エイチームフィナジーアドベントカレンダー最終日はs2terminalが担当します。私は普段、Web開発やデータサイエンス等を担当していますが、今年は 自然言語処理 技術に多く触れていました。
本稿では自然言語処理を用いて、「プリン」 に関する文書が私の大好きなポケモンのプリンを指しているのかどうかを分類します。自然言語処理技術の中でも古典的な手法である BoW と、比較的新しい BERT を用いて、すばやく正確に分類できること目指します。
プリンとは
プリン(Jigglypuff) とは、ポケットモンスター(以下ポケモン)に登場するキャラクターです。図鑑番号39。分類は「ふうせんポケモン」であり、その名の通り球状の体型をしています。全身ピンク色で大きな瞳が特徴のかわいいポケモンです。進化前の姿はププリン、進化後はプクリンとなります。
プリンは2021年「ポケモンユナイト」1にプレイアブルキャラクターとして登場。対戦環境の上位で活躍し続けました。
また「ポケットモンスター ブリリアントダイヤモンド・シャイニングパール」2においても、スーパーコンテストのゲージアイコンとして抜擢されました3。ポケモンにおけるこういうアイコン的な役割はだいたいピカチュウが担っている事を鑑みると、ここでプリンが使われている事はプリンの人気の高さやアイコンとしてのかわいさを象徴していると言えるでしょう。
このように2021年プリンは大活躍しており、2021年はプリンの年だったと言っても過言ではありません。そのためおそらくインターネット上にはプリンに関するブログ投稿等の文書で溢れかえっており、それらが本当にポケモンのプリンであるかどうか分類する問題の重要性も高まるのではないか?と考えました。
ポケモン以外のプリンについて
ポケモン以外の「プリン」と言われると、洋菓子の カスタードプディング(custard pudding) を指すことが一般的です。あまくてやわらかい黄色の食べ物です。
語義曖昧性解消
以上で述べた「プリン」のように、複数の意味をもつ語を 多義語(polysemic word) や 同音異義語(homonym) とよびます4。あるテキスト内で使われている多義語の意味を、複数の中から適切に選択する問題を 語義曖昧性解消(Word-Sense Disambiguation, WSD) とよびます。
Wikipediaにおいては「曖昧さ回避のためのページ」として複数の語義が示されており、これらから適切なものを選択します。
本稿では語義曖昧性解消のタスクとして、「"プリン"という語が含まれる文が与えられたとき、それがポケモンのプリンを指しているかどうか」を、自然言語処理技術を用いて判断してみます。
語義曖昧性解消の例
いくつかの例文を挙げるので、それが「ポケモンのプリンの話をしているのかどうか」を考えてみましょう。
「プリンうまかった」
これは「カスタードプディングを食べて、それがおいしかった(旨かった)」というように解釈できるため、ポケモンのプリンではない、と判断できます。
「相手のプリンうまかった」
これは「ポケモンユナイト」や「大乱闘スマッシュブラザーズ」のようなポケモンのプリンが活躍する対戦ゲーム5をプレイして、「対戦相手が上手だった(上手かった)」というように解釈できるため、ポケモンのプリンである、と判断できます。
「プリンかわいい」
これは「キャラクターのプリンがかわいい」と解釈できるため、ポケモンのプリンである、と判断できます。
「セブンイレブンのプリンかわいい」
これは「コンビニのセブンイレブンで販売しているプリンがかわいい」と解釈できるため、コンビニで日常的に販売されているカスタードプディングの話でありポケモンのプリンではない、と判断できます。
ですが、 セブンイレブンオリジナル ポケモン ジッパーバッグプレゼント!キャンペーン6のプリン の話だと解釈した場合は、同じ文でもポケモンのプリンであると判断されます。
このように「プリン」という語が登場する文において、周辺の語句が少し変化するだけでもそれがポケモンなのかどうか解釈が変わること、また文だけで曖昧性を完全に解消することは難しい時がある事がわかると思います。
実装の方針
語義曖昧性解消はテキストの分類問題として実装できます。
- 「ポケモンのプリンに関する文」と「ポケモンではないプリンに関する文」を、データとして作成
- 自然言語処理で前処理
- 機械学習で分類モデルを作成
本稿では機械学習については深く触れず、自然言語処理技術を中心に紹介していきます。
環境
- CPU Ryzen 5 3600 6コア
- 32GB RAM
- Windows 11 WSL2 Debian bullseye
- Docker version 20.10.11
- Python 3.10
2021年10月にリリースされた記事執筆時点での最新版であるPython3.10を用いており、対応していない一部ライブラリの利用に制約を受けています7。実際に利用したライブラリの一覧を含む全体のソースコードはGitHubに公開しています。(後述しますが、本稿における結果の再現を保証するものではありません)
データの作成
データはTwitter APIを利用して収集しました。「プリン」を含むツイートを取得し
- 「ポケモンのプリンに関するツイートである」ならば「1」
- 「ポケモンのプリンに関するツイートではない」ならば「0」
