VISITSサーバーエンジニアの@kshibata101です。
こちらはVISITS Advent Calendar 2019の17日目の記事です。
前回はGCPの本番運用の前編ということで、プロダクトをGCPで動かすことになり導入にあたって調査したことをつらつらと書いていました。
今回は後編ということで、導入してから開発中・リリース後の運用で分かった個人的ベストプラクティス・ハマりポイント等を残していこうと思います。
Project
まずはじめにGCPプロジェクトの構成です。
GCPはAWSの一般的なアカウントとは違い、組織が最初にあってその中にプロジェクトが属するスタイルです。
AWSでもAWS Organizationsという機能でアカウントの請求をまとめたり、環境ごとに権限を細かく管理できると思いますが、GCPでは最初から複数のプロジェクトを前提とした作りになっています。

多くのアプリケーションでは、開発・ステージング・本番など、環境を複数作ることがあると思います。
GCPではプロジェクトに切り替えは簡単にできるので、基本的には「環境ごとにプロジェクトを作成する」方針で行くといいと思います。
コンソールでのプロジェクトの切り替え方法は、画面上部のプロジェクト名をクリックするだけですね。
またコマンドでは、gcloud config set project $project_id とすることで、gcloudコマンドがactiveとするプロジェクトを設定することができます。
権限管理
IAM権限管理はプロジェクト単位でも可能ですし、フォルダと呼ばれるプロジェクトをグループ化した単位で設定可能です。
ということで現在はあるプロジェクトAを作る際は
- project-A(フォルダ)
- project-A-dev(プロジェクト: 開発環境)
- project-A-stg(プロジェクト: ステージング環境)
- project-A-prod(プロジェクト: 本番環境)
のように、フォルダを作って開発メンバーをそこに所属させ、メンバーごとにdev/stg/prodで権限を細かく付与させています。
逆にプロジェクト一つの中にdev/stg/prodのインスタンス等を作ると、権限管理が複雑化しがちになります。
プロジェクト名は一意な名前にしよう
プロジェクトにおける注意点としては、project_idはプロジェクト名とは違い、全世界でuniqueな文字列になります。
デフォルトのMy First Projectは当然ながらたくさんの人が作ってしまうため、eighth-anvil-xxxxとか適当な文字列がIDになります。
自分は最初の頃これによくハマって、コマンドでproject_idのところにプロジェクト名を指定してしまい、全然projectが切り替えられず悩むことが多々ありました。
プロジェクト名が一意になるように設定しておけばその辺りで悩むことはありません。
いい名前は取られてるケースが多いので、使いそうなプロジェクト名は先に押さえておくといいかもしれません笑
Google App Engine
続いて我らがPasS、App Engineです。
開発中は手動deployも可、落ち着いてきたら自動化しよう
最初触りながらGAEを試す場合は手元のコードを固めてdeployしてしまうのが最も簡単です。
gcloud app deploy はデフォルトではコマンドを実行した場所にあるDockerfileをビルドしてイメージ化し、それをGAE環境に構築してくれます。
なのでローカルでDockerベースで開発して、ある程度うまく動いたらdeployするサイクルを繰り返してさくさく確認していくのがいいと思います。
ただし編集中の状態のコードをdeployされると動かない可能性があるため、コマンドが終わるのを待っている間はボーッとするしかありません。
ある程度慣れてきたら、早いところdeployを自動化しておく方がよいかと思います。
自動化に関しては基本的にはGCPのCIサービス、Cloud Buildを使うことになると思います。
Github ActionsやCircleCIでもいいですが、権限管理が面倒な上に他のCIサービスに権限を渡すので漏洩リスクがあります。
Flexible Environmentはデプロイ時間がかかる
GAEにはStandard EnvironmentとFlexible Environmentがあるというのは前編の方で触れたのですが、FEのデメリットとしてdeploy時間がかかることがあげられます。
gcloud app deploy自体が内部でCloud Buildで実行されているのですが、Cloud Buildはデフォルトで10分で落ちてしまう仕様になっています。
長いなーと思って待っていたら、最後の最後に時間切れで落ちてしまってもう一度やり直し、といったことを何度もやりました。
実はこのデプロイ時間、設定で延長することができます。
cloudbuildでデプロイするにあたっては、基本的にcloudbuild.yamlを用意することになるかと思います。
yamlでtimeout: 1200sと設定しておくと20分にできたりするので、自動化の際はこれも設定しておきましょう。
steps:
- name: 'gcr.io/cloud-builders/gcloud'
args: 'app deploy app.yaml ...'
