はじめに
初めてKaggle(カグル)のコンペに参加してみたお話です。
前回の「はじめてのKaggle」では、
・Kaggleへの参加方法
・コンペに参加するやり方
・参加してコードを書くまで
・結果の提出方法
を中心に記述しました。
今回は「Titanicコンペ」で学習するところまで進めてみたいと思います。
サンプルコードの正解率「76%」を超えられるでしょうか。
目次
1.前提知識
2.学習の流れ
3.データを整備する
3.1.必要な項目を抽出する
3.2.欠損値を処理する
3.3.ラベルを数値化する
3.4.数値を標準化する
4.モデルを構築する
5.トレーニングデータで学習する
6.テストデータで結果を予想する
7.提出した結果
8.まとめ
履歴
1.前提知識
どのくらい機械学習を知っている人間が記述しているのか、というところからです。
半年くらい(2019年4月)前に機械学習に興味を持ち、以下の本を中心に学んできました。
・Python 機械学習プログラミング 達人データサイエンティストによる理論と実践
・詳解 ディープラーニング ~TensorFlow・Kerasによる時系列データ処理~
「scikit-learn(サイキットラーン)」や「tensorflow(テンソルフロー)」、「keras(ケラス)」が何なのか、分かってきたような、分からないような… という状況です。
自分が理解しているイメージとしては、以下のようなイメージです。
- scikit-learnはパラメータが少なく、お手軽に学習ができる(処理速度も速い)
- kerasはtensorflow上で動く機械学習ライブラリ群。scikit-learnより細かく設定できる。(kerasはtensorflow以外でも動くようですが、詳細は分かりません。Theano?)
- tensorflowは、機械学習を行うためのライブラリ群ですが、こちらのライブラリは入れものに近いです。機械学習に便利な「定数」や「変数」、「プレースホルダ」なるものが扱えますが、tensorflowだけだと「活性化関数」や「評価関数」などを自作する必要があります。
自分のレベルとして、scikit-learnやkerasを使って学習のコードが書けるかな、というくらいのレベルです。
2.学習の流れ
機械学習の流れは以下のようになります。
1.データを整備する
2.モデルを構築する
3.トレーニングデータで学習する
4.テストデータで結果を予想する
3.データを整備する
データを確認、整備します。
まずは、前回とは別に新しいNotebookで始めるため、「New Notebook」をクリックし、前回と同様に言語「Paython」、Type「Notebook」を選択します。
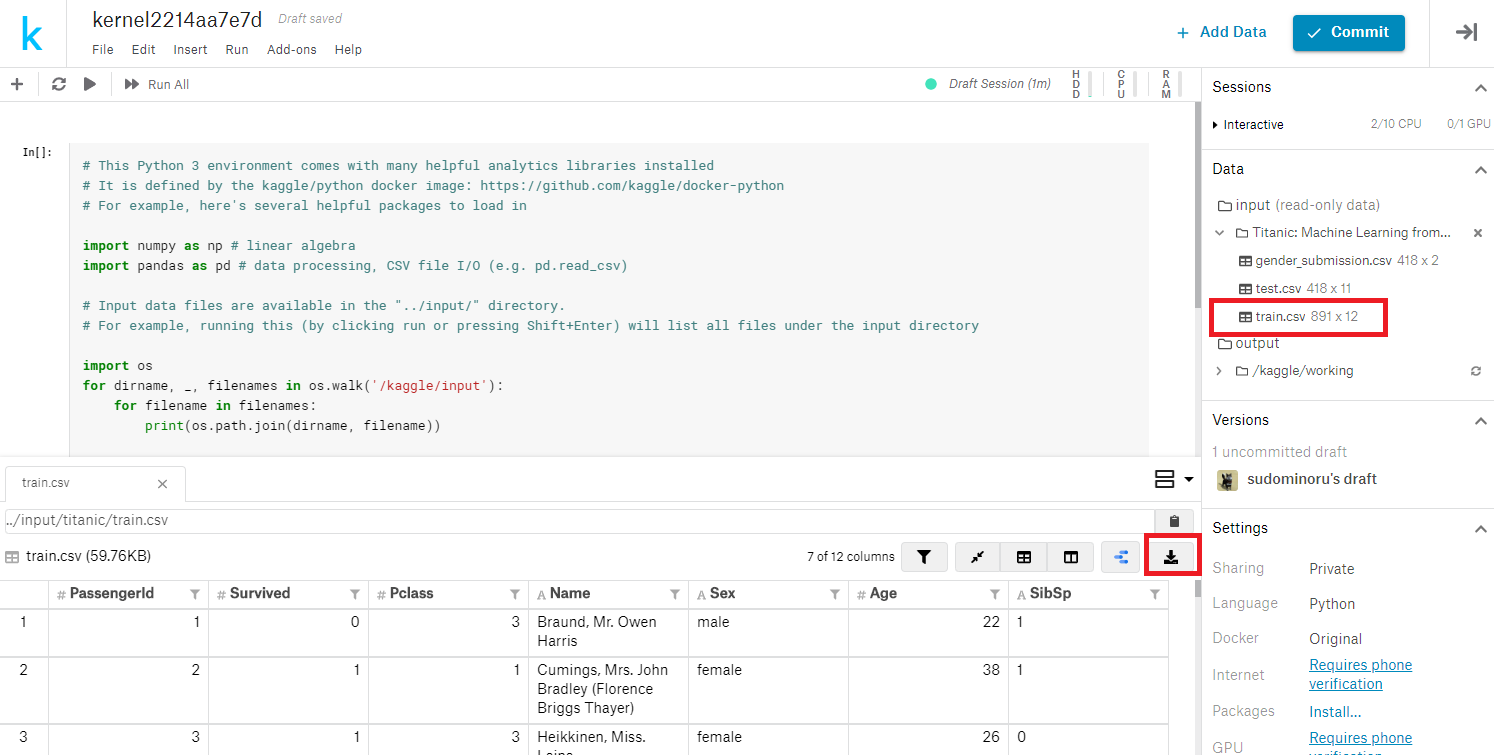
train.csvを確認します。
コードが書けますので、pandas.head() コマンドでデータを出力することもできますが、ダウンロードもできるのでダウンロードしてみましょう。
train.csvをクリックすると、画面したに100行のデータが表示されます。ダウンロードボタンでダウンロードできます。
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, | male | 22 | 1 | 0 | A/5 21171 | 7.25 | S | |
| 2 | 1 | 1 | Cumings, | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.925 | S | |
| 4 | 1 | 1 | Futrelle, | female | 35 | 1 | 0 | 113803 | 53.1 | C123 | S |
| 5 | 0 | 3 | Allen, | male | 35 | 0 | 0 | 373450 | 8.05 | S | |
