本記事は、VISITS Advent Calendar 2019の21日目の記事です。
VISITS Technologiesでインフラエンジニアをしている@syogunです。
本日は、全社的にDatadogを導入したので、何をやったのか、何がよくなったのか等を振り返りたいと思います。
これから、Datadogを導入しようと考えている方に少しでも参考になればと考えています。
それでは参りましょう。
なぜ導入したのか?
私が使いたかったからです!本気です。
弊社エンジニア @ham さんの スタートアップに転職して思ったこと にもありましたが、
スタートアップ企業は、技術選定の自由度が高い印象です。(言うまでもなく個人的な見解です)
もちろん同僚や上司を納得させ、最後までケツを持つ覚悟が必要だと思います。
具体的な理由としては、Datadogだけでかなりの領域の監視がカバーできるという点です。
インフラレイヤー以外にも外形監視、APM、ログ監視等の機能もあり、何かあった時は基本的にDatadog上で調査できる点は非常に魅力的でした。
やったこと
ここからは私が導入時にやったことを振り返っていきます。
Integration
弊社ではAWSやGCPといったクラウドサービス上でシステムが動いています。
AWSしか触ったことのないサーバーエンジニアがGCPで本番運用してみた(前編)
AWSしか触ったことのないサーバーエンジニアがGCPで本番運用してみた(後編)
Datadogでは、AWSやGCPのインテグレーション設定を行うだけで、かなりのメトリクスが取得できます。
今のところすべてのインテグレーションは無料で、種類も豊富なのでおすすめです。
インテグレーション
Datadog インテグレーション一覧(めっちゃあるやん..!)
AWS,GCPのインテグレーション方法に関しては、以下の記事をご参照ください。
Datadog AWS インテグレーション手順
Datadog GCP インテグレーション手順
Multi Organization
Datadogには、Multi Organization機能があります。
