こちらのデバッグ用ノートブックをウォークスルーします。
ai_parse_document 関数の概要
ai_parse_document()は、Databricks基盤モデルAPIの最先端のGenerative AIモデルを呼び出して、非構造化ドキュメントから構造化されたコンテンツを抽出する関数です。
主な特徴:
- 対応フォーマット: PDF、JPG/JPEG、PNG、DOC/DOCX、PPT/PPTX
- 抽出内容: ページ番号、ヘッダー、フッター、テキスト段落などのレイアウトメタデータ、テーブル(HTML形式)、図の説明など
- 出力形式: VARIANT型
基本構文
SELECT ai_parse_document(content) FROM READ_FILES('/path/to/documents', format => 'binaryFile');
請求書やPDFから特定情報(ベンダー名、日付、品目など)を抽出し、ai_queryと組み合わせて構造化データに変換するようなユースケースに最適です。
制限事項
-
処理時間: ドキュメントの構造情報を保持しながらコンテンツを抽出するため、特に高密度なコンテンツや解像度の低いコンテンツを含むドキュメントでは時間がかかる場合があります。
-
非ラテン文字の問題: 基盤となるモデルは、日本語や韓国語などの非ラテン文字のテキストを含む画像を処理する際に最適なパフォーマンスを発揮しない場合があります。
-
デジタル署名: デジタル署名を含むドキュメントは正確に処理されない場合があります。
-
カスタマイズ不可:
ai_parse_documentを動かすモデルのカスタマイズや、顧客が提供するモデルの使用はサポートされていません。 -
言語対応: 基盤となる言語モデルは複数の言語を処理できますが、このAI関数は英語向けにチューニングされています。
デバッグノートブック
以下のノートブックでは、ai_parse_document関数の出力を分析するための視覚的なデバッグインターフェースを提供します。解析されたドキュメントをインタラクティブなバウンディングボックスのオーバーレイとともにレンダリングし、ドキュメントの各領域からどのようなコンテンツが抽出されたかを確認できます。
日本語訳したノートブックです。元のノートブックでは途中エラーになった(修正依頼中)ので一部修正しています。
事前にボリュームにパースするPDFを格納しておきます。
🔍 AI Document Analysis Debug Interface
バージョン 1.2
最終更新日: 2025年10月6日(木)
変更履歴:
-
input_fileが未設定の場合、入力ディレクトリ内の全ファイルを処理します。
概要
このノートブックは、Databricksの ai_parse_document 関数の出力を分析するビジュアルデバッグインターフェースを提供します。解析されたドキュメントをインタラクティブなバウンディングボックス付きで表示し、各領域から抽出された内容を確認できます。
特長
- 📊 ビジュアルバウンディングボックス: テキストや要素が検出された領域を色分けして表示
- 🎯 インタラクティブツールチップ: バウンディングボックスにカーソルを合わせると、その領域の解析内容を表示
- 📐 自動スケーリング: 大きなドキュメントも最適な幅(1024px)に自動調整
- 🎨 要素タイプの可視化: テキスト、ヘッダー、表、図など要素ごとに色分け
必要なパラメータ
このインターフェースを利用するには、2つのUnity Catalog(UC)ボリュームパスの設定が必要です。
1. source_files
- 説明: 解析・可視化したいドキュメントが格納されているUCボリュームのパス
-
例:
/Volumes/catalog/schema/volume/documents/ - 要件: PDFや画像ファイルが格納されたボリュームへの読み取り権限
2. image_output_path
-
説明:
ai_parse_documentが抽出したページ画像を保存する書き込み可能なUCボリュームのパス -
例:
/Volumes/catalog/schema/volume/parsed_images/ - 要件: 中間画像出力の保存のため書き込み権限が必要
- 備考: 公式Databricksドキュメントに記載の通り、このパスは解析関数がページ画像を保存するために使用されます
3. page_selection
ページ選択文字列を解析し、表示するページインデックスのリストを返します。対応フォーマット:
- "all" または None: 全ページを表示
- "3": 特定ページ(1始まり)
- "1-5": ページ範囲(両端含む、1始まり)
- "1,3,5": 特定ページのリスト(1始まり)
- "1-3,7,10-12": 範囲と個別ページの混在
利用手順
-
このノートブックをクローンしてください:
- 上部ツールバーの 「ファイル → クローン」 を選択
- 任意のワークスペースに保存
- これにより、編集・実行可能な個人用コピーが作成されます
-
ボリューム内に input と output ディレクトリを作成し、PDFファイルをinputディレクトリにアップロードしてください。
-
ノートブック上部の入力ボックスでパラメータを設定してください
-
全てのコードセルを実行し、ビジュアルデバッグ結果を生成してください
期待される結果
- ドキュメント概要: ページ数、要素数、メタデータの表示
- 色分け凡例: 要素タイプごとの色ガイド
-
注釈付き画像: 各ページにバウンディングボックスを重ねて表示
- 任意のボックスにカーソルを合わせると抽出内容を表示
- 現在ホバー中の要素は黄色で強調
- 解析要素リスト: 抽出された全要素とその内容の一覧
# Execution Parameters
dbutils.widgets.text("catalog", "")
dbutils.widgets.text("schema", "")
dbutils.widgets.text("volume", "")
dbutils.widgets.text("input_file", "")
dbutils.widgets.text("page_selection", "all")
catalog = dbutils.widgets.get("catalog")
schema = dbutils.widgets.get("schema")
volume = dbutils.widgets.get("volume")
input_file = dbutils.widgets.get("input_file")
page_selection = dbutils.widgets.get("page_selection")
パラメーターの設定
# 設定パラメータ
source_files = f"/Volumes/{catalog}/{schema}/{volume}/input/{input_file}"
image_output_path = f"/Volumes/{catalog}/{schema}/{volume}/output/"
# ページ選択文字列を解析し、表示するページインデックスのリストを返します。
# 対応フォーマット:
# - "all" または None: 全ページを表示
# - "3": 特定ページ(1始まり)
# - "1-5": ページ範囲(両端含む、1始まり)
# - "1,3,5": 特定ページのリスト(1始まり)
# - "1-3,7,10-12": 範囲と個別ページの混在
page_selection = f"{page_selection}"
ドキュメントパースコードの実行 (少し時間かかります)
# ドキュメント解析実行コード(時間がかかる場合があります)
import json
# ai_parse_document() を使ったSQL文
if not input_file:
source_files = f"/Volumes/{catalog}/{schema}/{volume}/input/*"
sql = f'''
with parsed_documents AS (
SELECT
path,
ai_parse_document(content
,
map(
'version', '2.0',
'imageOutputPath', '{image_output_path}',
'descriptionElementTypes', '*'
)
) as parsed
FROM
read_files('{source_files}', format => 'binaryFile')
)
select path, to_json(parsed) as parsed_json from parsed_documents
'''
parsed_results = [json.loads(row.parsed_json) for row in spark.sql(sql).collect()]
デバッガー関数のロード
デバッガー関数
# デバッガ関数の読み込み
import base64
import io
import json
import os
from typing import Any, Dict, List, Optional, Set, Tuple, Union
from IPython.display import HTML, display
from PIL import Image
class DocumentRenderer:
def __init__(self):
# 異なる要素タイプの色のマッピング
self.element_colors = {
"section_header": "#FF6B6B",
"text": "#4ECDC4",
"figure": "#45B7D1",
"caption": "#96CEB4",
"page_footer": "#FFEAA7",
"page_header": "#DDA0DD",
"table": "#98D8C8",
"list": "#F7DC6F",
