#この記事について
あまり世間にレコメンドに関してサンプルデータを使って実装したチュートリアルが無かったので記事を書きました。
レコメンデーションを作成する手法は機械学習などを使った手法などがありますが、これは統計よりの手法を使ったレコメンデーション作成方法の記事です。
pythonとオープンデータセットを用いて説明をしていきます。
こちらはpythonによる実装の記事です。レコメンドの概念については以下の記事をどうぞ。
アソシエーション分析を活用したレコメンデーションのチュートリアル(概念編)
概念編の記事の流れに沿っての実装になります。
こちらの実装を環境構築無しで試したい場合
有料ですが、こちらでGoogle Colaboratoryの実行環境を用意しております。
必要なライブラリのインポート
必要なライブラリのインポートを行います。
#ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
データセットの読み込み
今回のチュートリアルで用いるデータセットを読み込みます。
こちらはgithubのリポジトリからデータセットを読み込んでいます。
※ちなみにGoogle Colaboratoryでの実行を前提としています。
#データセットの読み込み
import urllib.request
from io import StringIO
url = "https://raw.githubusercontent.com/tachiken0210/dataset/master/dataset_cart.csv"
#csvを読み込む関数
def read_csv(url):
res = urllib.request.urlopen(url)
res = res.read().decode("utf-8")
df = pd.read_csv(StringIO( res) )
return df
#実行
df_cart_ori = read_csv(url)
データセットの中身の確認
今回用いるデータセットの内容を確認します。
df_cart_ori.head()
| cart_id | goods_id | action | create_at | update_at | last_update | time | |
|---|---|---|---|---|---|---|---|
| 0 | 108750017 | 583266 | UPD | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 1385478215 |
| 1 | 108750017 | 662680 | UPD | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 1385478215 |
| 2 | 108750017 | 664077 | UPD | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 2013-11-26 03:11:06 | 1385478215 |
| 3 | 108199875 | 661648 | ADD | 2013-11-26 03:11:10 | 2013-11-26 03:11:10 | 2013-11-26 03:11:10 | 1385478215 |
| 4 | 105031004 | 661231 | ADD | 2013-11-26 03:11:41 | 2013-11-26 03:11:41 | 2013-11-26 03:11:41 | 1385478215 |
###本チュートリアルで使用するデータセットについて
このデータセットはとあるECサイトでの顧客がカートに商品を入れたりした時のログデータになります。
※一般的にはトランザクションデータと呼ばれます。
それぞれのカラム名(列名)の内容は以下の通りです。
・card_id:顧客に紐づけられるカートのID(顧客IDと考えても大丈夫ですので、以下顧客と呼びます)
・goods_id:商品ID
・action:顧客の行動(ADD:カートに追加、DEL:カートから消去、など)
・create_at:ログが作成された時間
・update_at:ログが更新された時間(今回は使用しません)
・last_update:ログが更新された時間(今回は使用しません)
・time:タイムスタンプ
また、今回使うデータセットも含め一般的なオープンデータセットは商品名などの具体名がデータセットに含まれていることはほとんどなく、基本的に商品のIDで表現されます。
よって実際どんな商品であるかはわかりづらいのですが、こちらはデータの内容上ご了承ください。
次に、少しこのデータの中身を眺めてみることにします。
このデータセットには全ての顧客のデータが時系列のログとして含まれていますので、1人の顧客のみに注目してみます。
まずデータの中でもっともログ数の多い顧客を抽出してみます。
df_cart_ori["cart_id"].value_counts().head()
#出力
110728794 475
106932411 426
115973611 264
109269739 205
112332751 197
Name: cart_id, dtype: int64
110728794のユーザーが475つのログが存在し、もっともログ数が多いようです。
この顧客のログを抜き出してみます。
df_cart_ori[df_cart_ori["cart_id"]==110728794].head(10)
| cart_id | goods_id | action | create_at | update_at | last_update | time | |
|---|---|---|---|---|---|---|---|
| 32580 | 110728794 | 664457 | ADD | 2013-11-26 22:54:13 | 2013-11-26 22:54:13 | 2013-11-26 22:54:13 | 1385478215 |