弊社では、ideagramやdesign thinking testといった複数プロダクトがあるんですが、各プロダクトごとにDatadogのOrganizationを作成して運用しています。
そうすることで、各プロダクトのエンジニアは、自身が開発するOrganizationに参加すればいい状態を作っています。
Organization切り替え時に再度認証(私はGoogle認証)が必要なところは若干手間です。改善に期待。
Synthetics(外形監視)
Syntheticsという外形監視機能があります。弊社ではこのSyntheticsの実行結果をSLOの目標値として使用しています。
SyntheticsにはAPIテストとブラウザテストの2種類があります。
APIテスト
これはシンプルな外形監視です。
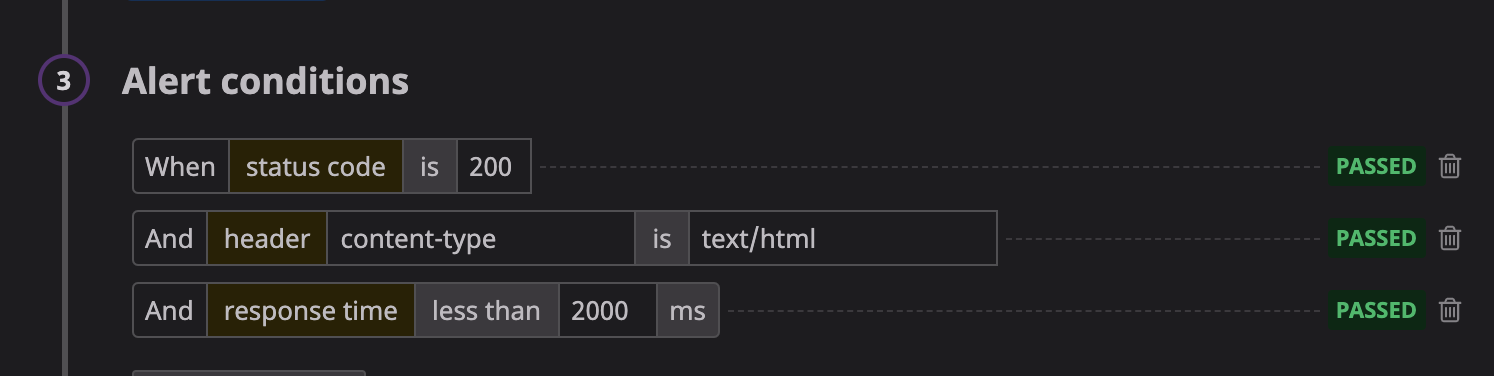
監視対象のURL、ロケーション、コンディション(responstimeやstatus code等を記載)を設定するだけです。
コンディション設定は以下のようなイメージです。
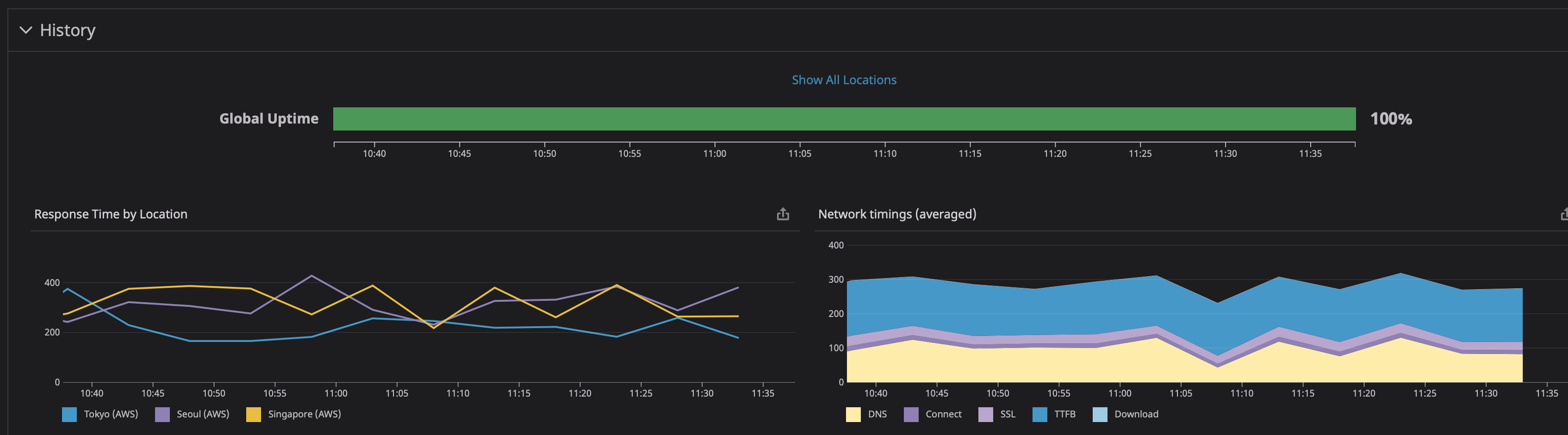
実行結果は以下のようなイメージです。
DNSの名前解決時間やTTFBなどの情報が確認できます。
ブラウザテスト
ブラウザテストは、ブラウザテストしたいサービスの画面遷移をレコーディングするだけでセットアップできます。
また、ユーザIDやパスワードといったアカウント情報もDatadog上に保存可能で、保存したアカウント情報をブラウザテストが使用してログインするといったことも可能です。
なお、ブラウザテストはAPIテストと比較してお値段が少々お高いので、実行回数にはお気をつけください。
料金はこちら
APM
APMを導入することで、インフラのメトリクスやログだけだと分からなかったアプリケーションレイヤーのボトルネックを特定するのに役立っています。

弊社CTO @mayah のアドベントカレンダーでもご紹介したのですが、 Kaizen Week と称して1週間を技術的負債を集中的に取り除く活動を定期的に開催しています。