を、筆者の手作業によって注釈付与したデータセットを用意します。
...が、 「ポケモンのプリン」に関するツイートがあまりにも少なかった ため、機械学習をうまく進めるにはデータを増やす必要があると判断しました。そこで「ポケモンのプリンである」文として、プリンの進化前「ププリン」および進化後「プクリン」に関するツイートも収集し、「ププリン」「プクリン」を「プリン」に置換し、すべて「ポケモンのプリンに関するツイートである」と注釈付与する事によって、データを増やしました。
なおこの時点で、冒頭に挙げた「インターネット上にはプリンに関するブログ投稿等の文書で溢れかえっており、それらが本当にポケモンのプリンであるかどうか分類する問題の重要性も高まるのではないか?」という前提条件は否定されましたが、気にせずに開発を続けます。
最終的に、以下のツイートを収集しデータセットとしました。
| ツイート | 件数 | label |
|---|---|---|
| ポケモンのプリンに関するツイート | 16件 | 1 |
| ポケモンではないプリンに関するツイート | 287件 | 0 |
| ププリンに関するツイート | 1841件 | 1 |
| プクリンに関するツイート | 1981件 | 1 |
今回は、下記のようにTSVファイルとして保存しました。
text label
0 プリンおいしい 0
0 プリンかわいい 1
0 セブンのプリンかわいい 0
0 プリンうまかった 0
0 相手のプリンうまかった 1
補足: Twitter API のデータ利用について
本稿においては自然言語処理技術の学習・研究のみを目的としてTwitter APIを利用しました。またTwitterは「Twitter APIの利用目的の制限に関する追加情報」においてツイート内容の再配布を認めていない8ため、本稿で利用した再現用のデータセットを公開することはできません。データの取得に利用したソースコードはGitHubに公開していますが、検証結果の再現を保証するものではなくTwitter APIからの返り値によって結果は変化します。
また、本稿内においてツイートの例として掲載している文(例: 「プリンうまかった」など)は実際のツイートではなく、すべて筆者が例として考えた架空の発言です。
語義曖昧性解消を実践したいがデータが無い、という場合は「SNOW E19:話題に基づく語義曖昧性解消評価セット」を利用して語義曖昧性解消の実験に取り組むことができます。筆者も最初はTwitter APIは利用せずこちらのデータセットを使って「ウイルス」がコンピュータ用語か医療用語かの分類を実装することで簡単な技術検証を行いました。
https://github.com/nut-jnlp/JapaneseTopicWSD
最も単純な分類の実装
語義曖昧性解消における最も単純な手法は、 最も高頻度な語義を常に選ぶ というものです。今回のケースならば「与えられた文はすべてポケモンのプリンに関するものである」という実装9です。つまり、どんな文字列が与えられても常に「1」を返すモデルです。
実装は下記のようになります。今後の拡張を見据えて若干冗長なコードを含んでいます。データセットを学習用:評価用=8:2に分割し(まだ何の学習もしていないので意味はありませんが)、評価結果を出力します。
import pandas
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, confusion_matrix, classification_report
def load_dataset(dataset_tsv_path):
df = pandas.read_table(dataset_tsv_path)
df = df.dropna(subset=['label'])
return df['text'].values, df['label'].values
class BaseDisambiguator():
def __init__(self, x_train, y_train, x_test, y_test) -> None:
self.x_train = x_train
self.y_train = y_train
self.x_test = x_test
self.y_test = y_test
def train(self):
pass
def predict(self, xs: list[str]) -> list[float]:
return self.predict_proba(xs)
def predict_proba(self, xs: list[str]) -> list[int]:
return [ 1 for _x in xs ]
def eval_print(self):
y_pred = self.predict(self.x_test)
print('roc_auc_score', roc_auc_score(self.y_test, y_pred))
def train_and_eval(self):
self.train()
self.eval_print()
# データセット読み込み
x, y = load_dataset('data/purin.tsv')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 予測の実行
