はじめに
参考記事を参考に「Transformerを用いた時系列分析」を行いました。
参考記事
使用データについて
トレンド傾向の掴みやすさから、yahoo financeからGSPCの日足を使用しました。
訓練データの期間:2015/1/1 - 2017/6/30
テストデータの期間:2017/7/1 - 2021/1/1
Transformerとは1
Transformerモデルは、従来のRNNモデルとは異なり、アテンション機構を用いることで、シーケンスデータ処理において高い性能を発揮します。
アテンション機構について、Tensorflow側で用意されています。
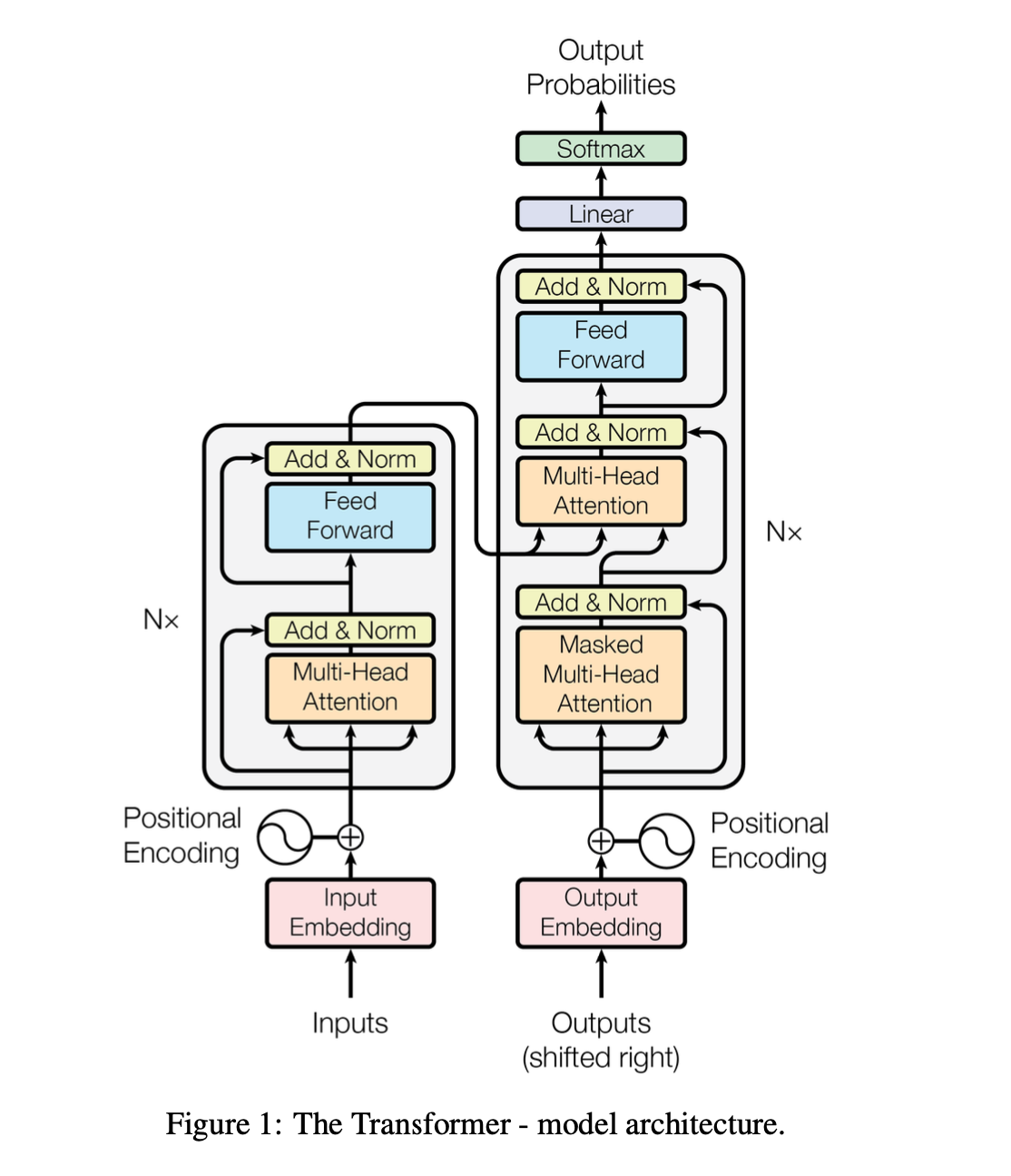
メインロジック
EncoderBlock
class EncoderBlock(tf.keras.layers.Layer):
def __init__(self, head_size, num_heads, ff_dim, dropout, attention_axes, epsilon, kernel_size):
super().__init__()
self.layer_norm1 = LayerNormalization(epsilon=epsilon)
self.multi_head_attention = MultiHeadAttention(
key_dim=head_size, num_heads=num_heads, dropout=dropout, attention_axes=attention_axes
)
self.dropout1 = Dropout(dropout)
self.layer_norm2 = LayerNormalization(epsilon=epsilon)
self.conv1d = Conv1D(filters=ff_dim, kernel_size=kernel_size, activation="relu")
self.dropout2 = Dropout(dropout)
self.conv1d_out = Conv1D(filters=head_size * num_heads, kernel_size=kernel_size)
def call(self, inputs):
x = self.layer_norm1(inputs)
x = self.multi_head_attention(x, x)
x = self.dropout1(x)
res = x + inputs
x = self.layer_norm2(res)
x = self.conv1d(x)
x = self.dropout2(x)