そのKaizen Weekで弊社エンジニア @kshibata101 さんがDatadog APMを活用したパフォーマンスチューニングを行い、Best KAIZEN Awardを受賞しました。
また、APMはアプリケーションのエラーメッセージも確認できるので、トラブルシューティング時にとても役立ちます。
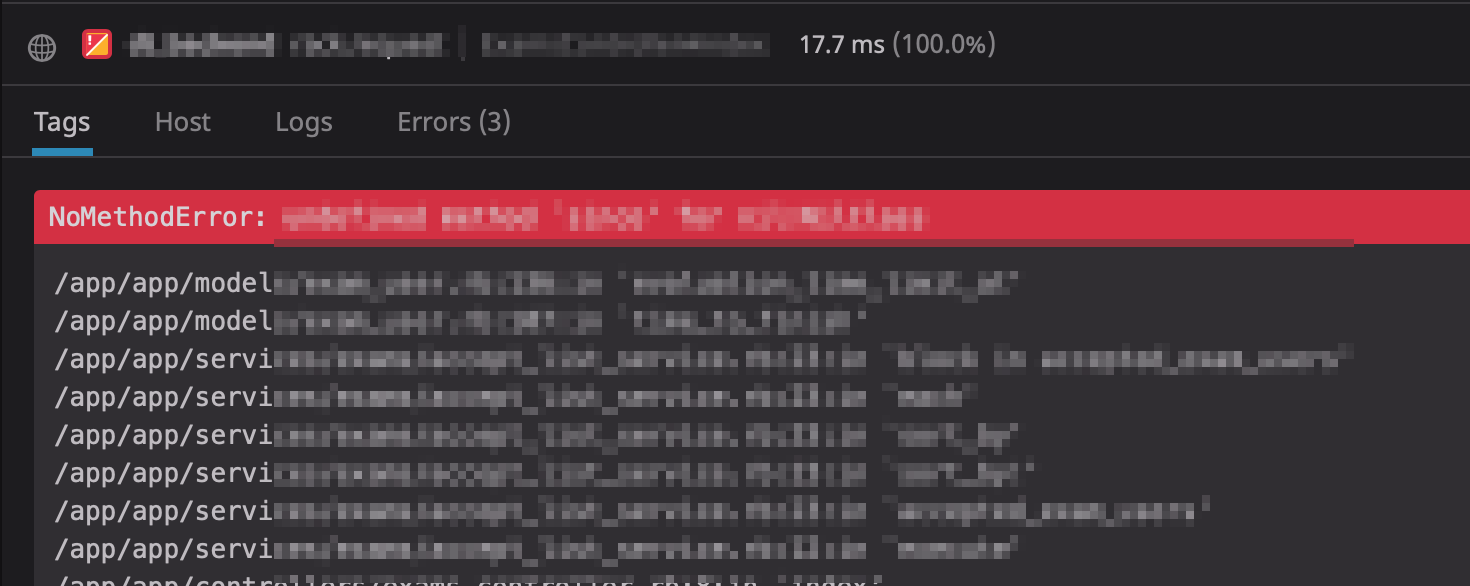
APMの導入方法に関しては、以下の記事をご参照ください。
Instrument your application
また、APMに関しては私を含め弊社メンバーがQiitaに記事を投稿してます。お時間ありましたら、そちらも併せてご参照ください。
GoのアプリケーションにDatadogAPMを導入する。
GAEにDatadog APMを導入する
Infrastructure
イングレーションのところでもご紹介しましたが、ALBやRDSといったメトリクスがモリモリ取得できます。
こちらのメトリクスを基にアラートが柔軟に設定可能です。
Containers
一部環境ではAWS FargateやGKEを導入しているんですが、コンテナの監視に強いのもDatadogの魅力です。
GKEの場合は、DeaemonSetでDatadogをデプロイ、Fargateの場合はSideCar方式でデプロイすればそれぞれコンテナのメトリクスが取得できます。
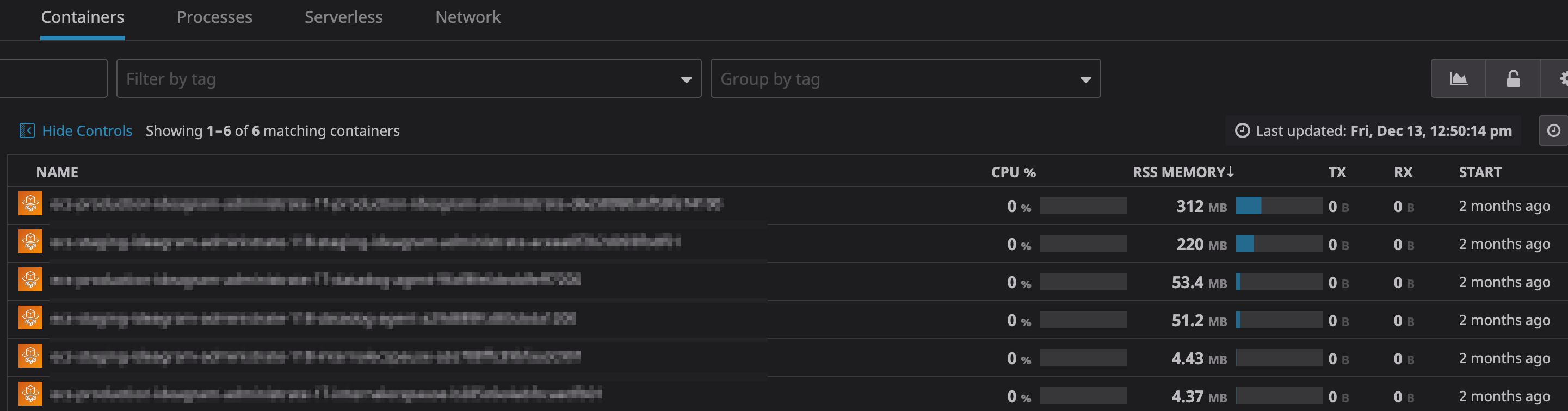
それぞれの導入方法に関しては、以下の記事をご参照ください。
How to monitor Google Kubernetes Engine with Datadog
Monitor AWS Fargate applications with Datadog
Serverless
Lambda等のメトリクスもインテグレーションを有効化するだけで自動で取得します。
インテグレーション設定1つでメトリクスが取得できるのは魅力ですね。
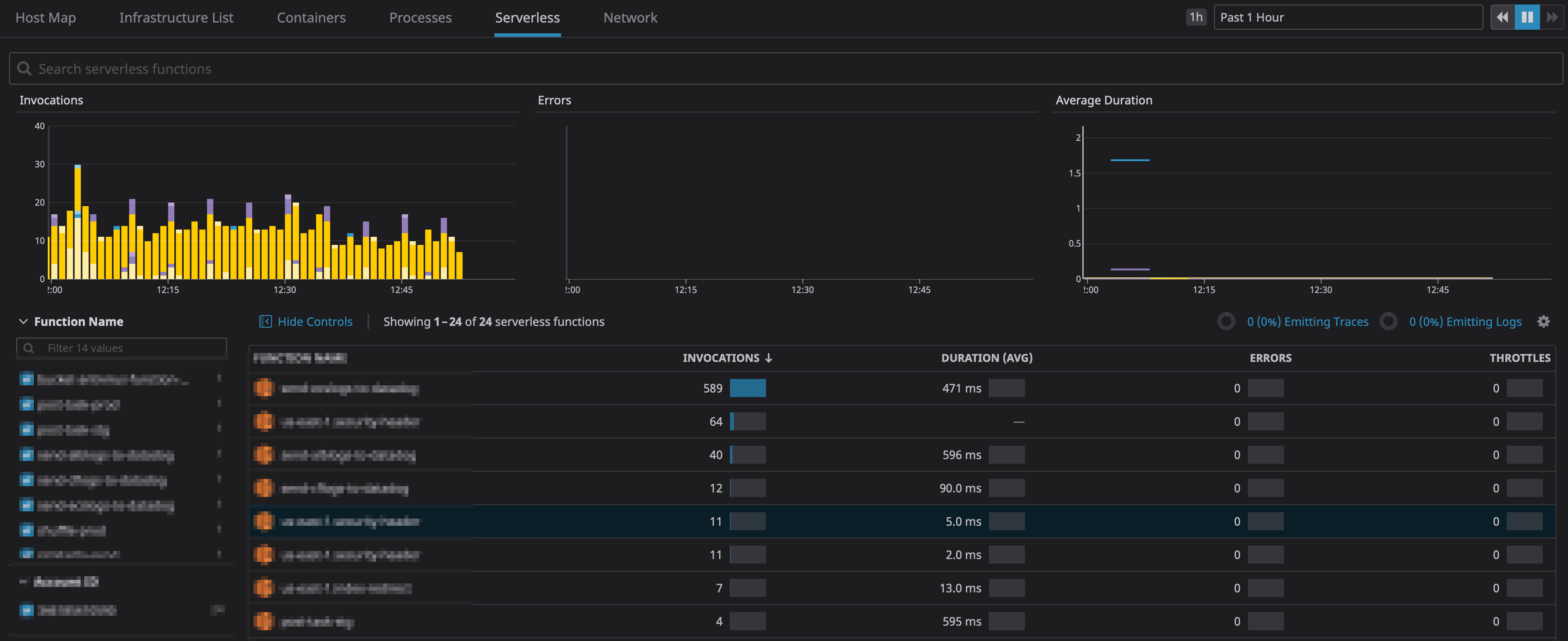
ContainerやServerlessの料金は、こちら
Monitors
Managed Monitors
