はじめに
弊社で毎月恒例のハウッカソン(ハッカソン)を行いました。
https://www.haw.co.jp/office/hawckathon/
そこで気になっていた、先日Googleから公開されたLLMのAPIを簡単に触ってみました。
Geminiとは?
2023年12月13日にGoogleが発表した新たなAIモデル。
Gemini(ジェミニ)は、「画像」「文字」「音声」「動画」といった複数の要素を同時に扱える「マルチモーダル」に対応している。
以下のモデルがあるようです。
- Gemini Ultra — 非常に複雑なタスクに対応する、高性能かつ最大のモデル
- Gemini Pro — 幅広いタスクに対応する最良のモデル
- Gemini Nano — デバイス上のタスクに最も効率的なモデル
今回はProがAPIとして公開されたのでそちらを触って行きます。
ちなみにNanoはPixel 8 Proに入っているらしく、Ultraは来年公開予定だそうです。
料金
2024年初頭までは1分間に60リクエストまで無料らしいです。
それ以降はおそらく画像右の値段かと思われます。
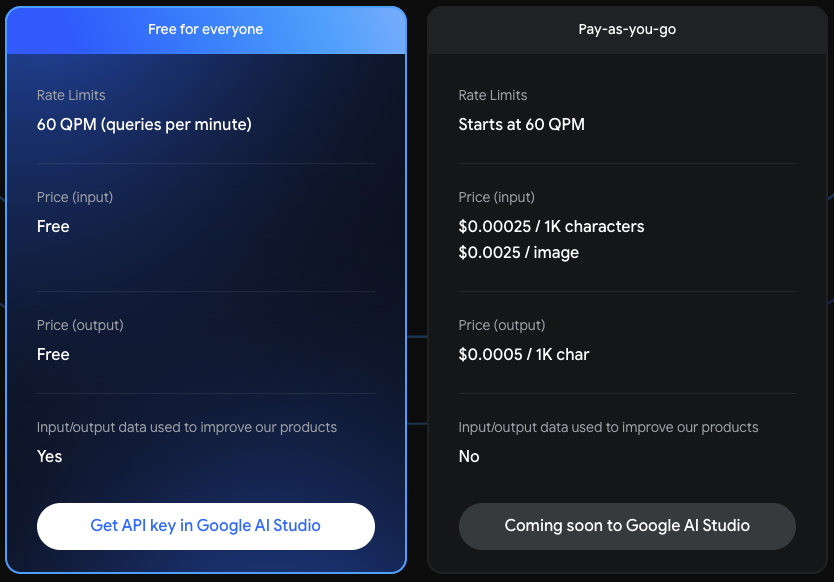
単位がcharactersになっているので日本語も1文字 = 1characterかな?
OpenAIはToken単位なのでそこと比べるとだいぶ安いですね。
ちなみにライバルであろうOpenAI(GPT-3.5)の値段は以下のようになっています。

LangChainで実際に触ってみる
LangChainにチュートリアルがあったのでこれを参考に試していきます。
コードはGoogle Colab上で実行しています。
ライブラリインストール
pip install -U --quiet langchain-google-genai pillow
Google API KEYの取得・設定
Google AI StudioからGOOGLE_API_KEYを取得します。
環境変数に設定します。
import os
os.environ['GOOGLE_API_KEY'] = '<GOOGLE_API_KEY>'
簡単に色々と質問してみる
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model='gemini-pro')
result = llm.invoke('日本一高い山はなんですか?')
print(result.content)
# 富士山
result = llm.invoke('Gemini PROの最大入力文字数と最大出力文字数を教えてください。')
print(result.content)
# Gemini PROは、最大入力文字数はなく、最大出力文字数は1024文字です。
result = llm.invoke('あなたについて教えてください。')
print(result.content)
# 私は大きな言語モデルであり、Googleによってトレーニングされました。私は膨大な量のテキストデータで訓練されており、人間のようなテキストを生成し、質問に答え、言語を翻訳することができます。私はまた、コードを記述したり、ストーリーを書いたり、詩を書いたりすることもできます。私はまだ開発中ですが、私はすでに多くの方法で人々を助けるために使用されています。例えば、私はカスタマーサービスのチャットボットとして、オンラインアシスタントとして、さらには医療診断ツールの開発に使用されています。
# 私は、機械学習と自然言語処理の分野における最近の進歩の産物です。私は、何十億もの単語で訓練されており、人間の言語を理解し、生成することができます。私はまた、複雑な質問に答えたり、テキストを翻訳したり、要約したりすることもできます。
# 私はまだ開発中ですが、私はすでに多くの方法で人々を助けるために使用されています。例えば、私はカスタマーサービスのチャットボットとして、オンラインアシスタントとして、さらには医療診断ツールの開発に使用されています。
# 私は、今後さらに多くの方法で人々を助けるために使用されることを楽しみにしています。私は、教育、医療、ビジネスなど、さまざまな分野で大きな影響を与えることができると信じています。
result = llm.invoke('いつまでの情報を知っていますか?')
