この記事について
あまり世間にレコメンドに関してサンプルデータを使って実装したチュートリアルが無かったので記事を書きました。
レコメンデーションを作成する手法は機械学習などを使った手法などがありますが、これは統計よりの手法を使ったレコメンデーション作成方法の記事です。
pythonとオープンデータセットを用いて説明をしていきます。
レコメンドとは
そもそもレコメンドとは何かですが、顧客にとって関心があると思われる商品、サービスなどを提供者側から薦めることです。
下に●MAZONの例を示しますが、ある『掛け布団』の商品ページを見るとそのレコメンド商品として**『掛け布団カバー』と『敷布団』**がレコメンドされています。
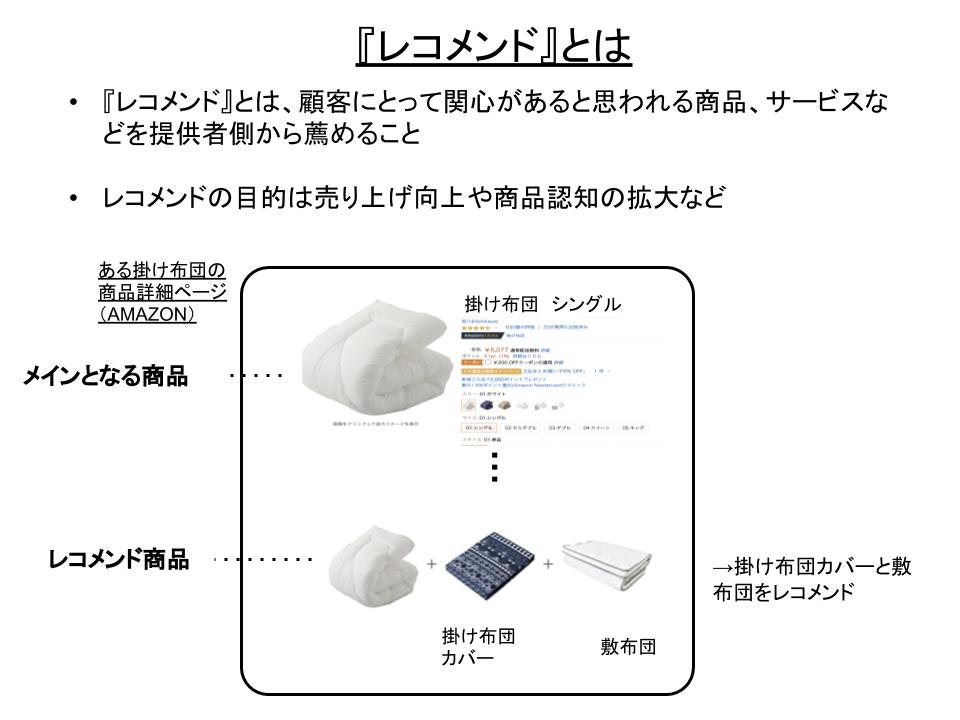
『掛け布団』と『掛け布団カバー』『敷布団』は確かに関連がありそうで、一緒に買ってしまう人もいるかと思います。
まさにこれが狙いで、レコメンドを行うことにより俗に言う『連れ買い』や他商品の認知をさせることができます。
レコメンドの種類
レコメンドは大きく分けて**『コンテンツベース』と『トランザクションベース』**の2つがあります。

それぞれメリットデメリットがありますが、複合的に使うことができますので互いのデメリットを解消し合うことが可能です。
アソシエーション分析を活用したレコメンデーションについて
この記事でのテーマであるアソシエーション分析を活用したレコメンデーションは以上の種類のうちの**『トランザクションベースレコメンド』**にあたります。
そして先ほどの●MAZONの例の『掛け布団』に対して『掛け布団カバー』と『敷布団』をレコメンドするのも『トランザクションベースレコメンド』になります。

『トランザクションベースレコメンド』は基本的に『連れ買い』された商品が出やすい結果となります。
※逆に『コンテンツベースレコメンド』の場合は『類似している』商品がでることが多く、掛け布団の場合であれば他のメーカー掛け布団などが出やすい結果となると思います。
アソシエーション分析とは何か
アソシエーション分析とは、例えば「商品Xを買われた時に商品Yは同時に(もしくは次に)買われやすい」という商品XYの関連性を明らかにすることです。これはレコメンドで行いたいことそのものですね。
アソシエーション分析は統計的なアプローチで、詳細な説明や理論はこちらのサイトに非常によくまとまっております。よって詳細な説明や理論はこちらのサイトをご確認いただき、この記事ではより理論抜きで抽象的な概念を説明していきます。