アラートはMonitorsから設定可能で、あらゆる情報(メトリクス、ログ、イベント等)からアラートの設定できます。
従来のシンプルな閾値監視(例えばCPU使用率90%以上とか)のみでなく、
Anomaly DetectionやRorecast Alertといった機械学習を使用した閾値も設定できることも魅力です。
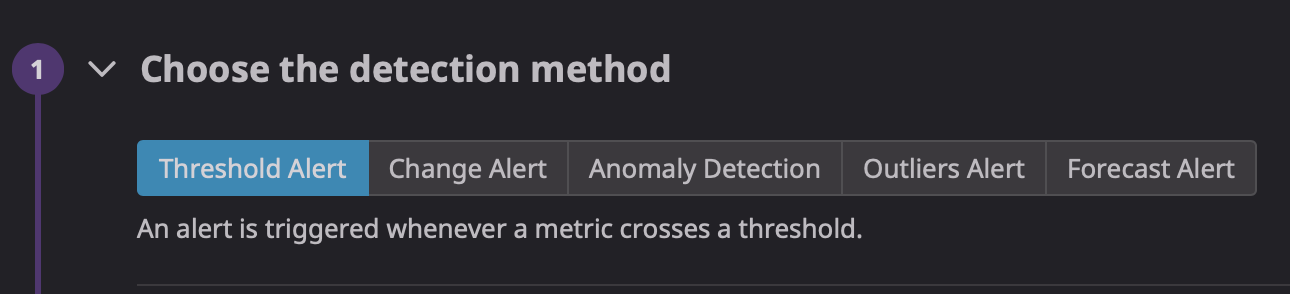
閾値を固定化しづらいシチュエーションや、いつもと違う動きを検知したいといったニーズを満たせそうです。
このあたりは、
Anomaly Detection
Outliers Alert
Forecast Alert
に詳しく書いてありますので、よかったらご参照ください。
今後こういった技術がどんどんブラッシュアップされ、人間がアラート設定しなくなる未来が私には見えました。
SLO
Datadogを導入するにあたって、各プロダクトごとにSLI/SLOを決めて、それに沿った監視を行うことにしました。
SLI/SLOに関しては、本題から少し逸れるため詳しくは記載しませんが、
Syntheticsによる5分毎のAPI Testが以下の条件を満たすこと
・レスポンスタイム:Response Timeがxxx msで完了すること
・ステータスコード:200を返すこと
・上記条件を正常とみなし、可用率が99.9%以上となること。
といった感じで各プロダクトのエンジニアとPMと相談しながら決めました。(このあたりはまだ手探りです)
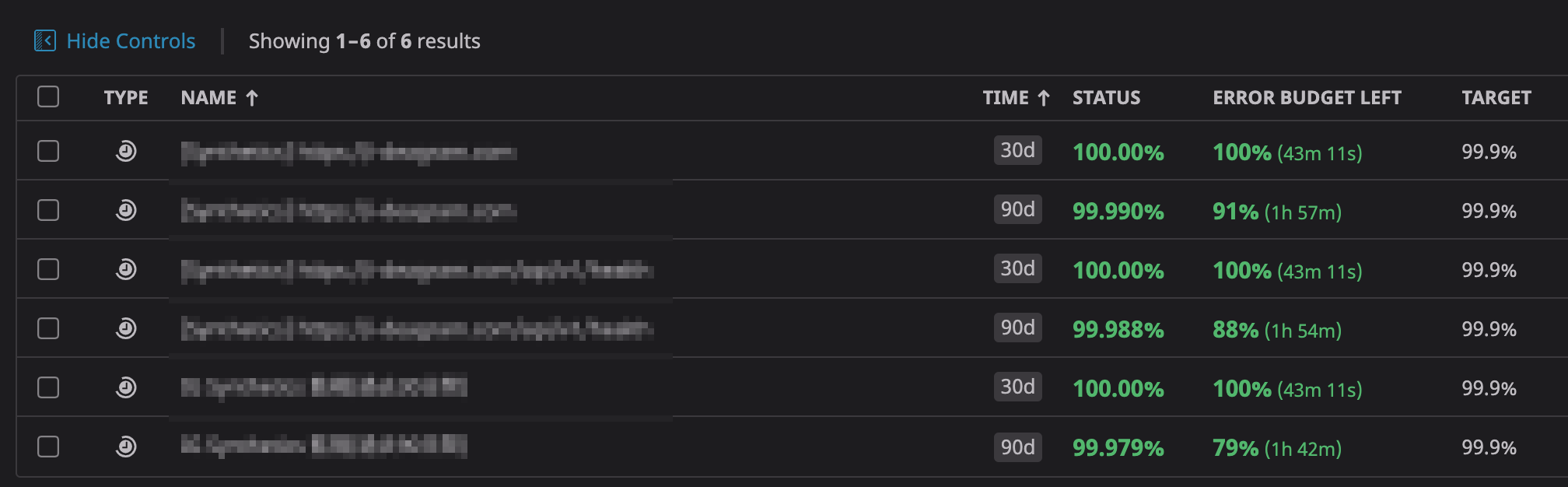
DatadogにはSLO機能があり、SLOの達成状況を可視化できるため、活用しています。
何をSLIにするかを設定し、目標とする稼働率(SLO)やSLO対象期間を設定することで、SLO達成状況が可視化できます。
また、SLOに基づいたError Budgetも出るので、リリース計画に参考にもできそうです。
例えば、「プロダクトAはError Budgetが残り少ないので今スプリントは、新規機能リリースはやめて改善タスクやバグチケットを中心にやっていこう」といった会話も可能できそうです。
Log Management