| 6 | 0 | 3 | Moran, | male | 0 | 0 | 330877 | 8.4583 | Q | ||
| 7 | 0 | 1 | McCarthy | male | 54 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 8 | 0 | 3 | Palsson, | male | 2 | 3 | 1 | 349909 | 21.075 | S | |
| 9 | 1 | 3 | Johnson, | female | 27 | 0 | 2 | 347742 | 11.1333 | S | |
| 10 | 1 | 2 | Nasser, | female | 14 | 1 | 0 | 237736 | 30.0708 | C |
ExcelなどでCSVを確認します。
意味がよく分からない項目もありますが、コンペのDataに説明書きがあります。
余談ですが、OverViewの説明にあるように、サンプルの「gender_submission.csv」は「女性のみ生存した」とみなしているようです。確かに「test.csv」の「Sex」と「gender_submission.csv」の「Survived」の値が一致します。それで正解率「76%」とはなかなか手ごわいですね。
Data Dictionary
| Variable | Definition | 訳 | Key |
|---|---|---|---|
| survival | Survival | 生存 | 0 = No, 1 = Yes |
| pclass | Ticket class | チケットクラス | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | 性別 | |
| Age | Age in years | 年齢 | |
| sibsp | # of siblings / spouses aboard the Titanic | タイタニック号に乗る兄弟/配偶者の数 | |
| parch | # of parents / children aboard the Titanic | タイタニック号に乗る親/子供の数 | |
| ticket | Ticket number | チケットの番号 | |
| fare | Passenger fare | 旅客運賃 | |
| cabin | Cabin number | 客室番号 | |
| embarked | Port of Embarkation | 乗船港 | C = Cherbourg, Q = Queenstown, S = Southampton |
どの項目を学習に利用するか検討します。
「Survival」が問われている部分ですので、学習の答えとして利用します。
女性や子供は優先的に救命ボートに乗れる可能性が高いため「性別」「年齢」は利用します。
また、状況次第ですが裕福度が影響した可能性もあります。「チケットクラス」「旅客運賃」も利用してみましょう。
「名前」「チケット番号」「乗船港」は関係なさそうなので除外します。
問題は「sibsp」と「parch」です。
「sibsp」と「parch」をExcelなどで集計したところ、以下になりました。
関連はありそうですが、今回は簡単にするため除外しました。
sibsp(タイタニック号に乗る兄弟/配偶者の数)
| sibspの値 | Survival=1 | Survival=0 | 生存率 |
|---|---|---|---|
| 0 | 210 | 608 | 26% |
| 1 | 112 | 209 | 35% |
| 2 | 13 | 28 | 32% |
| 3 | 4 | 16 | 20% |
| 4 | 3 | 18 | 14% |
| 5 | 0 | 5 | 0% |
| 8 | 0 | 7 | 0% |
parch(タイタニック号に乗る親/子供の数)