"default": "#BDC3C7",
}
def _parse_page_selection(
self, page_selection: Union[str, None], total_pages: int
) -> Set[int]:
"""ページ選択文字列を解析し、表示するページインデックスのセットを返します。
引数:
page_selection: 選択文字列またはNone
total_pages: 利用可能なページの総数
戻り値:
表示する0ベースのページインデックスのセット
"""
# Noneまたは"all"を処理 - すべてのページを返す
if page_selection is None or page_selection.lower() == "all":
return set(range(total_pages))
selected_pages = set()
# 入力をクリーンアップ
page_selection = page_selection.strip()
# 複数選択のためにカンマで分割
parts = page_selection.split(",")
for part in parts:
part = part.strip()
# 範囲かどうかを確認(ハイフンを含む)
if "-" in part:
try:
# 範囲を分割し、整数に変換
range_parts = part.split("-")
if len(range_parts) == 2:
start = int(range_parts[0].strip())
end = int(range_parts[1].strip())
# 1ベースから0ベースに変換
start_idx = start - 1
end_idx = end - 1
# 範囲内のすべてのページを追加(含む)
for i in range(start_idx, end_idx + 1):
if 0 <= i < total_pages:
selected_pages.add(i)
except ValueError:
print(f"警告: ページ選択の範囲 '{part}' が無効です")
else:
# 単一ページ番号
try:
page_num = int(part.strip())
# 1ベースから0ベースに変換
page_idx = page_num - 1
if 0 <= page_idx < total_pages:
selected_pages.add(page_idx)
else:
print(
f"警告: ページ {page_num} は範囲外です (1-{total_pages})"
)
except ValueError:
print(f"警告: ページ選択の番号 '{part}' が無効です")
# 有効なページが選択されていない場合、すべてのページにデフォルト
if not selected_pages:
print(
f"警告: 選択 '{page_selection}' に有効なページがありません。すべてのページを表示します。"
)
return set(range(total_pages))
return selected_pages
def _get_element_color(self, element_type: str) -> str:
"""要素タイプの色を取得します。"""
return self.element_colors.get(
element_type.lower(), self.element_colors["default"]
)
def _get_image_dimensions(self, image_path: str) -> Optional[Tuple[int, int]]:
"""画像ファイルの寸法を取得します。"""
try:
if os.path.exists(image_path):
with Image.open(image_path) as img:
return img.size # (幅、高さ)を返します
return None
except Exception as e:
print(f"{image_path} の画像寸法を取得中にエラーが発生しました: {e}")
return None
def _load_image_as_base64(self, image_path: str) -> Optional[str]:
"""ファイルパスから画像を読み込み、base64に変換します。"""
try:
if os.path.exists(image_path):
with open(image_path, "rb") as img_file:
img_data = img_file.read()
img_base64 = base64.b64encode(img_data).decode("utf-8")
ext = os.path.splitext(image_path)[1].lower()
if ext in [".jpg", ".jpeg"]:
return f"data:image/jpeg;base64,{img_base64}"
elif ext in [".png"]:
return f"data:image/png;base64,{img_base64}"
else:
return f"data:image/jpeg;base64,{img_base64}"
return None
except Exception as e:
print(f"{image_path} の画像を読み込む中にエラーが発生しました: {e}")
return None
def _render_element_content(self, element: Dict, for_tooltip: bool = False) -> str:
"""ツールチップと要素リスト表示のために適切なフォーマットで要素コンテンツをレンダリングします。
引数:
element: コンテンツ/説明を含む要素辞書
for_tooltip: これはツールチップ表示のためか(スタイリングと切り詰めに影響)
"""
element_type = element.get("type", "unknown")
content = element.get("content", "")
description = element.get("description", "")
display_content = ""
if content:
if element_type == "table":
# スタイリングを適用したHTMLテーブルをレンダリング
table_html = content
# コンテキストに基づいて異なるスタイリングを適用
if for_tooltip:
# ツールチップ用のコンパクトスタイリング
# ツールチップテーブルのために利用可能な全幅を使用
table_style = f'''style="width: 100%; border-collapse: collapse; margin: 5px 0; font-size: 10px;"'''
th_style = 'style="border: 1px solid #ddd; padding: 4px; background: #f8f9fa; color: #333; font-weight: bold; text-align: left; font-size: 10px;"'
td_style = 'style="border: 1px solid #ddd; padding: 4px; color: #333; font-size: 10px;"'
thead_style = 'style="background: #e9ecef;"'
else:
# 要素リスト用のフルスタイリング
table_style = '''style="width: 100%; border-collapse: collapse; margin: 10px 0; font-size: 13px;"'''
th_style = 'style="border: 1px solid #ddd; padding: 8px; background: #f5f5f5; font-weight: bold; text-align: left;"'
td_style = 'style="border: 1px solid #ddd; padding: 8px;"'
thead_style = 'style="background: #f0f0f0;"'
# スタイリング変換を適用
if "<table>" in table_html:
table_html = table_html.replace("<table>", f"<table {table_style}>")
if "<th>" in table_html:
table_html = table_html.replace("<th>", f"<th {th_style}>")
if "<td>" in table_html:
table_html = table_html.replace("<td>", f"<td {td_style}>")
if "<thead>" in table_html:
table_html = table_html.replace("<thead>", f"<thead {thead_style}>")
if for_tooltip:
display_content = table_html
else:
display_content = f"<div style='overflow-x: auto; margin: 10px 0;'>{table_html}</div>"
else:
# 通常のコンテンツ処理
if for_tooltip and len(content) > 500:
# ツールチップ表示用に切り詰め、HTMLを安全にエスケープ
display_content = self._escape_for_html_attribute(
content[:500] + "..."
