いままでPythonでPandasでのデータ操作は、必要になったらググって使い方を調べればいいという程度のスタンスでしたが、データ分析や機械学習のあたりを勉強するにあたって、Jupyter Notebookでデータをスラスラと操作できないと話にならないと感じてきて、Pandasの使い方を基本から改めて整理して勉強し始めています。この記事はその勉強ノートです。
この記事の内容は、以下のリンク先に従って準備したJupyter Notebookの環境で試しています。
Jupyter NotebookをDockerを使って簡単にインストールし起動(nbextensions、Scalaにも対応) - Qiita
この環境でブラウザで8888番ポートにアクセスして、Jupyter Notebookを使うことができます。右上のボタンのNew > Python3をたどると新しいノートを開けます。
DataFrameの概要
PandasのDataFrameは、行と列のある表形式のデータのイメージです。行には0から始まる行番号を付けることもありますが、文字列でもいいようです。列には列の名前がついています。
DataFrameは表形式であるのに対して、Seriesという列だけのオブジェクトもあります。
DataFrameとSeriesの内容は以下の記事がとても参考になりました。
僕のpandas.SeriesとDataFrameのイメージは間違っていた - Qiita
Pythonパッケージインポート
import pandas as pd
CSVファイルから読み込む
# ヘッダーがある場合
df = pd.read_csv("data.csv")
# ヘッダー行が列名になる
# ヘッダーがない場合
df = pd.read_csv("data.csv", header=None)
# 0から始まる番号が列名になる
# ヘッダーがなく列名を指定したい場合
df = pd.read_csv("data.csv", names=["id", "target", "data1", "data2", "data3"])
この記事のこれ以降は、適当な乱数で作成したCSVファイル
https://github.com/suzuki-navi/sample-data/blob/master/sample-data-1.csv
を使っています。
(GitHubってCSVファイルも整形して表示してくれるんですね)
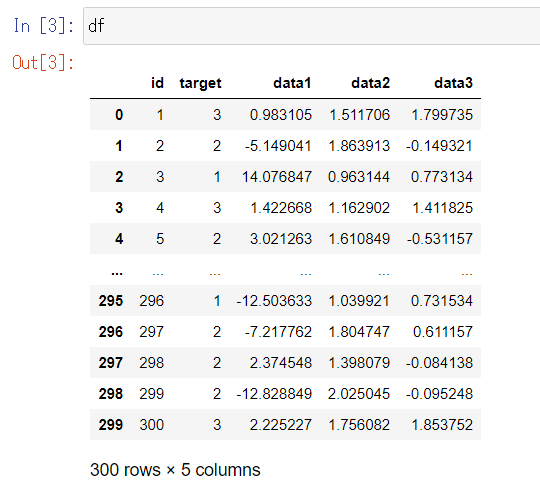
データの内容を確認
DataFrameのオブジェクトはJupyter Notebook上で内容を簡単に確認できます。
データの一部だけを見たい場合
# 先頭の5行
df.head()
# 先頭の3行
df.head(3)
# or
df[:3]
# 最後の5行
df.tail()
# 最後の3行
df.tail(3)
# 11行目から20行目だけを抜き出す
# (0から始まるインデックスでいうと10から19)
df[10:20]
# 11行目から最後までを抜き出す
# (0から始まるインデックスでいうと10から後ろ)
df[10:]
# 11行目のみを確認
# (0から始まるインデックスでいうと10)
df.loc[10]
# 特定の列のみを抜き出す
df[["target", "data1"]]
# 特定の列のみを抜き出す
# DataFrameでなくSeriesになる
df["data1"]
# df[["data1"]]とは異なる
# 特定の行範囲の特定の列のみを抜き出す
df[["target", "data1"]][10:20]
# or
df[10:20][["target", "data1"]]
一部の行のみを抜き出しても、行についているインデックスは維持されます。

データの形式を確認
df.shape
# => (300, 5)
df.columns
# => Index(['id', 'target', 'data1', 'data2', 'data3'], dtype='object')
df.dtypes
# => id int64
# target int64
# data1 float64
# data2 float64
# data3 float64
# dtype: object
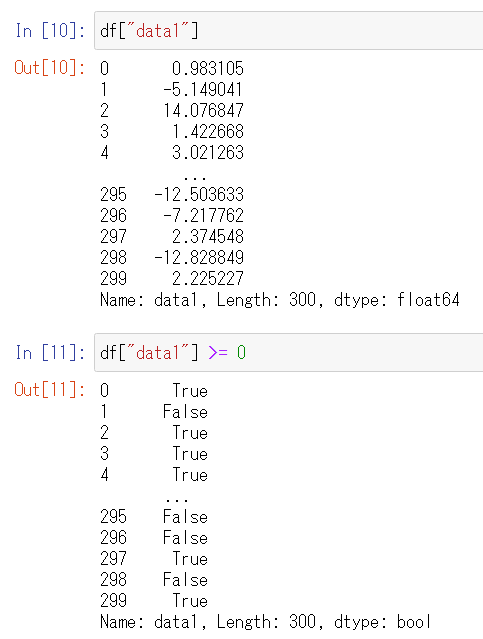
列に対して演算
列に対して演算ができます。
df["data1"]はSeriesですが、df["data1"] / 100のように書くとSeriesの各要素に対して/ 100という演算をして、結果をSeriesで取得できます。
列同士の演算もできます。
df["data1"] + df["data2"]
行を条件で抽出
# df["data1"] >= 0 がTrueとなる行のみからなるDataFrameを生成
# 行のインデックスは維持されるので、とびとびの番号になる
df[df["data1"] >= 0]
# SQLみたいにクエリすることもできる
df.query('data1 >= 30 and target == 1')
# クエリの中に文字列を入れたい場合は "" で囲む
df.query('target == "1"')
重複を削除した値の一覧を取得
df["target"].unique()
# => array([3, 2, 1])
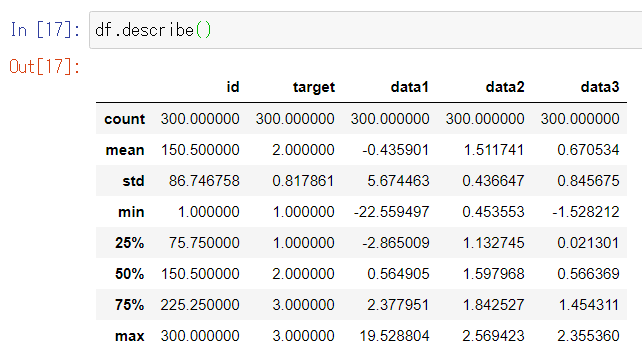
数値の列についての統計量を取得
df.describe()
ソート
以下は、data1列で行を並び替えたDataFrameを返します。
# data1列の昇順
df.sort_values("data1")
# data1列の降順
df.sort_values("data1", ascending=False)
# 複数の列で並び替え
df.sort_values(["target", "data1"], ascending=False)
第1ソートをtarget降順、第2ソートをdata1昇順とするにはどうしたらいいんだろう?
列を追加
以下の例では、既存の列に演算を施した新しい値の列を右端に追加する。
df["data_sum"] = df["data1"] + df["data2"] + df["data3"]

以上。