base_disambigunator = BaseDisambiguator(x_train, y_train, x_test, y_test)
base_disambigunator.train_and_eval()
スコアとしてROC AUC 0.5が得られます。このモデルは何もしていませんが、これから自然言語処理技術を用いてモデルを改善することで、この数字を高くしていきます。
roc_auc_score 0.5
補足: 評価指標について
機械学習における分類問題の評価指標には様々なものがあり、場合によって選択されます。今回AUC ROCスコアを用いますが、この選択において注意点があるため補足します。
評価出力メソッドを下記のように変更し、様々な指標を出力するようにしてみましょう。
def eval_print(self):
y_pred = self.predict(self.x_test)
display(Markdown('#### ROC AUC score'))
print(roc_auc_score(self.y_test, y_pred))
display(Markdown('#### confusion matrix'))
labels = [0,1]
cm = confusion_matrix(self.y_test, y_pred, labels=labels)
display(pandas.DataFrame(cm,
columns=[["Predicted"] * len(labels), labels],
index=[["Actual"] * len(labels), labels])
)
display(Markdown('#### classification report'))
print(classification_report(self.y_test, y_pred))
出力は下記のようになります。
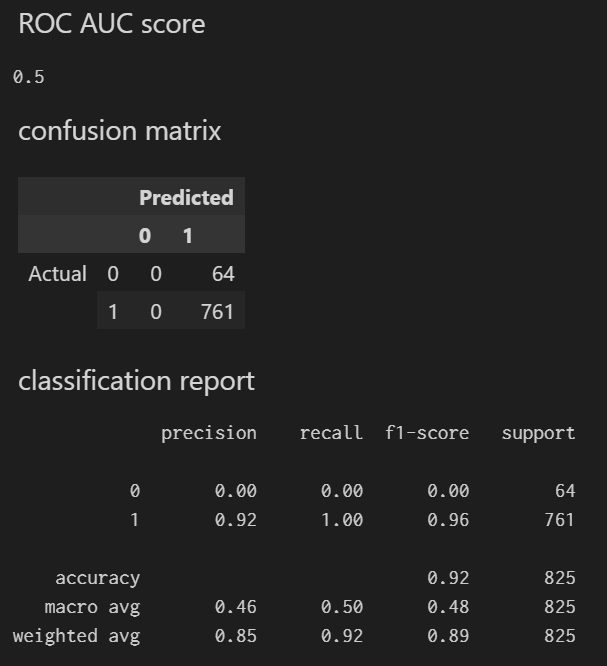
混同行列(confusion matrix) は、予測(predicted)と実際(actual)の組み合わせの個数を行列にしたものです。このモデルはすべて1(=ポケモンのプリンに関するもの)として出力するため、Predicted 0 の列はいずれの行も0になっています。このモデルが「何の予測もしていない低品質な物である」事をちゃんと示しています。
一方、このように何の処理もしていない低品質なモデルであるにも関わらず、1に着目した precision(適合率) 0.92、recall(再現率) 1.00、f1-score 0.96、および accuracy(精度) 0.92 と、非常に高い数字が並んでいます。本稿においてこれらの説明はしませんが、これらはいずれも機械学習において一般的に使われる指標です。
今回のテスト用データセットは9割程度がポケモンのプリンに関するもののため、「全部ポケモンのプリンに関するものである」と予想するとそれだけで「精度」が90%程度になる事は直感的に想像できると思います。つまり、何の予測もしていない低品質なモデルであるにも関わらず、指標によってはすでに非常に高い精度で予測できている優秀なモデルであると示されてしまいます。精度の指標はタスクによって適切なものを都度選択しましょう。
自然言語処理技術による分類モデルの構築
ここから自然言語処理技術を使って、分類モデルを改善していきます。そのためにはテキストをベクトルの表現に変える必要があります。様々な手法がありますが、単純なものとして Bag of Words(BoW) を利用します。これは、各単語の出現回数を数値として表現したものです。例を見てみましょう。
Bag of WordsでTokenize
「プリンうまい」と「相手のプリンうまい」の2文からなるデータセットがあったとして、このデータセットに登場する単語は「うまい」「の」「プリン」「相手」の4つのみです。それぞれの文に対して、登場回数を記録すると下記のとおりになります。
| もとのテキスト | うまい | の | プリン | 相手 |
|---|---|---|---|---|
| プリンうまい | 1 | 0 | 1 | 0 |
| 相手のプリンうまい | 1 | 1 | 1 | 1 |
「プリンうまい」を[1,0,1,0]、「相手のプリンうまい」を[1,1,1,1]に変換できます。このようにしてテキストを変換することで、機械学習アルゴリズムに掛けることができます。今回はロジスティック回帰を用います。
実際にBag of Wordsをプログラムで実装してみます。まずは 形態素解析 によって文を単語に分割します。Pythonで書かれた形態素解析器である Janome を利用します。例を見てみましょう。
from janome.tokenizer import Tokenizer as JanomeTokenizer
janome_tokenizer = JanomeTokenizer()
tokens = janome_tokenizer.tokenize("相手のプリンうまい", wakati=True)
print(list(tokens))
['相手', 'の', 'プリン', 'うまい']
