概要
Datadogは柔軟にダッシュボードを作成することができますが、
ダッシュボードを作成しようとすると選択肢が2つ出てきます。
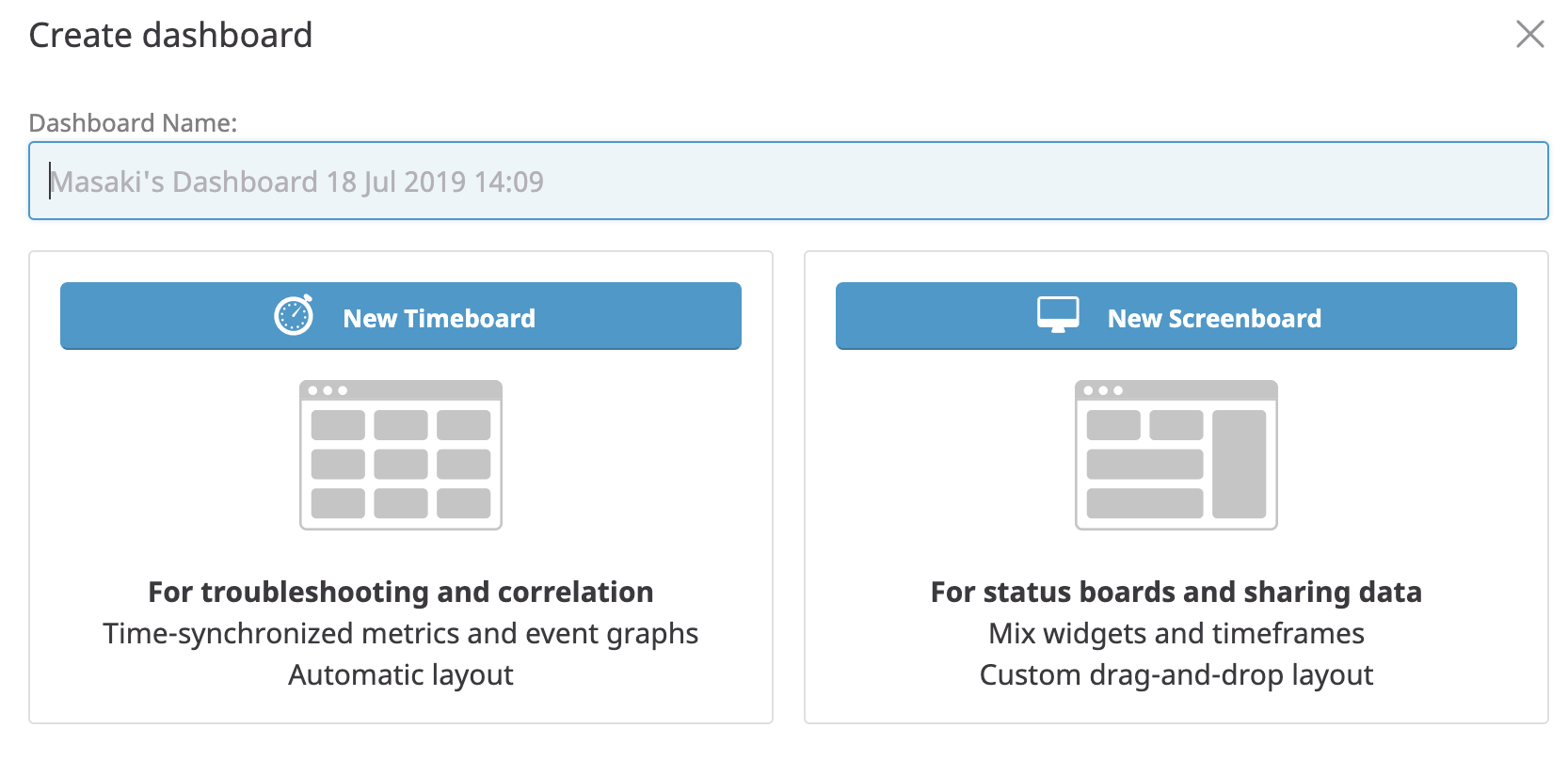
最初はこの2つの違いをよく理解できていないかったので、どっちを使えばいいだ?ってなってましたが、
使ってるうちに**「 Timeboard 便利やん!」**となったのでご紹介です。
ダッシュボードの概要
Screenboardについて
For status boards and sharing data とあるようにサービスのステータスがパッと一目で把握できるためのダッシュボードとして使っています。
例えば、各プロダクトごとのSLOの達成状況や外形監視(Synthetics)の結果、レスポンスタイム、エラーレイトといった値を可視化し、パッと見ただけでサービスの異常がざっくりと分かる作りにしています。