)
else:
display_content = (
self._escape_for_html_attribute(content)
if for_tooltip
else content
)
elif description:
desc_content = description
if for_tooltip and len(desc_content) > 500:
desc_content = desc_content[:500] + "..."
if for_tooltip:
display_content = self._escape_for_html_attribute(
f"説明: {desc_content}"
)
else:
display_content = f"<em>説明: {desc_content}</em>"
else:
display_content = (
"利用可能なコンテンツはありません" if for_tooltip else "<em>コンテンツなし</em>"
)
return display_content
def _escape_for_html_attribute(self, text: str) -> str:
"""HTML属性で安全に使用するためにテキストをエスケープします."""
return (
text.replace("&", "&")
.replace("<", "<")
.replace(">", ">")
.replace('"', """)
.replace("'", "'")
.replace("\n", "<br>")
)
def _calculate_tooltip_width(self, element: Dict, image_width: int) -> int:
"""テーブルコンテンツに基づいて動的なツールチップの幅を計算します。"""
element_type = element.get("type", "unknown")
content = element.get("content", "")
if element_type == "table" and content:
# 最初の行で<th>または<td>タグを探して列をカウント
import re
# 最初の行を見つける(theadまたはtbodyのいずれか)
first_row_match = re.search(
r"<tr[^>]*>(.*?)</tr>", content, re.DOTALL | re.IGNORECASE
)
if first_row_match:
first_row = first_row_match.group(1)
# thまたはtdタグをカウント
th_count = len(re.findall(r"<th[^>]*>", first_row, re.IGNORECASE))
td_count = len(re.findall(r"<td[^>]*>", first_row, re.IGNORECASE))
column_count = max(th_count, td_count)
if column_count > 0:
# 基本幅 + 列ごとの追加幅
base_width = 300
width_per_column = 80
calculated_width = base_width + (column_count * width_per_column)
# 画像幅の4/5に制限
max_width = int(image_width * 0.8)
return min(calculated_width, max_width)
# テーブル以外または計算が失敗した場合のデフォルト幅
return 400
def _create_annotated_image(self, page: Dict, elements: List[Dict]) -> str:
"""1024px幅に収まるようにスケーリングされた注釈付き画像を作成します。"""
image_uri = page.get("image_uri", "")
page_id = page.get("id", 0)
if not image_uri:
return "<p style='color: red;'>このページの画像URIが見つかりません</p>"
# 画像を読み込む
img_data_uri = self._load_image_as_base64(image_uri)
if not img_data_uri:
return f"""
<div style="background: #f8d7da; border: 1px solid #f5c6cb; color: #721c24; padding: 15px; border-radius: 5px;">
<strong>画像を読み込めませんでした:</strong> {image_uri}<br>
<small>ファイルが存在し、アクセス可能であることを確認してください。</small>
</div>
"""
# 元の画像寸法を取得
original_dimensions = self._get_image_dimensions(image_uri)
if not original_dimensions:
# フォールバック: 明示的なスケーリングなしで表示
original_width, original_height = 1024, 768 # デフォルトフォールバック
else:
original_width, original_height = original_dimensions
# 1024px幅に収まるようにスケーリングファクターを計算
max_display_width = 1024
scale_factor = 1.0
display_width = original_width
display_height = original_height
if original_width > max_display_width:
scale_factor = max_display_width / original_width
display_width = max_display_width
display_height = int(original_height * scale_factor)
# このページの要素をフィルタリングし、バウンディングボックスを収集
page_elements = []
for elem in elements:
elem_bboxes = []
for bbox in elem.get("bbox", []):
if bbox.get("page_id", 0) == page_id:
coord = bbox.get("coord", [])
if len(coord) >= 4:
elem_bboxes.append(bbox)
if elem_bboxes:
page_elements.append({"element": elem, "bboxes": elem_bboxes})
if not page_elements:
return f"<p>ページ {page_id} に要素が見つかりません</p>"
header_info = f"""
<div style="background: #e3f2fd; border: 1px solid #2196f3; border-radius: 8px; padding: 15px; margin: 10px 0;">