このように、日本語の文字列から単語を分割できました。
次に、すべての文に現れる単語をカウントして ボキャブラリ を構築します。Pythonにおける機械学習の有名ライブラリである scikit-learn のCountVectorizerを利用することでかんたんに実装できます。
from sklearn.feature_extraction.text import CountVectorizer
janome_tokenize = lambda text: janome_tokenizer.tokenize(text, wakati=True)
v = CountVectorizer(tokenizer=janome_tokenize)
texts = ["プリンうまい", "相手のプリンうまい"]
v.fit_transform(texts)
print(v.vocabulary_)
{'プリン': 2, 'うまい': 0, '相手': 3, 'の': 1}
4つの単語について、それぞれ対応するIDが振られた辞書が得られました。
最後に、個々の文をベクトル表現に エンコード します。
v.transform(texts).toarray()
array([[1, 0, 1, 0],
[1, 1, 1, 1]])
先程示したように「プリンうまい」を[1,0,1,0]、「相手のプリンうまい」を[1,1,1,1]に変換できました。
Bag of Wordsによるテキスト分類のベースラインの実装
janomeとCountVectorizerを利用したBag of Words表現を使って、分類モデルを構築してみます。先程実装したBaseDisambiguatorを継承することで評価部分などは共通化し、ベクトル表現を使った分類をするように実装します。
from numpy import count_nonzero
class CountDisambiguator(BaseDisambiguator):
def __init__(self, x_train, y_train, x_test, y_test, vectorizer=CountVectorizer()) -> None:
super().__init__(x_train, y_train, x_test, y_test)
self.vectorizer = vectorizer
def train(self):
x_train_vec = self.vectorizer.fit_transform(self.x_train)
# 不均衡データセットなので重みをつける
weights = {
0: 1 / count_nonzero(y_train == 0),
1: 1 / count_nonzero(y_train == 1),
}
self.model = LogisticRegression(solver='liblinear', class_weight=weights)
self.model.fit(x_train_vec, self.y_train)
return self.model
def predict(self, xs):
xs = self.vectorizer.transform(xs)
return self.model.predict(xs)
def predict_proba(self, xs: list[str]):
xs = self.vectorizer.transform(xs)
return [ x[1] for x in self.model.predict_proba(xs)]
実際に学習してみます。筆者の環境では10秒程度かかりました。
CountDisambiguator(x_train, y_train, x_test, y_test,
vectorizer=CountVectorizer(tokenizer=janome_tokenize)).train_and_eval()
auc_roc_score 0.7891548948751643
スコアが0.5→0.78に大きく改善しました。
この値をさらに改善できないか、以下で試していきます。
テキストの前処理による改善
Bag of Wordsはシンプルな表現ですので、前処理をすることで精度をより高められます。今回のデータセットで特徴的なのはTwitterの発言を利用しているため、@s2terminal_tech 今日プリンたべる?のように@付きのリプライと呼ばれる特殊な記法で会話されることがあります。この記法はポケモンかどうかに影響を及ぼさないと思われるため、削除してから学習してみます。
import re
def remove_anchor(text):
return re.sub(r'\@[a-zA-Z0-9]+', '', text)
CountDisambiguator(x_train, y_train, x_test, y_test,
vectorizer=CountVectorizer(tokenizer=janome_tokenize, preprocessor=remove_anchor)).train_and_eval()
auc_roc_score 0.7977681504599212
0.78→0.79に微増しました。