timeout: 1200s
バージョン固定をしておく
deploy時間がかかることで他にも問題が発生します。
以前書いた記事で少し触れたのですが、deploy中に別のdeployが走ると意図せずインスタンスが増えてしまう問題があります。
対策方法も書いていますが、
- cacheを導入してdeploy時間を短縮する
- versionを固定する
あたりをしておくだけでもだいぶ使い勝手は変わると思います。
バッチサーバーをGAEで使うときは生存管理に注意
webサーバーのようにhttpをlistenするスタイルではなく、プロセスを起動しておくスタイルのサーバーをGAEで起動するときは注意が必要です。
自分がハマったケースとしては、Railsのコードを通常のrails serverで動くwebサーバーと、sidekiqというジョブの非同期実行を行うバッチプロセスの2つの方法で動かしてました。
GAEはdeployごとにバージョンを持っていて、バージョンごとにサーバーを立てることができます。
GAEコンソール等で過去のバージョンの停止・削除を行うと画面上では削除の状態になりますが、実際には見た目よりも長くプロセスが生き残っています。
sidekiqはプロセスが生き続ける限りキューにあるジョブを取得して処理をしてしまうため、deploy直後に古いバッチプロセスがジョブを取ってしまい、古いコードのままで処理してしまってエラーということが結構発生しました。
webサーバーはアクセスの振り分けができるため、古いサーバーが生きていてもそちらにアクセスを送らなければ問題ありません。
ダウンタイムを許容するならプロセスを止めてからdeployすることもできますが、動いていない期間があるとまずいケースではGAEで動かすのは避けた方が良さそうです。
Cloud SQL
続いてDB周りです。
Cloud SQLは実は同じVPC内にない
一見Cloud SQLのインスタンスはproject内で作成するため自分たちのVPCに所属するかと思いきや、別のGoogleサービスのVPCに置かれることになるようです。
そのため同じVPCにあることを前提に設計してしまうと、あとで痛い目を見るかもしれません。
ただし、VPCピアリングの設定をすることで自分のVPCからprivate IPで接続することが可能です。

とはいえ公式はSQL Proxyベースでの接続を推奨しているため、基本的にはそちらを使った方が管理が楽になると思います。
ローカルからCloud SQL proxyで接続する
公式手順はこちらに記載されています。
# linux
$ wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy
# mac
$ curl -o cloud_sql_proxy https://dl.google.com/cloudsql/cloud_sql_proxy.darwin.amd64
# 両方とも
$ chmod +x cloud_sql_proxy
$ ./cloud_sql_proxy -instances=<INSTANCE_CONNECTION_NAME>=tcp:3306
接続時の注意点としては、最後に指定するport番号でローカルにプロセスを立ち上げるため、ローカルですでにmysqlを立ち上げていたりするとそことバッティングして立ち上げられなかったりします。
かぶった場合は3306以外のportを指定すればOKです。
気をつけていれば大丈夫かと思いますが、複数のプロジェクトを作る場合はハマる可能性もあるので注意です。
毎度立ち上げるのは面倒なので、MacであればLaunchctlに登録するなどして接続の自動化をしておくと楽です。
Redashから接続する
Redashは色々なデータベースの中身をグラフで見るのに便利なダッシュボードツールです。
Redashはデータソースと呼ばれるデータ置き場を設定し、そこに対してクエリを発行してデータを見れるようにしてくれますが、データソースにはCloud SQLも設定することができます。
直接Cloud SQLを設定できるわけではないですが、MySQLおよびPostgreSQLを選択できますので、
後は先程のSQL ProxyをRedashインスタンスに立ち上げておき、その接続設定をRedash側に登録すればOKです。
Redashは分析用途で重いクエリを発行することが多いので、本番DBとの接続にあたってはreplicaの方に向けておいた方が安全かと思います。
Cloud Functions
簡単な処理をさせたいときはCloud Functionsをよく使います。
前編でも触れましたが、無料枠がそれなりにあるのでSlack通知とかツール系でも活躍してくれます。
branch連携する場合、branch名に/が使えない
Cloud Functionsは反映する際に
- ソースコードを直接書いて反映
- ソースコードをzip化して反映(ローカルからとGCSから)
- Cloud Source Repository(GCPのレポジトリ、GitHubとも連携可能)で反映
という方法がありますが、多くの場合はGitOpsを考えて3番目のレポジトリ連携をするかと思います。
連携を行うとbranchをpushしたらそのままdeployさせる、といったことができるようになります。
$ gcloud functions deploy NAME \
--source https://source.developers.google.com/projects/PROJECT_ID/repos/REPOSITORY_ID/moveable-aliases/master/paths/SOURCE \
--runtime RUNTIME \
TRIGGER... \
[FLAGS...]
