 5|2024-12-03|2024-12-03 11:14:...| 5| 5| 5|
| 6|2024-12-03|2024-12-03 11:14:...| 6| 6| 6|
| 7|2024-12-03|2024-12-03 11:14:...| 7| 7| 7|
| 8|2024-12-03|2024-12-03 11:14:...| 8| 8| 8|
| 9|2024-12-03|2024-12-03 11:14:...| 9| 9| 9|
| 10|2024-12-03|2024-12-03 11:14:...| 10| 1| 0|
| 11|2024-12-03|2024-12-03 11:14:...| 11| 1| 1|
| 12|2024-12-03|2024-12-03 11:14:...| 12| 1| 2|
| 13|2024-12-03|2024-12-03 11:14:...| 13| 1| 3|
| 14|2024-12-03|2024-12-03 11:14:...| 14| 1| 4|
| 15|2024-12-03|2024-12-03 11:14:...| 15| 1| 5|
| 16|2024-12-03|2024-12-03 11:14:...| 16| 1| 6|
| 17|2024-12-03|2024-12-03 11:14:...| 17| 1| 7|
| 18|2024-12-03|2024-12-03 11:14:...| 18| 1| 8|
| 19|2024-12-03|2024-12-03 11:14:...| 19| 1| 9|
+---+----------+--------------------+--------+-------+------+
パーティションにおけるレコードの分布を表示する関数。
def rows_per_partition(sdf: "DataFrame") -> None:
num_rows = sdf.count()
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id").count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id").show()
パーティションとカラムのセットごとの分布を表示する関数。
def rows_per_partition_col(sdf: "DataFrame", num_rows: int, col: str) -> None:
sdf_part = sdf.withColumn("partition_id", f.spark_partition_id())
sdf_part_count = sdf_part.groupBy("partition_id", col).count()
sdf_part_count = sdf_part_count.withColumn("count_perc", 100*f.col("count")/num_rows)
sdf_part_count.orderBy("partition_id", col).show()
1. パーティショニングの復習
最も重要なことは良い並列化を実現することです。
- これは、パーティションの数が常に利用可能なコアの数に依存するべきであることを意味します。Sparkの言葉で言うと:
spark.sparkContext.defaultParallelism。推奨されるのは2-4倍の係数ですが、実際にはメモリとデータサイズに依存します。小さなデータサイズでは1倍の係数でも問題なく動作します。 - 良い並列化を実現するためには、均等(理想的には一様、最悪でも正規分布)に分布したデータセットを持つことが重要です。データの偏りは、狭い変換でも全体の実行が一つのパーティションやタスクに依存する原因となります。
パーティションサイズ
- パーティションサイズが非常に大きい場合(> 1GB)、OOM(メモリ不足)、ガベージコレクション(GC)やその他のエラーが発生する可能性があります。
- インターネット上の推奨事項では、100-1000 MBの範囲が良いとされています。例えば、Sparkは最大パーティションバイト数のパラメータを128 MBに設定しています。もちろん、これはマシンと利用可能なメモリに依存します。利用可能なメモリの限界を超えないように注意してください。
分散オーバーヘッド
- 前の実験で見たように、パーティションの数が多すぎると、スケジューリングと分散のオーバーヘッドが増加します。
- 実行時間が全体のタスク時間の少なくとも90%を占めていない場合や、タスクが100 ms未満の場合、それは通常短すぎます。
こちらも参照してください: https://stackoverflow.com/questions/64600212/how-to-determine-the-partition-size-in-an-apache-spark-dataframe
2. リパーティションの仕組み