このように、単純な前処理を追加するだけでも精度が向上することがあります。
Min DF, Max DF
文書集合の中で、ある語を含む文書数がいくつあるか(あるいは文書全体の何%の割合になるか)を示す指標が 文書頻度(Document Frequency, DF) です。たとえば「プリンうまい」「相手のプリンうまい」の2つの文書からなる集合において、「相手」のDFは1(あるいは50%)となります。
ほとんどすべての文書に登場するような語は、Bag of Wordsの表現で分類する場合は有効な特徴になりません。「他の文書には登場しないが特定の文書に登場する」ような単語を有効に使って分類するためです。
CountVectorizerのmax_dfを設定すると、DFが高い語を除外してベクトルにする事ができます。
CountDisambiguator(x_train, y_train, x_test, y_test,
vectorizer=CountVectorizer(tokenizer=janome_tokenize, max_df=0.7)).train_and_eval()
auc_roc_score 0.800108820630749
max_dfを設定することで0.78→0.80にスコアが改善しました。
逆に、文書全体において滅多に出現しないような語、限られた特定の個人しか発言しないような特殊な単語は、分類問題において役に立ちません。CountVectorizerのmin_dfで、DFの最低値を設定することで、このような語を無視できます。
CountDisambiguator(x_train, y_train, x_test, y_test,
vectorizer=CountVectorizer(tokenizer=janome_tokenize, min_df=3)).train_and_eval()
auc_roc_score 0.785869743758213
結果は微減となりました。このように、前処理が有効に機能しない場合ももちろんあります。ですがスコアの改善以外にもボキャブラリを削減することでモデルを軽量化できるなどの恩恵もあるため、DFを用いて単語を削減することが有効な場合もあります。
TF-IDF
DFに基づいて単語を削減する手法を紹介しました。が、「特定の文書だけに高頻度で登場する語は、その文書の特徴を表しているので、分類モデルにおいて有効なのではないか」という考え方もできます。
たとえば先程の例において「相手のプリンうまい」は、CountVectorizerによって[1,1,1,1]と表現されていました。すべての語が同じ重み付けになっています。ですが実際には「相手の」という他の文書に登場しない語がある事によって「他の文書よりもポケモンの話をしている確率が高いだろう」と考えられるため、「相手の」の方がより重要である、より高い数値になって欲しいです。
それを表現する指標としてTF-IDF(term frequency-inverse document frequency) を利用できます。これはTFとIDFの積を取ったものです。それぞれ説明します。
IDFのDFとは先程紹介した文書頻度(DF, Document Frequency)と同じものです。その逆数(inverse)10をとることで「あまり出現する文書が無い語ほど大きな値となる」ものがIDFです。
TF(Term Frequency)は、対象の文書に対象の語が現れる回数です。
TfidfVectorizerを利用することで、TF-IDFによるベクトル表現ができます。
from sklearn.feature_extraction.text import TfidfVectorizer
janome_tokenize = lambda text: janome_tokenizer.tokenize(text, wakati=True)
v = TfidfVectorizer(tokenizer=janome_tokenize)
texts = ["プリンうまい", "相手のプリンうまい"]
v.fit_transform(texts)
v.transform(texts).toarray()
array([[0.70710678, 0. , 0.70710678, 0. ],
[0.40993715, 0.57615236, 0.40993715, 0.57615236]])
「相手のプリンうまい」が、CountVectorizerだと[1,1,1,1]とベクトル化されていたのが、TfidfVectorizerを使うことで[0.40993715, 0.57615236, 0.40993715, 0.57615236]に変化しました。「相手」「の」にあたる語の方が数値が高くなっていて、語義曖昧性解消に於いてより重要な特徴であるということが数値で示されました。
実際にTfidfVectorizerを分類問題に適用してみましょう。
CountDisambiguator(x_train, y_train, x_test, y_test,
vectorizer=TfidfVectorizer(tokenizer=janome_tokenize)).train_and_eval()
auc_roc_score 0.8133931504599212
0.78→0.81に改善しました!