連携した後gcloud functions deployを使ってdeployを行いますが、このコマンドのSOURCEの部分に入るbranch名は/を含めることができないそうです。

Git Flowに従っている場合はfeature/xxxというようなブランチを作ることが多いと思いますが、Cloud Functionsへdeployする場合だけこの命名規則を変える必要があるため注意が必要です。
Cloud Storage
ストレージサービスのGCSです。
ファイルのバージョニングはコマンドから行う
誤って削除したり上書きしたりした際にもとに戻せるように、GCS上のファイルもバージョン管理をすることができます。
ただし、バージョン設定をしたりバージョンのファイルを確認したりするのはコマンドのみになります。
例えば設定のコマンドは以下のような形式になります。
$ gsutil versioning set on gs://[BUCKET_NAME]
基本的には誤った操作ミスを防ぐため消えてまずいファイルは設定しておいた方がいいかと思いますが、バージョンごとにファイル数カウントされるため、ファイル数が多いサービスを検討している場合は注意が必要です。
幸いバージョニングされたファイルに対してライフサイクル処理を設定できるので、バージョン数が一定増えたら古いものを削除するなどの設定をしておくのが良いかと思います。
CloudBuild
GCPのCI/CDサービス、CloudBuildです。
個人的にはGCPを使って一番色々試したのがCloudBuildかもしれません。
最近はGitHub Actionsが登場してGitOps関連はActionsにまとめることが増えてきましたが、権限管理の観点でGCPサービスを扱う処理を自動化する場合は引き続きCloudBuildを使うことが多いです。
ビルドの並列処理が可能
以前書いた記事で少し触れたことがあるのですが、CloudBuildではstepという単位で処理を並べていきます。
このstepは waitFor というオプションによって順序を制御することができます。
steps:
- id: 'build'
name: 'gcr.io/cloud-builders/docker'
args: ['build', '--no-cache', '-f', 'docker/Dockerfile.migrate',
'-t', 'gcr.io/$PROJECT_ID/migration:$_TAG', 'database/']
- id: 'cloudsql-proxy'
name: 'gcr.io/cloudsql-docker/gce-proxy'
entrypoint: 'sh'
args: ['-c', '/cloud_sql_proxy -dir=/cloudsql -instances=$_CLOUD_SQL_CONNECTION_NAME & while [ ! -f /cloudsql/stop ]; do sleep 2; done']
volumes:
- name: cloudsql
path: /cloudsql
waitFor:
- '-'
- id: 'migration'
name: 'gcr.io/cloud-builders/docker'
args: ['run', '-e', 'CLOUD_SQL_DSN=$_CLOUD_SQL_DSN',
'-v', 'cloudsql:/cloudsql', # volumeはhost側はpathではなくnameを指定しろとのこと
'gcr.io/$PROJECT_ID/migration:$_TAG']
volumes:
- name: cloudsql
path: /cloudsql
waitFor:
- 'build'
- name: 'gcr.io/cloud-builders/docker'
entrypoint: 'sh'
args: ['-c', 'touch /cloudsql/stop']
volumes:
- name: cloudsql
path: /cloudsql
waitFor:
- 'migration'
substitutions:
_TAG: 'latest'
