本記事について
前の記事からの続きです。
畳み込みニューラルネットワークの一種であるResNetを使って、
画像の分類をしてみたいと思います。
ResNetは前回記事でやった畳み込みニューラルネットワークのアルゴリズムの一種です。
2015年にマイクロソフトが発表し、その後、囲碁の世界チャンピオンを倒したAlphaGOという囲碁AIで使われました。
そんな凄いアルゴリズムを使って、
前回記事と同じく画像の分類をやってみたいと思います。
今までの畳み込みニューラルネットワークとどう違うの?
畳み込みニューラルネットワークは、畳み込み処理を増やせば増やすほど、複雑な特徴を認識しやすくなります。
しかし、過学習も起こりやすく、増やすことで結果が悪化することもしばしばあります。
ResNetでは残差ブロックというショートカット構造を追加することで、この問題を対処しています。
残差ブロックってなに?
畳み込み処理の前に、ショートカットコネクションと呼ばれる迂回経路を作成し、学習が不要になったら、畳み込み処理を行わないで、次の層に移動する構造体のことをいいます。
回帰予測の際に、EarlyStoppingで学習中に改善が見られなかったら指定されたエポック数に達してなくても中断するという処理を作成しましたが、それを畳み込み層のレイヤーで行うイメージです。
ResNetには、PlainとBottleneckという2つのアーキテクチャがあります。
今回はBottleneckというアーキテクチャを使って分類予測を行います。
Bottleneckアーキテクチャによる残差ブロックは以下のような構造になっています。
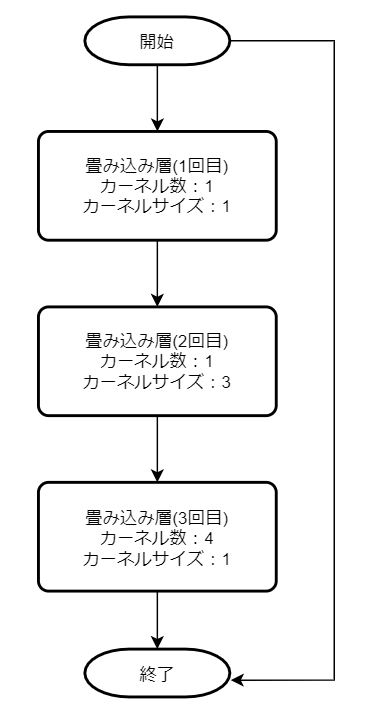
1回目を、カーネル数x,カーネルサイズyとすると
2回目は、カーネル数x,カーネルサイズ3y
3回目は、カーネル数4x,カーネルサイズy
パッケージのインポート
tensorflowは1.13.1を利用するので、以下のコマンドでインストールしてください。
!pip install tensorflow==1.13.1
インストールしたらライブラリをインポートします。
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
データセット
データは前回のCNNと同じcifar10を利用します。
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
model作成
FunctionalAPIでのモデル作成
今回のmodelは複雑な分岐や複数の出力があるため、
Sequentinalではなく、FunctionalAPIというネットワーク構造で構築します。
FunctionalAPIは、
Sequentinalのようにmodel.addでモデル自体に層を追加して作りこんでいくのではなく、
作成した層を次の層に渡し、最終的にmodelへ渡す方式で作りこんでいきます。
具体的には、以下のように書きます。
※FunctionalAPIの例示なので、下記コード自体は本プログラムには利用しません。
input = Input(Shape=(784,)) #入力層
x = Conv2D(64, (3, 3), activation='relu', padding='same')(input) #末尾に入力層を追記して渡す
x = MaxPool2D(pool_size=(2, 2))(x) #末尾に前の層(x)を追記して渡す
model = Model(inputs=input, outputs=x) #モデル作成
Sequentinalモデルは、model.addの中にConv2Dなどの層を追加していく方式でしたが、
FunctionalAPIでは、model.addではなく、次の層の末尾に()で囲って渡します。
畳み込み層の作成
今回は、畳み込み層を繰り返し利用するので、関数化します。
def convという関数を作成しましょう。
def conv(filters, kernel_size, strides=1):
return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False,
kernel_initializer='he_normal', kernel_regularizer=l2(0.0001))
filters:カーネル数
kernel_size:カーネルサイズ
strides:ストライド数(特徴マップ作成の際にどれだけズラして設定するかの数値)
strides:パディング方式
use_bias:バイアスを加えるかどうか
kernel_initializer:重み行列の初期値。he_normalだと正規分布。
kernel_regularizer:重みに適用させるペナルティの正則化方式。L2正則化を利用。
1回目に実行する残差ブロックを作成
今回、カーネル数の異なる残差ブロックを3種類作成するのですが、
それぞれの残差ブロックを18回処理したいと思います。
※18回×3種類の残差ブロックを作成
18回処理するにあたり、1回目の残差ブロックと2回目以降の残差ブロックでは処理内容が微妙に異なります。
分かりやすくするために、1回目の残差ブロックと2回目以降の残差ブロックを分けたいと思います。
# 1回目に実行する残差ブロック
def first_residual_unit(filters, strides):
def f(x):
# →BN→ReLU
x = BatchNormalization()(x)
b = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 1, strides)(b)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→
x = conv(filters, 1)(x)
# ショートカットのシェイプサイズを調整
sc = conv(filters, 1, strides)(b)
# Add
return Add()([x, sc])
return f
残差ブロックのコードを解説します。
x = BatchNormalization()(x)は学習を最適化する処理です。
使うタイミングは2パターンあります。
残差ブロックの一番最初に実行するパターンと、
畳み込み層と活性化関数の間にサンドイッチするパターンです。
Dropoutと併用はしない方が良いと言われていますので、今回Dropoutは利用していません。
次に、b = Activation('relu')(x)で活性化関数を適用します。
次に畳み込み層へ行くのですが、この時点で学習が不要だった場合は、Addまでジャンプします。
これが前述に記載したショートカット構造です。
x = conv(filters // 4, 1, strides)(b)から畳み込み層になるのですが、
filters(カーネルサイズ)を4で割った商にしています。
これは、Bottleneckアーキテクチャを利用しているためです。
3回目の畳み込み層では割らずに処理しているのが分かるかと思います。
1回目を、カーネル数x,カーネルサイズyとすると
2回目は、カーネル数x,カーネルサイズ3y
3回目は、カーネル数4x,カーネルサイズy
sc = conv(filters, 1, strides)(b)では、
ショートカットをxと同じサイズに調整しています。
最後にreturnで返して、1回目の残差ブロックは終了です。
2回目以降に実行する残差ブロック
続いて、2回目以降に実行する残差ブロックです。
引数にはstridesは不要です。
ショートカットのshape数調整は、前の層で実施済みなので不要です。
そのほかの処理は1回目と変わりません。
# 2回目以降に実行する残差ブロック
def residual_unit(filters):
def f(x):
sc = x
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→
x = conv(filters, 1)(x)
# Add
return Add()([x, sc])
return f
指定した回数分の残差ブロックを実行する関数を作成する
1回目のみ実行と、2回目以降実行する残差ブロック作成関数が出来たので、
この2つを組み合わせて、指定した個数分の残差ブロック作成関数を作成します。
# 指定した回数分の残差ブロックを実行する関数
def residual_block(filters, strides, unit_size):
"""
filters:カーネル数
strides:ストライド数
unit_size:残差ブロックの実行回数
"""
def f(x):
#1回目に実行する残差ブロック
x = first_residual_unit(filters, strides)(x)
#2回目以降の残差ブロック(すでに1回実行しているので、unit_sizeから1を引く)
for i in range(unit_size-1):
x = residual_unit(filters)(x)
return x
return f
モデル作成
前準備が完了したので、モデル作成を行います。
以下の流れで作成します。
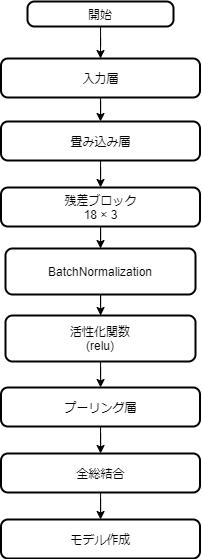
GlobalAveragePooling2Dの出力は1次元になるため、
全総結合の前にFlattenで1次元に変換する必要はありません。
# 入力データのシェイプ(入力層)
input = Input(shape=(32,32, 3))
# 畳み込み層(inputを渡す)
x = conv(16, 3)(input)
# 残差ブロック 18 × 3
x = residual_block(64, 1, 18)(x)
x = residual_block(128, 2, 18)(x)
x = residual_block(256, 2, 18)(x)
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
# プーリング層
x = GlobalAveragePooling2D()(x)
# 全結合層
output = Dense(10, activation='softmax', kernel_regularizer=l2(0.0001))(x)
# モデルの作成
model = Model(inputs=input, outputs=output)
TPUモデルへの変換
TPUモデルに変換する場合は、以下のコード
(※tensorflow1.13.1のコードです。)
import tensorflow as tf
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
モデルのコンパイル
tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc'])
正規化処理と画像の水増し
ImageDataGeneratorを使って画像データを正規化し、
画像の水増しをします。(水増しは訓練データのみ)
正規化の後は、fitを使って統計量の計算を行います。
5万枚も画像があるので水増しの必要があるの?