BERTを利用した分類
ここまでは古典的な手法を紹介してきましたが、自然言語処理において比較的新しい BERT(Bidirectional Encoder Representations from Transformers) を使った分類モデルの構築を紹介します。BERTとは2018年にGoogleが公開したニューラル言語モデルです。Encoderとあるとおり入力文をベクトル表現にエンコードし、様々な言語タスクに応用できます。Google検索にもBERTが利用されています。
BERTの特徴のひとつは Bidirectional(双方向) であること、これは「文の先頭から末尾に向かう順方向 」と、「末尾から先頭に向かう 逆方向 」の両方の情報を用いてモデルを構築していることです。その特徴から特に一部の単語が欠落した文の穴埋めのようなタスクを得意としており、huggingfaceのサイトで東北大学の公開している日本語BERTモデルでのデモを試す事ができます。
今まで紹介してきたBag of Wordsは単語にのみ着目したモデルであり、その文が持つ文脈の情報は欠落していました。しかし「プリンうまかった」の例のように、「プリン」という語の周辺の単語の微妙な変化によって語義が変化してきたのを見てきました。
BERTから得られるベクトルを利用することによって、Bag of Wordsなどでは欠落していた文脈の情報を加味できるのではないかと思います。実際に語義曖昧性解消タスクにおいてBERTを利用することで精度が改善したという論文もあります11。
BERTを使ってみる
BERTのベクトル表現は768次元もあり、出力したり図示したりして直感的に理解する事は難しいです。ここでは実際にBERTのベクトル表現を使って単純なタスクに取り組むことで、その挙動をすこし見てみます。
適当なテキストのBERTによるベクトル表現を取り出し、ベクトル毎のコサイン類似度を表示するコードが下記です。コサイン類似度というのはふたつのベクトルの類似度をあらわす指標のひとつであり、-1から+1までの値を取り、大きいほど類似しています。
import numpy
from itertools import combinations
from transformers import BertJapaneseTokenizer, TFBertModel
MODEL_NAME = 'cl-tohoku/bert-base-japanese'
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
model = TFBertModel.from_pretrained(MODEL_NAME)
def vectorize(text: str):
encoding = tokenizer(text, padding = 'longest', return_tensors='tf')
outputs = model(**encoding)
return outputs.last_hidden_state[0][0]
def cos_sim(v1, v2):
return numpy.dot(v1, v2) / (numpy.linalg.norm(v1) * numpy.linalg.norm(v2))
texts = [
"プリンうまい",
"セブンのプリンうまい",
"相手のプリンうまい",
]
for t in combinations(texts, 2):
print(t, cos_sim(vectorize(t[0]), vectorize(t[1])))
結果は下記のようになります。
('プリンうまい', 'セブンのプリンうまい') 0.86518896
('プリンうまい', '相手のプリンうまい') 0.80697733
('セブンのプリンうまい', '相手のプリンうまい') 0.83683854
ともに「ポケモンではないプリン」を指していると考えられる「プリンうまい」「セブンのプリンうまい」の類似度が最も高くなりました。何が決定的な差になっているか実際には分かりませんが、本稿における分類問題においてうまく機能するのではないかと予想できます。
BERTによる分類
実際にBaseDisambiguatorを継承して、BERTを利用した分類を行うモデルを構築してみます。
from tqdm import tqdm
class BertModelDisambiguator(BaseDisambiguator):
def __init__(self, x_train, y_train, x_test, y_test) -> None:
super().__init__(x_train, y_train, x_test, y_test)
self.bert_tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
self.bert_model = TFBertModel.from_pretrained(MODEL_NAME)
def preprocess(self):
self.x_train_vec = self.bert_vectorize(self.x_train)