- ドキュメント: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.repartition.html#pyspark.sql.DataFrame.repartition
- リパーティションはパーティションの数を増減させることができます
- リパーティションはデータのシャッフルを必要とするため、コアレスよりも非効率的になることがあります
- 一方で、コアレスがパーティションを単に結合するのに対し、リパーティションは均等な分布を作成します
- パーティションの数に基づくのではなく、行数に基づいてパーティションを分割することができます
- パーティションの数が定義されていない場合、デフォルト値は
spark.sql.shuffle.partitionsに依存し、これは200にデフォルト設定されています(後のエピソードでワイドな変換を評価する際に重要です)
3. コアレスの仕組み
- ドキュメント: https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.functions.coalesce.html
- 狭い変換
- パーティションの数を減らすことしかできません。エラーは発生しませんが、最初に利用可能なパーティション数より多い値は無視されます
- コアレスは各パーティション内のデータを偏らせる可能性があり、パフォーマンスが低下し、一部のタスクが非常に長く実行される原因となります。理由は、単にパーティションを結合するだけだからです。
- コアレスは小さなパーティションの数を効率的に減らし、パフォーマンスを向上させるのに役立ちます。パーティションの数が多すぎると、スケジューリングのオーバーヘッドが増えることを覚えておいてください。
4. リパーティションとコアレスの使いどころ
- データを別の数のパーティションに再分配したい場合。例えば、最初に7つのパーティションがあり、4つのコアがある場合、8つに増やすことができます(今回のトピック)
- データの偏りがあり、一部のパーティション/タスクが他よりも長く実行される場合。これはjoinや他のワイドな変換にも影響を与える可能性があります。リパーティションはこれを処理します。(今回のトピック)
- join操作は事前にデータをリパーティションすることで恩恵を受けることができます。リパーティションはjoin中のデータのシャッフルを減らします。また、カラムキーに基づく他のシャッフル操作(例:order by)にも有効です(後のエピソードで学びます)
- フィルター操作がより効率的になることがあります。(今回のトピック)
- 大規模なフィルター操作は多くの空のパーティションを生む可能性があります。例えば、1000万行と1000のパーティションがあり、フィルター後に10行だけ残る場合、次の操作(例:カウント)にとって突然のオーバーヘッドとなります。(今回のトピック)
- データフレーム内の構造化フィールドの展開はパーティションサイズを増加させることがあります。(後で)
- 書き込みを最適化または影響を与える。後で学ぶように、書き込みはパーティションの数に依存します。パーティションの数が多すぎると書き込みが非効率になります。例えば、parquetでのファイル作成も書き込み直前のパーティション数に依存します。(後のエピソードで学びます)
こちらも参照してください: https://medium.com/@zaiderikat/apache-spark-repartitioning-101-f2b37e7d8301
5. パーティション数の削減
num_rows = 200000000
5.1. シナリオ1
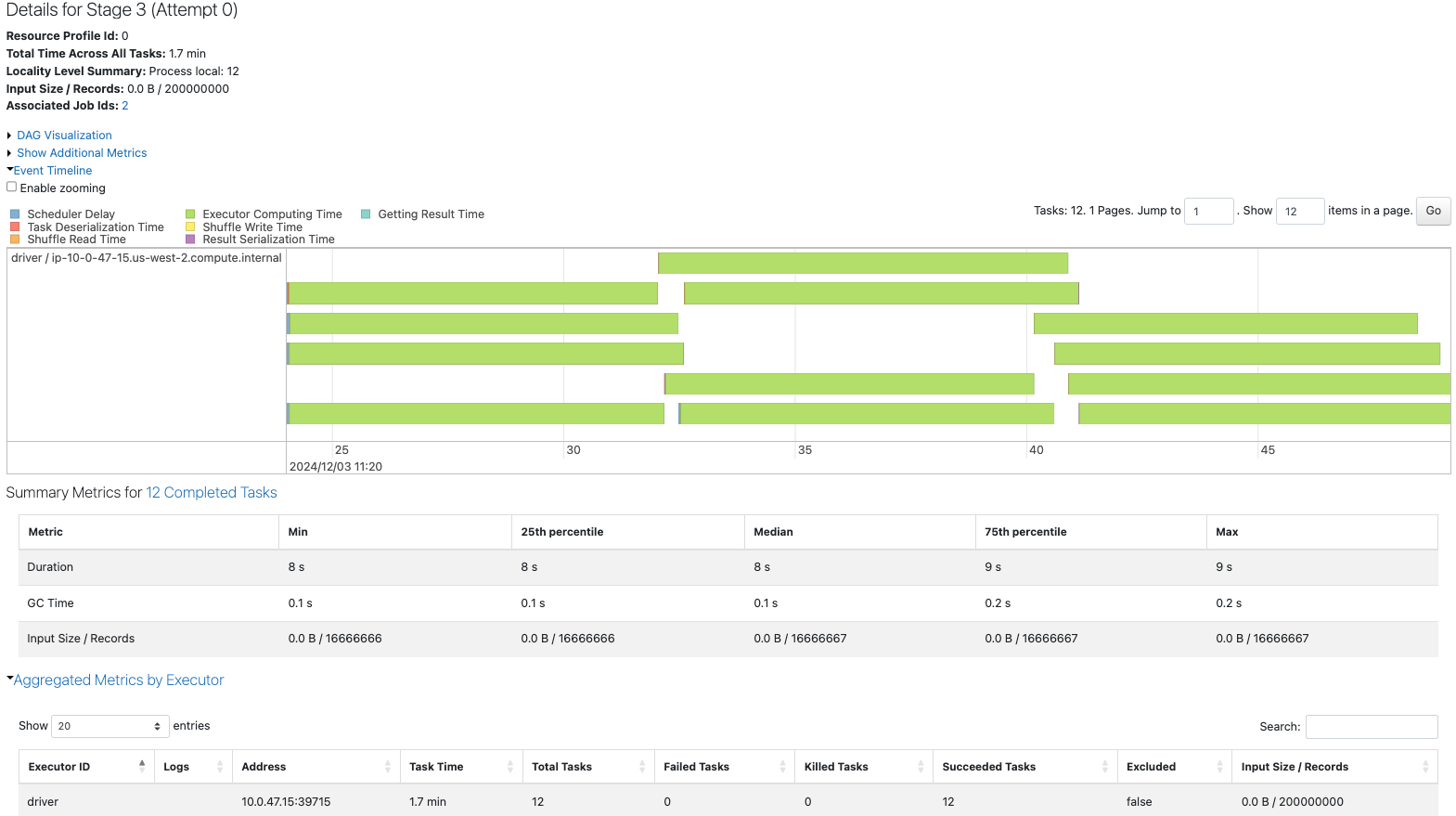
12が目標のパーティションサイズですが、入力として 13 パーティションがあります。
ベースラインとして12パーティションのデータフレームと13パーティションのデータフレームを作成します。後で、coalesceとrepartitionを使用しているSparkジョブと比較します。
sdf = sdf_generator(num_rows, 12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
均等なパーティションが作成されています。
sdf = sdf_generator(num_rows, 13)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 13")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
こちらも均等ですが、パーティション数がコア数の倍数ではないため、最後は1コアのみがタスクを実行しています。
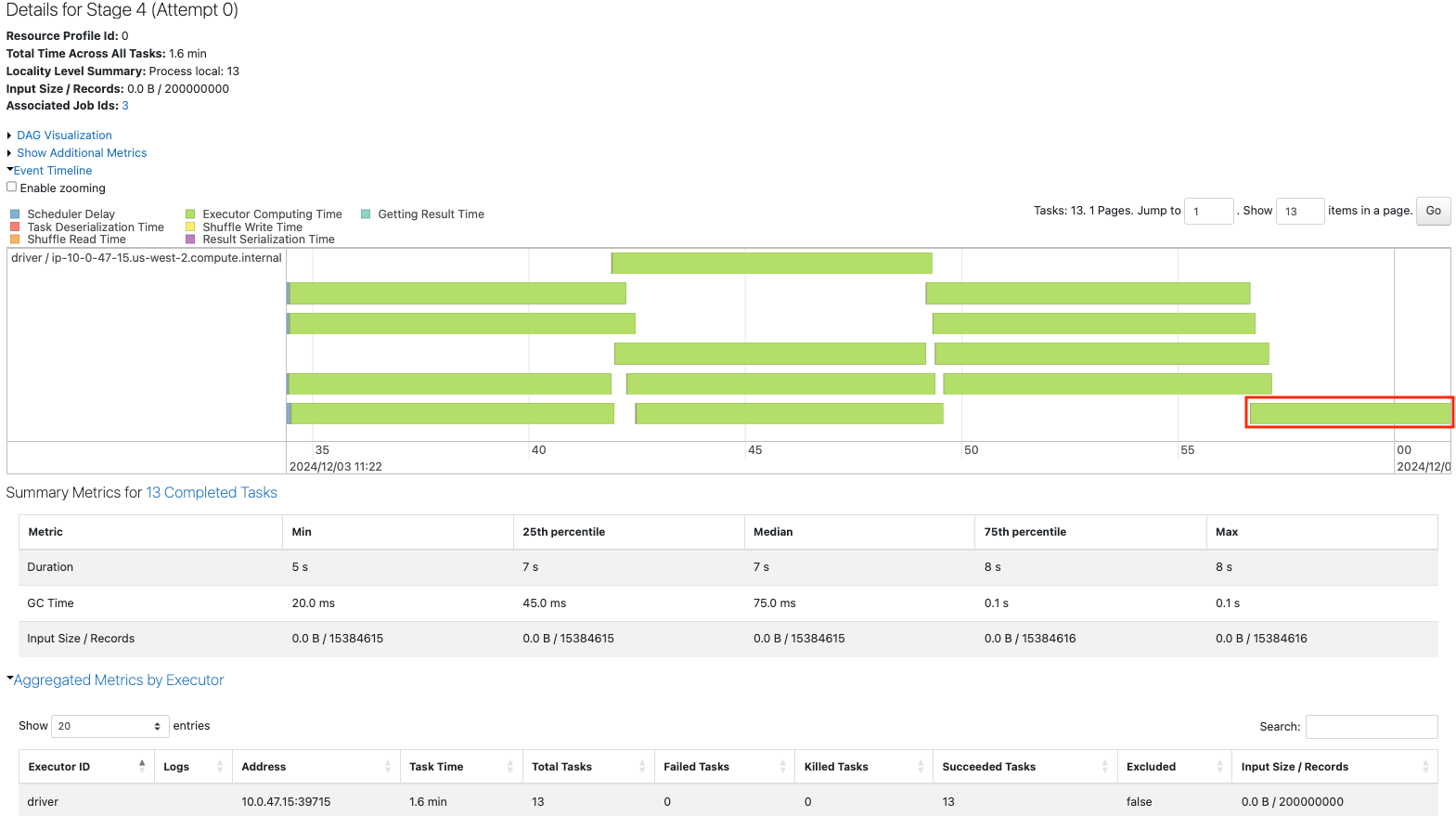
coalesceを用いてパーティション数を12に削減します。
sdf = sdf_generator(num_rows, 13).coalesce(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Coalesce 13 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