Log Managementは、さまざまなログを集約できます。
なんといっても便利なのは、使いやすいフィルタリング機能ではないでしょうか。
ログはjson化しておけば、Datadog側でよろしくParseしてくれますし、必要に応じてDatadog側でParse処理も書けたりするので柔軟に対応可能です。
また、ログから独自のメトリクスも生成できるようなので便利ですね。
以下、いくつか活用事例をご紹介します。
ALBやGCLBのログ
AWSのALBやGCPのGCLBのアクセスログをLog Managemenで可視化できます。もちろんこのログを基にアラートを設定することも可能です。
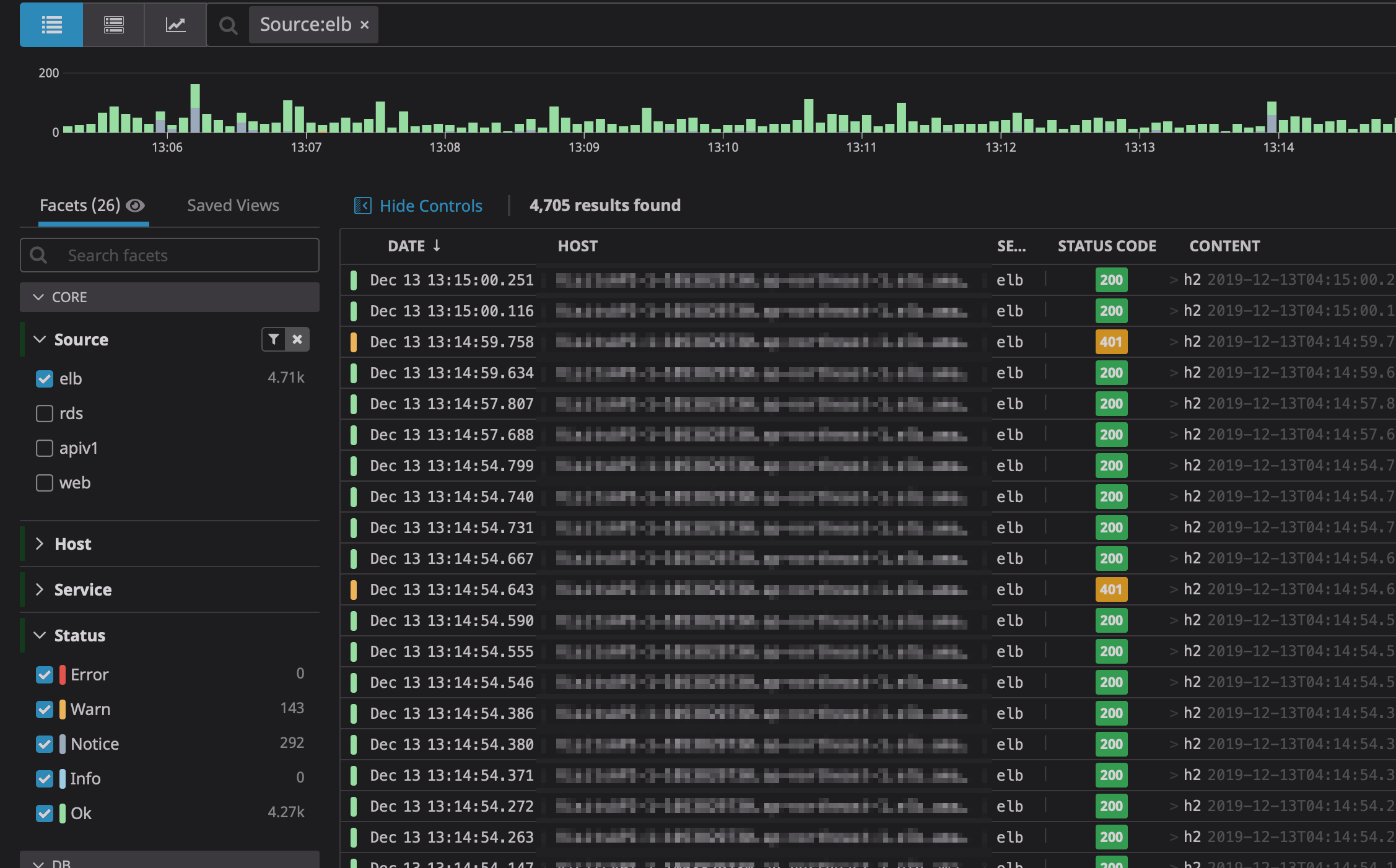
注意点としては、アクセス数が多いサービスの場合、S3->Datadogの転送料金が以外にかかってしまうので要注意です。
Datadog側でログをアーカイブするLog Archivesという機能があるので、保存期間を短くしてコストカットする手もあるかと思います。
導入方法に関しては、以下の記事をご参照ください。
Amazon Load Balancer
Collect Google Stackdriver logs with Datadog
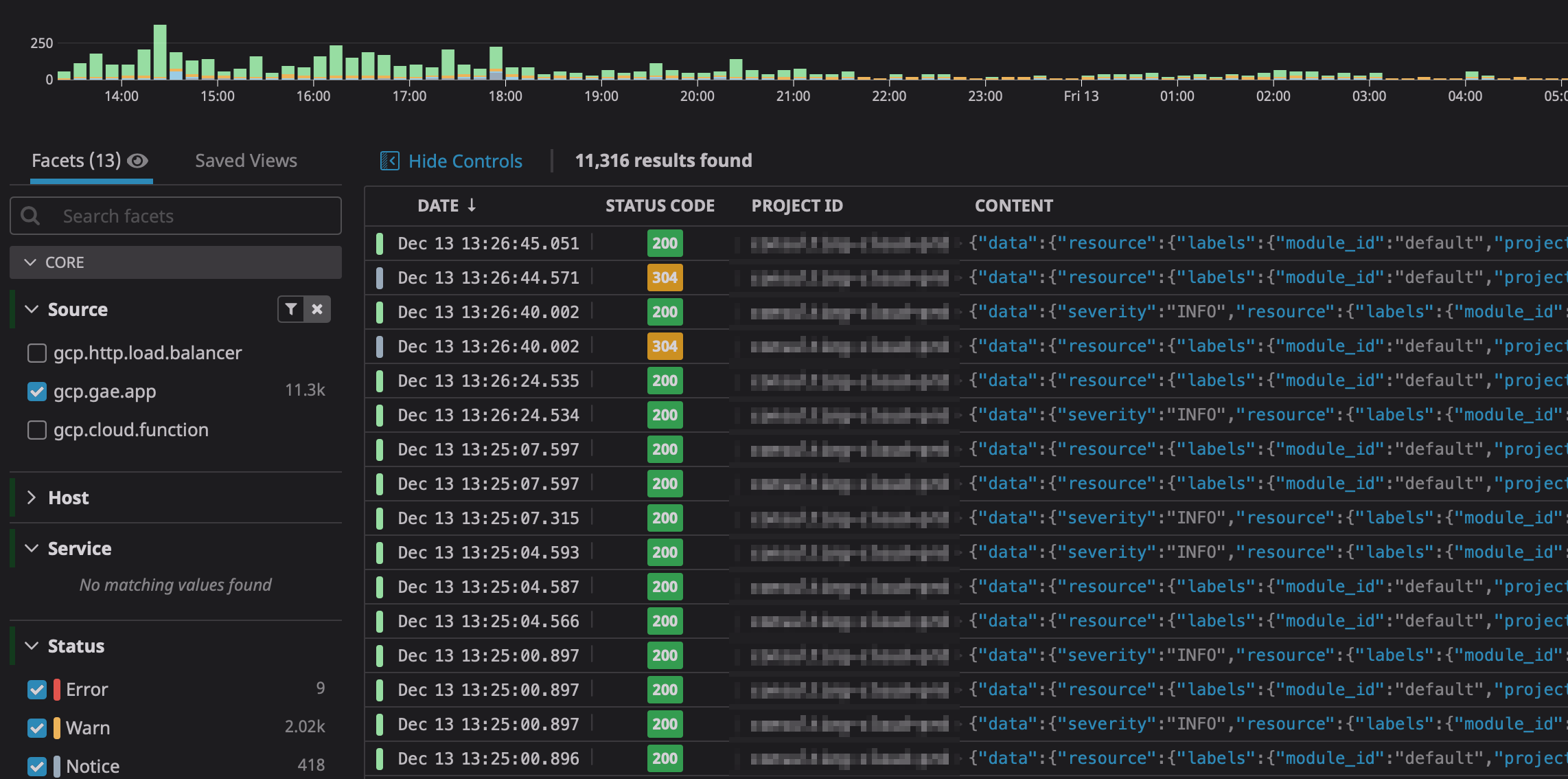
アプリケーションのログ
アプリケーションのログもLog ManagemenでParseしてくれます。
例えばGAEを使用している場合、Stackdriverに出力されたログをそのままLog Managemenに投げるだけでいい感じにParseしてくれます。
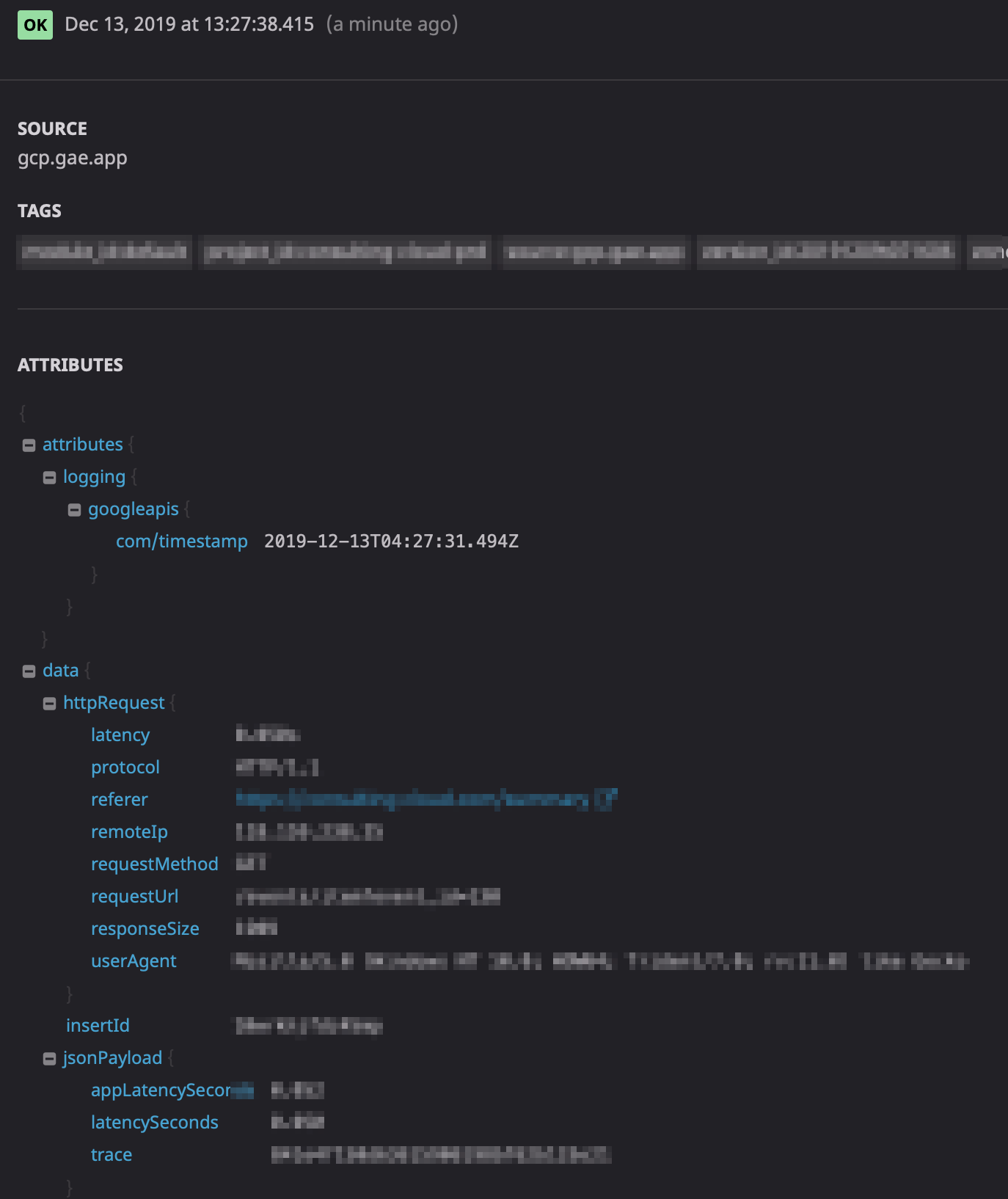
また各ログをクリックすると、こんな感じで詳細を確認できます。
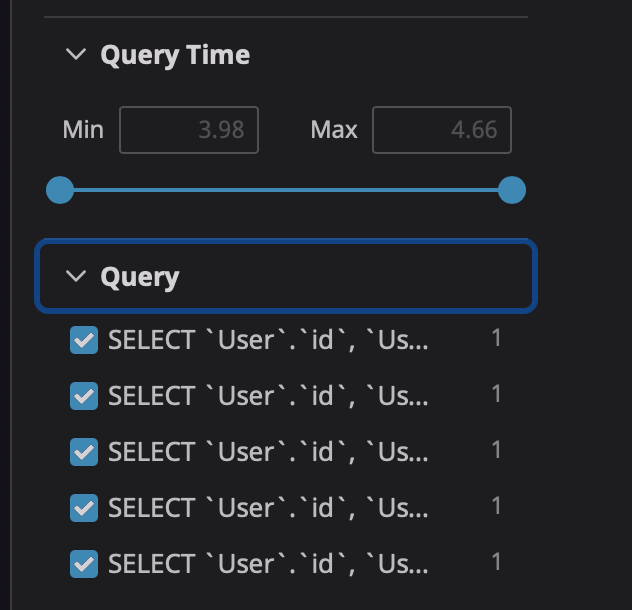
Slow Queryのログ
RDSのSlow QueryもParseしてくれます。
Log ManagemenにSlow Queryログを転送することによって
- どういった種類のSlow Queryが一番多いのか?