| parchの値 | Survival=1 | Survival=0 | 生存率 |
|---|---|---|---|
| 0 | 233 | 678 | 26% |
| 1 | 65 | 118 | 36% |
| 2 | 40 | 80 | 33% |
| 3 | 3 | 5 | 38% |
| 4 | 0 | 4 | 0% |
| 5 | 1 | 5 | 17% |
| 6 | 0 | 1 | 0% |
3.1.必要な項目を抽出する
サンプルコードを削除し、以下のコードを記述します。
train.csvを読み込み、必要な項目('Survived', 'Pclass', 'Sex', 'Age', 'Fare')のみを抽出します。
import numpy
import pandas
##############################
# データ前処理 1
# 必要な項目を抽出する
##############################
# train.csvを読み込む
df_train = pandas.read_csv('/kaggle/input/titanic/train.csv')
df_train = df_train.loc[:, ['Survived', 'Pclass', 'Sex', 'Age', 'Fare']]
df_train.head()
| index | Survived | Pclass | Sex | Age | Fare |
|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22 | 7.25 |
| 1 | 1 | 1 | female | 38 | 71.2833 |
| 2 | 1 | 3 | female | 26 | 7.925 |
| 3 | 1 | 1 | female | 35 | 53.1 |
| 4 | 0 | 3 | male | 35 | 8.05 |
必要な項目のみ抽出できました。
3.2.欠損値を処理する
欠損値がないか確認します。
##############################
# データ前処理 2
# 欠損値を処理する
##############################
# 欠損値がないか確認する
df_train.isnull().sum()
| 列 | カウント |
|---|---|
| Survived | 0 |
| Pclass | 0 |
| Sex | 0 |
| Age | 177 |
| Fare | 0 |
年齢がないデータが多いです。
可能であれば欠損値を埋めたりしますが、今回は削除します。
# 年齢がnullの行を削除する
# Delete rows with null age
df_train = df_train.dropna(subset=['Age']).reset_index(drop=True)
len(df_train)
| カウント |
|---|
| 714 |
年齢がnullの行が削除されました。
3.3.ラベルを数値化する
性別の「male」「female」はそのままでは扱いにくいので、数値化します。
male、femaleの2種類しかないので自分で変換してもよいのですが、scikit-learnには LabelEncoder という便利なクラスが用意されているので利用してみます。
LabelEncoder:fitメソッド、fit_transformメソッドは、入力に現れる文字列がN種類あるときに、それぞれに文字列を0からN-1までの整数に置き換える。
##############################
# データ前処理 3
# ラベル(名称)を数値化する
##############################
from sklearn.preprocessing import LabelEncoder