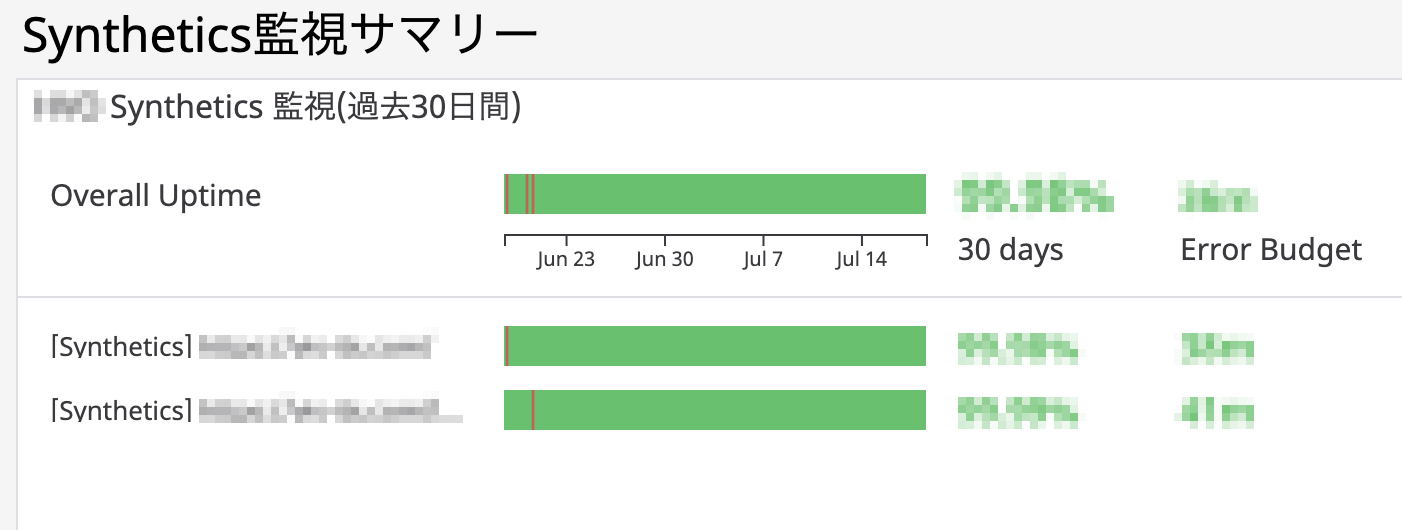
少し話がそれますが、最近SLOの機能がリリースされたので、このSLOの達成状況をダッシュボードで表示してたりします。
例 SLO)
Timeboardについて
For troubleshooting and correlation とあるように主にトラブルシューティング時のダッシュボードとして使用しています。
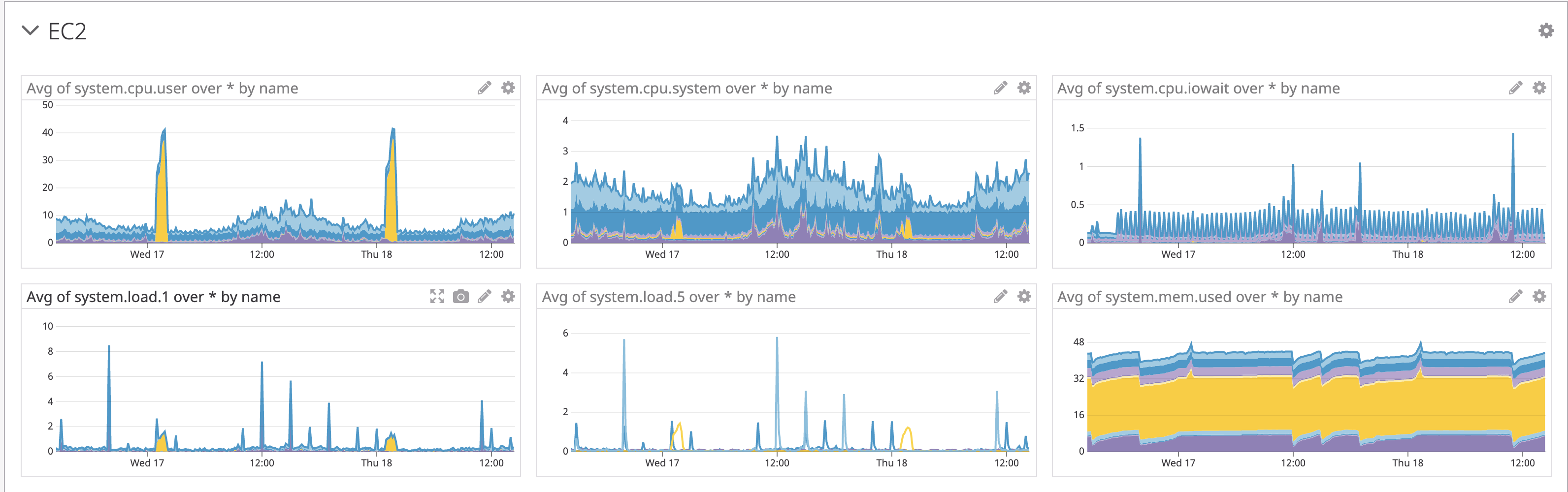
AWSをDatadogで監視している場合、ALB、EC2、RDSのメトリクスを取っているかと思いますが、それをこのTimeboard上に配置してます。
例 EC2のメトリクス)
Timeboardの何がうれしいか
ここがいいなと思ったところなんですが、Datadog上で発生したイベントの発生時刻をTimeboard上の各種メトリクスにオーバーレイすることができます。