- 一番実行時間が長いSlow Queryはどれか?
- どの時間帯にSlow Queryが発生しているのか?
といった情報が可視化できます。Queryの実行時間や種類でフィルタリングできるのですごく便利です。
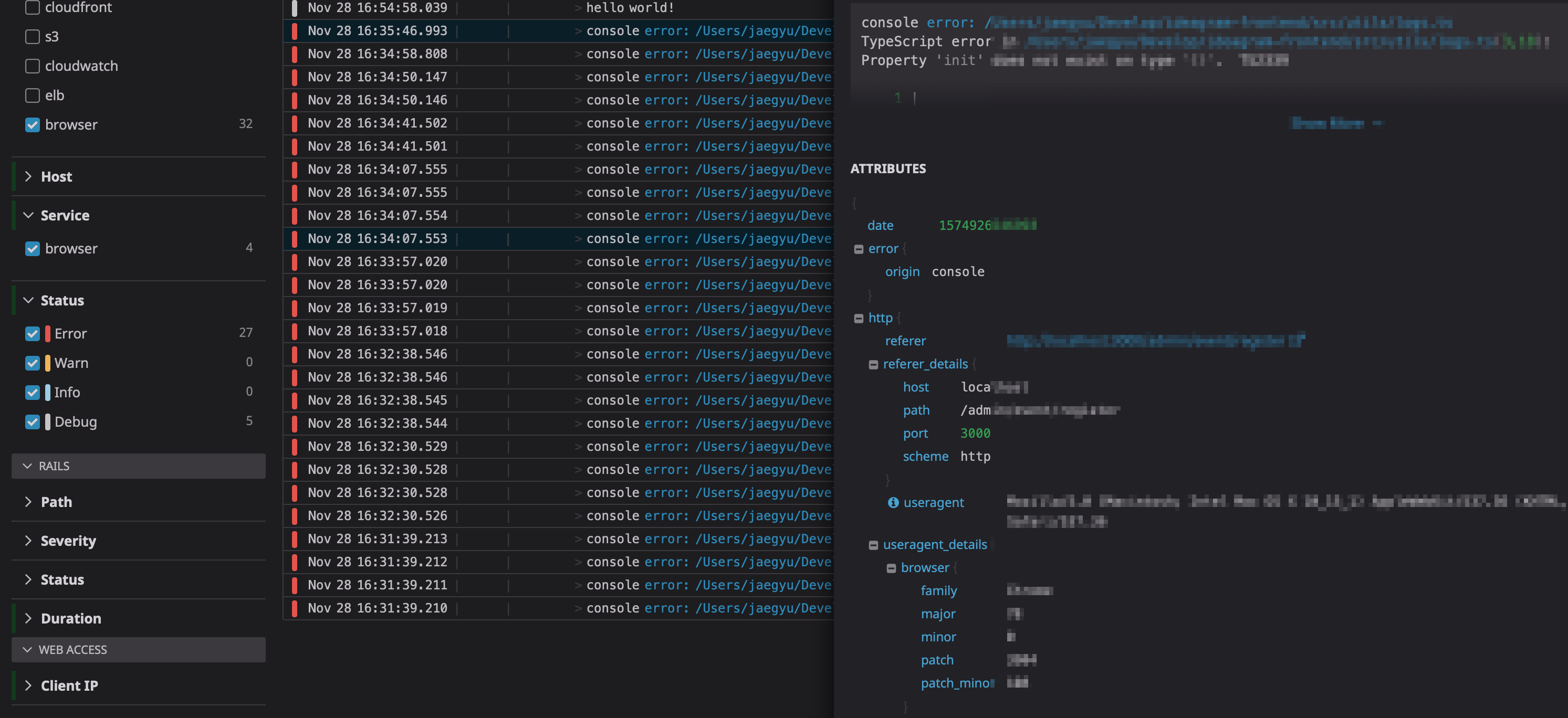
JavaScriptのログ
これはまだテスト運用中ですが、JavaScriptのログもLog Managemenに転送しています。
こうすることで、今まではDatadogで検知できなかったFrontendのエラーも検知できるようになります。
JavaScriptの導入方法に関しては、以下の記事をご参照ください。
Monitor JavaScript console logs and user activity with Datadog
この記事を書いている途中でIntroducing Datadog Real User Monitoringなる機能がローンチされて、実はそっち方がいいじゃないかと思ってます。またさわる機会があれば記事書きたいと思います、
Dashboards
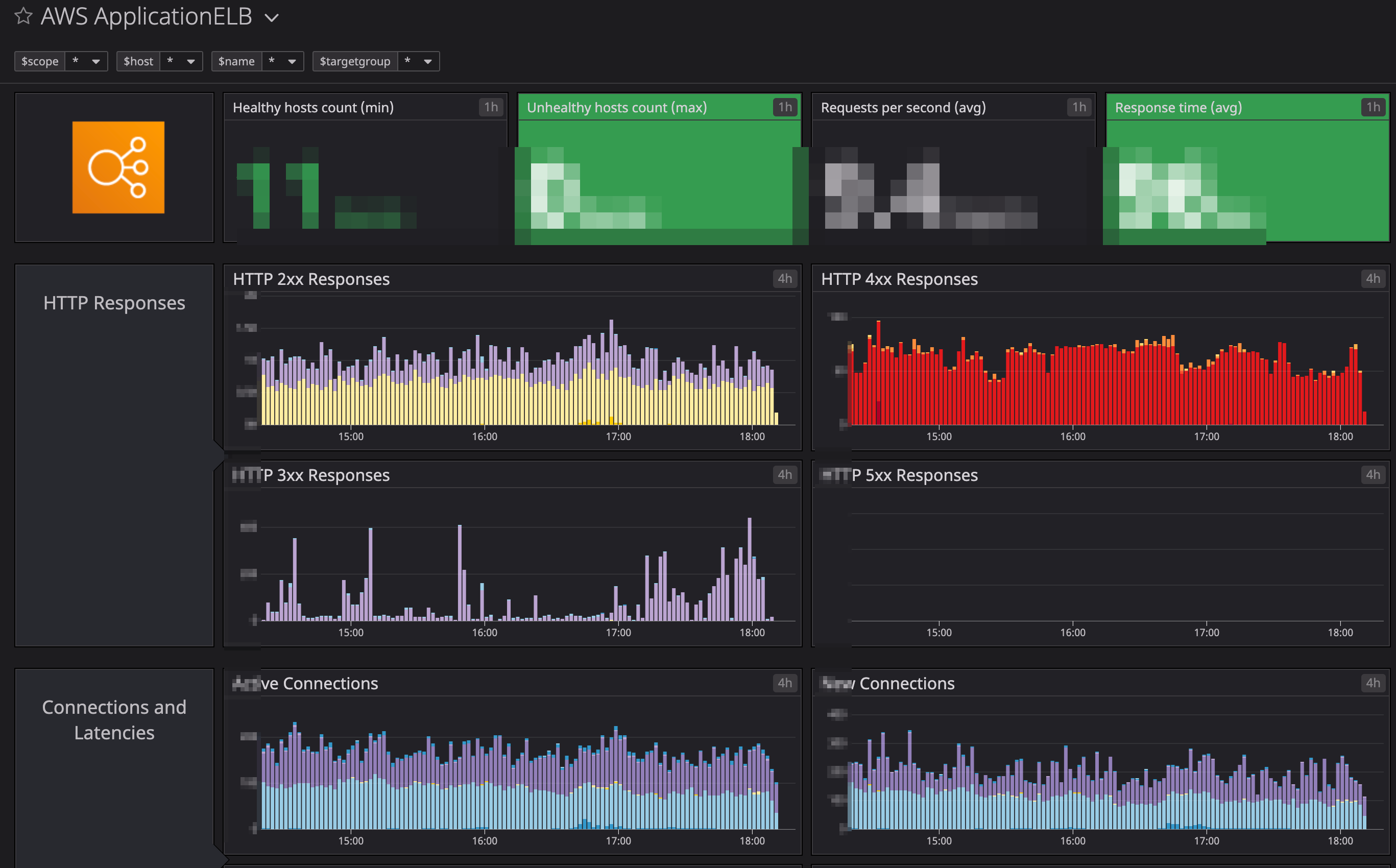
Datadogの魅力の一つはDashboardが柔軟に作れるという点ではないでしょうか。
例えば、イングレーション設定するだけで、以下のようなDashboardが自動的に作成されます。便利です。
新規Dashboard作成は、結構センスのいる作業(そして私はセンスなし)ですが、一度作ってコツが掴めけばある程度は作れる用になる気がします。
DatadogのDashboardには、TimeboardとScreenboardの2種類があります。
これどういう使い分けをするのか?最初は分からなかったんですが、今は自分なりにこう理解しています。(私がそう思っているだけです)
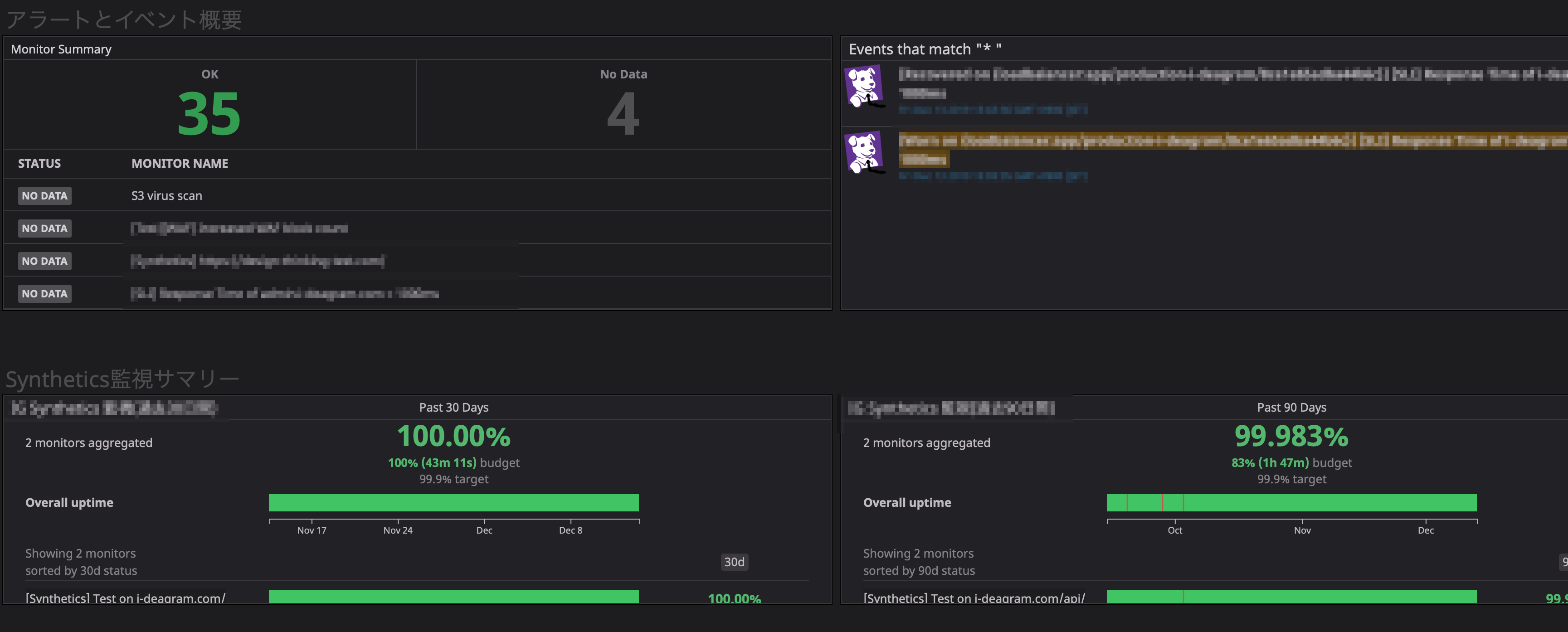
Screenboard
ステータス確認用のDashboard。
具体的には、サービスが生きているのか死んでいるのか、KPIやSLOを達成ているのかしていないのか等。
Screenboardは、現在のステータスを一目で確認できるDashboardという位置付けにしています。
Screenboardでは、何か異常があった時に何かが起こっていることは分かりますが、具体的に何が原因なのかは分かりません。
弊社では以下のようなDashboardにしてます。
