データサイエンティストの皆さん、こーんにちはー!
巷ではChatGPTのおかげで益々AIの注目度が上がっていますね。ただ、AIを使って業務を効率化しよう、というのはずいぶん前から言われている気がしますが、実際に社内全体にAI活用を浸透させることはなかなか難しいですよね。
(手前味噌で恐縮ですが、、、)社内でAI活用を促進する方法として、データサイエンティストの皆様が作成したAIモデルをRPAユーザーに使ってもらう、というやり方があります。(RPAがどれだけ素晴らしい技術であるかはここでは割愛します笑)
え、pythonの実行環境を整えたりしないといけないからそんな簡単にできないって?
そんなことはありません!UiPath AI Centerなら簡単にできるんです!
そもそもUiPath AI Centerってなに?
詳細はこちらをご参照いただくかUiPathまでお問合せいただければと思いますが、簡単に言うと、UiPathのRPAで利用できるAIモデルを一元管理できるクラウド製品です。(厳密にはオンプレミス向けのご用意もあります。)
つまり、このAI Centerに皆様が開発したAIモデルをアップロードすることで、社内全員のRPAユーザーがAIの恩恵を受けることができるのです!!
なお、OOTB(Out of the Box)パッケージという開発不要ですぐに使えるAIモデル群もあるので、データサイエンティストがいないお客様にもご利用いただける製品です。
でもAI Centerの使い方わからないし…
すみません、この記事の範囲外なので説明は割愛します…
以下の動画や記事をご参照ください![]()
![]()
https://www.youtube.com/watch?v=Cpa3HHX9CAQ
https://www.uipath.com/ja/community-blog/tutorials/ai-center
本題
それでは、実際にどうやってAIモデルをアップロードするか説明してきます。
今回は以下の手順で実施します。
- AIモデルの作成
- AI Centerへのアップロードファイル(zipファイル)の作成
- AI Centerへのアップロードとデプロイ
1. AIモデルの作成
AIモデルの作成はscikit-learnが使えるpython環境なら何でもよいのですが、今回は手軽に実施するためGoogleのColaboratoryを利用します。
今回サンプルとして作成するAIモデルはみんな大好き「タイタニックの生存者予測」です!
今回作るモデルはKaggleのチュートリアルから引用します。
データはこちらよりtrain.csvをダウンロードしてください。

ファイルをダウンロードできたら、Colaboratoryでノートブックを新規作成します。

ノートブックを開いたら、ノートブックのフォルダーにtrain.csvをアップロードします。(ドラッグ&ドロップでアップロードできます。)
以下のpythonコードを上記のノートブックに転記・実行します。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import joblib
# train.csvをpandasのDataFrameに読み込み
data = pd.read_csv('train.csv')
# トレーニングデータとテストデータに分割
# テストデータは後でUiPath Studio内で利用する
train, test = train_test_split(data, test_size=0.33, random_state=42)
# トレーニングデータ用のデータフレームを作成
# 学習対象の特徴量はkaggleのチュートリアルより引用
X = train[["Pclass", "Sex", "SibSp", "Parch"]]
X = pd.get_dummies(X)
y = train["Survived"]
# モデルの作成と学習
# 利用するモデル(ランダムフォレスト)はkaggleのチュートリアルより引用
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
# 学習済モデルをsavファイルに出力
# このファイルがAI Centerにアップロードするzipファイルの一部となる(AI Center用pyファイルで読み込む)
joblib.dump(model, "titanic_model.sav")
# 検証用のテストデータをcsvに出力
# このcsvは後でUiPath Studio内で利用する
test_input = test[["Pclass", "Sex", "SibSp", "Parch"]]
test_input = pd.get_dummies(test_input)
test_input.to_csv('titanic_test_input.csv')
# UiPath Studioでの予測結果を検証するために利用
test.to_csv('titanic_test_answer.csv')
コードの実行が終わったら、ノートブックのフォルダーから以下ファイルをダウンロードします。
- titanic_model.sav
- titanic_test_input.csv
- titanic_test_answer.csv

2. AI Centerへのアップロードファイル(zipファイル)の作成
これでモデルが完成したので、次にAI Centerにアップロードするためのzipファイルを作成します。
詳細はこちらの公式ドキュメントを参照してください。
AI Centerではトレーニングしないモデルと再トレーニング可能なモデルの2パターンをアップロードすることができます。今回は簡単な説明とするため、トレーニングしないモデルを作ります。
トレーニングしないモデルのzipファイルのフォルダー構成は以下です。
titanic_model/ # フォルダー名(のちのzipファイル名)は任意
- titanic_model.sav # 実際に値の予測を行うモデル。main.pyから呼び出す(名前は任意)
- main.py # RobotがMLスキルを呼び出したときに(AI Centerが)実行するpyファイル。この中で上記のモデルを呼び出す
- requirements.txt # main.pyの実行に必要なpythonの依存関係を記述する
上記のzipファイルを構成するmain.pyとrequirements.txtを以下の通り作成します。
import joblib
import json
import pandas as pd
import io
class Main(object):
def __init__(self):
self.model = joblib.load('titanic_model.sav')
def predict(self, X):
X = io.BytesIO(X)
inputdata = pd.read_csv(X)
result = self.model.predict(inputdata)
return json.dumps(result.tolist())
scikit-learn==1.2.2
pandas==1.5.3
requirements.txtに記載のバージョンは一例です。
ここまで終わったら、titanic_modelフォルダーをzipに圧縮しておきます。
3. AI Centerへのアップロードとデプロイ
いよいよ、UiPath AI Centerに作成したAIモデルをアップロードします!
それでは、AI Centerを開いてください。

