線形のSVM(サポートベクターマシン)は、特徴空間を線形分離して分類する機械学習のモデルです。線形に分離できないような場合には、カーネル法を使ったSVNにより非線形に分離できます。
いままでカーネル法というのがよくわかっていなかったのですが、以下の記事が非常にわかりやすかったです。
これ以降は、以下の記事に従って準備したJupyter Notebookの環境で試しています。
Jupyter NotebookをDockerを使って簡単にインストールし起動(nbextensions、Scalaにも対応) - Qiita
この環境でブラウザで8888番ポートにアクセスして、Jupyter Notebookを使うことができます。右上のボタンのNew > Python3をたどると新しいノートを開けます。
また、適当にランダムで作成したCSVファイル
https://github.com/suzuki-navi/sample-data/blob/master/sample-data-1.csv
を使っています。
データ準備
CSVファイルからデータを読み込んでDataFrameのオブジェクトにします。
import pandas as pd
from sklearn import model_selection
df = pd.read_csv("sample-data-1.csv", names=["id", "target", "data1", "data2", "data3"])
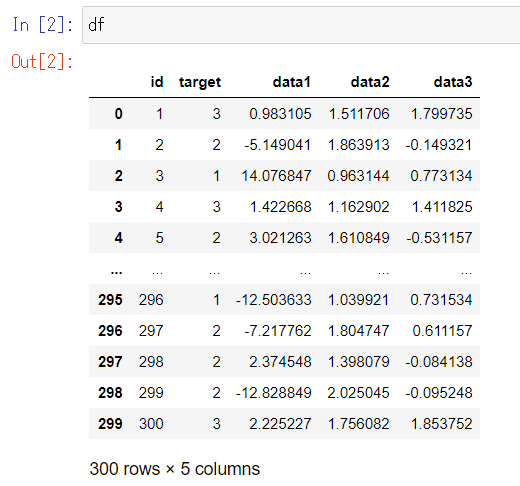
dfはPandasのDataFrameオブジェクトです。
参考
PandasのDataFrameに対する基本操作をJupyter Notebook上で試す - Qiita
このCSVのデータには特徴変数はdata1, data2, data3がありますが、散布図でデータの様子を確認してみます。
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(df["data1"], df["data2"], c = df["target"])
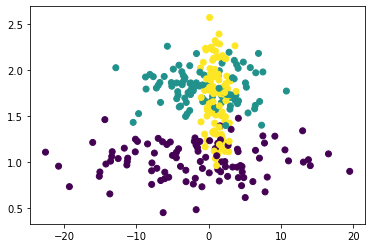
plt.scatter(df["data1"], df["data3"], c = df["target"])
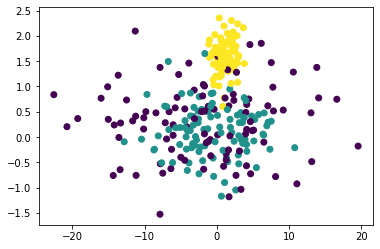
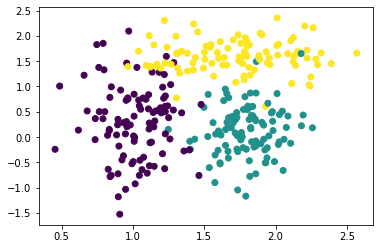
plt.scatter(df["data2"], df["data3"], c = df["target"])
参考
ヒストグラム・散布図をJupyter Notebook上で表示する - Qiita
散布図を見るとdata2とdata3の2つでなんとなく分類できそうな気がしますので、これで試してみます。
feature = df[["data2", "data3"]]
target = df["target"]
featureはPandasのDataFrameオブジェクト、targetはPandasのSeriesオブジェクトになります。
300レコードありますが、これを特徴変数と目的変数それぞれ訓練データと検証データに分割します。単にレコードを2つに分割するだけですが、model_selection.train_test_splitを使うと簡単に分割できます。これによりランダムに分割されます。
feature_train, feature_test, target_train, target_test = model_selection.train_test_split(feature, target, test_size=0.2)
test_size=0.2は全データの2割を検証データにする指定です。
特徴変数(df[["data2", "data3"]], feature_train, feature_test)はPandasのDataFrameオブジェクト、目的変数(df["target"], target_train, target_test)はSeriesオブジェクトです。
学習
作成した訓練データ(feature_train, target_train)をもとに学習します。
from sklearn import svm
model = svm.SVC(kernel="linear")
model.fit(feature_train, target_train)
SVC(kernel="linear")は線形分離するSVMの分類機のモデルです。fitで学習をさせます。
参考
sklearn.svm.SVC — scikit-learn 0.21.3 documentation
評価
学習したモデルで訓練データの特徴変数(feature_train)から推論結果(pred_train)を作成し、それと目的変数(target_train)とを比べて、正解率を評価します。metrics.accuracy_scoreという関数で簡単に評価できます。
from sklearn import metrics
pred_train = model.predict(feature_train)
metrics.accuracy_score(target_train, pred_train)