<strong>ページ {page_id + 1}: {len(page_elements)} 要素</strong><br>
<strong>元のサイズ:</strong> {original_width}×{original_height}px |
<strong>表示サイズ:</strong> {display_width}×{display_height}px |
<strong>スケールファクター:</strong> {scale_factor:.3f}<br>
</div>
"""
# このページのためのユニークなコンテナIDを生成
container_id = f"page_container_{page_id}_{id(self)}"
# スケーリングされた座標を使用してバウンディングボックスオーバーレイを作成し、ホバー機能を追加
overlays = []
for idx, item in enumerate(page_elements):
element = item["element"]
element_id = element.get("id", "N/A")
element_type = element.get("type", "unknown")
color = self._get_element_color(element_type)
# ツールチップ用に共有コンテンツレンダラーを使用
tooltip_content = self._render_element_content(element, for_tooltip=True)
# 動的ツールチップ幅を計算
tooltip_width = self._calculate_tooltip_width(element, display_width)
# テーブルはHTMLとしてレンダリングし、他のコンテンツはエスケープする必要があります
for bbox_idx, bbox in enumerate(item["bboxes"]):
coord = bbox.get("coord", [])
if len(coord) >= 4:
x1, y1, x2, y2 = coord
# 座標にスケーリングを適用
scaled_x1 = x1 * scale_factor
scaled_y1 = y1 * scale_factor
scaled_x2 = x2 * scale_factor
scaled_y2 = y2 * scale_factor
width = scaled_x2 - scaled_x1
height = scaled_y2 - scaled_y1
# 無効なボックスをスキップ
if width <= 0 or height <= 0:
continue
# 可能な場合はボックスの上にラベルを配置
label_top = -18 if scaled_y1 >= 18 else 2
# このバウンディングボックスのユニークID
box_id = f"bbox_{page_id}_{idx}_{bbox_idx}"
# ツールチップの位置を計算(右側を優先するが、必要に応じて左に切り替える)
tooltip_left = 10
overlay = f"""
<div id="{box_id}"
class="bbox-overlay bbox-{container_id}"
style="position: absolute;
left: {scaled_x1:.1f}px; top: {scaled_y1:.1f}px;
width: {width:.1f}px; height: {height:.1f}px;
border: 2px solid {color};
background: {color}25;
box-sizing: border-box;
cursor: pointer;
transition: all 0.2s ease;">
<div style="background: {color}; color: white;
padding: 1px 4px; font-size: 9px; font-weight: bold;
position: absolute; top: {label_top}px; left: 0;
white-space: nowrap; border-radius: 2px;
box-shadow: 0 1px 2px rgba(0,0,0,0.3);
pointer-events: none;
max-width: {max(50, width-4):.0f}px;
overflow: hidden;
z-index: 1000;">
{element_type.upper()[:6]}#{element_id}
</div>
<!-- ツールチップを子要素として(CSSホバーアプローチ) -->
<div class="bbox-tooltip" style="
position: absolute;
left: {tooltip_left}px;
top: {height};
background: rgba(255, 255, 255, 0.98);
color: #333;
border: 2px solid #ccc;
padding: 12px;
border-radius: 6px;
font-size: 12px;
width: {tooltip_width}px;
max-width: {tooltip_width}px;
word-wrap: break-word;
z-index: 10000;
pointer-events: none;
box-shadow: 0 4px 12px rgba(0, 0, 0, 0.15);
display: none;
line-height: 1.4;
max-height: 400px;
overflow-y: auto;">
<div style="font-weight: bold; color: #0066cc; margin-bottom: 8px; padding-bottom: 6px; border-bottom: 1px solid #ddd;">
{element_type.upper()} #{element_id}
</div>
<div style="font-family: 'Segoe UI', 'Helvetica Neue', Arial, sans-serif; font-size: 11px;">
{tooltip_content}
</div>
</div>
</div>
"""
overlays.append(overlay)
# 純粋なCSSホバー機能(Databricksで動作)
styles = f"""
<style>
/* バウンディングボックスのホバー効果 */
.bbox-{container_id}:hover {{
background: rgba(255, 255, 0, 0.3) !important;
border-width: 3px !important;
z-index: 1001 !important;
}}
/* 純粋なCSSを使用してホバー時にツールチップを表示 */
.bbox-{container_id}:hover .bbox-tooltip {{
display: block !important;
}}
/* ツールチップが他の要素の上に表示されるようにする */
.bbox-{container_id} {{
z-index: 100;
}}
.bbox-{container_id}:hover {{