と思うかもしれませんが、1種類につき5千枚しかないので
水増しをしておいた方が良いです。
# 訓練データの正規化と水増し処理
train_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
width_shift_range=0.125,
height_shift_range=0.125,
horizontal_flip=True)
# テストデータの正規化処理(水増しは意味がないのでしない)
test_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
# データセット全体の統計量を予め計算
for data in (train_gen, test_gen):
data.fit(train_images)
学習
ようやくモデルの作成もデータの前処理も終わったので、学習を開始します。
学習率の変更
今回、学習するにあたって、LearningRateSchedulerを利用して
エポック数ごとに学習率を変更したいと思います。
1~79までは学習率0.1、
80~119は学習率0.01、
120以上は0.001と回数ごとに小さくすることで、
学習時間を短縮することが出来ます。
# LearningRateSchedulerの準備
def step_decay(epoch):
x = 0.1
if epoch >= 80: x = 0.01
if epoch >= 120: x = 0.001
return x
lr_decay = LearningRateScheduler(step_decay)
学習の実行
学習を実行します。
今回は画像の水増しを行っているので、
ちょっとオプションが多めです。
# 学習
batch_size = 128
history = tpu_model.fit_generator(
train_gen.flow(train_images, train_labels, batch_size=batch_size),
epochs=100,
steps_per_epoch=train_images.shape[0] // batch_size,
validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size),
validation_steps=test_images.shape[0] // batch_size,
callbacks=[lr_decay])
今回の学習は1時間程度かかります。
学習が完了したら、グラフで学習結果を表示します。
plt.plot(history.history['acc'], label='acc')
plt.plot(history.history['val_acc'], label='val_acc')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
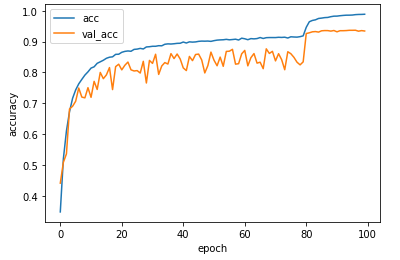
学習の評価
test_imagesで学習の評価をしましょう。
前回のCNNでは、正解率71.2%でした。
Resnetではどうなるでしょうか。
batch_size = 128
test_loss, test_acc = tpu_model.evaluate_generator(
test_gen.flow(test_images, test_labels, batch_size=batch_size),
steps=10)
print('loss: {:.3f}\nacc: {:.3f}'.format(test_loss, test_acc ))

なんと、成果率93.4%!
従来のCNNと比べて劇的に改善しました。
推論
個別の画像での予測結果も念のため確認しましょう。
# 推論する画像の表示
for i in range(16):
plt.subplot(2, 8, i+1)
plt.imshow(test_images[i])
plt.show()
# 推論したラベルの表示
test_predictions = tpu_model.predict_generator(
test_gen.flow(test_images[0:16], shuffle = False, batch_size=16),
steps=16)
test_predictions = np.argmax(test_predictions, axis=1)[0:16]
labels = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
print([labels[n] for n in test_predictions])

モデルの保存
Google colaboratory上にあるmodelを、
以下のコードでローカル環境にダウンロードしましょう。
# モデルの保存
tpu_model.save('resnet.h5')
# モデルをローカル環境にダウンロード
from google.colab import files
files.download( "resnet.h5" )
長くなりましたが、以上になります。