| 32619 | 110728794 | 664885 | ADD | 2013-11-26 22:55:09 | 2013-11-26 22:55:09 | 2013-11-26 22:55:09 | 1385478215 |
| 33047 | 110728794 | 664937 | ADD | 2013-11-26 22:58:52 | 2013-11-26 22:58:52 | 2013-11-26 22:58:52 | 1385478215 |
| 33095 | 110728794 | 664701 | ADD | 2013-11-26 23:00:25 | 2013-11-26 23:00:25 | 2013-11-26 23:00:25 | 1385478215 |
| 34367 | 110728794 | 665050 | ADD | 2013-11-26 23:02:40 | 2013-11-26 23:02:40 | 2013-11-26 23:02:40 | 1385478215 |
| 34456 | 110728794 | 664989 | ADD | 2013-11-26 23:05:03 | 2013-11-26 23:05:03 | 2013-11-26 23:05:03 | 1385478215 |
| 34653 | 110728794 | 664995 | ADD | 2013-11-26 23:07:00 | 2013-11-26 23:07:00 | 2013-11-26 23:07:00 | 1385478215 |
| 34741 | 110728794 | 664961 | ADD | 2013-11-26 23:09:41 | 2013-11-26 23:09:41 | 2013-11-26 23:09:41 | 1385478215 |
| 296473 | 110728794 | 665412 | DEL | 2013-12-03 17:17:30 | 2013-12-03 17:17:30 | 2013-12-03 07:41:13 | 1386083014 |
| 296476 | 110728794 | 665480 | DEL | 2013-12-03 17:17:37 | 2013-12-03 17:17:37 | 2013-12-03 07:42:29 | 1386083014 |
この顧客を見ると、1日の中で連続的にカートを商品に入れているのがわかります。
これを同様に他の顧客に対して分析すると、『全般的にある商品xの次には商品yがカートに入れられやすい』というのが見えてきそうです。
このように**『ある商品xの次には商品yがカートに入れられやすい』というパターンをこのデータセットから分析することが、今回の目的になります。**
次から実際にデータを処理していきますが、以上を頭の片隅におきながら進めます。
データの前処理
ここから、データの前処理を行なっていきます。
まず、"action"の列に注目すると、ADDやDELなど様々なものがあります。こちらは、ひとまずADD(カートに加えた)というログのみに絞ることにします。
顧客の商品需要にのみに注目するということですね。
df = df_cart_ori.copy()
df = df[df["action"]=="ADD"]
df.head()
| cart_id | goods_id | action | create_at | update_at | last_update | time | |
|---|---|---|---|---|---|---|---|
| 3 | 108199875 | 661648 | ADD | 2013-11-26 03:11:10 | 2013-11-26 03:11:10 | 2013-11-26 03:11:10 | 1385478215 |
| 4 | 105031004 | 661231 | ADD | 2013-11-26 03:11:41 | 2013-11-26 03:11:41 | 2013-11-26 03:11:41 | 1385478215 |
| 6 | 110388732 | 661534 | ADD | 2013-11-26 03:11:55 | 2013-11-26 03:11:55 | 2013-11-26 03:11:55 | 1385478215 |
| 7 | 110388740 | 662336 | ADD | 2013-11-26 03:11:58 | 2013-11-26 03:11:58 | 2013-11-26 03:11:58 | 1385478215 |
| 8 | 110293997 | 661648 | ADD | 2013-11-26 03:12:13 | 2013-11-26 03:12:13 | 2013-11-26 03:12:13 | 1385478215 |
続いて、顧客ごとに商品をカートに入れた順番を時系列にするために、データセットのソートを行います。
df = df[["cart_id","goods_id","create_at"]]
df = df.sort_values(["cart_id","create_at"],ascending=[True,True])
df.head()
| cart_id | goods_id | create_at | |
|---|---|---|---|
| 548166 | 78496306 | 661142 | 2013-11-15 23:07:02 |
| 517601 | 79100564 | 662760 | 2013-11-24 18:17:24 |
| 517404 | 79100564 | 661093 | 2013-11-24 18:25:29 |
| 23762 | 79100564 | 664856 | 2013-11-26 13:41:47 |