プロジェクトを作成します。

プロジェクト名をつけて作成してください。プロジェクト名は何でもいいですが、ここではTitanic_LeoSamaWaTasukarunokaとしておきましょう。

プロジェクトを作成したら、MLパッケージよりzipファイルをアップロードします。


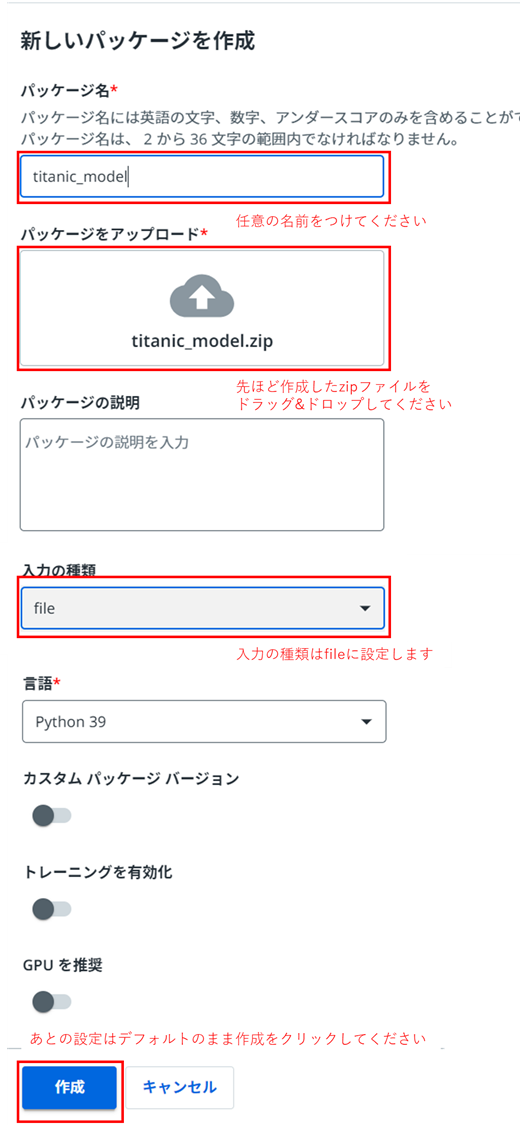
アップロード後、ステータスが「未デプロイ」になるまで待ちます。

次に、アップロードしたMLパッケージをMLスキルとしてデプロイします。



ステータスが利用可能になるまで待ちます。
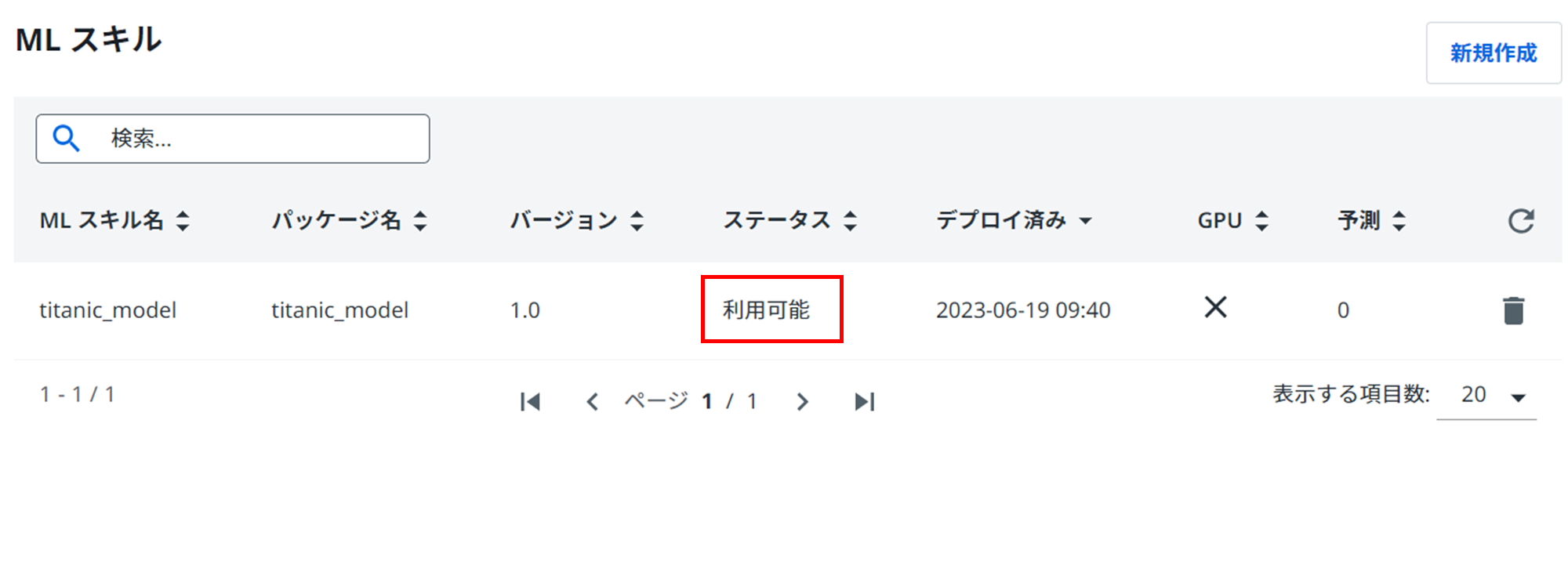
みなさんお疲れさまでした。ここまでの作業で自作したAIモデルをUiPath AI Centerにアップロードすることができました!
次回は今回アップロードしたAIモデルをUiPath Studioで利用する方法をご説明します。