本記事について
前の記事からの続きです。
畳み込みニューラルネットワーク(CNN)を使って、画像の分類をしてみたいと思います。
本記事のその1で、ニューラルネットワークによる手書きの数字画像の分類を行いましたが、
CNNではより精度の高い分類が可能です。
畳み込みニューラルネットワーク(CNN)って?
画像を扱う際に最もよく用いられている深層学習モデルの1つです。
通常のニューラルネットワークに加えて、
「畳み込み」という処理を加えるため、「畳み込みニューラルネットワーク」と言います。
「畳み込み処理」ってなに?
近年、スマホのカメラも高画質になって1枚で数MBもあります。
これをそのまんま学習に利用してしまうと、容量が多すぎてとても時間がかかります。
学習の効率を上げるために、画像の容量を小さくする必要があります。
しかし、ただ容量を小さくするだけではダメです。
小さくすることで画像の特徴が無くなってしまうと
なんの画像かわからなくなり、意味がありません。
__畳み込み処理とは、元の画像データの特徴を残しつつ圧縮すること__を言います。
具体的には、以下の手順になります。
- 「畳み込み層」で画像を「カーネル」という部品に分解する。
- 「カーネル」をいくつも掛け合わせて「特徴マップ」を作成する。
- 作成した「特徴マップ」を「プーリング層」で更に小さくする。
最後に1次元の配列データに変換し、
ニューラルネットワークで学習するという流れになります。
構築環境について
今回の記事では、Google Colaboratory環境下で実行します。
また、tensorflowのバージョンは1.13.1です。
ダウングレードする場合は、以下のコマンドでできます。
!pip install tensorflow==1.13.1
ライブラリのインポート
今回もtensorflow.kerasを使っていきます。
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Activation, Dense, Dropout, Conv2D, Flatten, MaxPool2D
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
画像データの準備
画像データはcifar10ライブラリでダウンロードします。
(train_images, train_labels)は、訓練用の画像と正解ラベル
(test_images, test_labels)は、検証用の画像と正解ラベルです。
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
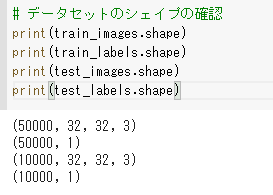
データセットのシェイプの確認をします。
32ピクセルのRGB画像(32×32×3)が訓練用は5万件、検証用は1万件あることがわかります。
画像の中身も確認してみましょう。

画像の正解ラベル↓

それぞれの数字の意味は以下になります。
ラベル「0」: airplane(飛行機)
ラベル「1」: automobile(自動車)
ラベル「2」: bird(鳥)
ラベル「3」: cat(猫)
ラベル「4」: deer(鹿)
ラベル「5」: dog(犬)
ラベル「6」: frog(カエル)
ラベル「7」: horse(馬)
ラベル「8」: ship(船)
ラベル「9」: truck(トラック)
データセットの前処理
train_imagesの中身は以下のように
0~255の数値が入っています。(RGBのため)