| 22308 | 79100564 | 562296 | 2013-11-26 13:44:20 |
ここからの処理は、アソシエーション分析のライブラリに合うようにデータを整形していきます。
顧客ごとに、カートに入れた商品を順にリストに入れていきます。
df = df[["cart_id","goods_id"]]
df["goods_id"] = df["goods_id"].astype(int).astype(str)
df = df.groupby(["cart_id"])["goods_id"].apply(lambda x:list(x)).reset_index()
df.head()
| cart_id | goods_id | |
|---|---|---|
| 0 | 78496306 | ['661142'] |
| 1 | 79100564 | ['662760', '661093', '664856', '562296', '663364', '664963', '664475', '583266'] |
| 2 | 79455669 | ['663801', '664136', '664937', '663932', '538673', '663902', '667859'] |
| 3 | 81390353 | ['663132', '661725', '664236', '663331', '659679', '663847', '662340', '662292', '664099', '664165', '663581', '665426', '663899', '663405'] |
| 4 | 81932021 | ['662282', '664218'] |
続いて、上のデータフレームの中身確認しましょう。
2行目の顧客(79100564)に注目してください。
まず1つ目の商品663801の後に664136をカートに入れています。つまりX="663801"、Y="664136"になります。<
また、664136の後には664937をカートに入れています。これらに関してはX="664136"、Y="664937"になります。
このように、顧客ごとにこのXYのペアを並べればアソシエーション分析を行うことが可能になります。
それではこのXYが対になるようにデータを整形していきましょう。
def get_combination(l):
length = len(l)
list_output = []
list_pair = []
for i in range(length-1):
if l[i]==l[i+1]:
pass
else:
list_pair =[l[i],l[i+1]]
list_output.append(list_pair)
return list_output
df["comb_goods_id"] = df["goods_id"].apply(lambda x:get_combination(x))
#アソシエーション入力のリストを作る
dataset= []
for i,contents in enumerate(df["comb_goods_id"].values):
for c in contents:
dataset.append(c)
print("XYのペアの数は",len(dataset))
print("XYのペアの中身",dataset[:5])
#出力
XYのペアの数は 141956
XYのペアの中身 [['662760', '661093'], ['661093', '664856'], ['664856', '562296'], ['562296', '663364'], ['663364', '664963']]
アソシエーション分析の実行
以上を入力としてアソシエーション分析にかけます。
アソシエーション分析をしてくれるメソッドをassociationメソッドとして作成してあるので、これを利用します。
#アソシエーションライブラリ
def association(dataset):
df = pd.DataFrame(dataset,columns=["x","y"])
num_dataset = df.shape[0]
df["sum_count_xy"]=1
print("calculating support....")
df_a_support = (df.groupby("x").sum()/num_dataset).rename(columns={"sum_count_xy":"support_x"})
df_b_support = (df.groupby("y").sum()/num_dataset).rename(columns={"sum_count_xy":"support_y"})
df = df.groupby(["x","y"]).sum()
df["support_xy"]=df["sum_count_xy"]/num_dataset
df = df.reset_index()
df = pd.merge(df,df_a_support,on="x")
df = pd.merge(df,df_b_support,on="y")
print("calculating confidence....")
df_temp = df.groupby("x").sum()[["sum_count_xy"]].rename(columns={"sum_count_xy":"sum_count_x"})
df = pd.merge(df,df_temp,on="x")
df_temp = df.groupby("y").sum()[["sum_count_xy"]].rename(columns={"sum_count_xy":"sum_count_y"})
df = pd.merge(df,df_temp,on="y")
df["confidence"]=df["sum_count_xy"]/df["sum_count_x"]
print("calculating lift....")