def train(self):
# 不均衡データセットなので重みをつける
weights = {
0: 1 / count_nonzero(y_train == 0),
1: 1 / count_nonzero(y_train == 1),
}
self.model = LogisticRegression(solver='liblinear', class_weight=weights)
self.model.fit(self.x_train_vec, self.y_train)
return self.model
def predict(self, xs):
xs = self.bert_vectorize(xs)
return self.model.predict(xs)
def predict_proba(self, xs: list[str]):
xs = self.bert_vectorize(xs)
return [ x[1] for x in self.model.predict_proba(xs)]
def bert_vectorize(self, xs):
return [ self.bert_vectorize_single(x) for x in tqdm(xs) ]
def bert_vectorize_single(self, text: str) -> tensorflow.Tensor:
max_length = 256
encoding = self.bert_tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors='tf'
)
output = self.bert_model(**encoding)
last_hidden_state = output.last_hidden_state
return last_hidden_state[0][0]
実際に学習を実行してみます。なお今回のデータセットの4,000件程度のツイートをすべてベクトルに変換するpreprocess()メソッドの実行には、筆者の環境で20分程度かかりました。
bert_disambiguator = BertModelDisambiguator(x_train, y_train, x_test, y_test)
bert_disambiguator.preprocess()
bert_disambiguator.train()
bert_disambiguator.eval_print()
auc_roc_score 0.8298189060446781
今までで最高値である0.82を叩き出しました。
まとめ
「BoWで前処理を行わなかったモデル」「TF-IDFを用いたモデル」「BERTを用いたモデル」の3種類で、実際の入力に対してどのような予測をするのか見てみましょう。
test_texts = [
"プリンとイーブイかわいい",
"相手のプリンうまい",
"セブンのプリンおいしい",
"焼きプリンおいしい",
]
print([ round(f, 4) for f in disambiguator.predict_proba(test_texts)])
出力を整形したものは以下です。数値は「ポケモンのプリンである確率」で、0.5以上の場合はポケモンのプリンである、と言えます。
| 入力 | ラベル | BoW | TF-IDF | BERT |
|---|---|---|---|---|
| プリンとイーブイかわいい | ポケモンである | 0.5256 | 0.5003 | 0.531 |
| 相手のプリンうまい | ポケモンである | 0.5102 | 0.5001 | 0.6259 |
| セブンのプリンおいしい | ポケモンではない | 0.5078 | 0.4998 | 0.501 |
| 焼きプリンおいしい | ポケモンではない | 0.5183 | 0.4997 | 0.327 |
BoWによるモデルはすべて「ポケモンである」と判定されてしまっています。またTF-IDFによるモデルはこの4件すべての予想を的中させています。
ですがこれら2つのモデルはいずれも0.5前後の非常に微妙な差で判別されているのに対し、BERTは「相手のプリンうまい」を「0.6259」、「焼きプリンおいしい」を「0.327」と、ある程度ハッキリと判定されていることがわかります。
モデルの改善案
本稿で示したモデル構築手法はごく一部であり、まだまだ様々な手法を使って改善の余地があると考えられます。
データの増量
今回学習用のデータは筆者の手作業で作成したため量が限られており、データ量を増やすために苦しい手法も用いました。何らかの方法で良質なデータを大量に入手できれば精度向上が期待できます。
ルールベースでの判定
「プリン」を含むツイートを取得した結果「プリンセスコネクト」「ポムポムプリン」等の単語も拾ってしまいました。これらはいずれも日本製の可愛いキャラクターを指すものであり、機械学習でポケモンと区別することは難しい可能性があります。
が、単純に文字列一致でこれらの単語が含まれていたらポケモンではないとする判定を行えば、高い精度で判定できると考えられます。