z-index: 9999 !important;
}}
</style>
"""
return f"""
{header_info}
{styles}
<div id="{container_id}" style="position: relative; display: inline-block; border: 2px solid #333; border-radius: 8px; overflow: visible; background: white;">
<img src="{img_data_uri}"
style="display: block; width: {display_width}px; height: {display_height}px;"
alt="ページ {page_id + 1}">
{''.join(overlays)}
</div>
"""
def _create_page_elements_list(self, page_id: int, elements: List[Dict]) -> str:
"""特定のページの要素の詳細リストを作成します。"""
# このページの要素をフィルタリング
page_elements = []
for elem in elements:
elem_bboxes = []
for bbox in elem.get("bbox", []):
if bbox.get("page_id", 0) == page_id:
elem_bboxes.append(bbox)
if elem_bboxes:
page_elements.append(elem)
if not page_elements:
return f"<p>ページ {page_id + 1} に要素が見つかりません</p>"
html_parts = []
for element in page_elements:
element_id = element.get("id", "N/A")
element_type = element.get("type", "unknown")
color = self._get_element_color(element_type)
# このページのためのバウンディングボックス情報を取得
bbox_info = "バウンディングボックスなし"
bbox_list = element.get("bbox", [])
if bbox_list:
bbox_details = []
for bbox in bbox_list:
if bbox.get("page_id", 0) == page_id:
coord = bbox.get("coord", [])
if len(coord) >= 4:
bbox_details.append(
f"[{coord[0]:.0f}, {coord[1]:.0f}, {coord[2]:.0f}, {coord[3]:.0f}]"
)
bbox_info = "; ".join(bbox_details) if bbox_details else "無効なバウンディングボックス"
# 要素リスト表示のために共有コンテンツレンダラーを使用
display_content = self._render_element_content(element, for_tooltip=False)
element_html = f"""
<div style="border-left: 5px solid {color};
padding: 15px; margin: 15px 0;
background: {color}15; border-radius: 5px;">
<div style="display: flex; justify-content: space-between; align-items: flex-start; margin-bottom: 10px;">
<h4 style="margin: 0; color: {color}; font-size: 16px;">
{element_type.upper().replace('_', ' ')} (ID: {element_id})
</h4>
<code style="background: #f5f5f5; padding: 3px 6px; border-radius: 3px; font-size: 10px; max-width: 300px; word-break: break-all;">
{bbox_info}
</code>
</div>
<div style="font-size: 14px; line-height: 1.4;">
{display_content}
</div>
</div>
"""
html_parts.append(element_html)
return f"""
<div style="margin: 20px 0;">
<h3 style="color: #333; margin-bottom: 15px;">📋 ページ {page_id + 1} の要素 ({len(page_elements)} アイテム)</h3>
{''.join(html_parts)}
</div>
"""
def _create_summary(
self, document: Dict, metadata: Dict, selected_pages: Set[int], total_pages: int
) -> str:
"""ページ選択情報を含む要約を作成します。"""
elements = document.get("elements", [])
# 選択されたページの要素のみをカウント
selected_elements = []
for elem in elements:
for bbox in elem.get("bbox", []):
if bbox.get("page_id", 0) in selected_pages:
selected_elements.append(elem)
break
# タイプ別にカウント(選択されたページのため)
type_counts = {}
for elem in selected_elements:
elem_type = elem.get("type", "unknown")
type_counts[elem_type] = type_counts.get(elem_type, 0) + 1
type_list = ", ".join([f"{t}: {c}" for t, c in type_counts.items()])
# ページ選択情報を作成
if len(selected_pages) == total_pages:
page_info = f"すべての {total_pages} ページ"
else:
# 表示のために1ベースに変換
page_nums = sorted([p + 1 for p in selected_pages])
if len(page_nums) <= 10:
page_info = f"ページ {', '.join(map(str, page_nums))} ({len(selected_pages)} of {total_pages})"
else:
page_info = f"{len(selected_pages)} of {total_pages} ページが選択されました"
doc_id = str(metadata.get('id', 'N/A'))
return f"""