df["lift"]=df["confidence"]/df["support_y"]
df["sum_count"] = num_dataset
df_output = df
return df_output
#データセットをアソシエーション分析にかける
df_output = association(dataset)
df_output.head()
| x | y | sum_count_xy | support_xy | support_x | support_y | sum_count_x | sum_count_y | confidence | lift | sum_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 485836 | 662615 | 1 | 7.04444e-06 | 7.04444e-06 | 0.000147933 | 1 | 21 | 1 | 6759.81 | 141956 |
| 1 | 549376 | 662615 | 1 | 7.04444e-06 | 2.11333e-05 | 0.000147933 | 3 | 21 | 0.333333 | 2253.27 | 141956 |
| 2 | 654700 | 662615 | 1 | 7.04444e-06 | 0.000464933 | 0.000147933 | 66 | 21 | 0.0151515 | 102.421 | 141956 |
| 3 | 661475 | 662615 | 1 | 7.04444e-06 | 0.000965088 | 0.000147933 | 137 | 21 | 0.00729927 | 49.3417 | 141956 |
| 4 | 661558 | 662615 | 1 | 7.04444e-06 | 0.000408577 | 0.000147933 | 58 | 21 | 0.0172414 | 116.548 | 141956 |
結果が出ました。
それぞれの列の内容は以下になります
・x:条件部X
・y:結論部Y
・sum_count_xy:XYに当てはまるデータ数
・support_xy:XYの支持度
・support_x:Xの支持度
・support_y:Yの支持度
・sum_count_x:Xに当てはまるデータ数
・sum_count_y:Yに当てはまるデータ数
・confidence:確信度
・lift:リフト
##アソシエーション結果の後処理
さて、以上でアソシエーションの実行は終わりましたが1つ注意点があります。
基本的にはliftの値が高いものは関連性が高いと見えるのですが、そのデータ数が少ないとそれが偶然に起こっただけかもしれない疑いがあります。
例えば一番上の行をみてください。 x="485836", y="662615"の部分です。
これはliftの値は6760ととても高いですが、これが起こった数はたった1回(=support_xy)です。1回という数字はデータ数が十分だと仮定すると、これが偶然で起こった可能性が高いと見なせます。
それでは、偶然or偶然ではないを判断するsupport_xyの閾値はどうやって導くのでしょうか?
。。。実際は、その閾値を導くのは難しいです。(正解はありません)
ここでは、一旦support_xyのヒストグラムを確認してみます。
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.hist(df_output["sum_count_xy"], bins=100)
ax.set_title('')
ax.set_xlabel('xy')
ax.set_ylabel('freq')
#見辛いのでy軸の範囲を限定します
ax.set_ylim(0,500)
fig.show()
support_xyのヒストグラム
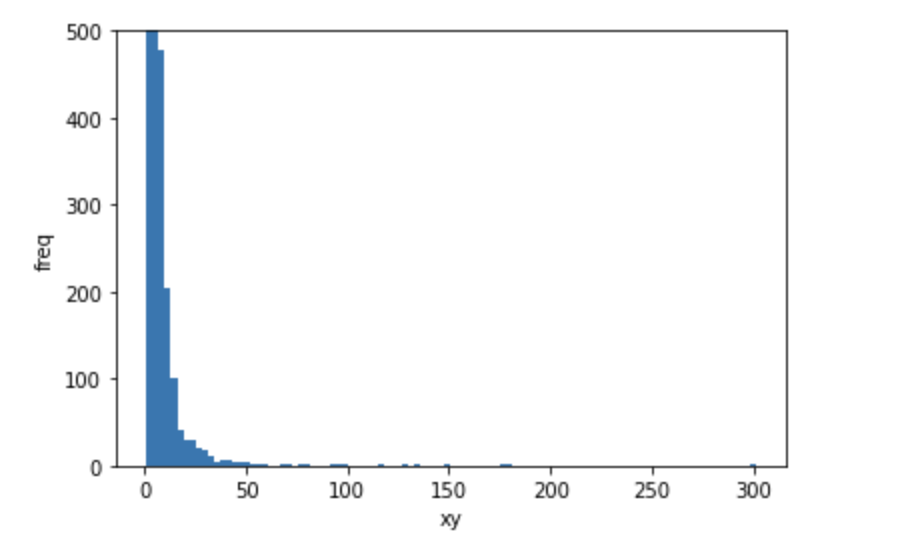
殆どのデータがx軸のsupport_xyが0付近に集中していることが分かります。
このチュートリアルではこの0付近のデータは全て偶然とみなし、削除することにします。
閾値の設定では分位数を利用し、下位98パーセントのデータは偶然とみなせるよう閾値を設定します。
※分位点については以下のリンクを参考になさってください。
https://ja.wikipedia.org/wiki/%E5%88%86%E4%BD%8D%E6%95%B0
df = df_output.copy()
df = df[df["support_xy"]>=df["support_xy"].quantile(0.98)]
df.head()
| x | y | sum_count_xy | support_xy | support_x | support_y | sum_count_x | sum_count_y | confidence | lift | sum_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 58 | 662193 | 667129 | 8 | 5.63555e-05 | 0.0036138 | 0.00281073 | 513 | 399 | 0.0155945 | 5.54822 | 141956 |
| 59 | 665672 | 667129 | 12 | 8.45332e-05 | 0.00395193 | 0.00281073 | 561 | 399 | 0.0213904 | 7.61026 | 141956 |