x = self.conv1d_out(x)
return x + res
TransformerModel
class TransformerModel(tf.keras.Model):
def __init__(self,
head_size,
num_heads,
ff_dim,
num_trans_blocks,
mlp_units,
dropout=0,
mlp_dropout=0,
attention_axes=None,
epsilon=1e-6,
kernel_size=1,
n_outputs=PREDICT_PERIOD):
super().__init__()
self.encoder_blocks = [
EncoderBlock(
head_size=head_size,
num_heads=num_heads,
ff_dim=ff_dim,
dropout=dropout,
attention_axes=attention_axes,
epsilon=epsilon,
kernel_size=kernel_size
) for _ in range(num_trans_blocks)
]
self.pooling = GlobalAveragePooling1D(data_format="channels_first")
self.mlp = Sequential([
Dense(dim, activation="relu") for dim in mlp_units
])
self.dropout = Dropout(mlp_dropout)
self.output_layer = Dense(n_outputs)
def call(self, inputs):
x = inputs
for block in self.encoder_blocks:
x = block(x)
x = self.pooling(x)
x = self.mlp(x)
x = self.dropout(x)
return self.output_layer(x)
損失関数
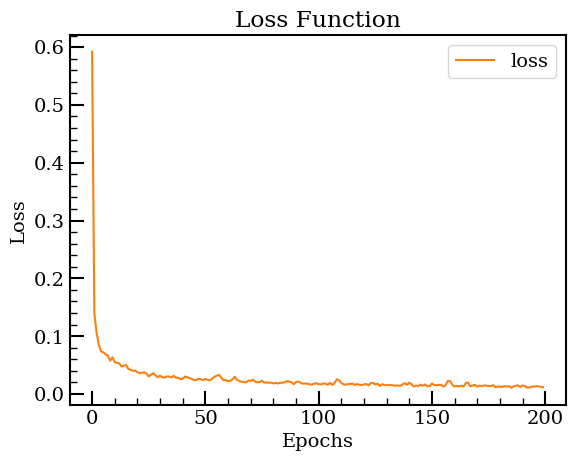
学習結果
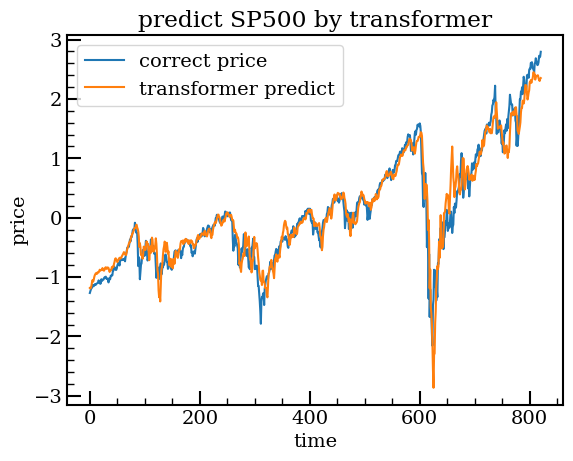
-
'Attention is all you need'. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Kaiser, L., & Gomez, A. N. (2017). Advances in Neural Information Processing Systems, 30. ↩