ロジックにランダムさがあるので、毎回結果は違うかもしれませんが、0.95と表示されました。
過学習していないか汎化性能を見るために、訓練データで評価します。
pred_test = model.predict(feature_test)
metrics.accuracy_score(target_test, pred_test)
0.9333333333333333と表示されました。まあまあいいのかな、よくわかりませんが。
scikit-learnとは別にmlxtendというパッケージに含まれるplotting.plot_decision_regionsを使うとどのように分類しているのかを散布図で視覚化してくれます。plot_decision_regionsにはPandasのオブジェクトではなくNumPyの配列を渡す必要がありますので、to_numpy()というメソッドで変換します。
from mlxtend import plotting
plotting.plot_decision_regions(feature.to_numpy(), target.to_numpy(), clf=model)
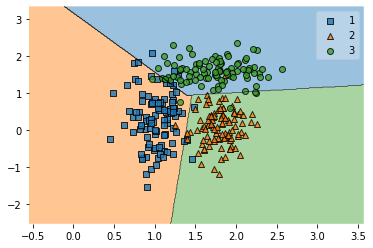
いい感じ。
参考
plot_decision_regions - Mlxtend.plotting - mlxtend
pandas.DataFrame.to_numpy — pandas 0.25.3 documentation
カーネル法を使ってみる
非線形分離を試してみたいと思います。RBFカーネルというのを使ってみます。
svm.SVC(kernel="linear")をsvm.SVC(kernel="rbf", gamma="scale")にすればいいだけです。gamma="scale"はRBFカーネルの場合のハイパーパラメータで、"scale"を指定すると訓練データの数と特徴変数の分散から自動で計算してくれます。
以下のコードで、モデルの作成、学習、推論、評価までします。
model = svm.SVC(kernel="rbf", gamma="scale")
model.fit(feature_train, target_train)
pred_train = model.predict(feature_train)
metrics.accuracy_score(target_train, pred_train)
0.95と表示されました。
汎化性能を見るために、訓練データで評価します。
pred_test = model.predict(feature_test)
metrics.accuracy_score(target_test, pred_test)
0.95と表示されました。さきほどの線形分離よりちょっとだけいい数字です。
plotting.plot_decision_regions(feature.to_numpy(), target.to_numpy(), clf=model)
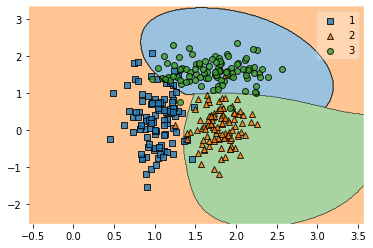
非線形というだけあってたしかに曲線で分離されています。
今回のサンプルは線形分離しやすいものだったので、非線形にするほどでもなかったのかもしれません。
ほかのデータでカーネル法を試す
data2とdata3では線形分離できてしまうので、ほかのデータの組み合わせでRBFカーネルを試してみます。
まずはdata1とdata2。以下のコードで分離している様子の図だけ作ります。
feature = df[["data1", "data2"]]
target = df["target"]
feature_train, feature_test, target_train, target_test = model_selection.train_test_split(feature, target, test_size=0.2)
model = svm.SVC(kernel="rbf", gamma="scale")
model.fit(feature_train, target_train)
plotting.plot_decision_regions(feature.to_numpy(), target.to_numpy(), clf=model)
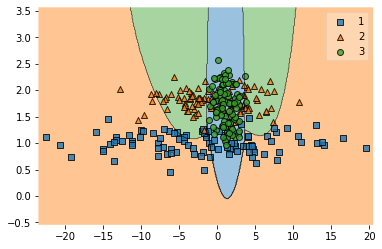
いちおう正解率を見てみます。
pred_train = model.predict(feature_train)
metrics.accuracy_score(target_train, pred_train)
0.7583333333333333でした。
pred_test = model.predict(feature_test)
metrics.accuracy_score(target_test, pred_test)
0.7833333333333333でした。
ちなみに同じデータで線形(kernel="linear")で試しても0.71~0.74でした。図を見るとカーネル法ががんばってそうに見えますが、数値にするとそんなに大差はない?非線形ができるからといってあまり期待しないほうがいいのかな。
data1とdata3でも試しましたが、同じような感じでしたので、省略・・・
以上。