例えば、Dagtadogで設定した「Response Time」のアラートが発生した場合、そのアラートを検索窓で検索することで各種メトリクス上に発生時刻をオーバーレイします。
例 検索窓)
例 Response Timeの検索結果)
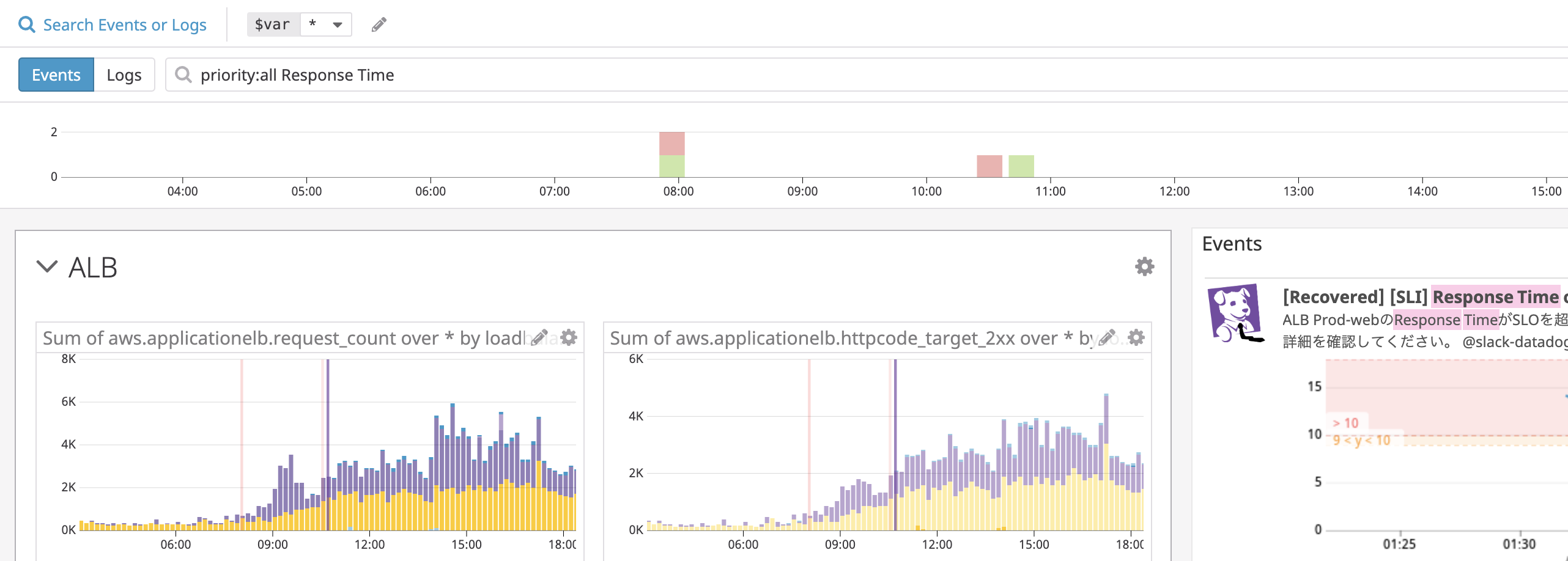
この例だと、左のピンク線がアラート発生時刻で、右のピンクの線がアラート復旧時刻となります。
このTimeboard上にEC2やRDSといった関連しそうなメトリクスを配置しておけば、アラート発生・復旧時刻と各種メトリクスがオーバーレイされ、相関が可視化できるため、トラブルシューティング時に役に立つことがあります。
まとめ
今まであるようでなかったこの機能、トラブルシューティングにとても役に立ちます。
トラブルシューティング時に役に立ったメトリクスをどんどん追加して、育てていく感じで徐々にブラッシュアップしていくことをオススメします。