最後のタスクで二つのパーティションが結合されています。Summary Metricsを見ると、最大のパーティションは他のタスクの約2倍のサイズとなっています。
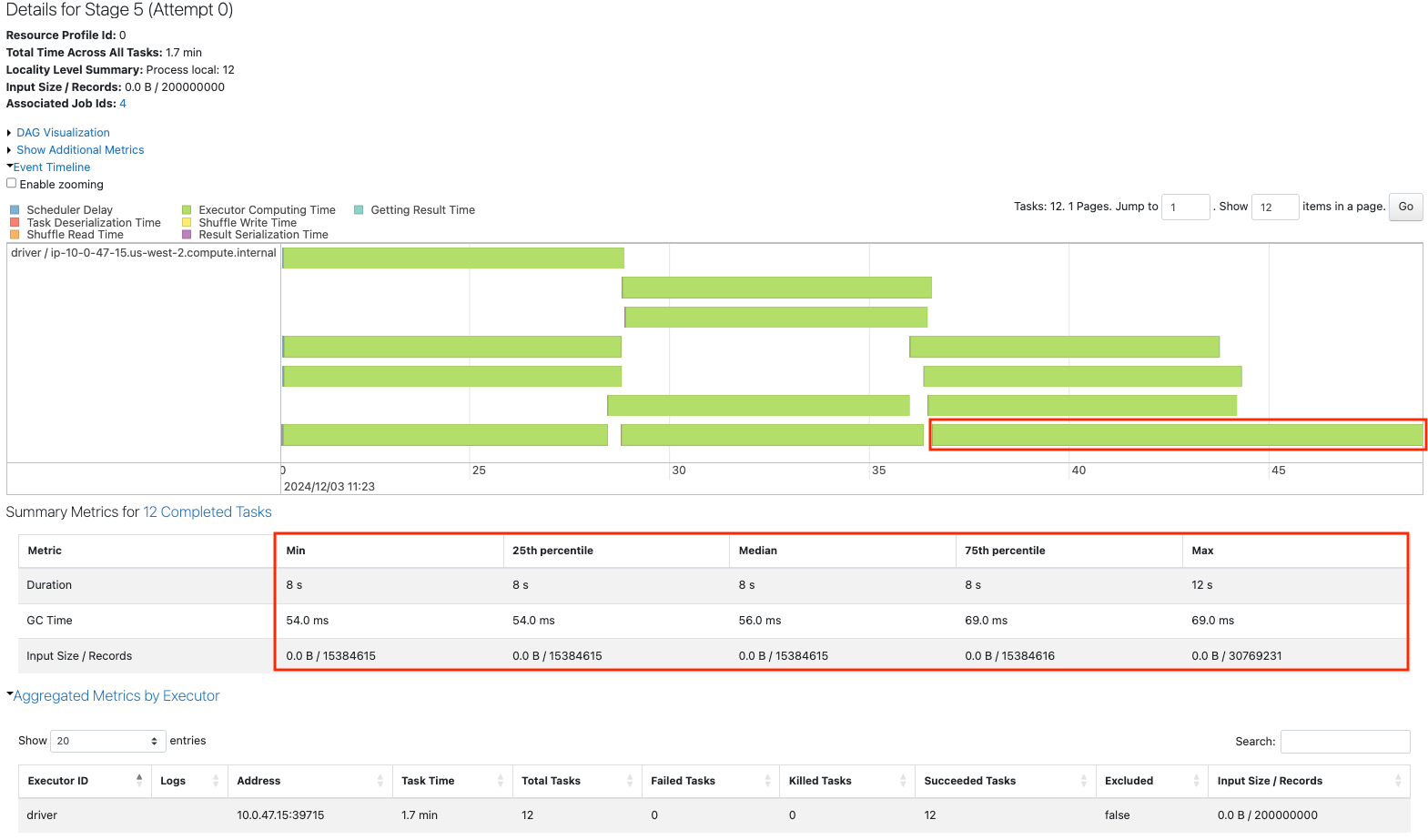
repartitionを用いてパーティション数を12に削減します。こちらは均等なパーティションが作成されますが、タスク間でのデータのやり取りが発生するため、上のジョブに比べて時間を要するものとなっています。
sdf = sdf_generator(num_rows, 13).repartition(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition 13 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
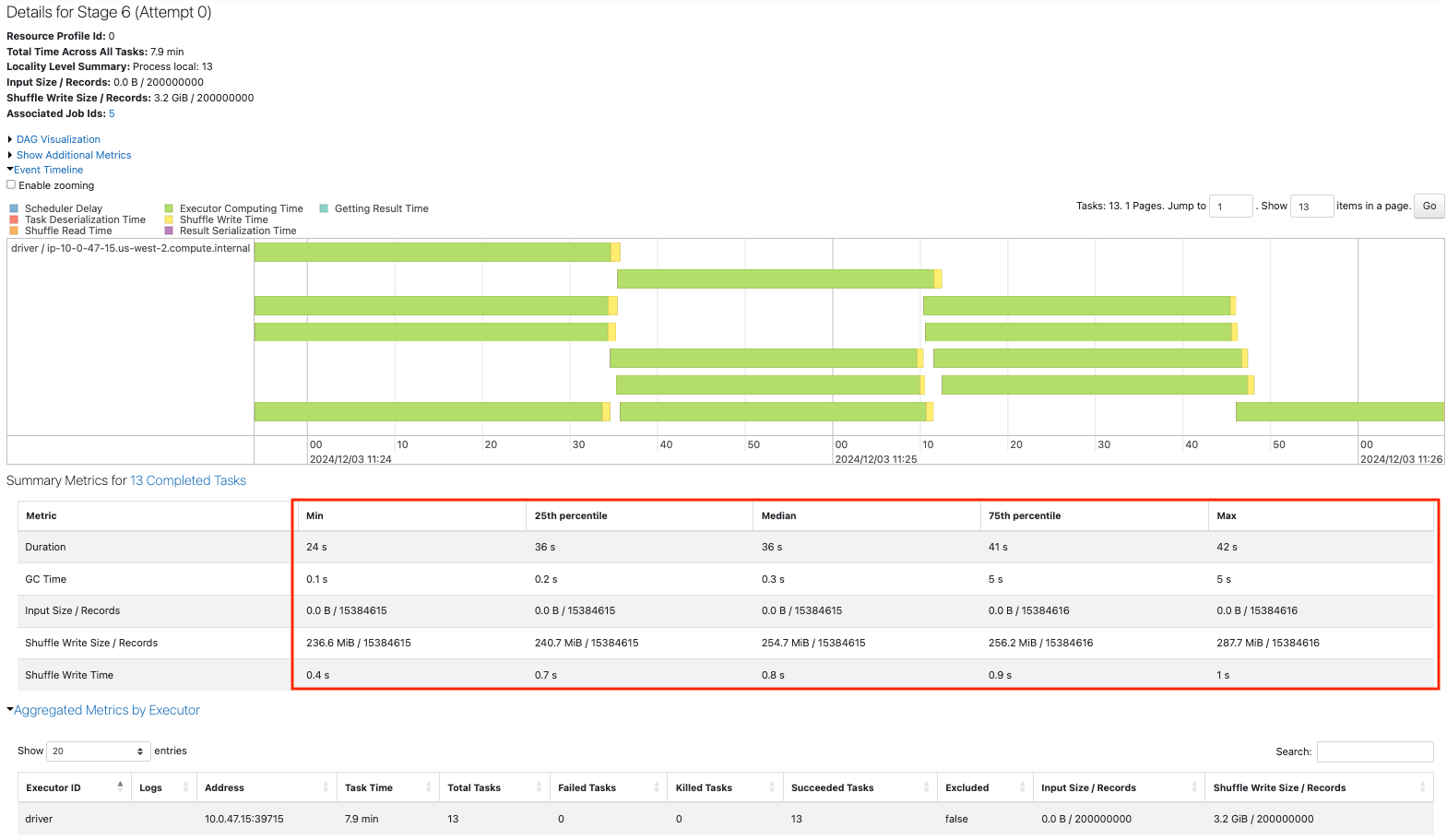

5.2. シナリオ2
12が私たちの目標のパーティションサイズですが、入力として20001のパーティションがあります。
ベースラインとなる20001のパーティションを持つデータフレームを作成します。
sdf = sdf_generator(num_rows, 20001)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 20001")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
coalesceでパーティションを12に削減します。
sdf = sdf_generator(num_rows, 20001).coalesce(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Coalesce 20001 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
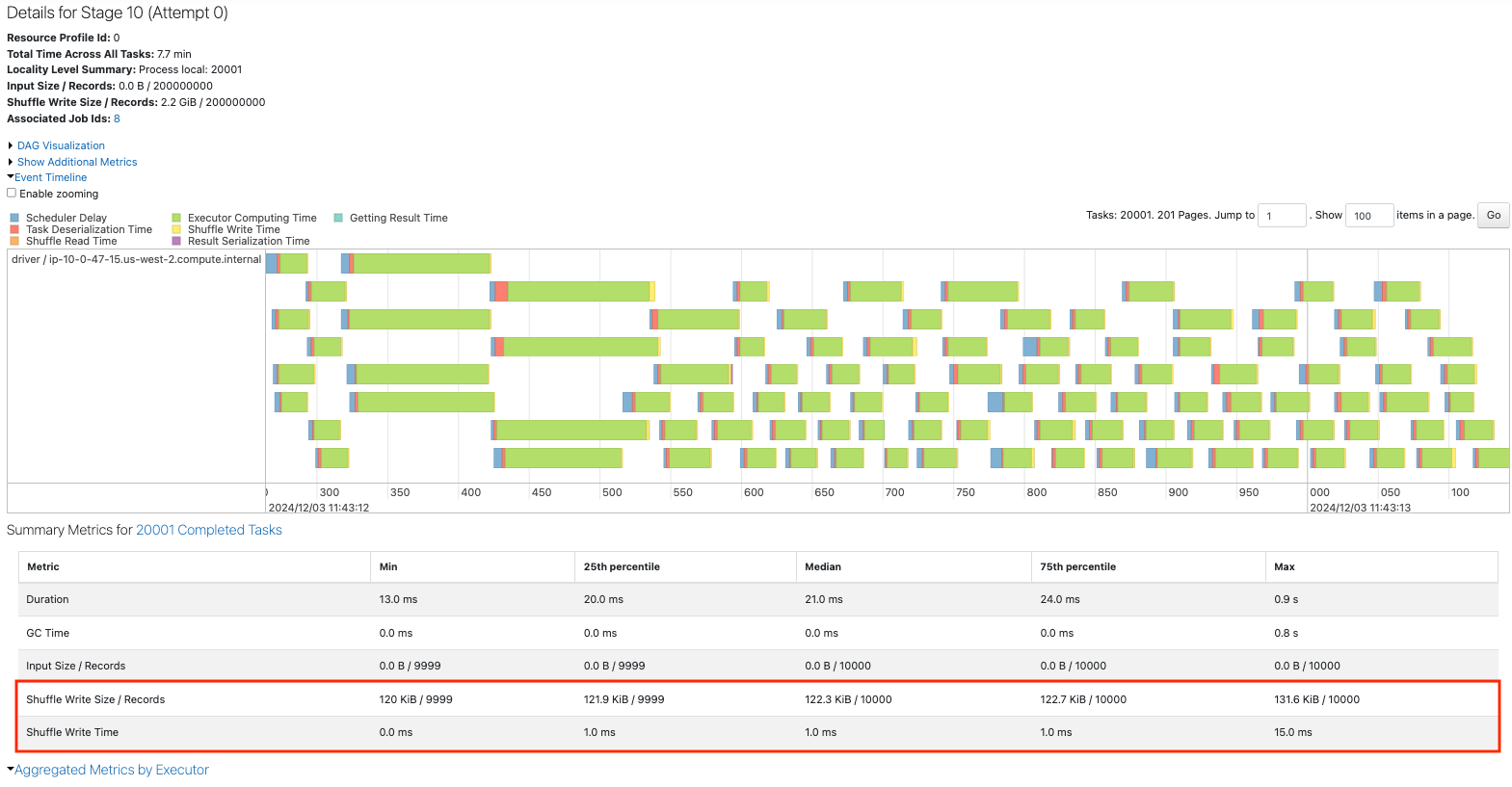
repartitionでパーティションを12に削減します。
sdf = sdf_generator(num_rows, 20001).repartition(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition 20001 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
3つのジョブを比較すると、ベースラインよりもcoalesceを行った方が高速になっています。
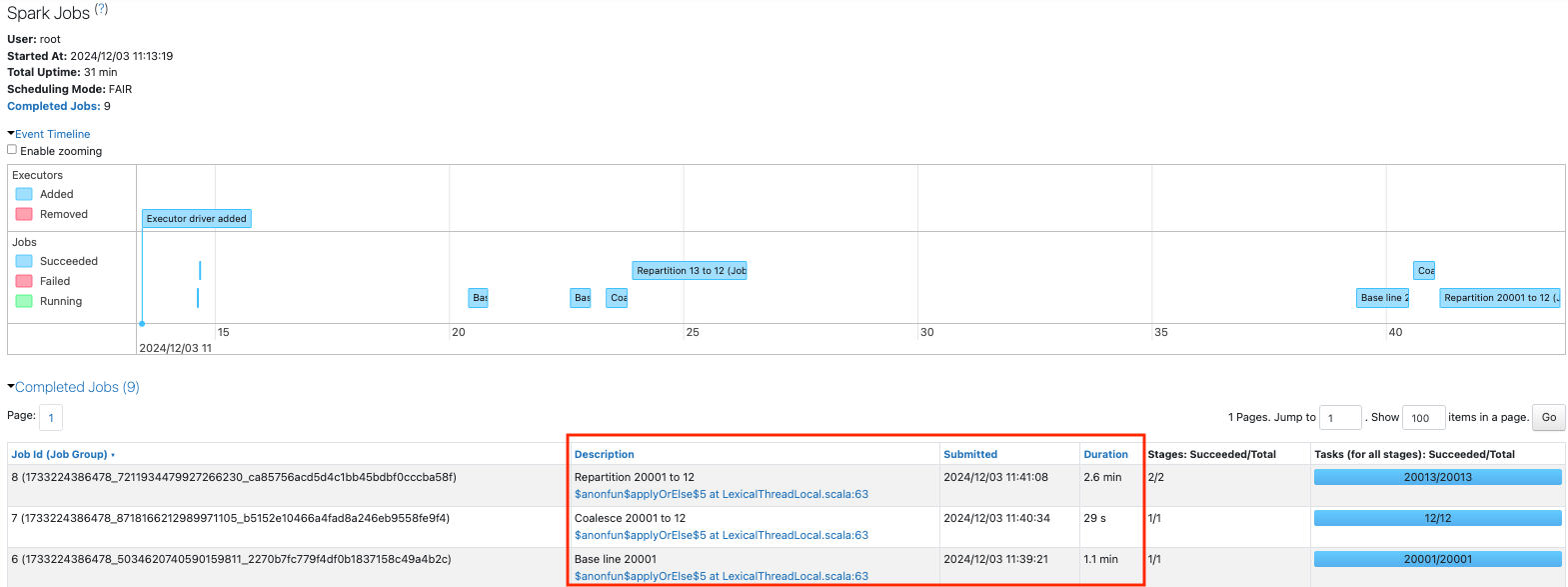
ベースラインでは大量のパーティションを捌く必要があるため、スケジューラの遅延が顕著になっています。
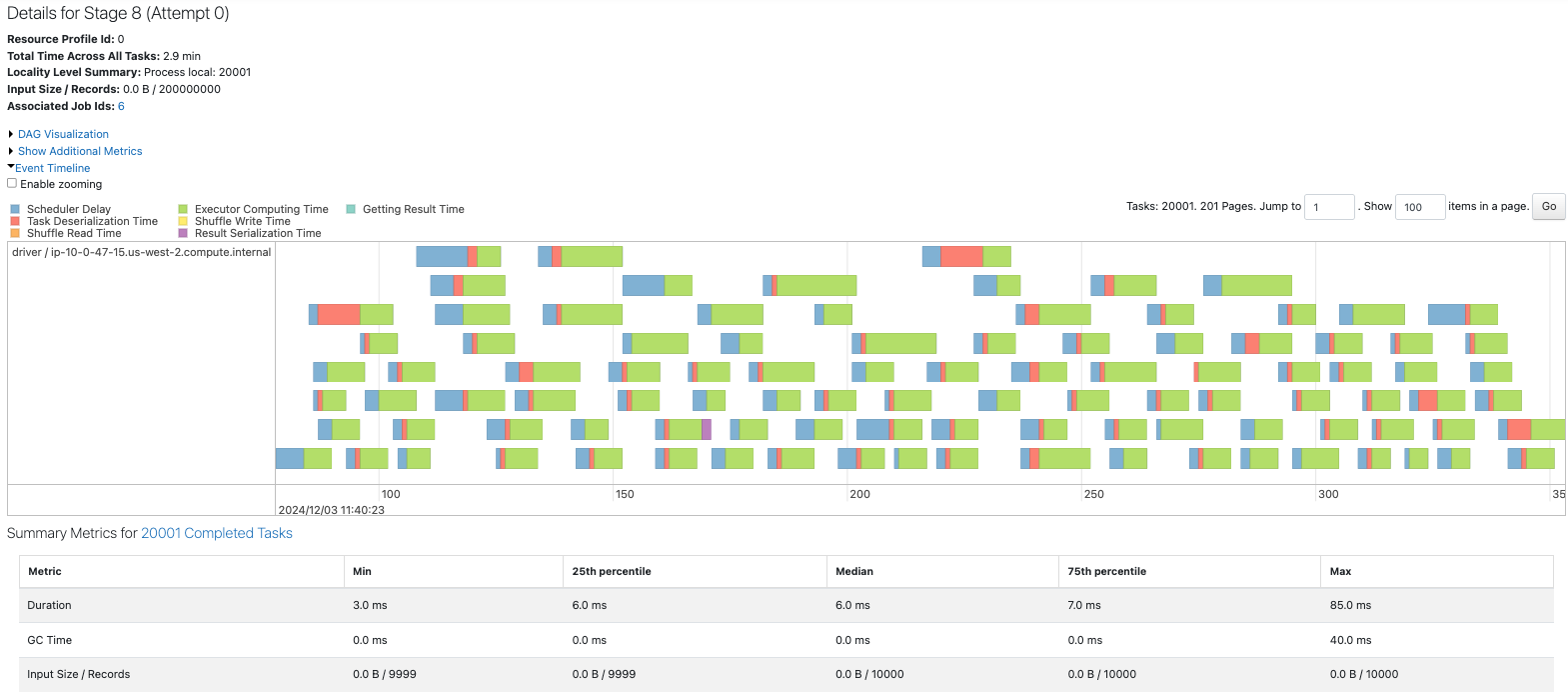
coalesceを行うことで、大量の小さなパーティションをまとめることができ、パフォーマンスの改善につながっています。データもほぼ均等に分配されています。
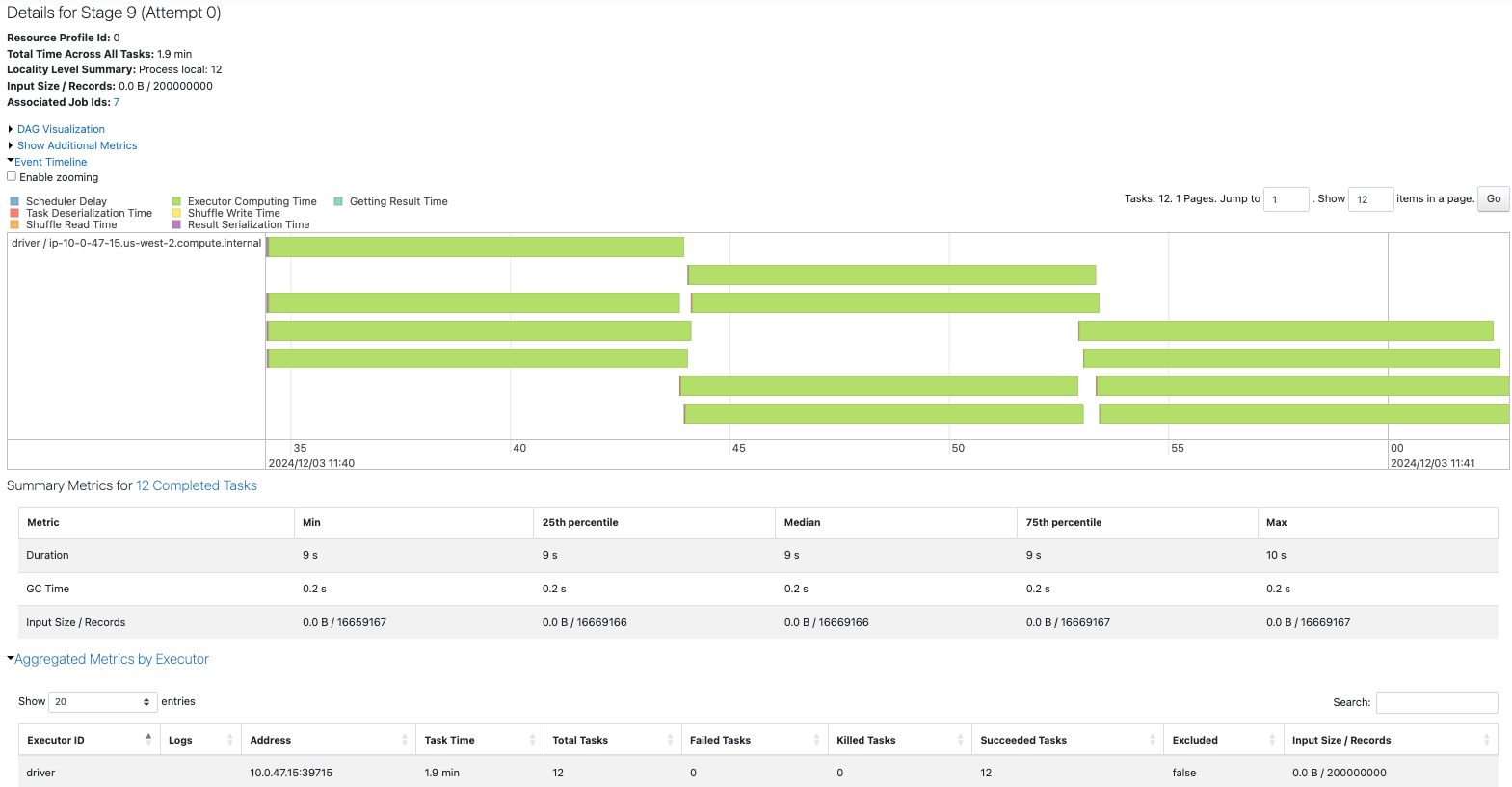
このケースではrepartitionの効果はcoalesceと大きく変わりませんが、シャッフルが発生することで処理に時間を要しています。
5.3. シナリオ3
40が私たちの目標のパーティションサイズですが、入力として90のパーティションがあります。
ベースラインとなる40パーティションと90パーティションのデータフレームを作成します。
sdf = sdf_generator(num_rows, 40)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 40")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
sdf = sdf_generator(num_rows, 90)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 90")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
coalesceで90パーティションを40パーティションに削減します。
sdf = sdf_generator(num_rows, 90).coalesce(40)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Coalesce 90 to 40")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
repartitionで90パーティションを40パーティションに削減します。