Timeboard
Timeboardはトラブルシューティング用のDashboardで、Screenboardで何かが起こっていることを検知して、実際に何が起こったのかを調査するためのDashboardという位置付けにしています。
このDashboardはとても便利、ALB、EC2、RDSといった別々のメトリクスを一画面でかつ同じ時間軸で見れるので相関関係が確認しやすいです。
私のお気に入りは、Datadogがアラート名で検索すると、そのアラートが発生した時間とメトリクスをオーバーレイしてくれます。
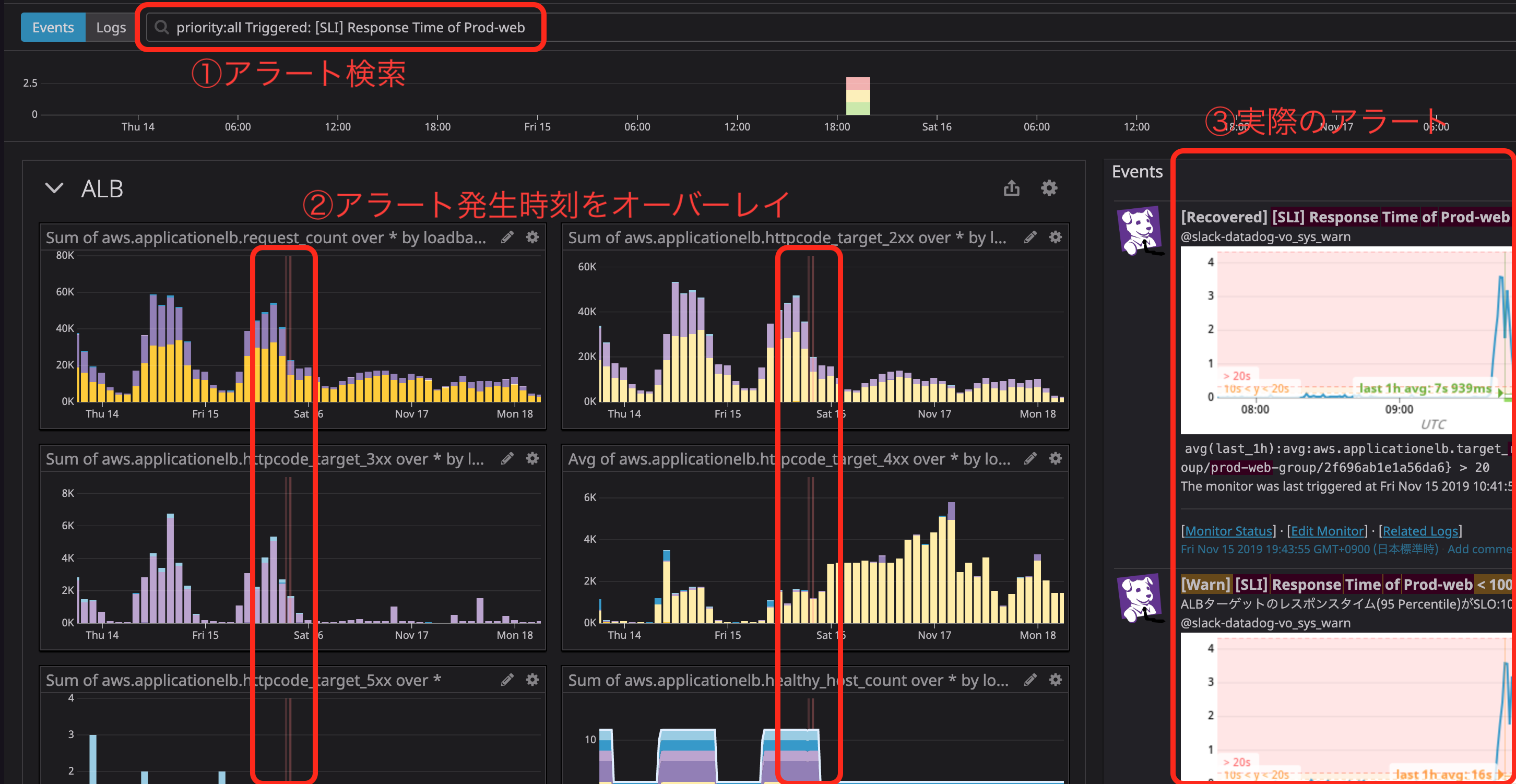
詳細は、以前私が書いたDatadogのDashboard(Timeboard)が便利!もご参照ください。
コード化(terraform化)
Datadogは、Terraformによってコード管理できます。
弊社ではGCPで似たような構成をしているプロダクトがいくつかあり、その場合Terraformでコード化しておくことで、MonitorやDashboardを簡単に複製できる仕組みを整えています。
このあたりは、気力があればまた書きたいと思います。
導入方法に関しては、以下の記事をご参照ください。
Managing Datadog with Terraform
社内布教活動
監視は一度作ったら終わりではなく、開発メンバーでPDCAを回して継続して改善していく必要があります。
私の場合、Datadogのセットアップは基本1人で進めてきたため、私以外のエンジニアがDatadogをさわる機会がなかったので、いくつか社内布教活動を行いました。
以下、事例です。
エンジニア勉強会
弊社では週1回、エンジニアの勉強会を行なっているため、そこで勉強会を開催しました。
Datadogは、多機能がゆえにメニューが豊富なので、どこを見ればいいんだ?ってなりがちです。
勉強会ではDatadogで見て欲しいポイントや機能を絞って、使い方を中心にレクチャーしました。
MTGでアラートを振り返る
週次開催されるプロダクトMTG等で、Datadogが発報したアラートから気になるものがあれば議題にあげて、開発メンバーに確認してもらうようにしています。(全プロダクトではないです)
このアラートは既知なのか?既知であれば対応中のものなのか?このままアラートとして出し続けて良いものなのか?等を議論し、アラートが狼少年化しないよう日々PDCAを回しています。
アラートが来たら騒ぐ