<div style="background: #e3f2fd; border: 1px solid #2196f3; border-radius: 8px; padding: 20px;">
<h3 style="margin: 0 0 10px 0; color: #1976d2;">📄 ドキュメント要約</h3>
<p style="margin: 8px 0;"><strong>表示中:</strong> {page_info}</p>
<p style="margin: 8px 0;"><strong>選択されたページの要素:</strong> {len(selected_elements)}</p>
<p style="margin: 8px 0;"><strong>要素タイプ:</strong> {type_list if type_list else 'なし'}</p>
<p style="margin: 8px 0;"><strong>ドキュメントID:</strong> <span style="font-family: monospace; font-size: 0.9em;">{doc_id}</span></p>
</div>
"""
def render_document(
self, parsed_result: Any, page_selection: Union[str, None] = None
) -> None:
"""ページ選択サポートを持つメインレンダリング関数。
引数:
parsed_result: 解析されたドキュメント結果
page_selection: ページ選択文字列。サポートされている形式:
- "all" または None: すべてのページを表示
- "3": ページ 3 のみを表示 (1ベース)
- "1-5": ページ 1 から 5 までを表示 (含む)
- "1,3,5": 特定のページを表示
- "1-3,7,10-12": 混合形式
"""
try:
# 辞書に変換
if hasattr(parsed_result, "toPython"):
parsed_dict = parsed_result.toPython()
elif hasattr(parsed_result, "toJson"):
parsed_dict = json.loads(parsed_result.toJson())
elif isinstance(parsed_result, dict):
parsed_dict = parsed_result
else:
display(
HTML(
f"<p style='color: red;'>❌ 結果を変換できませんでした。タイプ: {type(parsed_result)}</p>"
)
)
return
# コンポーネントを抽出
document = parsed_dict.get("document", {})
pages = document.get("pages", [])
elements = document.get("elements", [])
metadata = parsed_dict.get("metadata", {})
if not elements:
display(
HTML("<p style='color: red;'>❌ ドキュメントに要素が見つかりません</p>")
)
return
# ページ選択を解析
selected_pages = self._parse_page_selection(page_selection, len(pages))
# タイトルを表示
display(HTML("<h1>🔍 AI 解析ドキュメント結果</h1>"))
# 要約HTMLを作成
summary_html = self._create_summary(
document, metadata, selected_pages, len(pages)
)
# カラーレジェンドHTMLを作成
legend_items = []
for elem_type, color in self.element_colors.items():
if elem_type != "default":
legend_items.append(
f"""
<span style="display: inline-block; margin: 5px;">
<span style="display: inline-block; width: 15px; height: 15px;
background: {color}; border: 1px solid #999; margin-right: 5px;"></span>
{elem_type.replace('_', ' ').title()}
</span>
"""
)
legend_html = f"""
<div style="background: #f9f9f9; padding: 20px; border-radius: 8px; border: 1px solid #ddd;">
<strong>🎨 要素の色:</strong><br>
{''.join(legend_items)}
</div>
"""
# 要約とレジェンドを横に表示
combined_html = f"""
<div style="display: grid; grid-template-columns: 1fr 1fr; gap: 15px; margin: 15px 0;">
{summary_html}
{legend_html}
</div>
"""
display(HTML(combined_html))
# 選択された要素で注釈付き画像を表示
if pages:
display(HTML("<h2>�️ 注釈付き画像と要素</h2>"))
# 表示のために選択されたページをソート
sorted_selected = sorted(selected_pages)
for page_idx in sorted_selected:
if page_idx < len(pages):
page = pages[page_idx]
# 注釈付き画像を表示
annotated_html = self._create_annotated_image(page, elements)
display(
HTML(f"<div style='margin: 20px 0;'>{annotated_html}</div>")
)
# 画像のすぐ後にこのページの要素を表示
page_id = page.get("id", page_idx)
page_elements_html = self._create_page_elements_list(
page_id, elements
)
display(HTML(page_elements_html))
except Exception as e:
display(HTML(f"<p style='color: red;'>❌ エラー: {str(e)}</p>"))
import traceback
display(HTML(f"<pre>{traceback.format_exc()}</pre>"))
# 簡単な使用関数
def render_ai_parse_output(parsed_result, page_selection=None):
"""ページ選択を持つai_parse_document出力をレンダリングする簡単な関数。
引数:
parsed_result: 解析されたドキュメント結果
