自己紹介
- すぎゃーん (id:sugyan)
- Web系エンジニア
- ドルヲタ歴5年ちょい
- TensorFlowで機械学習に入門 (2015.11〜)
- はてなブログ書いてます
- すぎゃーんメモ http://memo.sugyan.com/
アジェンダ
- アイドル顔識別について
- 学習用データセットの収集・作成
- モデルの評価と実験
- 収集したデータを使った顔画像生成
アイドル顔識別について
問題設定
「入力した画像に対し、写っているのが『どのアイドル(人物)か』を機械学習により自動判定する」

- 画像内の顔領域検出
- こちらは別タスク (Cloud Vision APIなど)
- 抽出した顔部分の分類
- この分類器を作っている、という話
Deep Learning による画像分類
- TensorFlowチュートリアルの最初の例
- 畳み込みニューラルネットワークを使った CIFAR-10 などの画像分類
- 学習には大量の教師データが必要
- 入力画像と、正しい分類ラベルのセット
分類対象のアイドル
- ライブアイドル
- (俗称 インディーズアイドル、地下アイドル、など)
- 数千人いる、と言われている
- Twitter、BlogなどWebメディアも積極的に活用
- 「自撮り」を多く載せていて、顔画像を集めやすい
アイドル顔識別の難点
- 対象は10〜20代女性、という近い属性
- そもそも「アイドルなんてみんな同じ顔に見える」という人もいる
- 表情・角度・画質などが様々すぎる
- 変顔もあるし、ブレていたり暗かったり
- メイク・加工アプリによる変貌
- 成長や整形(!)でリアルに顔が変わることも
- 突然卒業・脱退してしまう (つらい)
- 分類対象からは外す必要がある
Phase-1: 5人組グループのメンバー識別