sdf = sdf_generator(num_rows, 90).repartition(40)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition 90 to 40")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
Sparkジョブを比較します。前のシナリオ同様にrepartitionは他のジョブよりも時間を要しています。
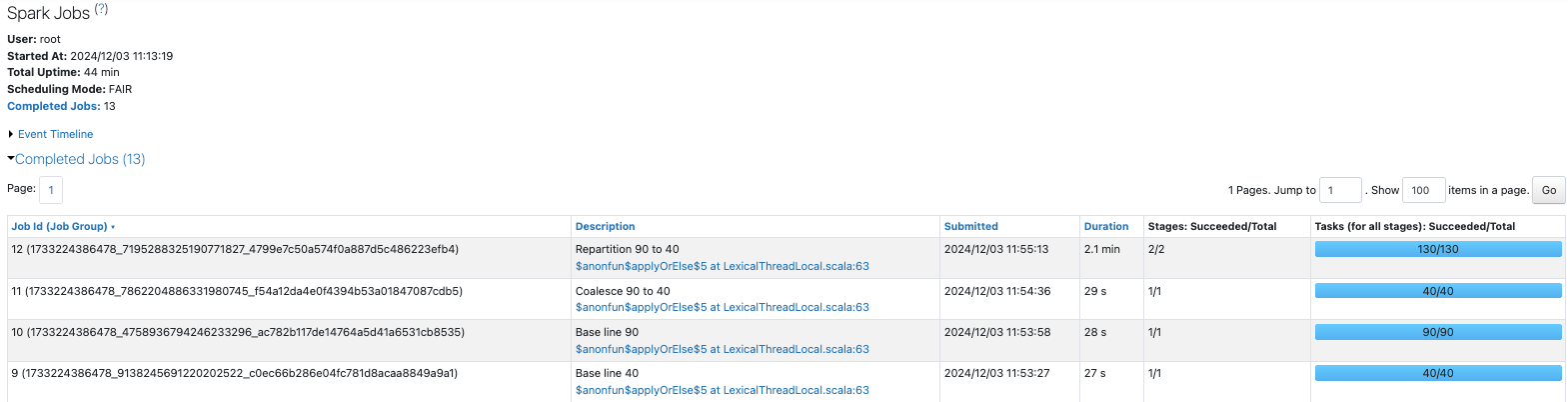
コア数の倍数の40パーティションの場合は、コアに均等にタスクが割り振られています。

90パーティションの場合は、後半で一部のコアしか使用されていない状態が生じています。
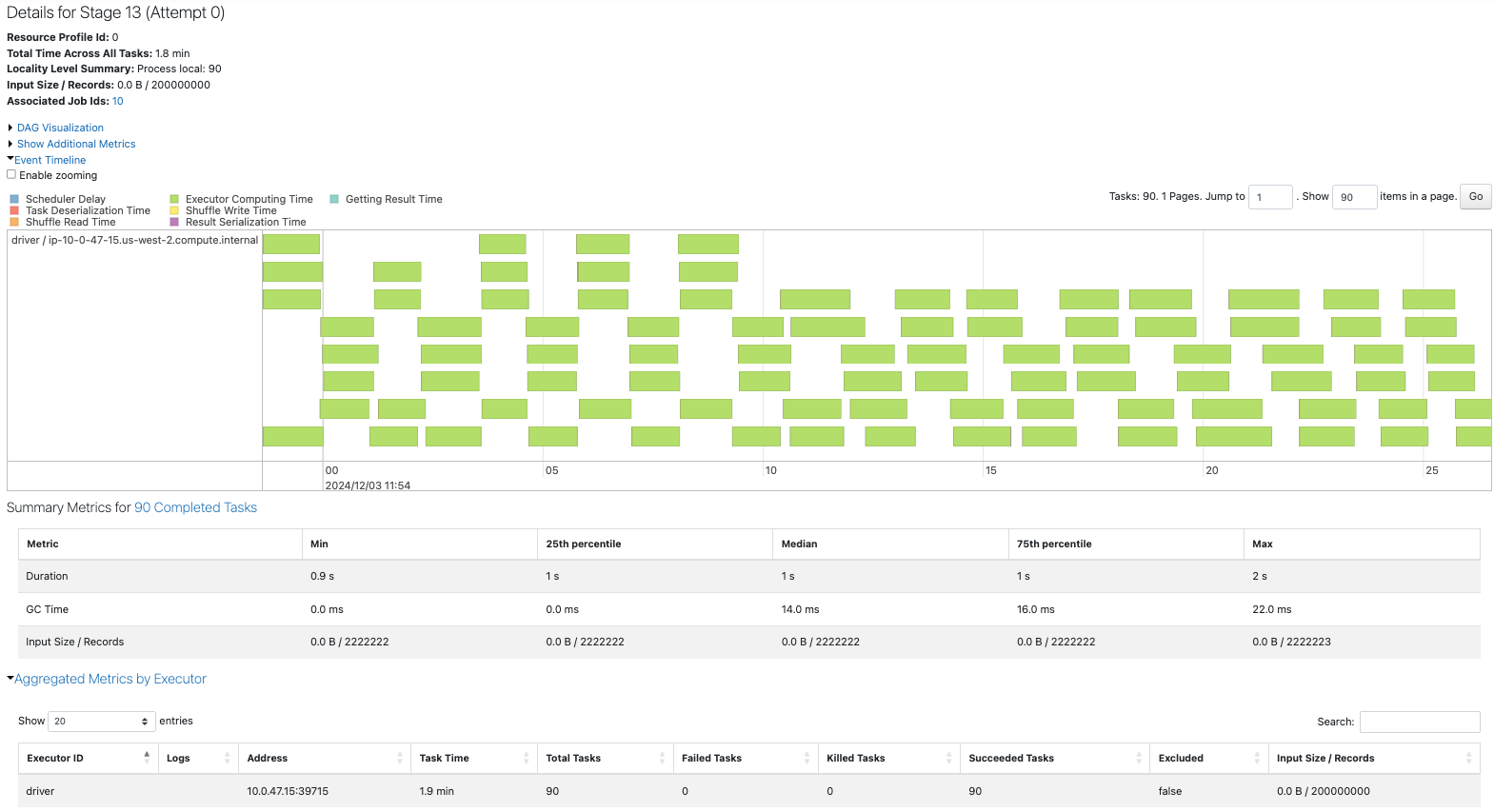
coalecseをした場合、元がコア数の倍数ではないため、結合結果にばらつきが生じています。

repartitionはシャッフルを伴う処理ですが、パーティションがほぼ均等になっています。
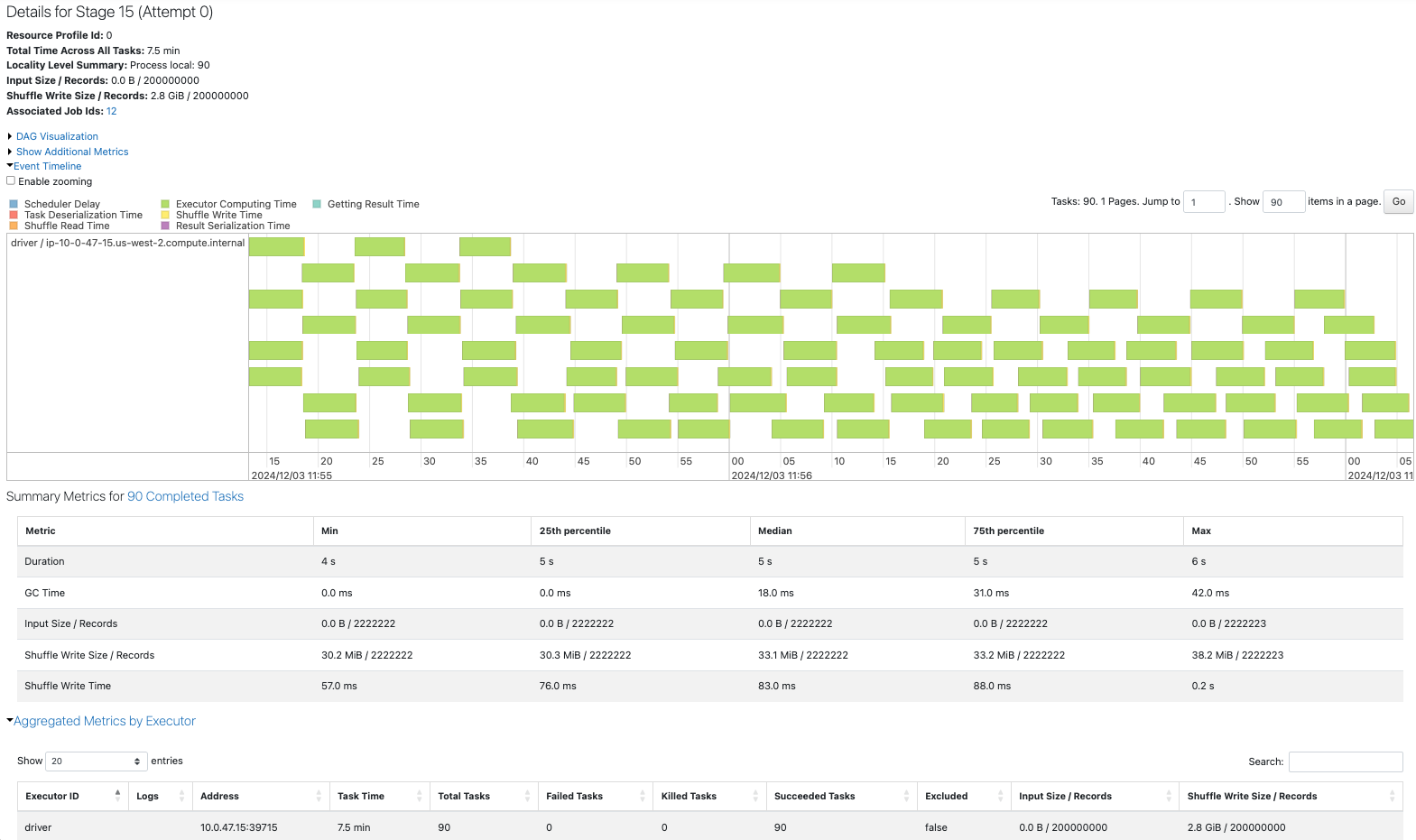
6. パーティション数の増加
ベースラインとなる1パーティション、10パーティション、12パーティションのデータフレームを作成します。
sdf = sdf_generator(num_rows, 1)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 1")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
1
sdf = sdf_generator(num_rows, 10)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 10")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
10
sdf = sdf_generator(num_rows, 12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
パーティションを1から12に増加させます。
sdf = sdf_generator(num_rows, 1).repartition(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition 1 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
パーティションを10から12に増加させます。
sdf = sdf_generator(num_rows, 10).repartition(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition 10 to 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
Sparkジョブを比較します。1から12へのrepartitionが一番時間を要しています。
1パーティションの場合、1つのタスクのみがずっと処理を行っています。
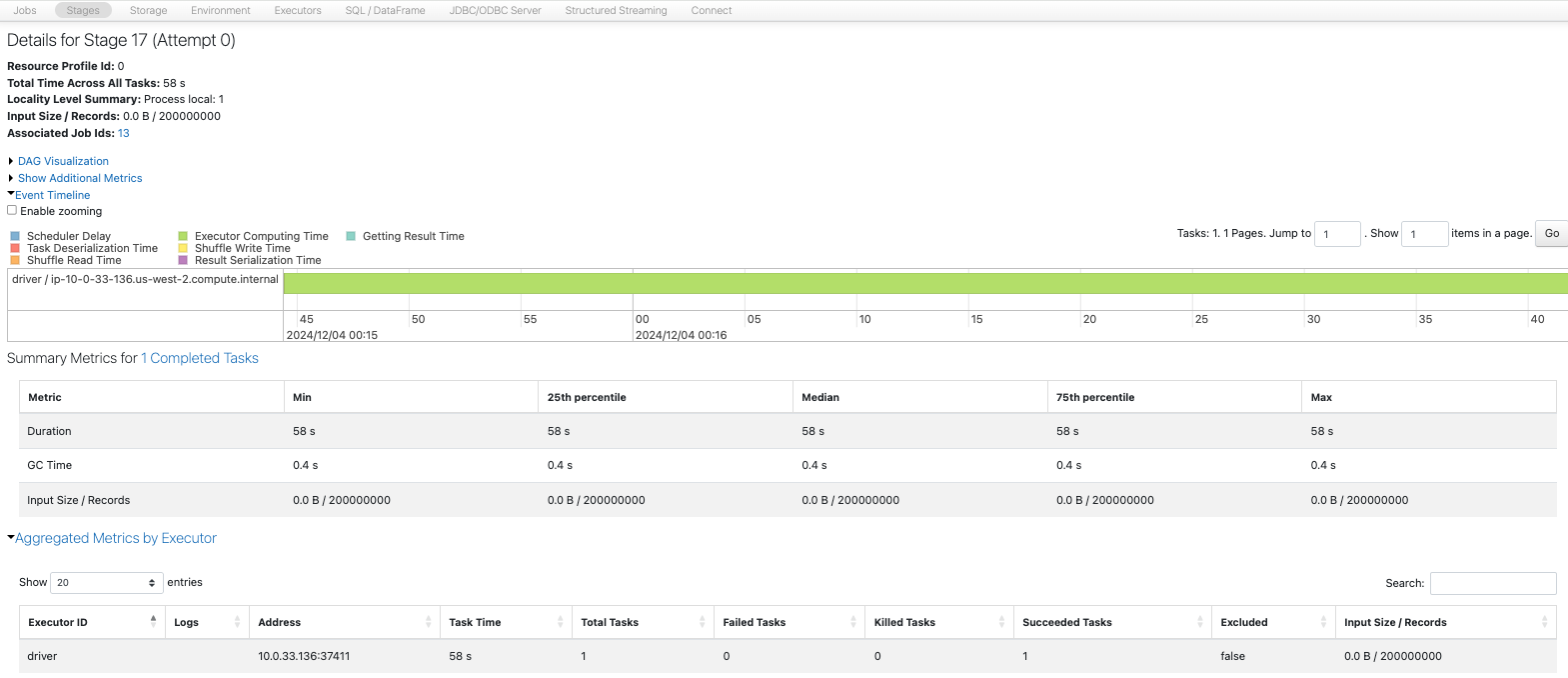
10パーティションの場合、遊休CPUが生じていますが、12パーティションの場合は4コアを有効に活用しています。
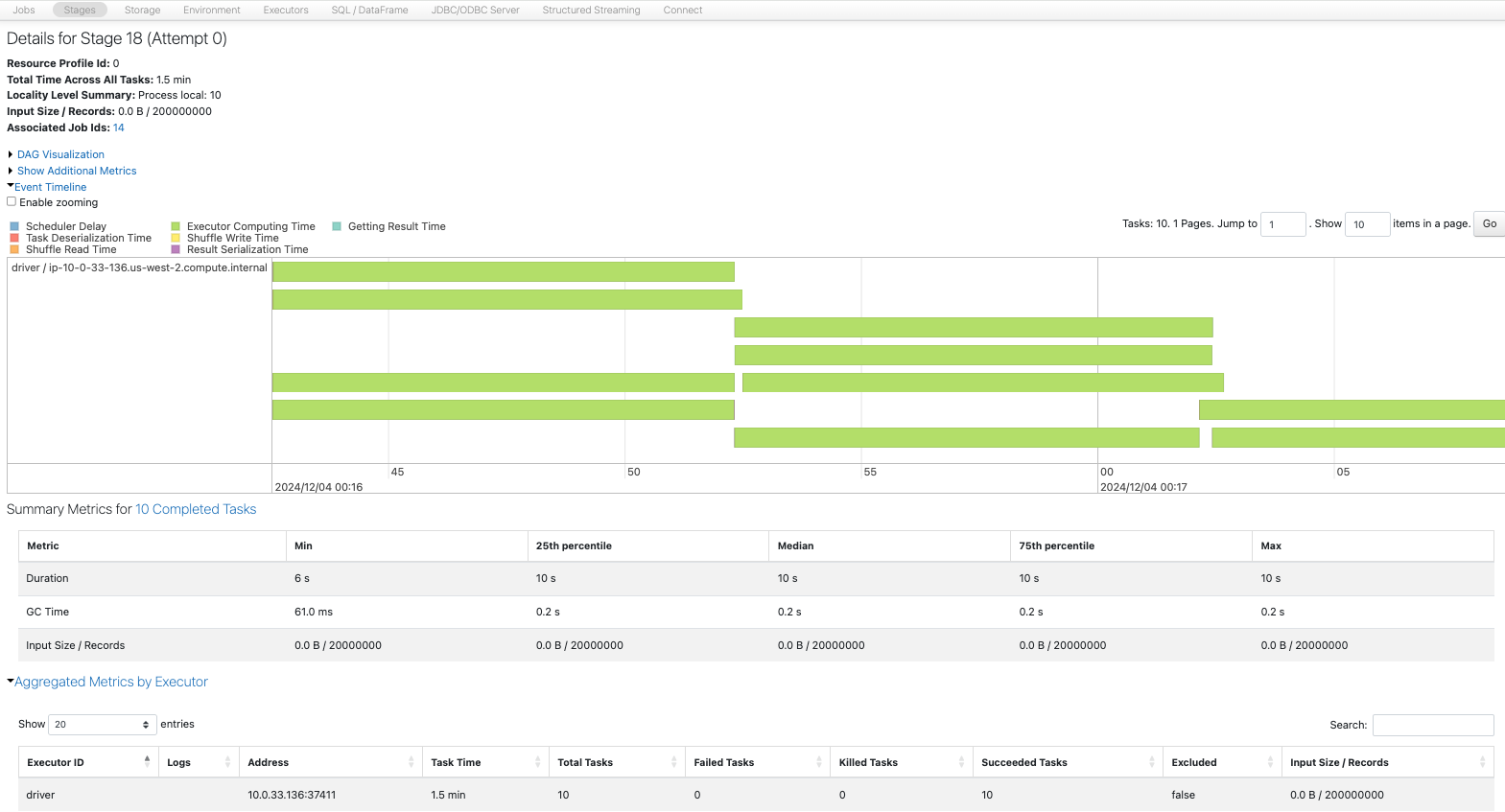
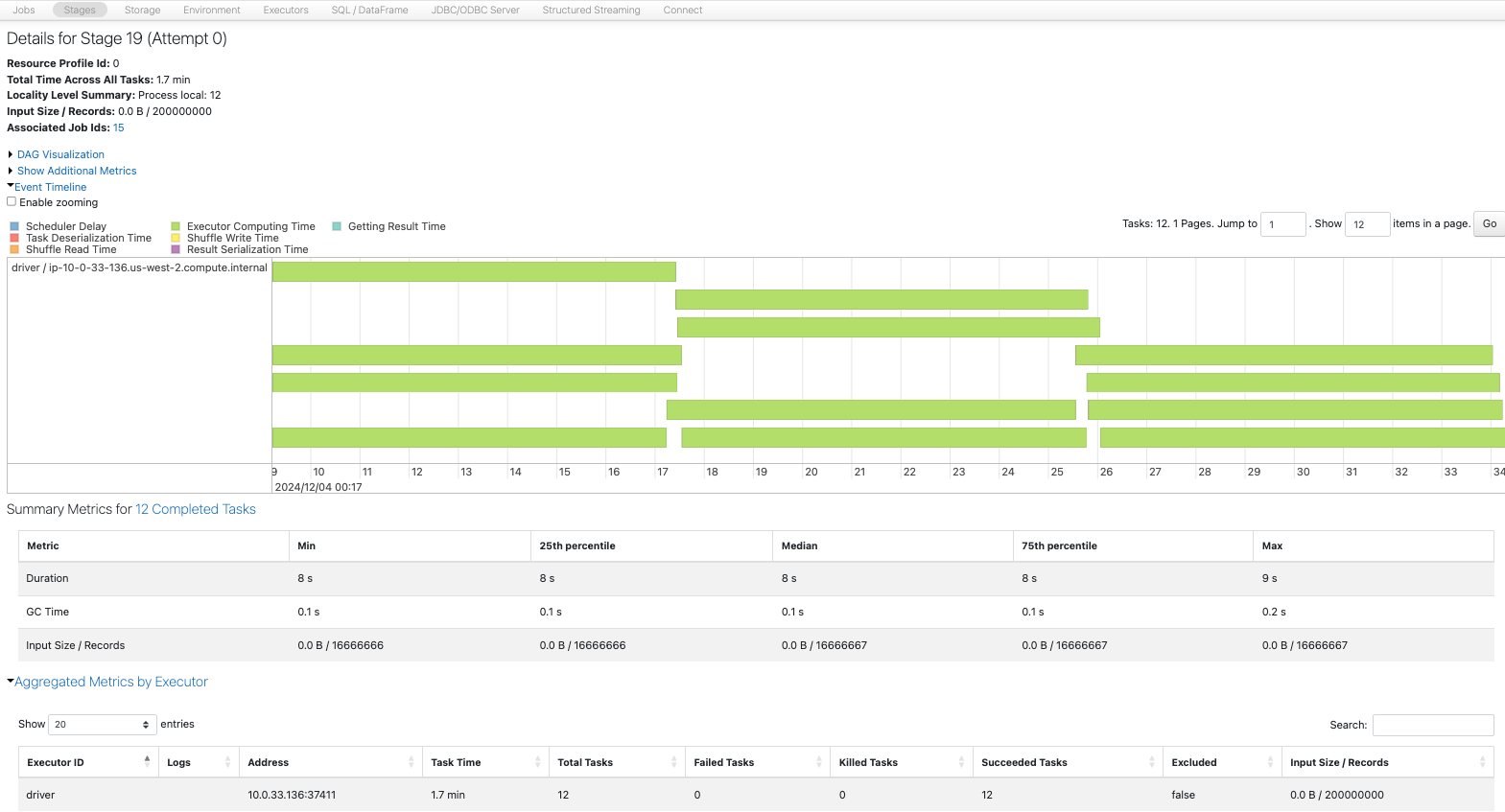
1パーティションから12パーティションへのrepartitionでは、シャッフルを伴う1つの大きなタスクが処理を行っており、大きなパーティションがコアのメモリーに乗り切らずSpill(溢れ)も発生しています。
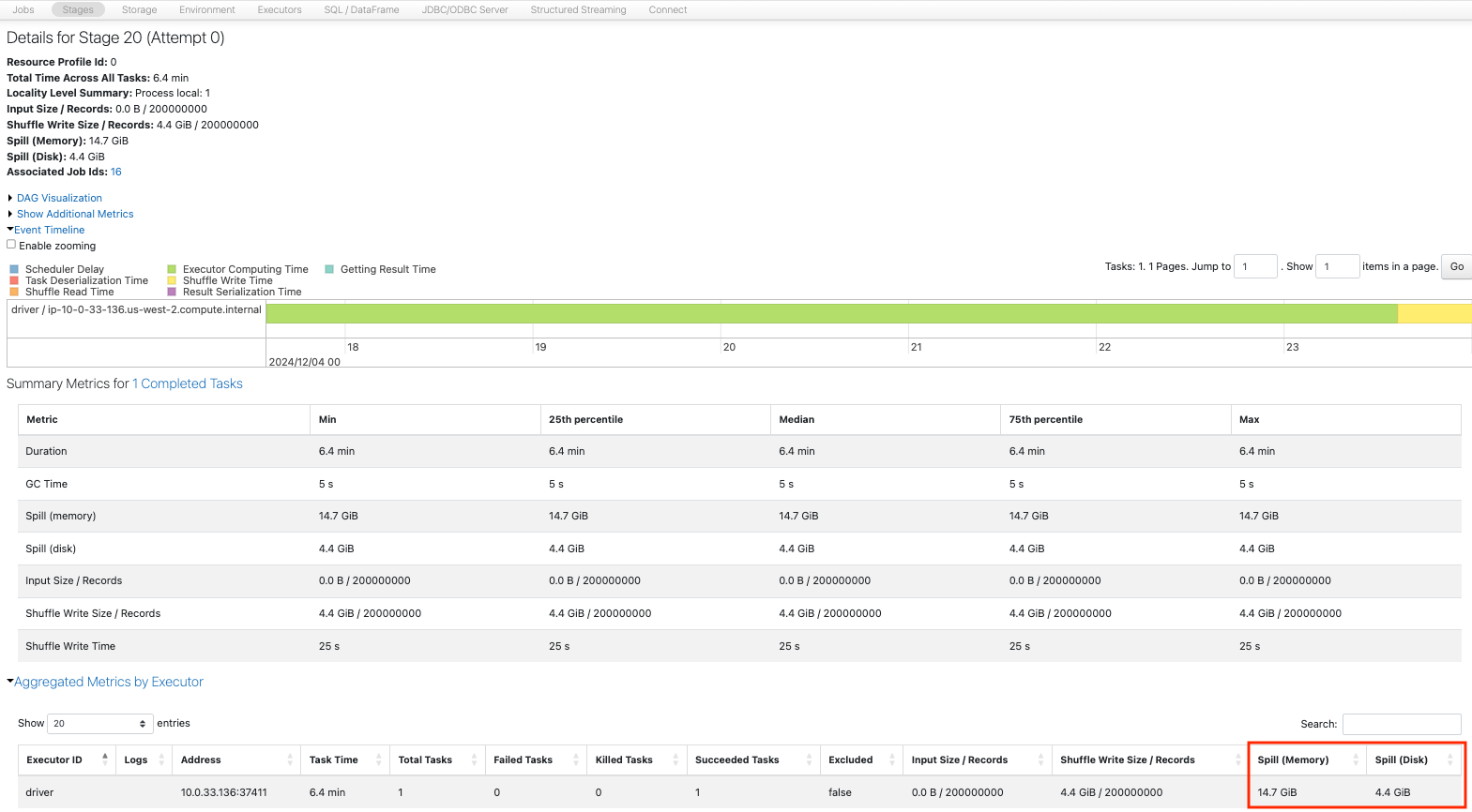
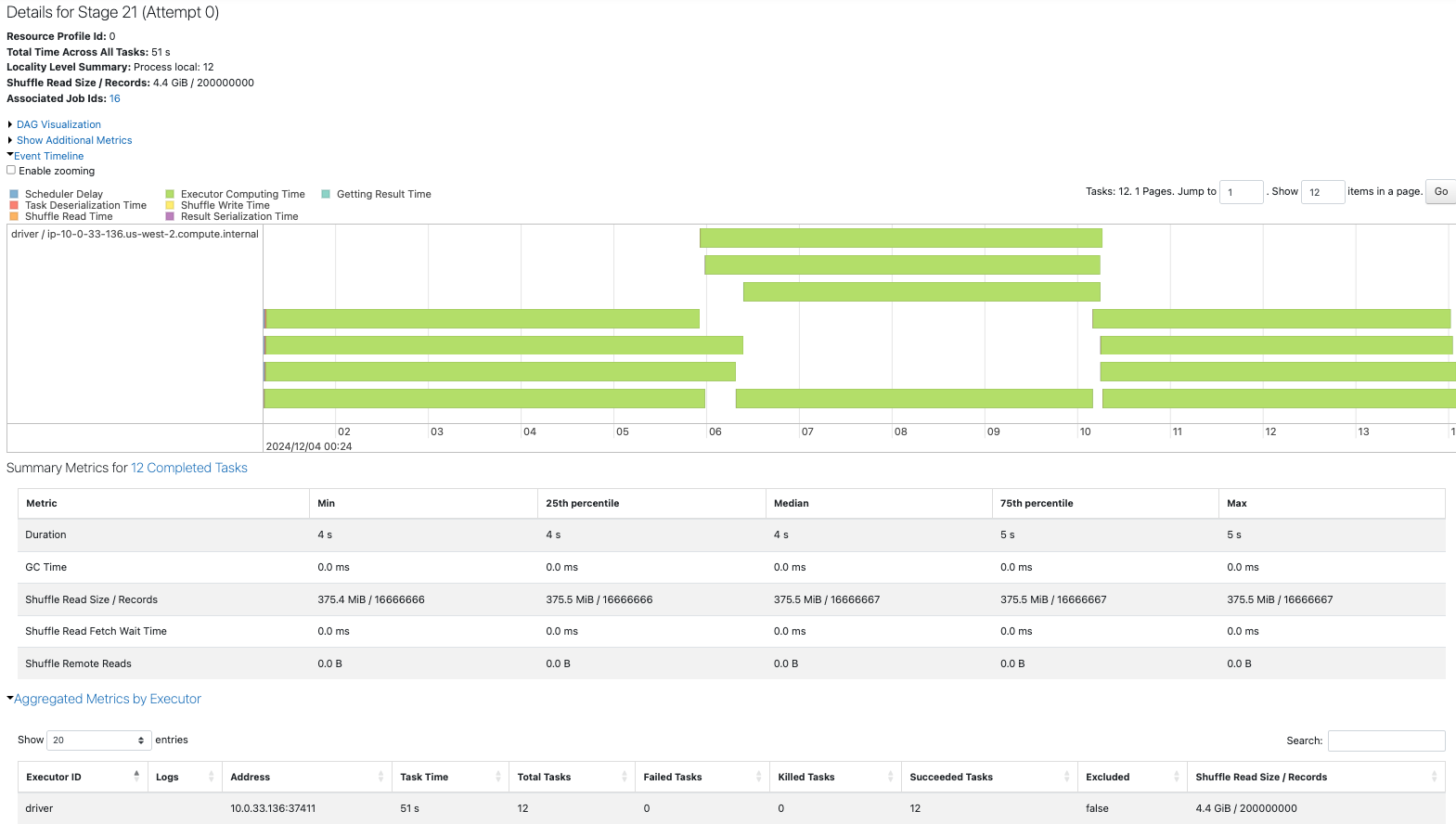
10パーティションから12パーティションへのrepartitionでは、10のタスクによって再配分が行われており、性能へのインパクトは1からのrepartitionほどではありません。
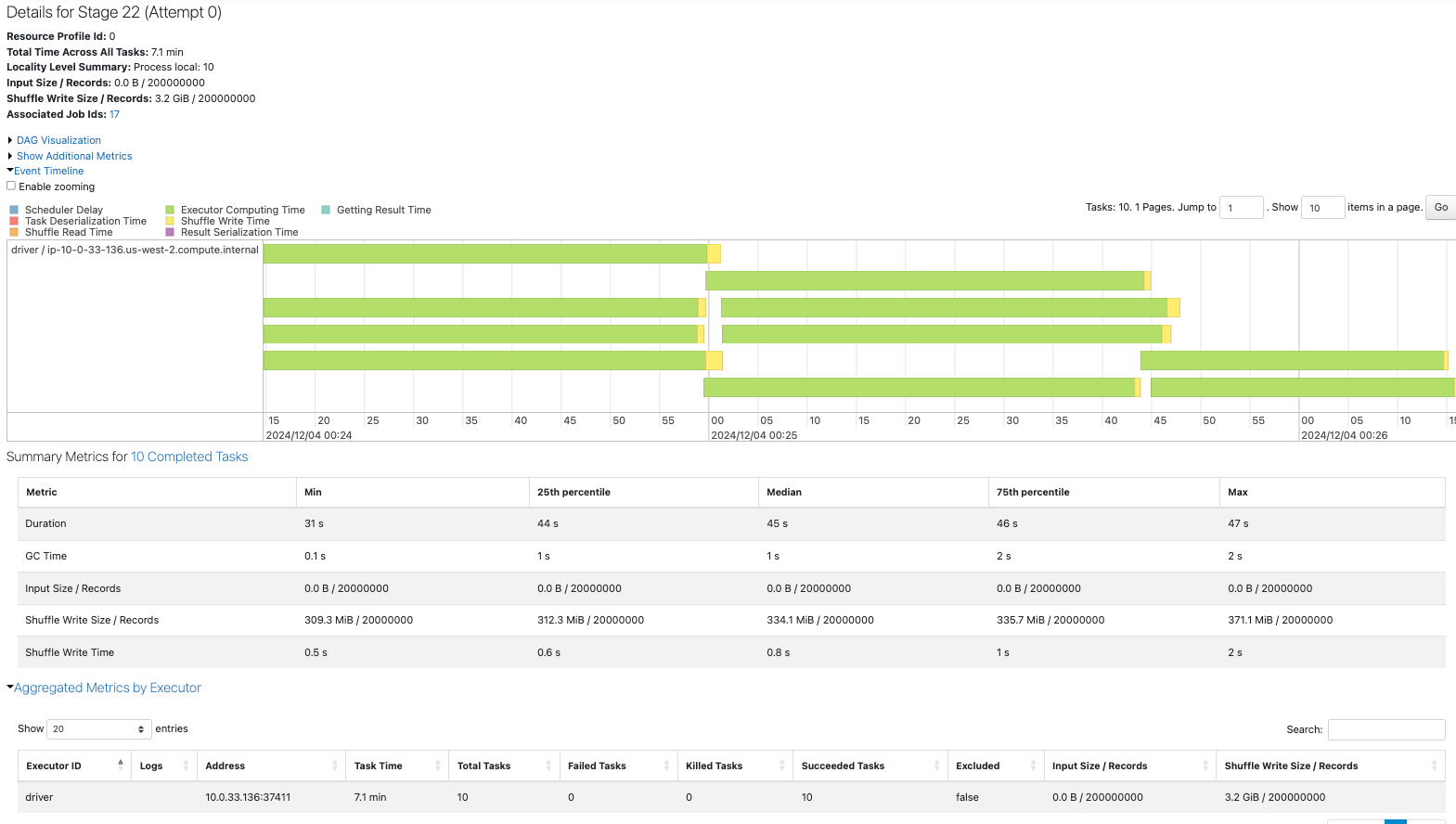
7. データの偏り
フィルターまたはコアレスで生成で偏りを生成します。
ベースラインとなる、均等な12パーティションと15パーティション、偏りのある12パーティションを作成します。
sdf = sdf_generator(num_rows, 12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
sdf = sdf_generator(num_rows, 15)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 15")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
15
15パーティションを12パーティションにcoalesceして偏りを生じさせます。