_CLOUD_SQL_CONNECTION_NAME: '' # required
_CLOUD_SQL_DSN: '' # required
images:
- 'gcr.io/$PROJECT_ID/migration:$_TAG'
こちらは以前の記事で紹介したマイグレーションに関するコードですが、何をやっているかはさておきwaitForを指定している箇所がいくつかあります。
文字列を指定しているstep(buildやmigrationなど)に関しては別のstepのidを指定することで、そのstepが終わった後に処理をするというstepの直列化ができます。
反対に、-を指定している2番目のstepは開始と同時に実行することを意味します。
このためwaitFor: '-'を指定したstepは並列実行させることができます。
とはいえそこまで並列実行をしたい場面は多くないと思いますので、できるんだくらいでとどめておいていいかもしれません。
GitHub Checksとの連携は組織で一つのGCPプロジェクトしか設定できない
GitHubとCloudBuildの連携には CloudBuildトリガー と GitHub Checks という2種類の方式があります。
CloudBuildトリガーはGCPのプロジェクトごとに、好きなレポジトリを指定して連携することができます。
しかしGitHub Checksでは、チームごとにプロジェクトとレポジトリを持っていても、全レポジトリをある一つのGCPプロジェクトに紐付ける必要があります。
Github Checks
GitHub Checksとはpushしたbranchのcommitに対してCIの結果をGitHub上で教えてくれるもので、最近ではこれを元にPull Requestのマージ許可を出す等の設定もできたりします。

CloudBuildもCIサービスということでChecksに登録することができますが、実際にCI処理を走らせるGCPプロジェクトは全てのレポジトリで一つということになります。
これは、ChecksがGitHubの外部アプリで実現しており、アプリでは同じサービスを一つしか登録できないという仕様のためかと思われます。
例
例えばチームAとチームBがいて、レポジトリa-appとb-serviceを管理し、GCPプロジェクトproject-aとproject-bでそれぞれ動かしているとします。
通常はa-appはproject-aのCloudBuild、b-serviceはproject-bのCloudBuildに設定をしたいところですが、GitHub Checksはどちらかのプロジェクトに寄せる必要がでてきます。
なお、トリガーはそれぞれのプロジェクトで設定が可能です。
チーム数が多い組織の場合はこの辺りの統一を図っておくことが良さそうです。
VISITS社の場合、共有用のGCPプロジェクトを作りそこで動作させるようにしています。
共有プロジェクトは他にもチーム横断で使うファイルやdockerイメージを共有するなど便利な場面は多いので、作成して損はないかなと思います。
レポジトリごとにカスタマイズは可能、ただしレポジトリ構成に注意
とはいえChecksで走るCIはレポジトリごとにカスタマイズは可能です。
どんなCIを走らせるかはGCPプロジェクト側で設定することはできず、各レポジトリにあるcloudbuild.yamlまたはyamlがなければDockerfileをビルドしてその成否で判断されます。
このため、レポジトリによって実行内容を設定してしまえば実質的な問題はあまりありません。
ちなみにこのcloudbuild.yamlやDockerfileは レポジトリのルート直下 にあるファイルしか対象となりません。
このため1レポジトリで実行できるChecks用のCIは1種類となってしまいます。
cloudbuild.yamlを工夫すれば複数走らせることも可能ですが、そんな厄介なCI管理をするのは本末転倒になりそうです。
レポジトリで複数のChecksを走らせたい場合は、そもそもコードを分割するなどレポジトリ構成を考慮するか、無理せず別のCIサービスを使うことをオススメします。
PubSub
非同期処理を行うなら欠かせないメッセージキューサービスです。
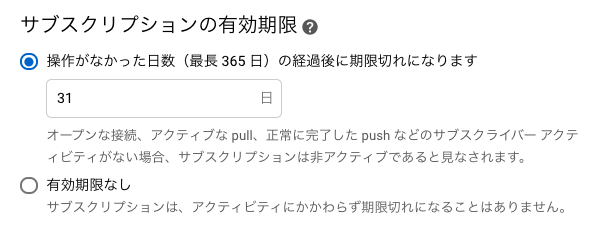