page_selection: オプションのページ選択文字列。例:
- None または "all": すべてのページを表示
- "3": ページ 3 のみを表示
- "1-5": ページ 1 から 5 までを表示
- "1,3,5": 特定のページを表示
- "1-3,7,10-12": 混合形式
"""
renderer = DocumentRenderer()
renderer.render_document(parsed_result, page_selection)
def render_ai_parse_output_interactive(parsed_results):
"""ページナビゲーションボタン、スライダー、ドロップダウンを持つインタラクティブレンダラー。
引数:
parsed_results: 単一の解析されたドキュメント結果または解析結果のリスト
"""
try:
import ipywidgets as widgets
from IPython.display import clear_output
except ImportError:
display(
HTML(
"<p style='color: red;'>❌ ipywidgetsがインストールされていません。インストールするには: pip install ipywidgets</p>"
)
)
return
# 結果のリストを処理
if isinstance(parsed_results, list):
# 成功した結果とエラー結果を分ける
successful = []
errors = []
for idx, result in enumerate(parsed_results):
# 最初に辞書に変換
if hasattr(result, "toPython"):
result_dict = result.toPython()
elif hasattr(result, "toJson"):
result_dict = json.loads(result.toJson())
elif isinstance(result, dict):
result_dict = result
else:
errors.append((idx, f"未知のタイプ: {type(result)}"))
continue
# エラーかどうかを確認
if result_dict.get('type') == 'error':
errors.append((idx, result_dict.get('message', result_dict.get('error', '未知のエラー'))))
else:
successful.append((idx, result))
# 要約を表示
display(HTML(f"""
<div style='background: #f0f0f0; padding: 15px; border-radius: 5px; margin: 10px 0;'>
<strong>📊 バッチ結果:</strong> {len(successful)} 成功, {len(errors)} エラー
</div>
"""))
# エラーがあれば表示
if errors:
error_html = "<div style='background: #fff3cd; border: 1px solid #ffc107; padding: 10px; margin: 10px 0; border-radius: 5px;'>"
error_html += "<strong>⚠️ エラーが発生しました:</strong><ul>"
for idx, err_msg in errors:
error_html += f"<li>ドキュメント {idx}: {err_msg}</li>"
error_html += "</ul></div>"
display(HTML(error_html))
if not successful:
display(HTML("<p style='color: red;'>❌ 表示する成功した結果がありません</p>"))
return
# 複数のドキュメント - ドキュメントセレクタを作成
has_multiple_docs = len(successful) > 1
successful_docs = successful # 後で使用するために保存
else:
has_multiple_docs = False
successful_docs = [(0, parsed_results)]
# 出力エリアとドキュメントドロップダウン(必要に応じて)
output_area = widgets.Output()
if has_multiple_docs:
doc_dropdown = widgets.Dropdown(
options=[(f"ドキュメント {idx}", idx) for idx, _ in successful_docs],
value=successful_docs[0][0],
description="ドキュメント:",
style={"description_width": "70px"},
layout=widgets.Layout(width="200px"),
)
doc_label = widgets.Label(value=f"1 of {len(successful_docs)} ドキュメント")
# 現在の状態を保存
current_state = {"doc_idx": successful_docs[0][0], "page_num": 1}
def get_current_document():
"""現在選択されているドキュメントとそのページを取得します。"""
for idx, doc in successful_docs:
if idx == current_state["doc_idx"]:
# 辞書に変換
if hasattr(doc, "toPython"):
parsed_dict = doc.toPython()
elif hasattr(doc, "toJson"):
parsed_dict = json.loads(doc.toJson())
elif isinstance(doc, dict):
parsed_dict = doc
else:
return None, []
document = parsed_dict.get("document", {})
pages = document.get("pages", [])
return doc, pages
return None, []
# 初期ドキュメントとページを取得
parsed_result, pages = get_current_document()
if not pages:
display(HTML("<p style='color: red;'>❌ ページが見つかりません</p>"))
return
# ページナビゲーションウィジェットを作成
prev_button = widgets.Button(
description="◀ 前へ",
disabled=True,
button_style="primary",
layout=widgets.Layout(width="120px"),
)
next_button = widgets.Button(
description="次 ▶",
disabled=False if len(pages) > 1 else True,
button_style="primary",