sdf = sdf_generator(num_rows, 15)
sdf = sdf.coalesce(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line skewed 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
15パーティションを12パーティション、そして、8パーティションにcoalesceします。
sdf = sdf_generator(num_rows, 15)
sdf = sdf.coalesce(12)
sdf = sdf.coalesce(8)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Coalesce for Skew 8")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
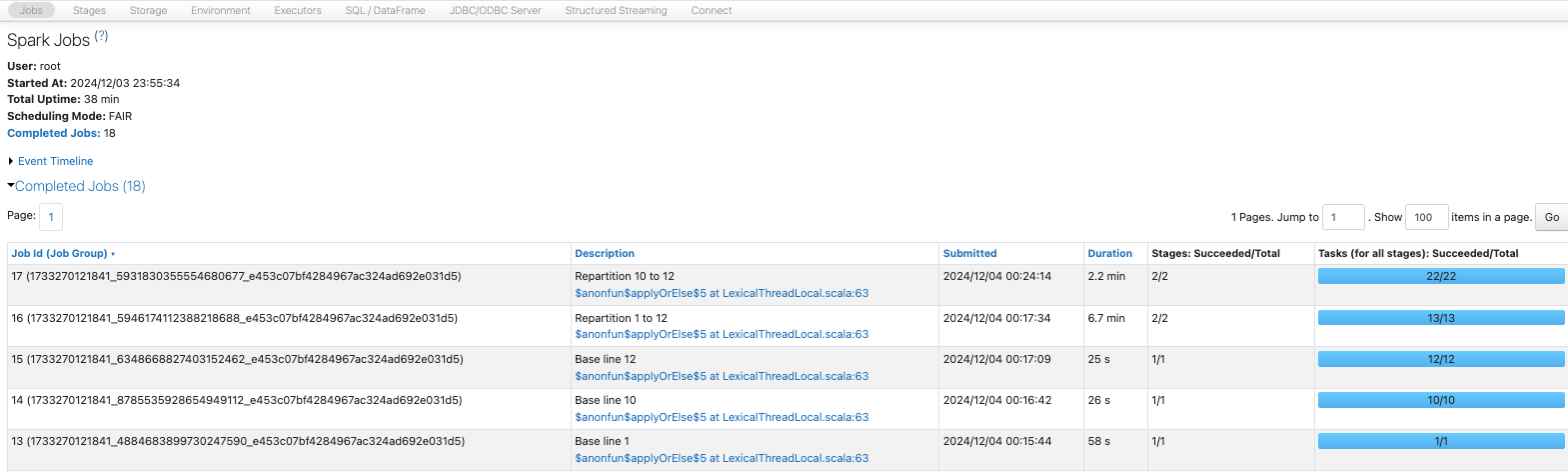
ここで、Spark UIのSQL / Dataframeタブにアクセスし、当該ジョブの物理実行計画を確認します。Sparkは処理の実行前に計画の最適化を行うので、後で指定されている8パーティションへのcoalesceのみが計画に含まれていることを確認できます。
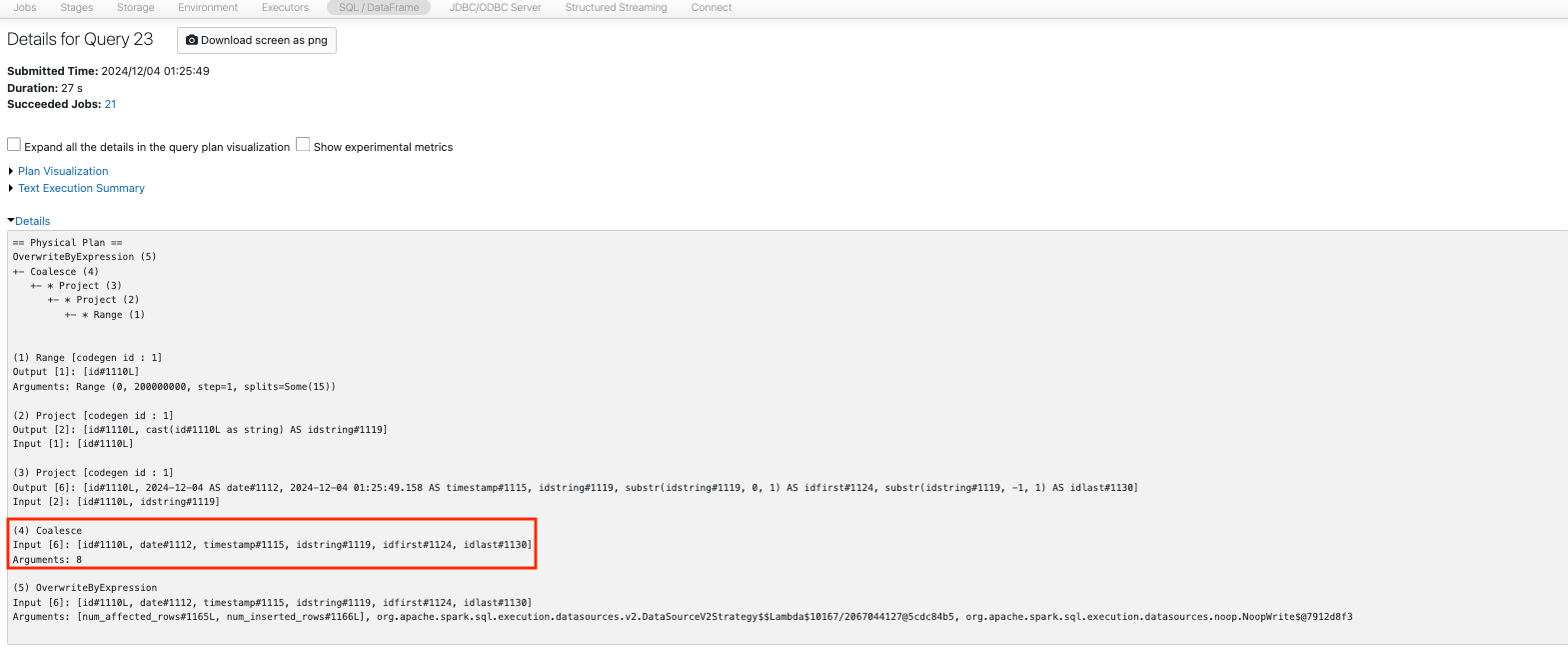
15パーティションを12にcoalesceし、さらに12パーティションでのrepartitionを行います。
sdf = sdf_generator(num_rows, 15)
sdf = sdf.coalesce(12)
sdf = sdf.repartition(12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition for Skew 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
このケースでも、物理計画を確認するとRoundRobinPartitioning(12)から、repartitionのみが計画に含まれるように最適化されていることを確認できます。
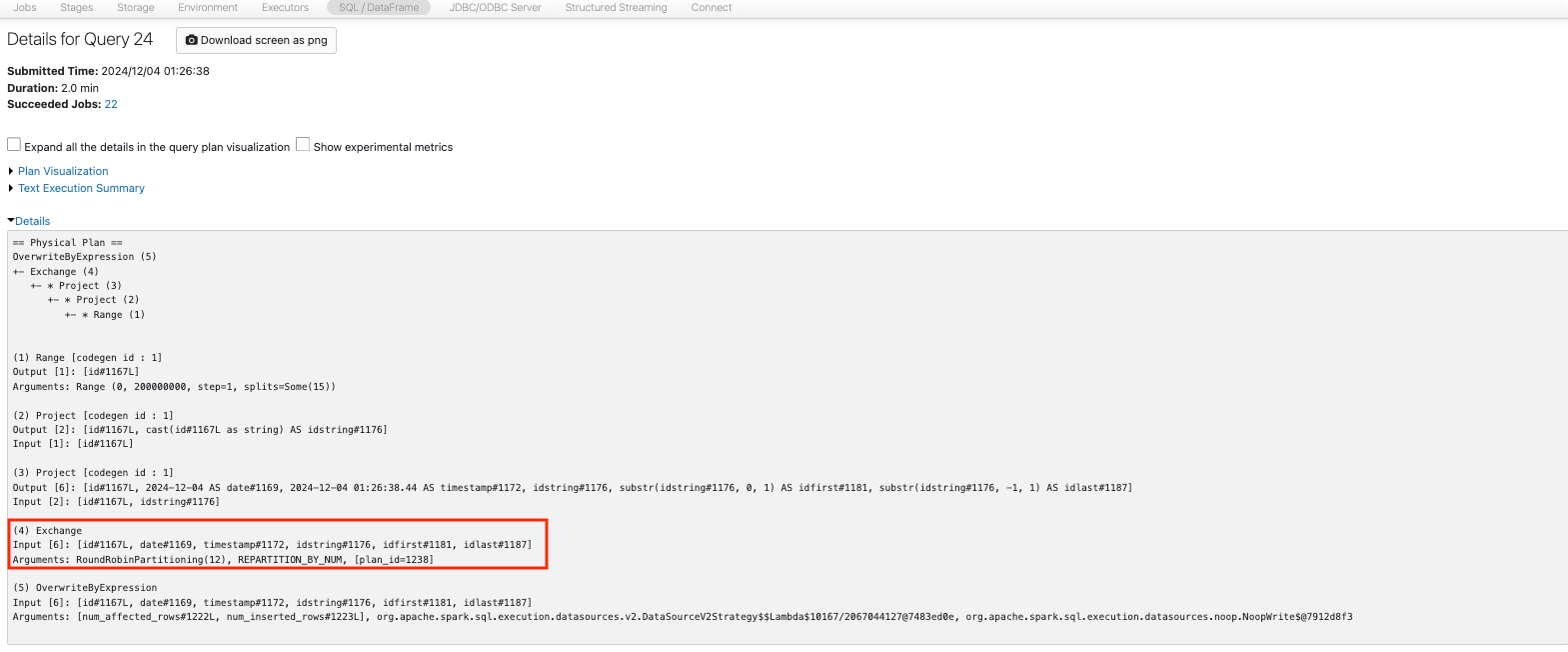
他のケースでもデータの分布や処理時間、物理計画を確認してみましょう。
15パーティションを12にcoalesceし、8にrepartitionします。
sdf = sdf_generator(num_rows, 15)
sdf = sdf.coalesce(12)
sdf = sdf.repartition(8)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Repartition for Skew 8")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
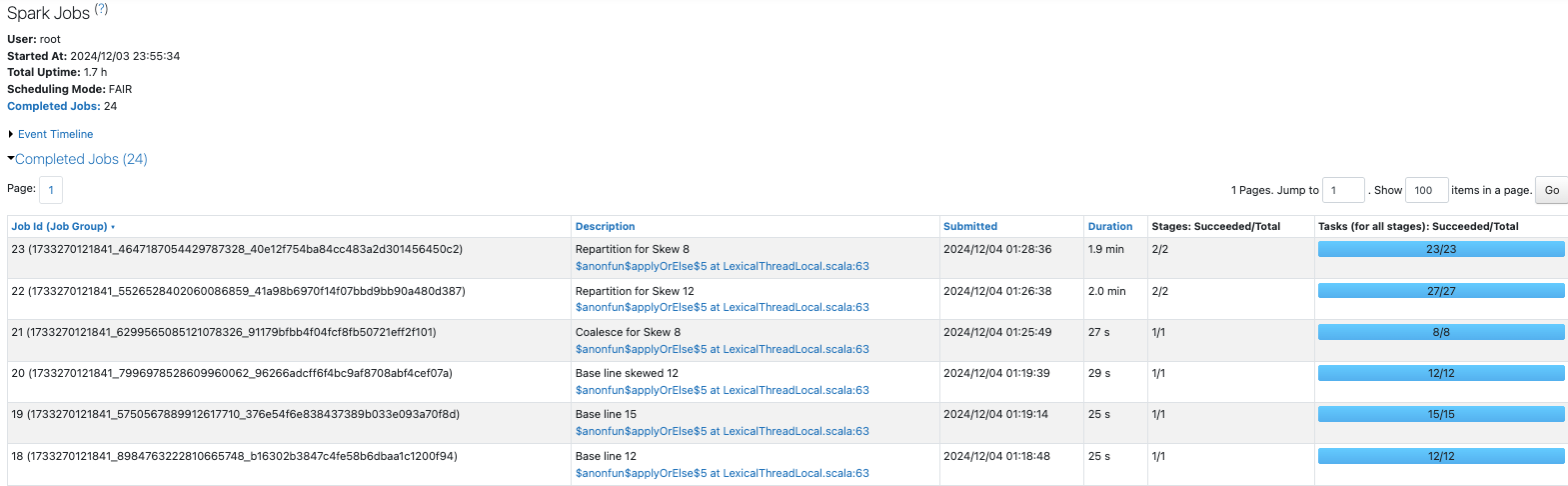
Sparkジョブの一覧は以下のようになります。
8. フィルター操作をより効率的に
パーティショニングを活用することで、フィルタリング処理のパフォーマンスを改善できるケースがあります。
ベースラインとなる12パーティションのデータフレームを作成し、id列に対するフィルタリングを行います。
sdf = sdf_generator(num_rows, 12)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
sdf = sdf_generator(num_rows, 12)
sdf = sdf.filter(f.col("id") < 1000)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12 with filter id")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
処理時間を見ると、repartitionした方が時間がかかっています。

ドリルダウンしていくと、シャッフル(exchange)によって処理時間が増加しています。
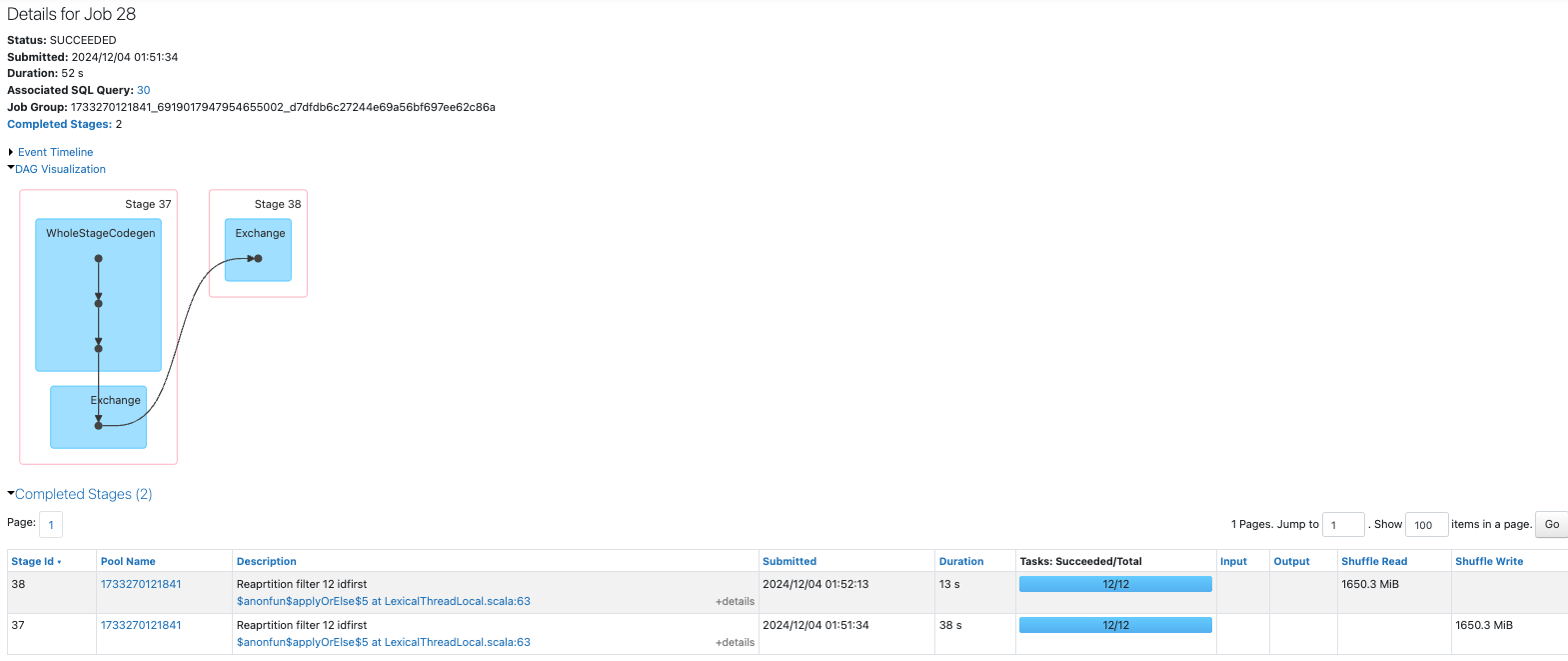
id列は連番なので、それに基づく12のパーティションを作成したとしても、各パーティションにさまざまなidが含まれるため、結果的にシャッフルが生じて、処理時間の増加につながっています。
次は、idfirst列に対するフィルタリングを行います。
sdf = sdf_generator(num_rows, 12)
sdf = sdf.filter(f.col("idfirst") == "1")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12 with filter idfirst")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