サブスクリプションの有効期限に注意
かつてはサブスクリプションが1ヶ月間呼ばれないと、自動的に削除する仕組みになっていました。
このため、あまり呼ばれないサブスクリプションは勝手になくなってしまい、かつそのことに気づかず正常に動いてくれると思い込んでしまうケースがよくありました。
staging環境など比較的使用頻度の低い環境や、そもそも呼ばれにくいトピックなどはこちらに注意する必要があります。
現在は、有効期限を無制限にするオプションがついていますが、defaultでは自動削除になっているのでよほどのことが無い限り無制限に変更しておきましょう。
Cloud Functionsの関数サブスクライバに指定する場合、同じ関数を複数のトピックに紐付けられない
PubSubのサブスクライバはAPI形式であればだいたい設定できるので、Cloud Functionsの関数も選択することができます。
ただし、1関数は1つのトピックにしか紐付けられないため、複数のトピックで同じ処理をさせたい関数があったとしても、それぞれ別の関数としてdeployしてそれぞれのトピックに結びつける必要があります。

自分の場合、トピックが呼ばれた後slackに通知したかったので通知用関数を実装したのですが、この通知関数を複数のトピックに紐付けられず、結局トピック分だけ関数を作成する羽目になってしまいました。
トピックをまとめるのはそれはそれでPubSub周りの設計の変更が必要になるので、PubSubで横断的な処理をCloud Functionsにさせようと検討している方はご注意ください。
Logging
AWSのCloudWatch Logsに該当するのはLoggingサービスです。
デフォルトではそんなに見やすくないのは、AWSと同じです。。
GAEのログを拾う場所に気をつける
GAEのログは(GAEに限らずですが)特定のディレクトリに吐いたログまたは標準出力をLoggingにエントリしてくれます。
設定方法に関しては素晴らしい記事があるので、そちらに譲りたいと思います。
基本的には /var/log/app_engine/custom_logs/ 以下にカスタムログとしてファイル出力すれば後はよしなにやってくれるという感じです。jsonファイルにjson形式で吐き出すと、jsonでドットつなぎで検索することもできて大変便利です。
標準出力のログエントリは注意
ちなみに標準出力(エラー出力も)の方もログエントリしてくれますが、動作が不安定だったりします。
Railsのproductionモードで動かした場合にはnginxのアクセスログに紐づけてくれるという素敵仕様になっていたのですが、developmentモードでは動いてくれません。また同じような構成をしている別プロジェクトでも動いてくれませんでした。
もしかしたら標準出力ではなくrubyのgemの方でやっている可能性もあるのですが、まだそこまで調査はできていないためキーとなる設定が判明したら共有したいと思います。
また構造化ロギングによって標準出力でjson形式で吐き出すとjsonでログエントリしてくれると記載があったりしますが、実際にはうまく動きませんでした。
GAEやGKEなどgoogle側が管理しているフルマネージド系では中身の設定がどうなっているのかいまいち追いづらいところがあるため、無理せずカスタムログによるエントリを検討することをオススメします。
おわりに
後編はかなり個別具体論っぽくなってしまいましたが、ここ1-2年GCPの色々な機能を使ってみて得た知見の共有でした。
最近AWSを使っていないのであまり比較の形で書けず恐縮ですが、ある程度注意したりときにハマって調べたりすればGCPでも全然やっていけると思ってます(というか思いたい)。
最近ではGAになったCloud Runが気になっていて、Dockerベースのインフラ構築がますます捗ってきています。
すでに一部では本番でも使っているのですが、とにかくdeployが速いのでサービスで使えそうならdeployの遅いGAEを代替できる可能性もあるかもしれません。
GKEに関しては取り組み始めということで分からない部分も多くそこを攻略しないとGCPを使い倒したと言えないので、また知見が貯まったら共有したいと思います。