| 60 | 666435 | 667129 | 30 | 0.000211333 | 0.0082279 | 0.00281073 | 1168 | 399 | 0.0256849 | 9.13817 | 141956 |
| 62 | 666590 | 667129 | 7 | 4.93111e-05 | 0.00421257 | 0.00281073 | 598 | 399 | 0.0117057 | 4.16464 | 141956 |
| 63 | 666856 | 667129 | 8 | 5.63555e-05 | 0.00390966 | 0.00281073 | 555 | 399 | 0.0144144 | 5.12835 | 141956 |
これで偶然起こったと思われるxyのペアのデータを省くことができました。
続いて最後の処理、xに関連性の高いyのみを残します。これは先ほど説明した通り、liftの値が高いxyペアのみ残せば良いことになります。
ここではliftが2.0以上のペアのみ残すことにします。
ちなみにlift(リフト値)の意味のイメージですが、xの商品がカートに入れられた際にyの商品が他の商品に比べどれだけカートに入れられやすいかを示す値です。
例えば上のデータフレームの中身でいうと、"662193"(x)という商品がカートに入れられた際にその次に”"667129"(y)という商品は5.5倍カートに入れられやすいということになります。
df = df[df["lift"]>=2.0]
df_recommendation = df.copy()
df_recommendation.head()
| x | y | sum_count_xy | support_xy | support_x | support_y | sum_count_x | sum_count_y | confidence | lift | sum_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 58 | 662193 | 667129 | 8 | 5.63555e-05 | 0.0036138 | 0.00281073 | 513 | 399 | 0.0155945 | 5.54822 | 141956 |
| 59 | 665672 | 667129 | 12 | 8.45332e-05 | 0.00395193 | 0.00281073 | 561 | 399 | 0.0213904 | 7.61026 | 141956 |
| 60 | 666435 | 667129 | 30 | 0.000211333 | 0.0082279 | 0.00281073 | 1168 | 399 | 0.0256849 | 9.13817 | 141956 |
| 62 | 666590 | 667129 | 7 | 4.93111e-05 | 0.00421257 | 0.00281073 | 598 | 399 | 0.0117057 | 4.16464 | 141956 |
| 63 | 666856 | 667129 | 8 | 5.63555e-05 | 0.00390966 | 0.00281073 | 555 | 399 | 0.0144144 | 5.12835 | 141956 |
アソシエーション結果(=レコメンデーションデータ)の使い方
以上で基本的なレコメンデーションデータの生成は終了です。
具体的なこれの使い方は、例えば"662193"という商品をカートに入れた人に”667129”という商品を進めるというシンプルなものです。
実際はデータベースにこのレコメンデーションのデータを格納しておき、xが入力された時にyを出力するようにします。
このレコメンデーションの問題点
さて、レコメンデーションのデータを作成をし終えましたがこのレコメンデーションの問題点を(隠すことなく)示しておきます。
それは全ての入力商品(x)を対象とできていないことです。
これを確認してみましょう。
まず、xが元々のトランザクションデータにおいて何種類あるかを確認します。
# xは元データのgoods_idなので、それのユニーク数を集計します。
df_cart_ori["goods_id"].nunique()
#出力
8398
xは元々8398種類存在します。
つまり、本来はこの8398種類の入力(x)に対し、関連性の高い商品(y)をレコメンデーションできるべきです。
それでは先ほどの出力がどの程度の入力(x)に対応しているかを確認します。
# レコメンデーション結果のxのユニーク数を集計します。
df_recommendation["x"].nunique()
#出力
463
先ほどのレコメンデーションデータが対応する入力(x)は463種類しか対応していません。(463/8392なのでだいたい5パーセントぐらい)
これがユーザー行動ベースレコメンデーションの1つの弱点です。
おそらく、実際ではこれを対策する必要が出てくるでしょう。
この対策としては以下が考えられます。
- トランザクションデータ数を増やす
- 他のレコメンドデータ(コンテンツベースレコメンドなど)で補完する
まとめ
アソシエーションを活用したレコメンデーションは、トランザクションデータが溜まっていれば比較的容易にレコメンデーションデータの作成が可能です。
実際の業務でレコメンドエンジンを作ろうとしている方は、ぜひお試しいただけると!