idfirst列に基づく12パーティションを作成してフィルタリングを行います。こちらで可視化したように、フィルタリングで指定している1はidfirstの大部分を占めていることに注意してください。結果として、idfirstが1であるデータが含まれる単一の大きなパーティションを作り出すことになります。
sdf = sdf_generator(num_rows, 12)
sdf = sdf.repartition(12, "idfirst")
rows_per_partition_col(sdf, num_rows, "idfirst")
sdf = sdf.filter(f.col("idfirst") == "1")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Reaprtition filter 12 idfirst")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
+------------+-------+---------+----------+
|partition_id|idfirst| count|count_perc|
+------------+-------+---------+----------+
| 0| 1|111111111|55.5555555|
| 3| 0| 1| 5.0E-7|
| 3| 6| 11111111| 5.5555555|
| 3| 7| 11111111| 5.5555555|
| 3| 9| 11111111| 5.5555555|
| 5| 2| 11111111| 5.5555555|
| 6| 4| 11111111| 5.5555555|
| 9| 5| 11111111| 5.5555555|
| 10| 3| 11111111| 5.5555555|
| 10| 8| 11111111| 5.5555555|
+------------+-------+---------+----------+
12
こちらも、repartitionした方が遅くなっています。

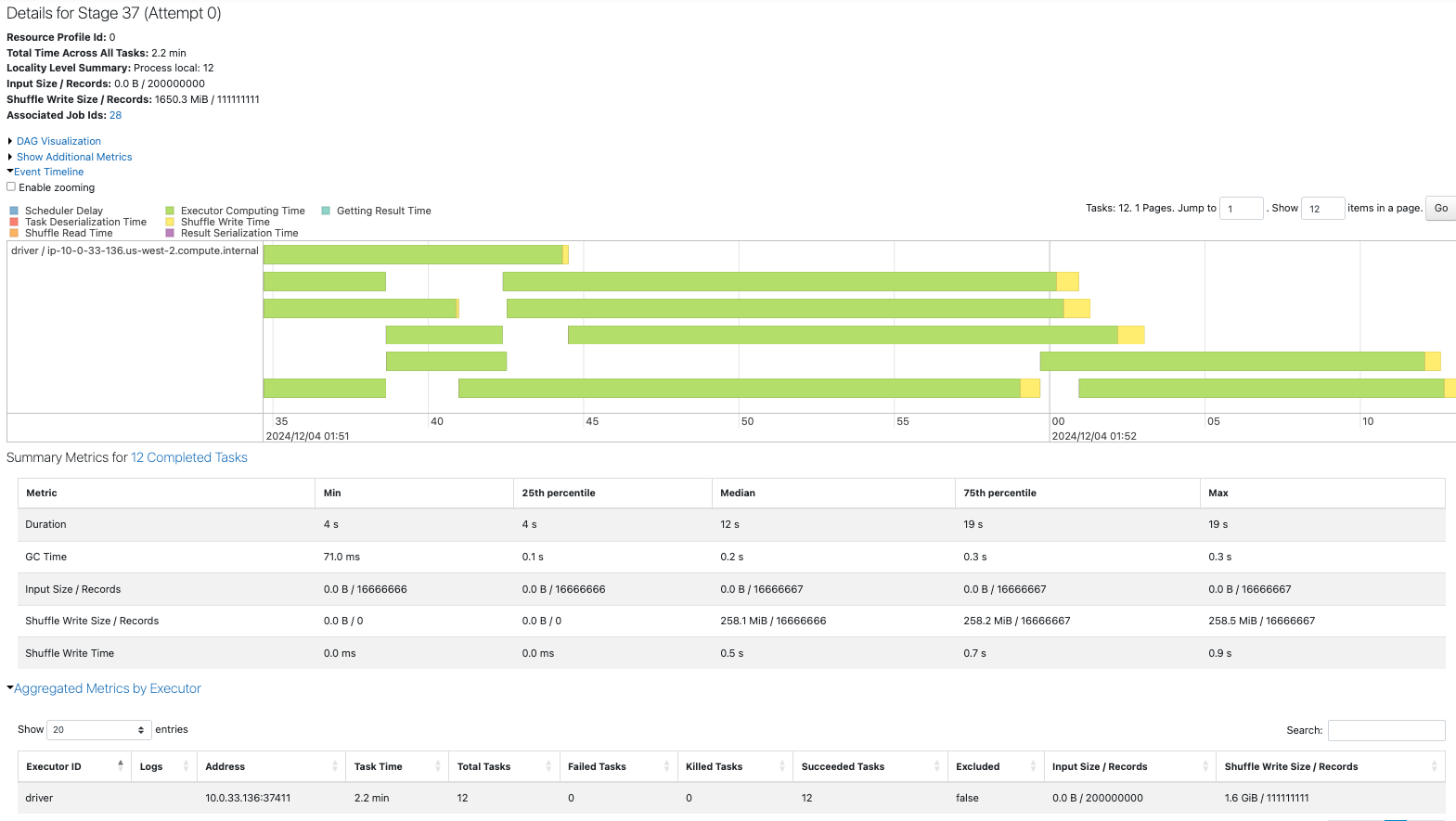
repartionした方のSparkジョブをドリルダウンしていくと、フィルタリングを行なってからシャッフルを行なっていることが実行計画からわかります。


最初のステージでは一部のタスクでは黄色のShuffle Writeが行われていないことがわかります。
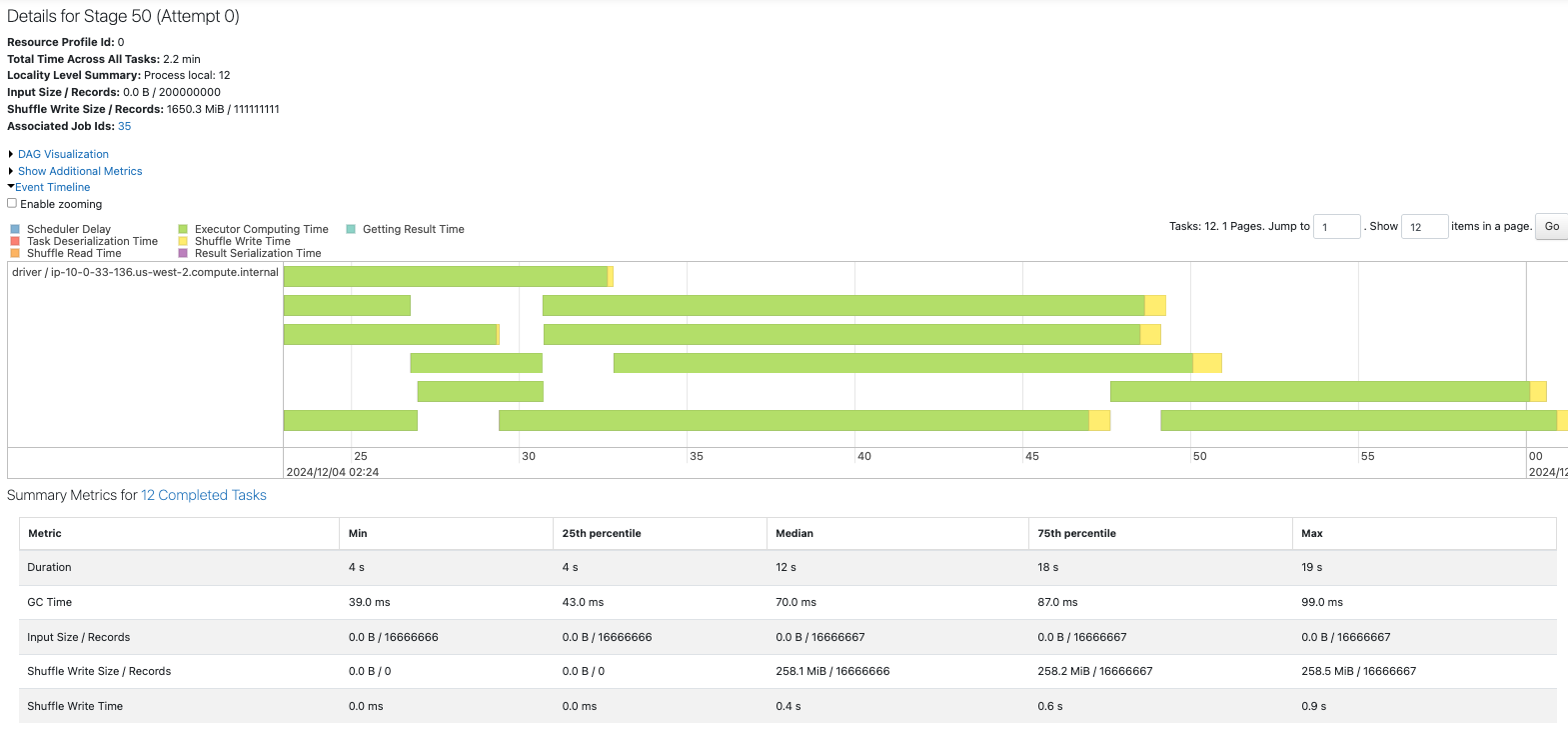
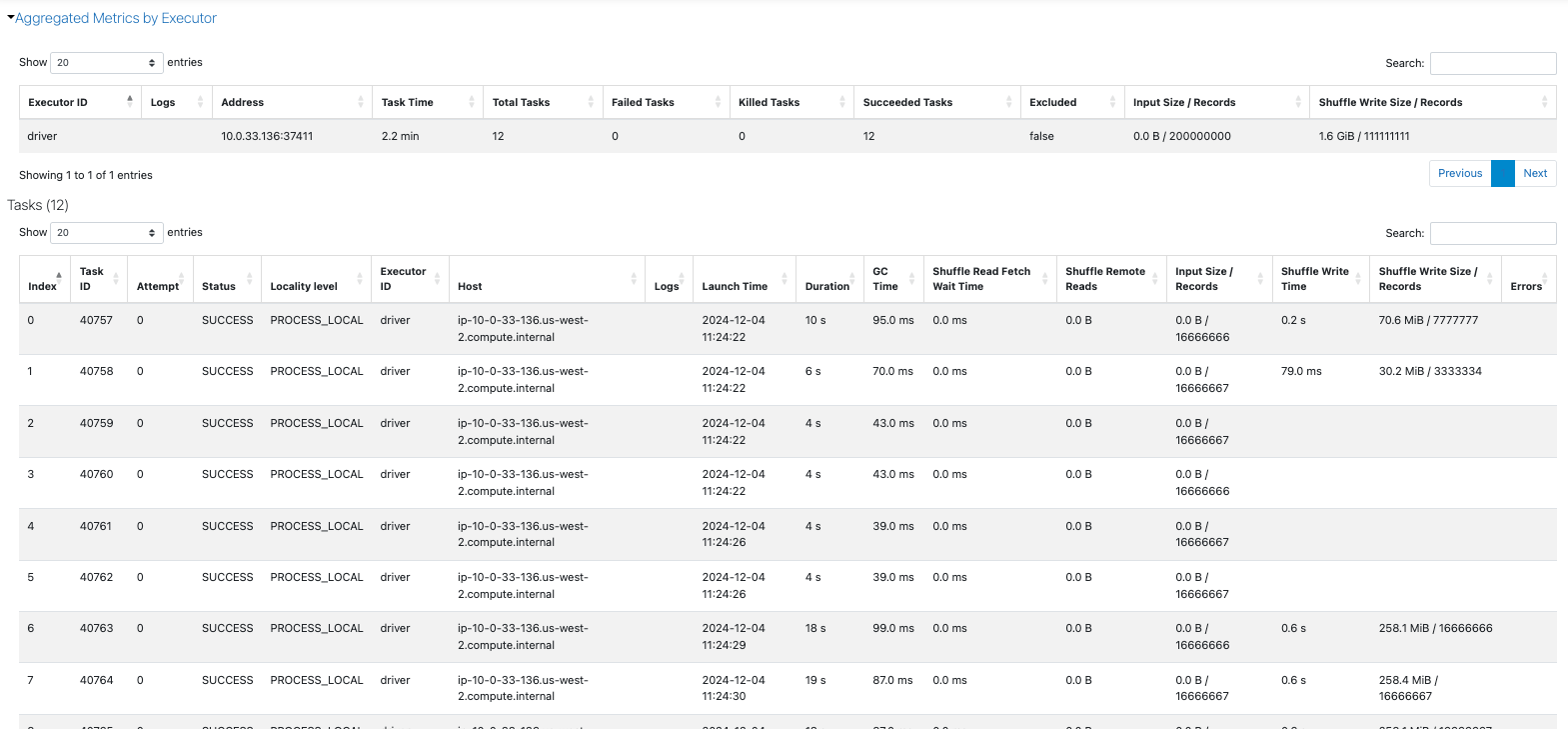
また、111,111,111レコードのシャッフルが発生しているため処理時間の増加につながっていると考えられます。
最後にidlast列に対しても同様のことを行います。
sdf = sdf_generator(num_rows, 12)
sdf = sdf.filter(f.col("idlast") == "1")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 12 with filter idlast")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
12
sdf = sdf_generator(num_rows, 12)
sdf = sdf.repartition(12, "idlast")
rows_per_partition_col(sdf, num_rows, "idlast")
sdf = sdf.filter(f.col("idlast") == "1")
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Reaprtition filter 12 idlast")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
+------------+------+--------+----------+
|partition_id|idlast| count|count_perc|
+------------+------+--------+----------+
| 0| 1|20000000| 10.0|
| 3| 0|20000000| 10.0|
| 3| 6|20000000| 10.0|
| 3| 7|20000000| 10.0|
| 3| 9|20000000| 10.0|
| 5| 2|20000000| 10.0|
| 6| 4|20000000| 10.0|
| 9| 5|20000000| 10.0|
| 10| 3|20000000| 10.0|
| 10| 8|20000000| 10.0|
+------------+------+--------+----------+
12
repartionのシャッフルによるインパクトはありますが、idlastによるパーティションは均等なため、idfirstのケースよりも性能へのインパクトは軽微です。