これを正規化するために、一律255で割ります。
通常のニューラルネットワークでは、
訓練データを1次元に変更する必要がありましたが、
畳み込み処理では3次元のデータを入力する必要があるため、正規化処理だけでOKです。
train_images = train_images.astype('float32')/255.0
test_images = test_images.astype('float32')/255.0
また、正解ラベルをto_categoricalでOne-Hot表現に変更します。
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
モデル作成
モデル作成は以下のコードです。
model = Sequential()
# 畳み込み処理1回目(Conv→Conv→Pool→Dropout)
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 畳み込み処理2回目(Conv→Conv→Pool→Dropout)
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# ニューラルネットワークによる分類(Flatten→Dense→Dropout→Dense)
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
1つ1つ解説します。
まず、model = Sequential()でシーケンシャルモデルを作成します。
次に、畳み込み処理です。
今回は畳み込み処理を2回やった後に、
ニューラルネットワークによる分類を行いたいと思います。
1回目の畳み込み処理の説明をします。
まず、model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))で
畳み込み層を作成します。
Conv2Dにカーネル数、カーネルサイズ、活性化関数、パディング、入力サイズを渡しています。
カーネル数が32、サイズは3×3、活性化関数はrelu、パディングのsameは作成した特徴マップを0で囲うという処理です。
上記処理で作成した特徴マップを
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))で
更に畳み込み層で特徴を抽出した特徴マップを作成します。
次はプーリング層です。
model.add(MaxPool2D(pool_size=(2, 2)))で画像を圧縮します。
MaxPool2DとはMAXプーリングという方式のことを言います。
サイズは圧縮後のサイズです。
最後に、
model.add(Dropout(0.25))でドロップアウトで無効化処理をして、
畳み込み処理の1回目が終了です。
これと同じ処理をもう1度実施してから、
model.add(Flatten())で1次元に変換し、
通常のニューラルネットワークの分類予測を行います。
TPUモデルへの変換処理
モデルのコンパイル、の前に
作成したモデルをTPUモデルに変換します。
今のままでもコンパイルも学習も可能ですが、
畳み込みニューラルネットワークは膨大な量の計算が発生するため、
TPUでの処理しないととても時間がかかります。
以下の手順で変換してください。
# TPUモデルへの変換
import tensorflow as tf
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
モデルのコンパイル
損失関数は、分類に向いているcategorical_crossentopy、
活性化関数はAdam(学習率は0.001)、評価指数はacc(正解率)に設定します。
tpu_model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
学習
作成したモデルで学習します。
TPUモデルで学習する場合、1回目は結構時間がかかりますが、2回目以降は速いです。
もしTPUじゃなく、通常のモデルで学習したら、倍以上の時間がかかると思います。
history = tpu_model.fit(train_images, train_labels, batch_size=128,
epochs=20, validation_split=0.1)
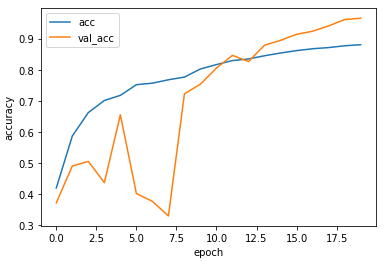
学習結果をグラフ表示
正解率が9割を超えているようです。
かなり精度が高いですね。
plt.plot(history.history['acc'], label='acc')
plt.plot(history.history['val_acc'], label='val_acc')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
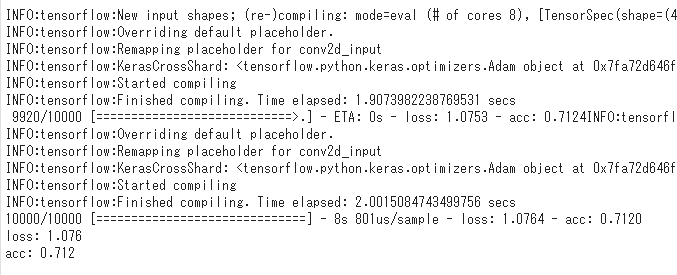
学習の評価
検証データで試すと、正解率が71.2%まで落ちました。
新しい画像だと、あまり精度が高くないので、改善の余地がありそうです。
test_loss, test_acc = tpu_model.evaluate(test_images, test_labels)
print('loss: {:.3f}\nacc: {:.3f}'.format(test_loss, test_acc ))
推論
最後に、推論です。
実際に画像を渡してどんな予測がされているか確認します。
Google ColabのTPUは8コアで構成されている関係で、
8で割り切れる数で学習しなければいけません。
そのため、学習データは16にしたいと思います。
# 推論する画像の表示
for i in range(16):
plt.subplot(2, 8, i+1)
plt.imshow(test_images[i])
plt.show()
# 推論したラベルの表示
test_predictions = tpu_model.predict(test_images[0:16])
test_predictions = np.argmax(test_predictions, axis=1)[0:16]
labels = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
print([labels[n] for n in test_predictions])

画像が小さくてよく分かりにくいですが、
予測できているようです。
次回は、同じ画像データをResNetというCNNで予測してみたいと思います。