適切な前処理
今回はいくつかの前処理を紹介しましたが、組み合わせて使うことはしませんでした。効果的な前処理を組み合わせて使うことで精度が向上することがあります。またmin_dfとmax_dfについては適当な値をひとつ試しただけであり、ハイパーパラメータ探索の手法で最も精度が高くなる値を設定することができます。
他にも形態素解析や係り受けのような日本語文法情報を用いた特徴量を生成するなど、さまざまな前処理が考えられます。
機械学習アルゴリズムの選択
本稿では自然言語処理技術のみに着目し機械学習については極力触れないようにするため、機械学習アルゴリズムは一貫してロジスティック回帰のみを用いました。ですが機械学習アルゴリズムには他にも様々な物があり、適切に選択することで精度が改善します。
特に、今回利用したBoWで得られるベクトル表現はほとんどの値がゼロになる「疎なベクトル」であるのに対し、BERTで得られるのは「密なベクトル」であり、機械学習アルゴリズムとの相性は異なるものなので同一のアルゴリズムを用いる事は本来避けるべきだと思われます。
BERT利用方法の工夫
今回はBERTの出力するベクトルを特徴量として機械学習を行いましたが、BERTの別の利用方法として特定のタスクに対して ファインチューニング して利用するというものがあります。
またBERTのモデルについても東北大学が公開している物を利用しましたが、日本語に対応したBERTのモデルは他にも様々な物があるため、選択によって動作が変化します。
おわりに
本稿では語義曖昧性解消の手法と実装をいくつか紹介し、それによってプリンがポケモンかどうか判別する手法を示しました。これらの手法を利用することで、ポケモンのプリンに関する文書を効率的に分類できると思います。いつかプリンに関するブログ投稿等の文書で溢れかえった状況になった時にはこれらの手法が有効ではないかと考えます。
またサンダー(Zapdos)12やピジョン(Pidgeotto)13など普通名詞と同名の日本語名を持つポケモンは他にも存在しますが、これらも本稿と同様の手法でポケモンに関する文書かどうかを分類できると思います。
参考文献
- O'Reilly Japan - Pythonではじめる機械学習
- 自然言語処理(’19)|放送大学
- BERTによる自然言語処理入門 Transformersを使った実践プログラミング | Ohmsha
- 機械学習・深層学習による自然言語処理入門 | マイナビブックス
- 言語資源活用ワークショップ2019発表論文集 BERTを利用した教師あり学習による語義曖昧性解消
- On SemEval-2010 Japanese WSD Task
-
2021年7月21日発売の対戦アクションゲーム。2021年11月にはITエンジニア限定の大会も開催され、筆者も参加した https://www.pokemonunite.jp/ja/ ↩
-
2021年11月19日発売のロールプレイングゲーム https://www.pokemon.co.jp/ex/bdsp/ja/ ↩
-
公式サイトのスクリーンショットを参照。冒険の舞台であるシンオウ地方にプリンは生息していないにも関わらずアイコンとして使われている点からプリンの存在感の強さが伺える https://www.pokemon.co.jp/ex/bdsp/ja/features/210818_06/ ↩
-
多義語と同音異義語の意味は本来異なるものだが、本稿では区別しない ↩
-
いわゆる本家のポケモンである「ポケットモンスター ブリリアントダイヤモンド・シャイニングパール」や「ポケットモンスター ソード・シールド」においてもプリンで対戦することは可能だが、2021年12月現在の対戦環境においてプリンが活躍しているとは言えず、この文からこれらの作品を遊んでいるという解釈の確度は低い ↩
-
2021年11月18日から全国のセブンイレブンで対象商品を購入するとポケモンのグッズ等がついてくるキャンペーンが開催され、ププリン・プリン・プクリンのデザインされたジッパーバッグが配布された。 https://www.ssnp.co.jp/news/distribution/2021/11/2021-1116-1316-14.html ↩
-
記事執筆時点ではPython3.10でPyTorchが利用できず、TensorFlowのNightly Buildを用いて開発している。 ↩
-
Twitter公式サイトの解釈によっては、再配布が禁じられているのはツイート本文のみで、ツイートIDやユーザIDの再配布は可能であるようにも受け取れるが、いずれの再配布も行わない ↩
-
データセットの用意について述べたとおり、「プリン」を含むツイート自体はポケモンのプリンではないものの方が多いが、本稿で用いるデータセット上はポケモンのプリンに関する物のほうが多くなっている ↩
-
一般的には逆数の対数をとる。 ↩
-
https://repository.ninjal.ac.jp/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=2594&item_no=1&page_id=13&block_id=21 ↩