アソシエーションの分析手法
アソシエーション分析において関連性を評価できる手法は2つあります。
1. 確信度(Confidence)を用いる方法
2. リフトを用いる方法
ちなみにこの記事では2のリフト値を用いる方法を採用します。2は1がベースとなりますので、まず1から以下に説明していきます。
1. 確信度(Confidence)の考え方
簡単にいうと、ある商品Xが買われた時に同時に(もしくはその次に)変われる商品Yを見つける手法です。
以下の図をみてください。
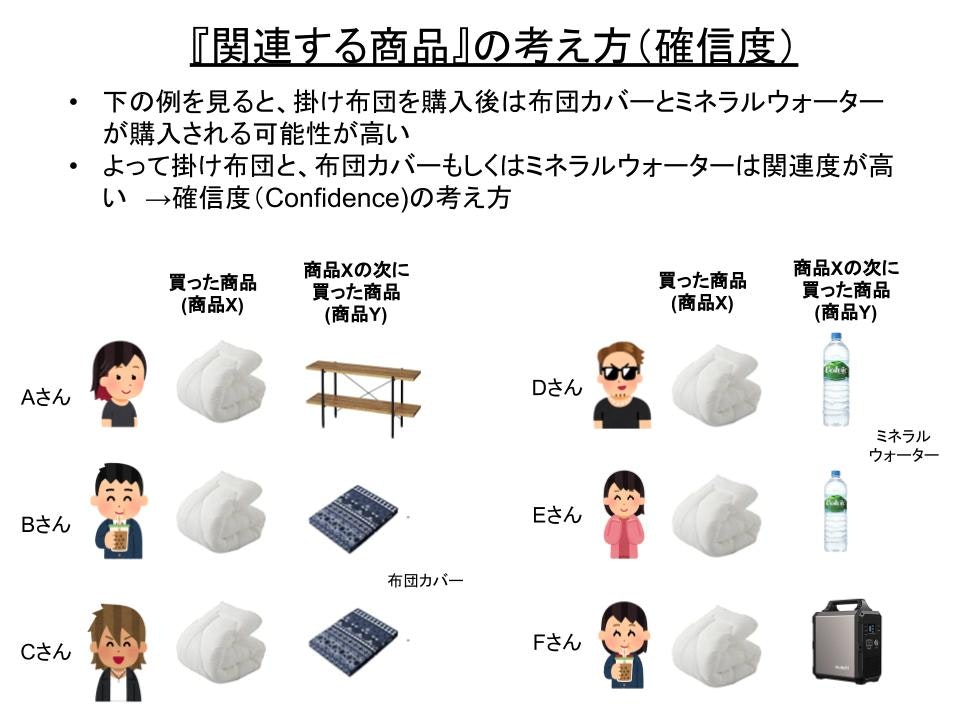
まず小規模な例ですが、以上のように先ほどの掛け布団を買った顧客のデータを抜き出してみたとします。
これを見ると6人のうち、掛け布団を購入後に布団カバーを2人、ミネラルウォーターを2人、他の商品は1人づつという結果になってます。
この結果だけを見ると掛け布団と関連性が高いのは布団カバーとミネラルウォーターということになります。
この考え方が**確信度(confidence)**の考え方です。
2. リフトの考え方
1の確信度の考え方には一つ考慮すべきポイントがあります。以下の図をみてください。
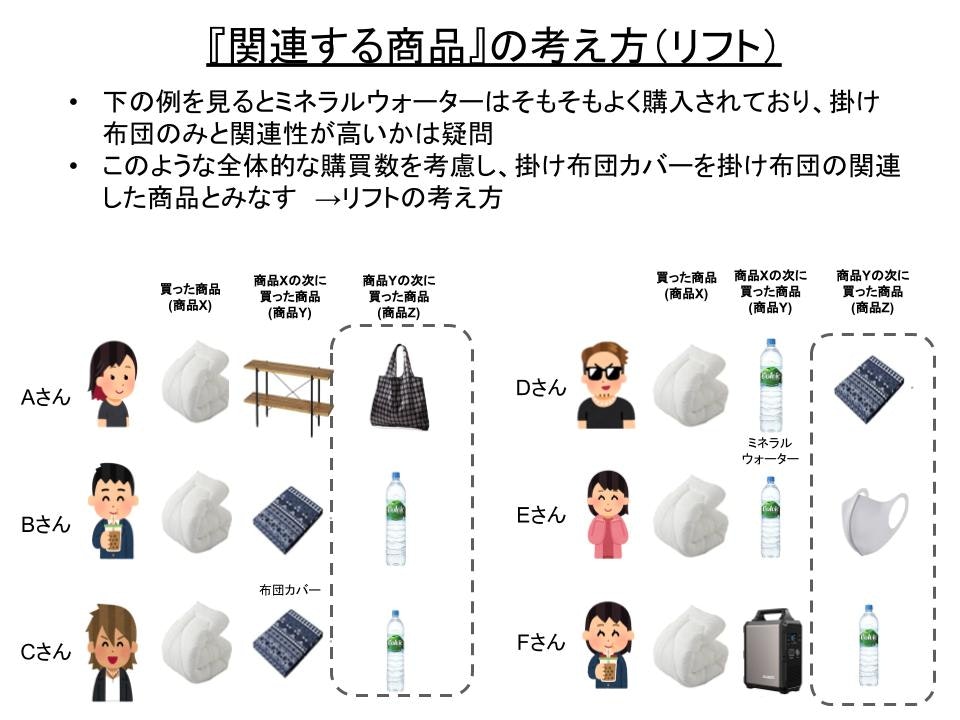
仮にこの6人の顧客のデータをもう少し集めたとしましょう。
上の例だと、ミネラルウォーターはそもそもメジャーな商品で掛け布団とは関係なく頻繁に購入されています。この場合、ミネラルウォーターは掛け布団のみと関連性が高いということは疑問に思えてきます。
しかし結果的にミネラルウォーターが買われることが多いのであれば、その商品Xに対してもミネラルウォーターをレコメンドしておけばいいのではと考えるかもしれません。
これが一概にダメだとは言い切れないのですが、個人的に以下を考えます。
1. そもそもメジャーな商品は認知されているためレコメンドする必要がない
2. 顧客側から見たときに、レコメンド商品として違和感を感じる
リフトの考え方では、このようなメジャーな商品は省き、商品Xに特徴的な関連商品Yを見つけることが可能になります。
実際はこちらのサイトにあるようにリフト値というものをトランザクションデータから算出し、それを元に関連性の高い商品XYのペアを導いていくといく流れになります。
サンプルデータを用いたチュートリアル
こちらに記事を追加しました。