layout=widgets.Layout(width="120px"),
)
page_dropdown = widgets.Dropdown(
options=[(f"ページ {i+1}", i + 1) for i in range(len(pages))],
value=1,
description="移動:",
style={"description_width": "50px"},
layout=widgets.Layout(width="150px"),
)
page_slider = widgets.IntSlider(
value=1,
min=1,
max=len(pages),
step=1,
description="",
continuous_update=False,
layout=widgets.Layout(width="300px"),
)
page_label = widgets.Label(value=f"ページ 1 of {len(pages)}")
def update_page_controls(pages):
"""ドキュメントが変更されたときにページコントロールを更新します。"""
page_dropdown.options = [(f"ページ {i+1}", i + 1) for i in range(len(pages))]
page_slider.max = len(pages)
page_slider.value = 1
page_dropdown.value = 1
current_state["page_num"] = 1
def update_page(page_num):
"""特定のページに更新し、すべてのコントロールを更新します。"""
current_state["page_num"] = page_num
# 現在のドキュメントを取得
parsed_result, pages = get_current_document()
# すべてのウィジェットを更新
page_slider.value = page_num
page_dropdown.value = page_num
page_label.value = f"ページ {page_num} of {len(pages)}"
# ボタンの状態を更新
prev_button.disabled = page_num == 1
next_button.disabled = page_num == len(pages)
# ページをレンダリング
with output_area:
clear_output(wait=True)
renderer = DocumentRenderer()
renderer.render_document(parsed_result, page_selection=str(page_num))
def on_prev_click(_):
if current_state["page_num"] > 1:
update_page(current_state["page_num"] - 1)
def on_next_click(_):
_, pages = get_current_document()
if current_state["page_num"] < len(pages):
update_page(current_state["page_num"] + 1)
def on_slider_change(change):
update_page(change["new"])
def on_page_dropdown_change(change):
update_page(change["new"])
def on_doc_dropdown_change(change):
"""ドキュメント選択の変更を処理します。"""
current_state["doc_idx"] = change["new"]
# 新しいドキュメントのページを取得
_, pages = get_current_document()
# 新しいドキュメントのためにページコントロールを更新
update_page_controls(pages)
# ドキュメントラベルを更新
if has_multiple_docs:
doc_idx_position = next(i for i, (idx, _) in enumerate(successful_docs) if idx == change["new"])
doc_label.value = f"{doc_idx_position + 1} of {len(successful_docs)} ドキュメント"
# 新しいドキュメントの最初のページをレンダリング
update_page(1)
# イベントハンドラを接続
prev_button.on_click(on_prev_click)
next_button.on_click(on_next_click)
page_slider.observe(on_slider_change, names="value")
page_dropdown.observe(on_page_dropdown_change, names="value")
if has_multiple_docs:
doc_dropdown.observe(on_doc_dropdown_change, names="value")
# レイアウト
if has_multiple_docs:
# ドキュメント行: [ドキュメントドロップダウン] [ラベル]
doc_row = widgets.HBox(
[
doc_dropdown,
doc_label,
],
layout=widgets.Layout(margin="0 0 10px 0")
)
# ページナビゲーション行: [前へ] [スライダー] [次] | [ドロップダウン] [ラベル]
page_nav_row = widgets.HBox(
[
prev_button,
page_slider,
next_button,
widgets.Label(value=" "), # スペーサー
page_dropdown,
page_label,
]
)
# ドキュメントセレクタの上にウィジェットを表示
display(widgets.VBox([doc_row, page_nav_row, output_area]))
else:
# ページナビゲーションのみ: [前へ] [スライダー] [次] | [ドロップダウン] [ラベル]
nav_row = widgets.HBox(
[
prev_button,
page_slider,
next_button,
widgets.Label(value=" "), # スペーサー
page_dropdown,
page_label,
]
)
# ウィジェットを表示
display(widgets.VBox([nav_row, output_area]))
# 初期レンダリングをトリガー
update_page(1)
デバッグの可視化結果
# デバッグ可視化結果
render_ai_parse_output_interactive(parsed_results)
以下のようにドキュメントがどのようにパースされたのかが可視化されます。
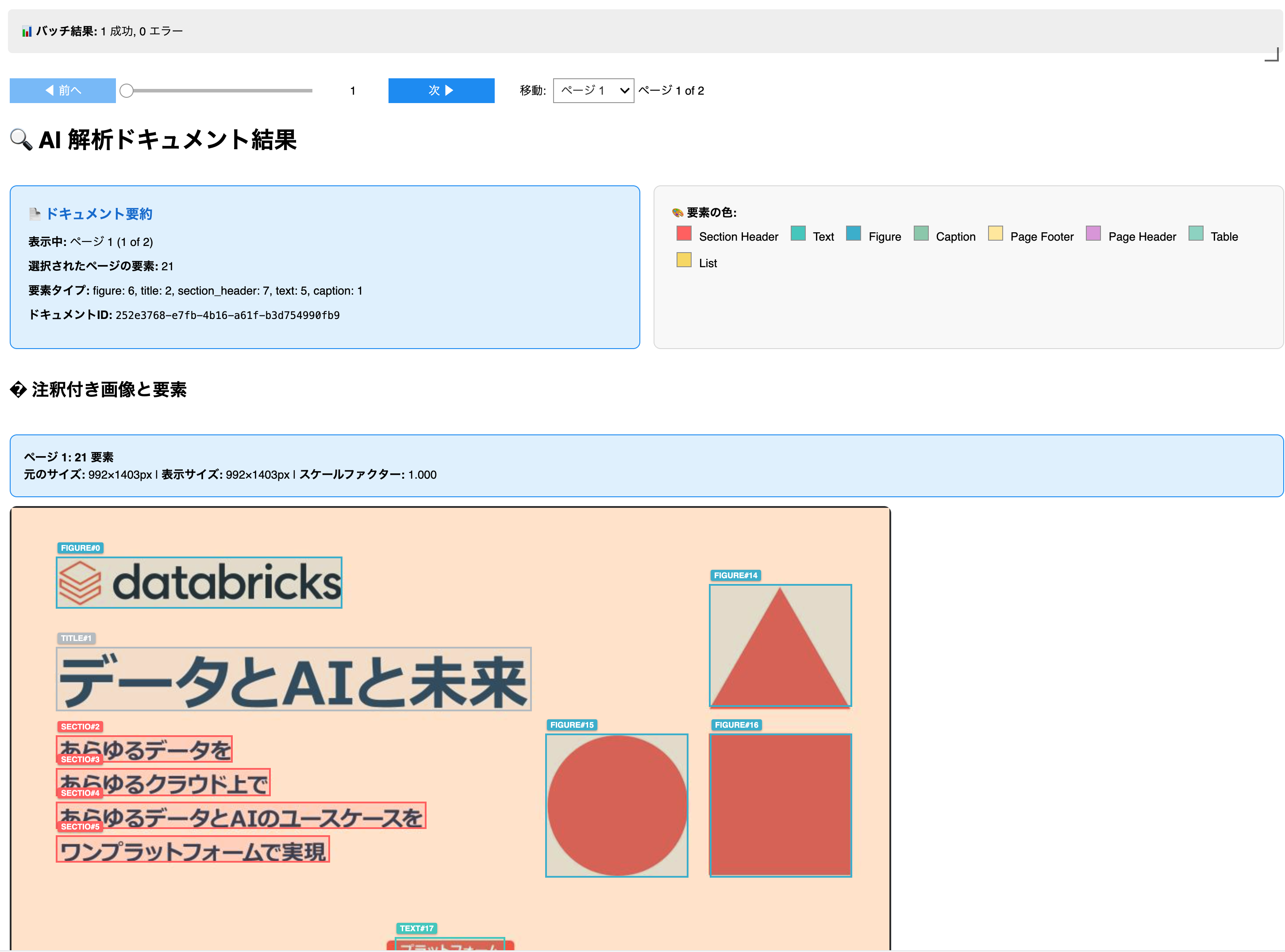

ボックスにマウスをホバーするとパース結果を確認できます。

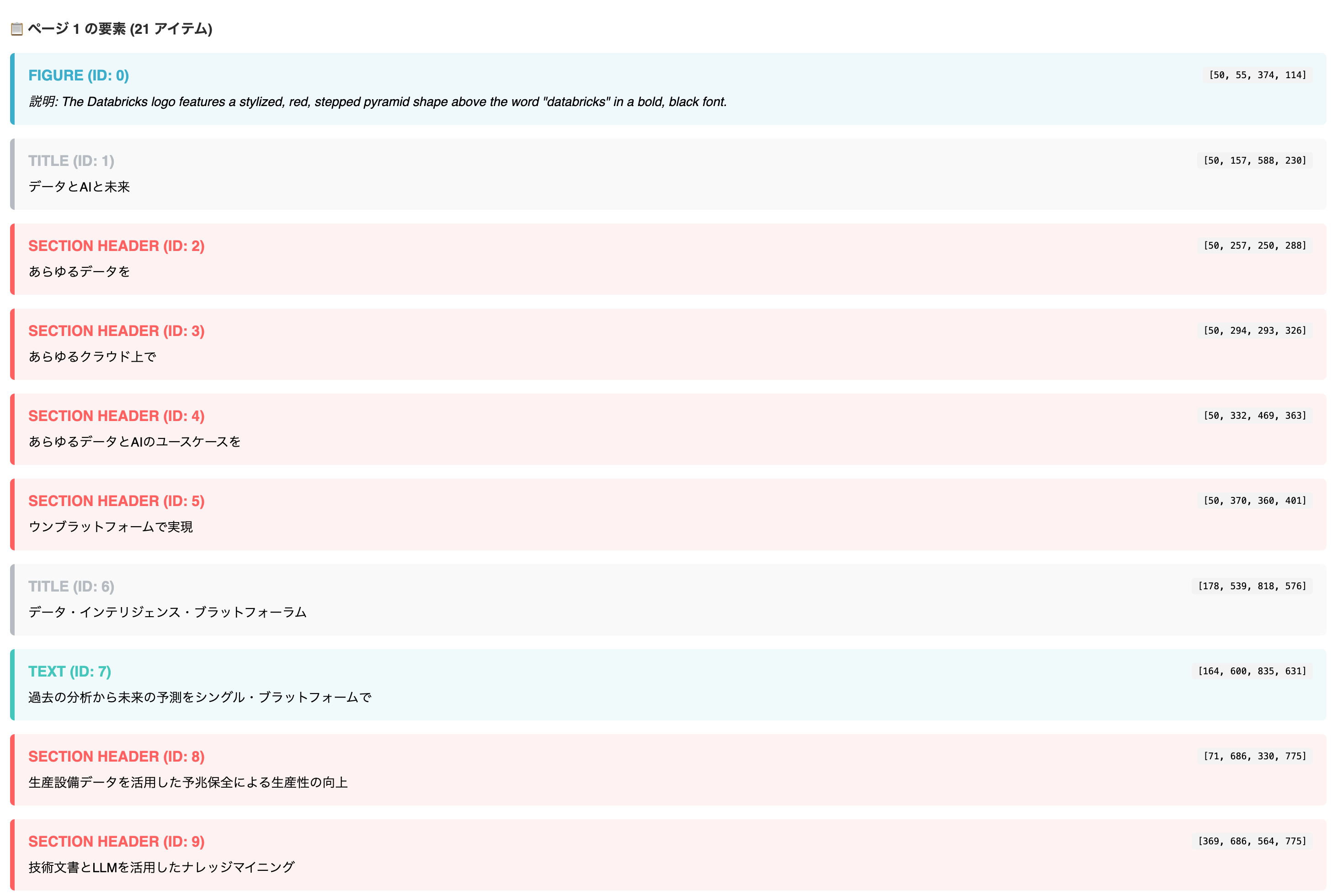
一覧でも確認できます。
ご活用ください!