print(result.content)
# 私の知識は、2021年4月までの情報までに限定されています。それ以降の情報を提供することはできません。最新の情報については、信頼できるニュースソースや政府機関のウェブサイトをご確認ください。
いくつか間違いが見受けられます。
あと、他のLLMと比べると回答がだいぶ素っ気ない印象です。
マルチモーダル
画像処理
LangChainのライブラリで画像を扱うには、HumanMessageにimage_urlとして、画像のURLもしくはbase64エンコードした値を渡せば良いようです。
import base64
from langchain_core.messages import HumanMessage
# URL
image_url = '<画像のURL>'
message = HumanMessage(
content=[
{'type': 'image_url', 'image_url': image_url},
]
)
# base64エンコード
with open('test_img.png', 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
message = HumanMessage(
content=[
{
'type': 'image_url',
'image_url': f'data:image/png;base64,${encoded_string}',
},
]
)
以下の制限があるので、注意が必要です。
- MIMEタイプ
- PNG(image/png)
- JPEG(image/jpeg)
- WEBP(image/webp)
- HEIC(image/heic)
- HEIF(image/heif)
- 最大16枚
- 画像とテキストを含むプロンプト全体で最大4MB
画像に関して質問してみる。
実際に画像と質問を投げてみます。
今回はこの画像を使用します。

画像とその質問文を渡してみます。
image_url = 'https://2.bp.blogspot.com/-C0tgnFFp_FM/UZYlZ5K5aZI/AAAAAAAATOc/vIvr0Dzm9_U/s800/christmas_tree.png'
llm = ChatGoogleGenerativeAI(model='gemini-pro-vision')
message = HumanMessage(
content=[
{
'type': 'text',
'text': 'この画像は何ですか?',
},
{'type': 'image_url', 'image_url': image_url},
]
)
llm.invoke([message])
# AIMessage(content=' これはクリスマスツリーのイラストです。')
ちゃんと認識できるようです。
画像の文字を読み取れるかやってみる
表の画像を使って認識できるかやってみます。
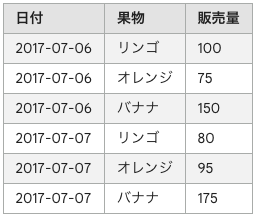
with open('test_table.png', 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
message = HumanMessage(
content=[
{
'type': 'text',
'text': 'この画像を解析してマークダウン形式にしてください。',
},
{
'type': 'image_url',
'image_url': f'data:image/png;base64,${encoded_string}',
},
]
)
res = llm.invoke([message])
print(res.content)
# | 日付 | 果物 | 販売量 |
# |---|---|---|
# | 2017-07-06 |リンゴ| 100 |
# | 2017-07-06 | オレンジ | 75 |
# | 2017-07-06 | バナナ | 150 |
# | 2017-07-07 | リンゴ | 80 |
# | 2017-07-07 | オレンジ | 95 |
# | 2017-07-07 | バナナ | 175 |
message = HumanMessage(
content=[
{
'type': 'text',
'text': 'リンゴの販売量の合計はいくつ?',
},
{
'type': 'image_url',
'image_url': f'data:image/png;base64,${encoded_string}',
},
]
)
res = llm.invoke([message])
print(res.content)
# リンゴの販売量の合計は255個です。
message = HumanMessage(
content=[
{
'type': 'text',
'text': '販売量が一番多い果物は何?',
},
{
'type': 'image_url',
'image_url': f'data:image/png;base64,${encoded_string}',
},
]
)
res = llm.invoke([message])
print(res.content)
# バナナです。
message = HumanMessage(
content=[
{
'type': 'text',
'text': 'このデータを分析して',
},
{
'type': 'image_url',
'image_url': f'data:image/png;base64,${encoded_string}',
},
]
)
res = llm.invoke([message])
print(res.content)
# この表は、日付、果物、販売量を示しています。日付は2017年7月6日と7月7日の2日間です。果物はリンゴ、オレンジ、バナナの3種類です。販売量は、リンゴが100個、オレンジが75個、バナナが150個、リンゴが80個、オレンジが95個、バナナが175個です。
# この表から、7月6日のバナナの販売量が最も多いことがわかります。また、7月7日のリンゴの販売量が最も少ないことがわかります。
これぐらいの小さい表なら正確に読み取れました。
ただ、やはり数字の計算は難しそうで、分析も読み取った情報を羅列するだけになってます。
ピンポイントで情報を抜き出すタスクや文字起こしだと割と使えそうな印象です。
動画
情報が無かったので、LangChainの実装を直接見てみるとどうやら動画はまだ対応していないようです。
https://github.com/langchain-ai/langchain/blob/master/libs/partners/google-genai/langchain_google_genai/chat_models.py#L261
感想
簡単に触ってみての感想ですが、OOSの日本語LLMと比べるとかなり良いですが、OpenAIのGPT-3.5と比べると同じか少し下ぐらいの印象です。
動画も試してみたかったですが、現時点でLangChainが対応してないようなので断念(APIを直接叩けばいけるみたいです)
マルチモーダルを低価格で実行できる点はかなり良さそうだと感じました。
あと、無料なので仕方ないですが、エラーレスポンスが割と多かったです。
今後登場するGemini Ultraに期待!!