Datadogのアラートを設定した私は何のアラートなのか予想がつきますが、その他の開発メンバーは(特に最初の方は)内容を理解できていないことが多いと思います。
私の役目はDatadogからアラートがきたら、アラートの内容を確認して、確認した結果をコメントするようにしています。
そうすることで、(心優しい)開発メンバーがエラー内容について補足してくれたりして、今後対応方針をその場で決めたりしています。
KPT
ここからはKPTで振り返りを。
Keep
- インフラからフロントエンドまで異常を検知できる仕組みが整いつつある。
- アラートを日々改善することで徐々にノイズは減ってきている。(狼少年化しないことが大事)
- 私以外のエンジニアも監視に携わる機会が増えてきた。
- Datadogの開発速度が早く、新機能を試したくなる。楽しい。
- 監視をDatadogに統一することで、学習コストが減った気がする。
Problem
- (Datadogの話から少し逸れますが)SLOの運用がうまくいっていない。
- Datadog自体のコストの監視ができていない。
- アラート自体、まだまだ改善の余地はある。
Try
- SLOのあり方や具体的な数値については、もう1度PMや開発メンバーとMTGした方が良さそう。またSLOの定期的な見直しや運用ルールの明確化が必要かも。
- (特に)ログはアクセス数が増えるにしたがってコストがかさむので、何からコストをチェックできる仕組みを作る。
- 継続してアラートのチューニングやアプリケーションの改修を行い、本当に必要なアラート(何かしらのアクションが必要なもの)だけが飛ぶようにしていく。
まとめ
今回、全社横断的にDatadogを導入したことで、各プロダクトで最低限の監視すべてきものがある程度標準化できたのではないかと考えています。そこから各プロダクト固有の監視を追加、アップデートしていけば、より良い監視に近づいていける気がします。
また、今では調査に必要な情報はDatadogに集約されているため、 「何かあればDatadogだけを見れば分かる」という状態ができつつあります。これはトラブルシューティング時の初動が早くなり、操作にも慣れているので問題の特定が早くなると言う効果があるんじゃなかろうか?とは感じています。
Datadog自体の開発速度も早く、監視がどんどん便利になっている感があり、よりクリエティブな開発に集中したい方にはオススメのツールでした。
まだまだ書きたいことはありましたが、またの機会にしたいと思います。
ではまた!!