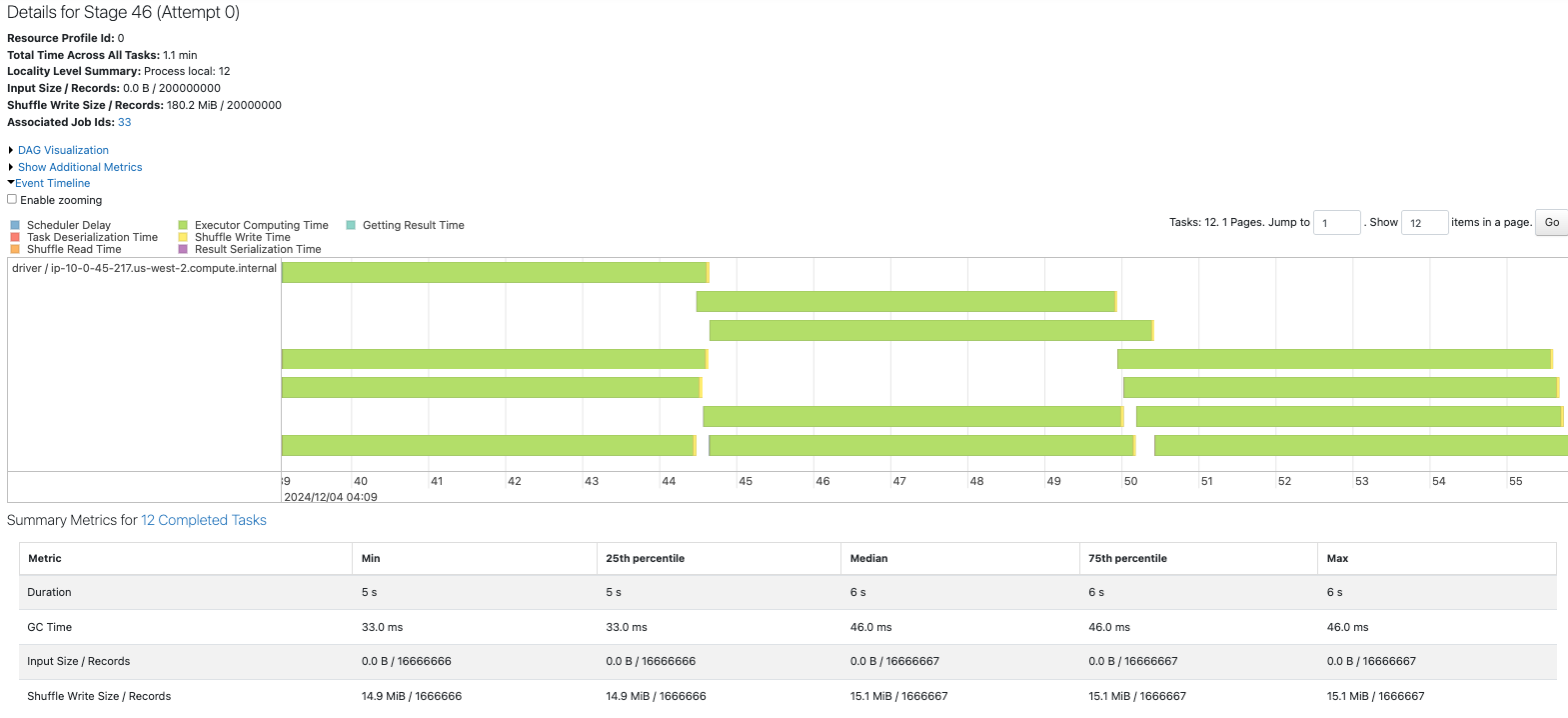
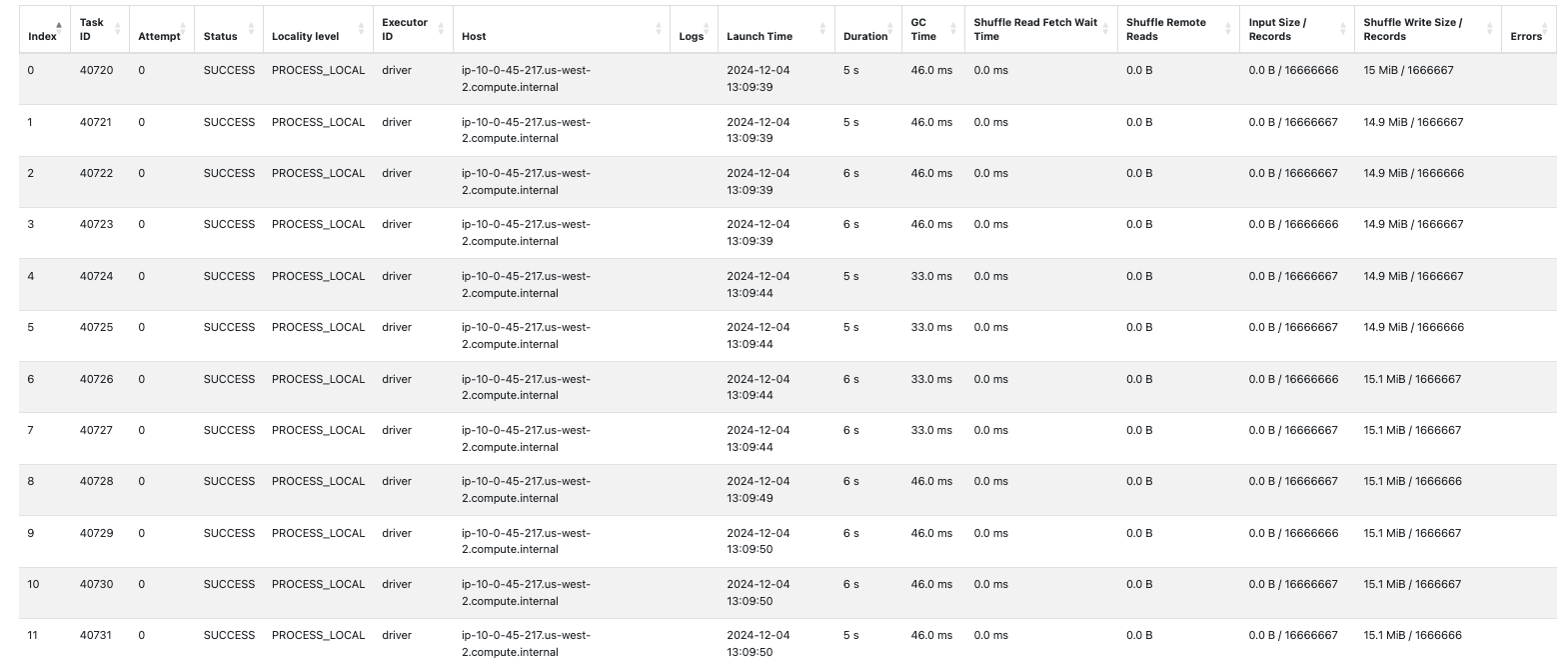
今回はいずれもベースラインよりも時間を要している結果になっていますが、フィルタリングとパーティションの挙動を理解することには意義があると思います。
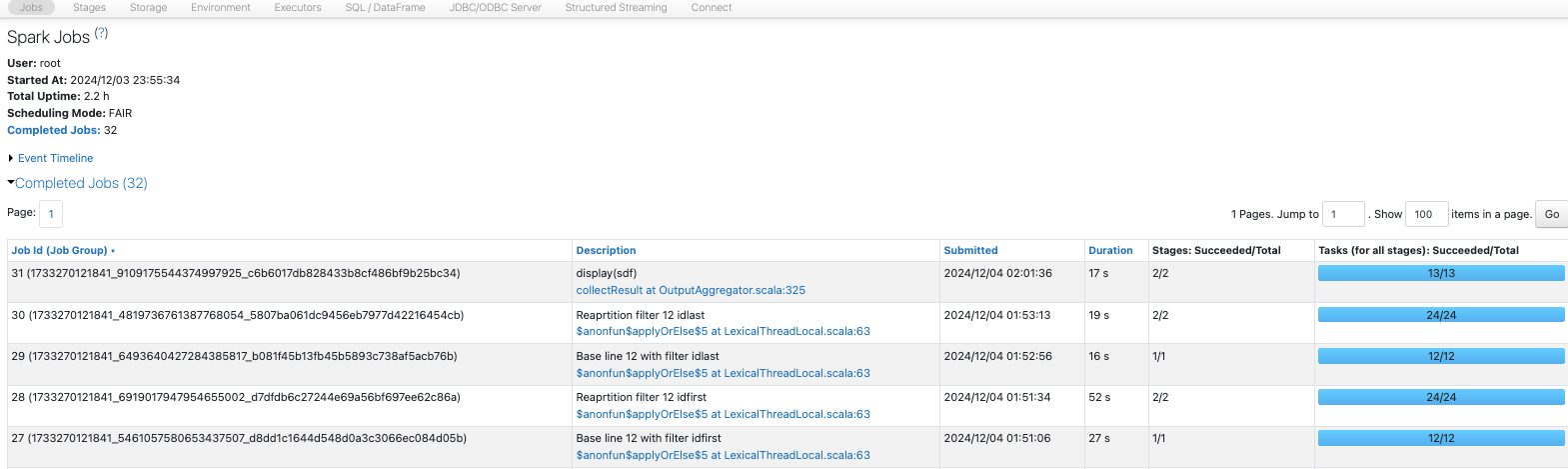
9. より大きなフィルター操作と空のパーティション
ベースラインの20パーティションと4パーティションのデータフレームを作成します。
sdf = sdf_generator(num_rows, 20)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 20")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
rows_per_partition(sdf)
+------------+--------+----------+
|partition_id| count|count_perc|
+------------+--------+----------+
| 0|10000000| 5.0|
| 1|10000000| 5.0|
| 2|10000000| 5.0|
| 3|10000000| 5.0|
| 4|10000000| 5.0|
| 5|10000000| 5.0|
| 6|10000000| 5.0|
| 7|10000000| 5.0|
| 8|10000000| 5.0|
| 9|10000000| 5.0|
| 10|10000000| 5.0|
| 11|10000000| 5.0|
| 12|10000000| 5.0|
| 13|10000000| 5.0|
| 14|10000000| 5.0|
| 15|10000000| 5.0|
| 16|10000000| 5.0|
| 17|10000000| 5.0|
| 18|10000000| 5.0|
| 19|10000000| 5.0|
+------------+--------+----------+
sdf = sdf_generator(num_rows, 4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 4")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
200行のみを選択するフィルタリングを行います。
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line 200 filter")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
20
結果として、20パーティションありながらも、1つのパーティションのみがデータを保持することになります。これは、後続の処理においてデータの不均衡を引き起こします。
rows_per_partition(sdf)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 200| 100.0|
+------------+-----+----------+
不均衡を避けるためにcoalesceを行います。しかし、coalesceはデータの再分配を行わないので意味がありません。空のパーティションをまとめても効果はありません。
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.coalesce(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 coalesce")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
4
rows_per_partition(sdf)
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 200| 100.0|
+------------+-----+----------+
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.repartition(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 repartition")
sdf.write.format("noop").mode("overwrite").save()
sc.setJobDescription("None")
4
rows_per_partition(sdf)
フィルタリング結果が無事再分配されました。
+------------+-----+----------+
|partition_id|count|count_perc|
+------------+-----+----------+
| 0| 50| 25.0|
| 1| 50| 25.0|