- 対象を某国民的グループのメンバー5人だけに限定
- ブログに載せている画像から顔画像を収集
- 各メンバー200枚前後、自力でラベル付け
- TensorFlow同梱のCIFAR-10用モデルを利用
- それに合わせて32×32のデータセットを用意
- ある程度の分類が出来るようになることを確認
収集画像からの顔検出
- 顔領域の検出はOpenCVのHaar-like特徴での検出器に回転補正機能を入れたものを自作して利用
- http://memo.sugyan.com/entry/20151203/1449137219
- 遅いし誤検出も多いので改善したいとは思っている
- 外部WebAPIサービスの利用も検討したが件数が多く無料枠で収まらない
Phase-2: 分類モデルを自作
CIFAR-10の実装を参考に、自分で書いてみる
- 96×96の、より大きい入力画像を受け付けるよう
- 畳み込み層の深さも増やしたり
- Optimizerを入れ替えたり
Phase-3: 分類対象の拡大
- 自撮り投稿サービス等から収集し、1,500人ほどを登録
- 本当はもっと居るので2,000くらいまでは増やしたい
- 1人あたり200件の学習データを用意しようとすると最低でも400,000件…
- 地道にTwitterのアカウントを調べて登録、定期的に検索APIから投稿画像を収集
- 毎日2,000~3,000くらい集まる、半年以上続けて9月中旬時点で50数万件
- …が、これらに分類ラベルを付けないと学習データとして使えない
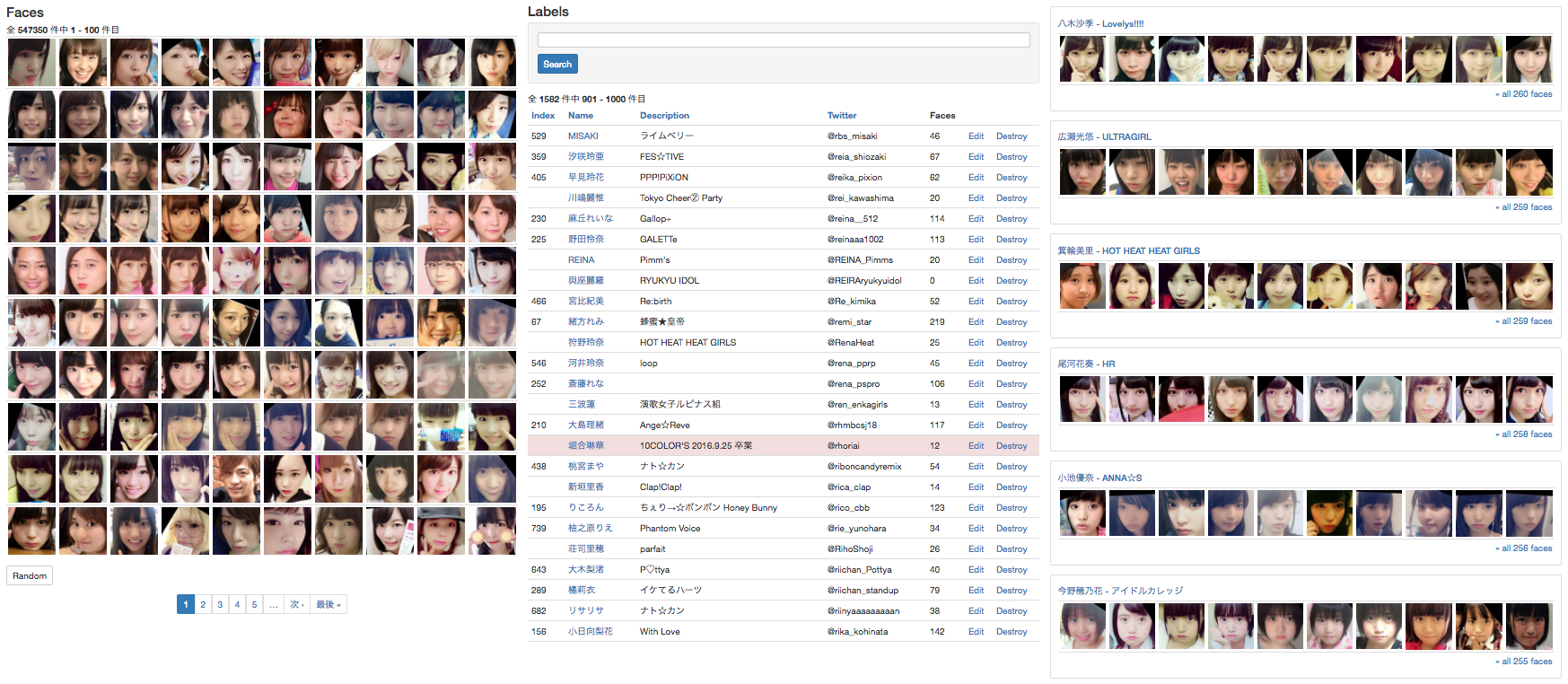
収集画像から検出して抽出した顔が「どのグループの何ちゃん」か 1,000以上の選択肢から…
超専門的知識と労力が必要!!!
気合いで解決
- ヲタクなので200人くらいなら見分けられる
- 知ってる子を優先的に探して毎日コツコツとラベル付けしていく
- 知らない子でも自撮りっぽい投稿ならその投稿者本人に違いない
- 知ってる子と写っていて名前が書いてあれば特定できるし
- やってるうちに自分自身もどんどん学習する、人間はすごい
一覧表示や入力インタフェースが欲しくなり、管理用Webアプリを自作
Phase-4: 半教師あり学習的アプローチ
- ある程度の件数が集まったアイドルを対象に分類器を学習させ、
- 学習したモデルに対し未知の画像を与えて、その分類結果をヒントとして利用
- 「どのグループの何ちゃん?」ではなく「○○の△△ちゃんだと思うけど合ってる?」の2択に絞れる
- 合っていれば学習データが増えるし
- 間違っていたら正しくラベル付けて学習しなおせばどんどん精度が上がる
- こまめに学習用データセットを更新し、学習をやり直す
- 過去の学習済パラメータをロードし、それを初期値として学習開始することで効率よく
- 分類数が変化したときは最後の全結合層だけ初期化する
このサイクルを繰り返し、ラベル付け済データは9月末時点で約85,000件 (分類数750)
モデルの評価と実験
ある程度データ作成できた時点で精度を試してみた
- 40人×150=6,000件で学習し1,200件で評価するデータセット

約94%の正答率になることを確認

- 入力画像サイズは多少縮小しても同程度の性能に
- 中間層の出力を調べ、ユニット数をある程度減らしても影響がないことを確認
- モデルパラメータ保存ファイルのサイズ削減に成功
- 今はこのときよりもっとデータ増えたので改めて試したいところ
また、かなり学習しても予想外の入力に対して誤った分類をすることも確認

未知画像に対するクラスタリング?
- 半教師あり的アプローチは、学習した顔に関しては未知のものから判定できる
- 学習してないまったく未知の人物の顔画像に対し「これとこれは同じ人物」と判定できないか?
- 顔分類の学習により、中間層が様々な特徴を捉えているのでは?
- 未知画像を与えたときの中間層出力の分布を調べる

データ整理してちゃんと試してみたいところ
収集した顔画像を使ってDCGANによる生成
これも色々と実験中 近々ブログにまとめる予定

まとめ
- TensorFlowをきっかけに顔識別器を作って色々やってる
- 結局データ収集が一番大変
- Tutorialや先行事例など色々あるので知識ゼロからでも意外と何とかなってる
- 初心者でも始めやすいTensorFlow++