| 2| 50| 25.0|
| 3| 50| 25.0|
+------------+-----+----------+
10. より大きなフィルタリングとカウント
ベースラインとして、パーティション数20と4のデータフレームのカウントを取得します。
sdf = sdf_generator(num_rows, 20)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line Count 20")
print(sdf.count())
sc.setJobDescription("None")
20
200000000
sdf = sdf_generator(num_rows, 4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("Base line Count 4")
print(sdf.count())
sc.setJobDescription("None")
4
200000000
パーティション数4の方が早いです。これはパーティション数の増加に伴うスケジューラの遅延を回避しているためと考えられます。
20パーティション
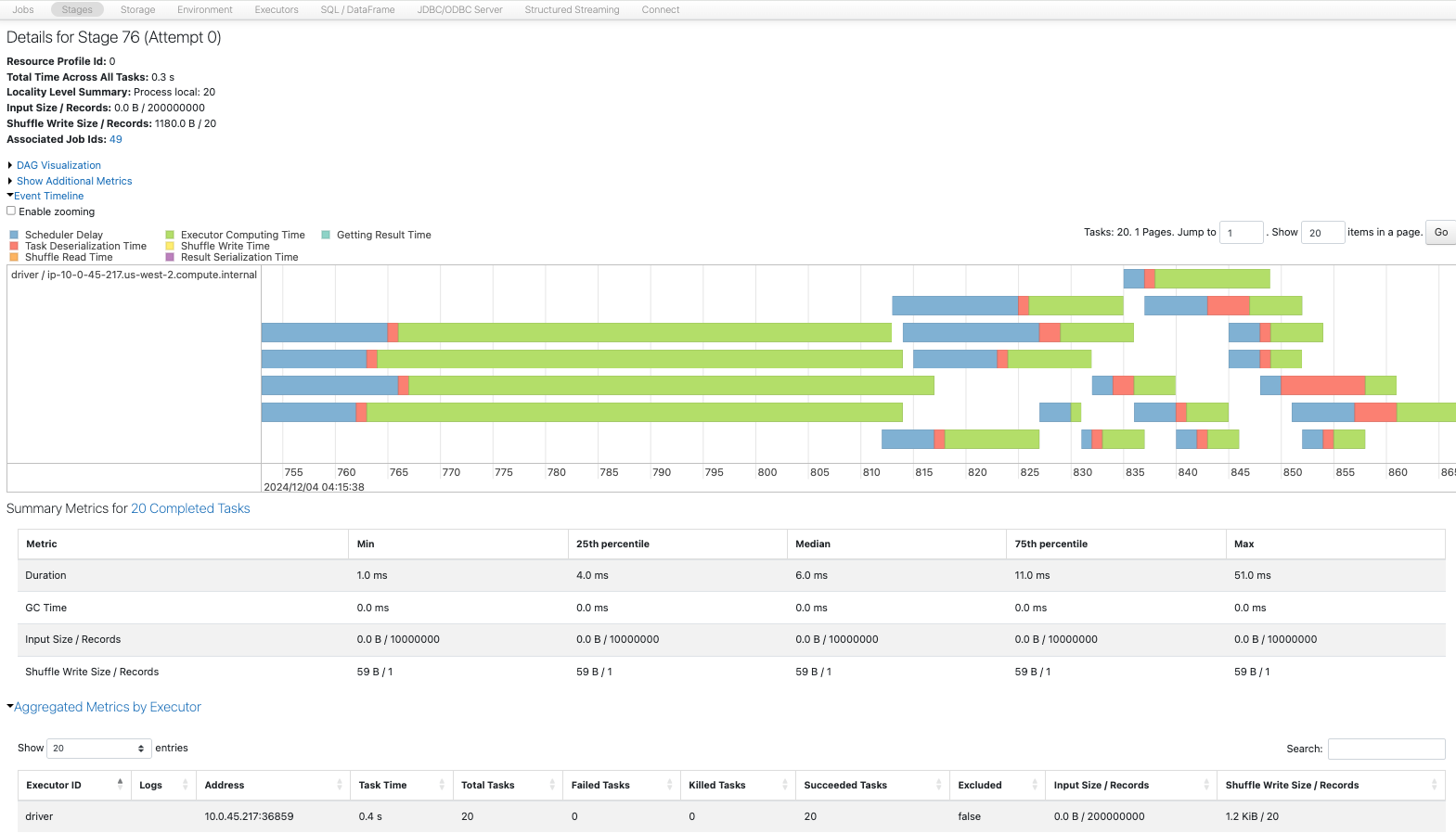
4パーティション
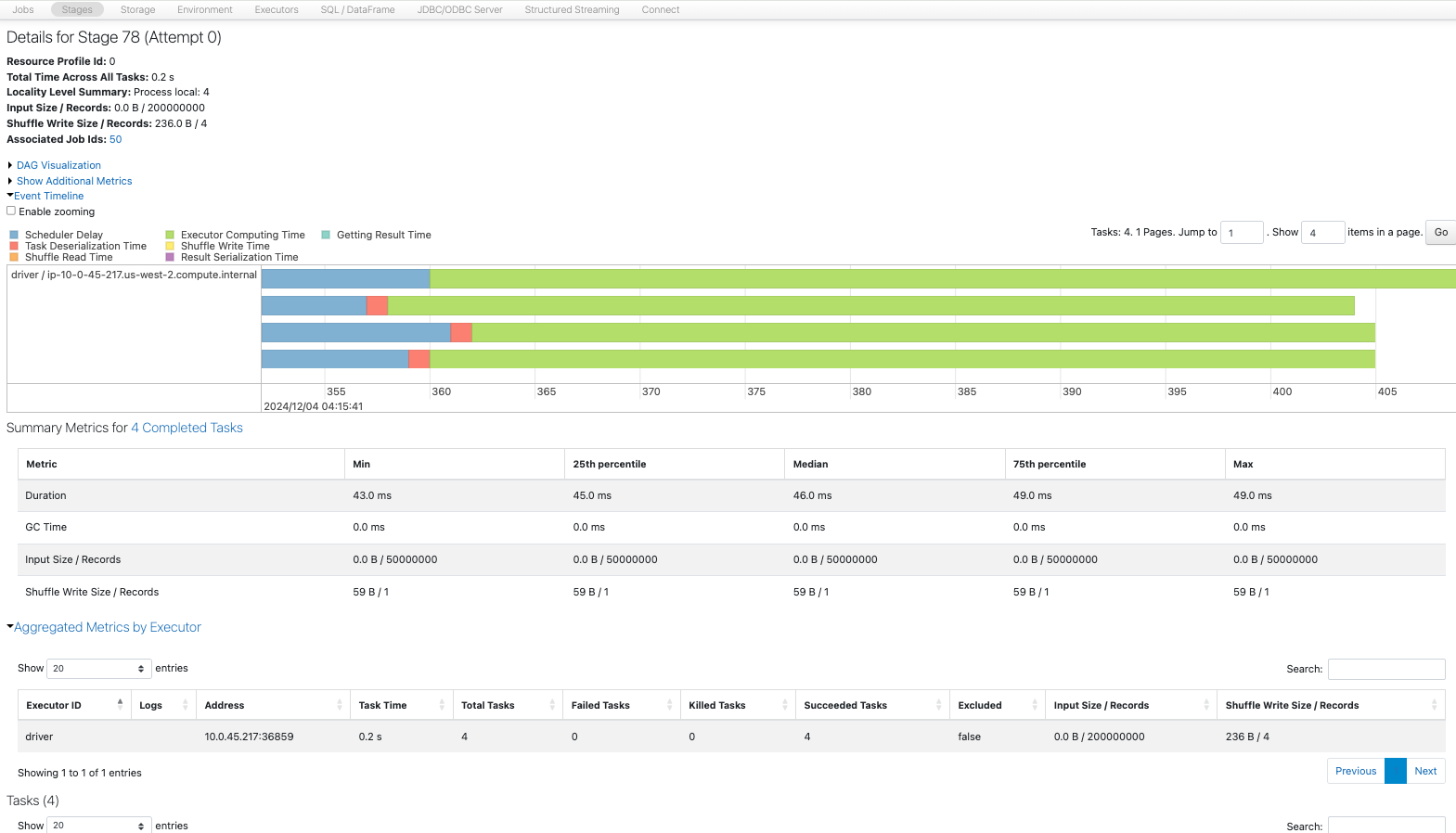
フィルタリングを行うことで、取り扱うデータ量が削減されるので処理時間は短縮されます。

sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.coalesce(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 coalesce count")
print(sdf.count())
sc.setJobDescription("None")
4
200
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.repartition(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 repartition count")
print(sdf.count())
sc.setJobDescription("None")
4
200
フィルタリングを行うことで、取り扱うデータ量が削減されるので処理時間は短縮されます。そして、coalesceを適用するかrepartitionを適用するのかに応じて、カウントの挙動が異なります。
-
coalesce: フィルタリングされたデータは1パーティションに留まり続けるので、1タスクがカウントを行う -
repartition: データが複数のパーティション(以下の例では4)に再分配されるので、4タスクがカウントを行う

sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.coalesce(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 coalesce count")
print(sdf.count())
sc.setJobDescription("None")
4
200
1タスクがカウントを行います。
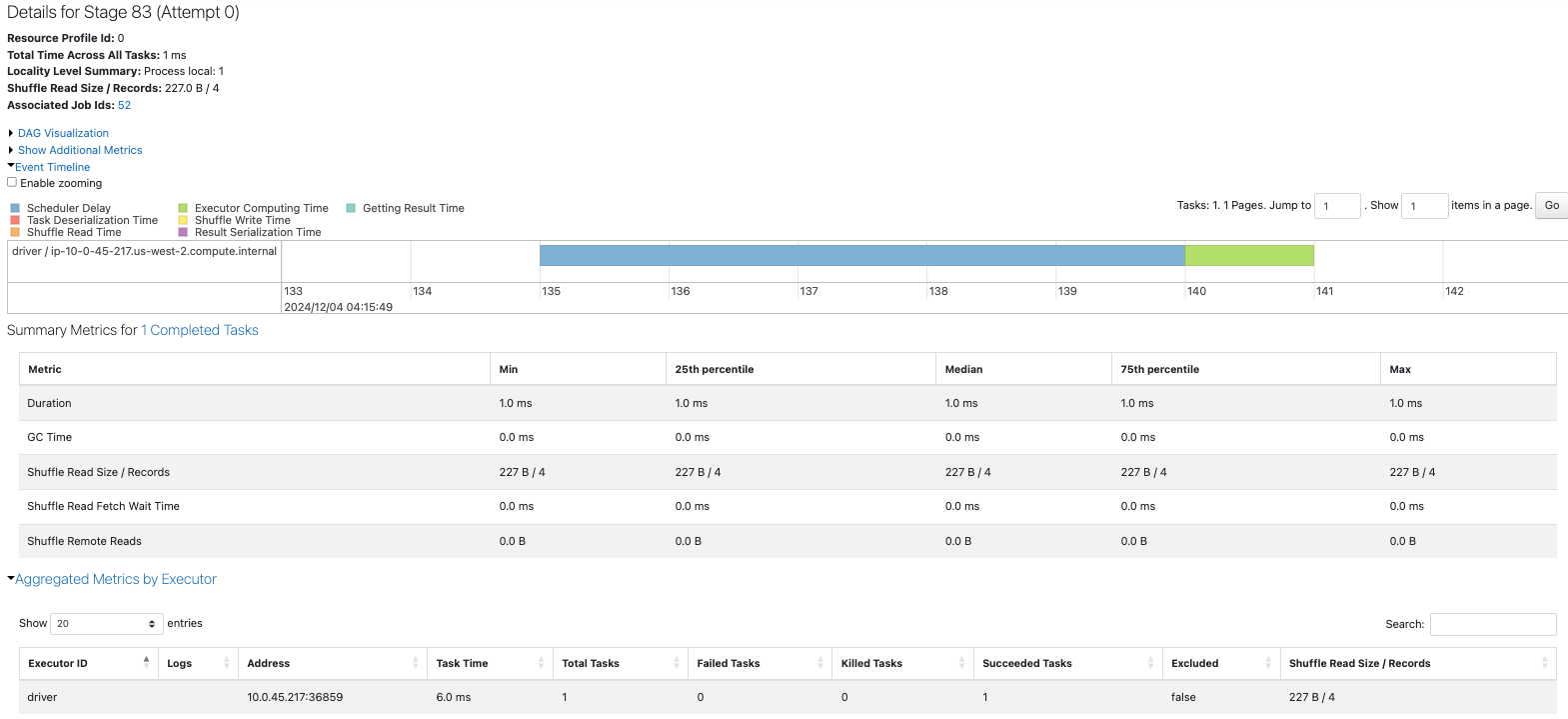
sdf = sdf_generator(num_rows, 20)
sdf = sdf.filter(f.col("id") < 200)
sdf = sdf.repartition(4)
print(sdf.rdd.getNumPartitions())
sc.setJobDescription("4 repartition count")
print(sdf.count())
sc.setJobDescription("None")
4
200
4タスクでカウントを行います。
パーティションの数、データの分布を踏まえて処理を理解することが重要だと感じました。
11. 最後のコメント
- 現在のプロセスのパフォーマンスとデータの分散をバランスさせる必要があります。これにより、データクエリや結合、ソートなどの操作において利益を得ることができます。
- ここで深く掘り下げても、パフォーマンスの重要なボトルネックが明らかになる場合にのみ意味があります。たとえば、実行時間を10秒短縮できるとしても、それは価値があるでしょうか?しかし、少量のデータが毎日3時間かかり、それを15分に短縮できる場合は、改善する価値があります。
- Spark UIで以下の点について簡単に確認する必要があります:
- ドライバーメモリが多く消費されているか、つまり
collect()などのドライバーの実行が行われているか(後で詳しく調査) - すべてのコアが使用されているか
- ディスクへのスピルが発生しているか(後で詳しく調査)
- ドライバーメモリが多く消費されているか、つまり
次はパーティションの数とファイル書き込みの関係性について学びます。