# 性別をLabelEncoderを利用して数値化する
encoder = LabelEncoder()
df_train['Sex'] = encoder.fit_transform(df_train['Sex'].values)
df_train.head()
| index | Survived | Pclass | Sex | Age | Fare |
|---|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 22 | 7.25 |
| 1 | 1 | 1 | 0 | 38 | 71.2833 |
| 2 | 1 | 3 | 0 | 26 | 7.925 |
| 3 | 1 | 1 | 0 | 35 | 53.1 |
| 4 | 0 | 3 | 1 | 35 | 8.05 |
「Sex」が数値化されました。
このエンコーダは、後でtest.csvのsexを数値化するときにも利用します。
3.4.数値を標準化する
数値はそのまま学習データとして投入するより、尺度をあわせる(標準化)した方がうまく学習できるケースが多いようです。
例えば、試験の成績を分析する場合に、点数(100点満点、200点満点)で分析するより、偏差値で分析したほうが分かりやすい、といったところでしょうか。
「年齢」と「運賃」を標準化してみます。
標準化もラベルエンコードと同様にscikit-learnに便利なクラスがあります。 StandardScaler です。
##############################
# データ前処理 4
# 数値を標準化する
# Data preprocessing 4
# Standardize numbers
##############################
from sklearn.preprocessing import StandardScaler
# 標準化
# Standardize numbers
standard = StandardScaler()
df_train_std = pandas.DataFrame(standard.fit_transform(df_train.loc[:, ['Age', 'Fare']]), columns=['Age', 'Fare'])
# Age を標準化
# Standardize Age
df_train['Age'] = df_train_std['Age']
# Fare を標準化
# Standardize Fare
df_train['Fare'] = df_train_std['Fare']
df_train.head()
| index | Survived | Pclass | Sex | Age | Fare |
|---|---|---|---|---|---|
| 0 | 0 | 3 | 1 | -0.530376641 | -0.518977865 |
| 1 | 1 | 1 | 0 | 0.571830994 | 0.69189675 |
| 2 | 1 | 3 | 0 | -0.254824732 | -0.506213563 |
| 3 | 1 | 1 | 0 | 0.365167062 | 0.348049152 |
| 4 | 0 | 3 | 1 | 0.365167062 | -0.503849804 |
年齢と運賃が標準化されました。
ここまでで、データ整備が完了しました。
4.モデルを構築する
データの準備が完了したら、モデルの構築に移ります。
とりあえずは、sckit-learnで構築してみましょう。
以下は、sckit-learnサイトにある、アルゴリズム選択のフローチャートです。
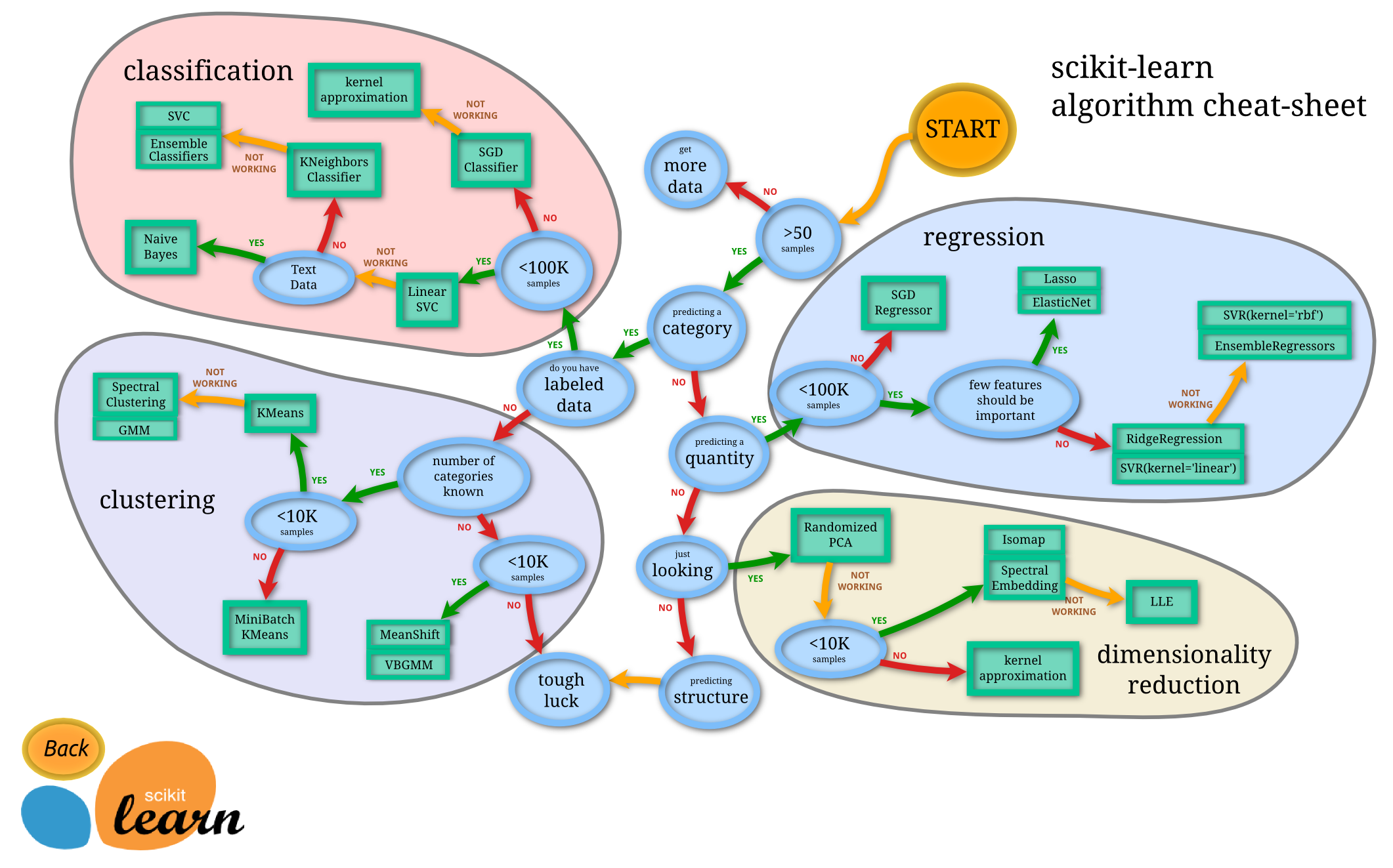
このフローチャートにそって、モデルを選択してみましょう。
「カテゴリ分け」YES ⇒「ラベルデータあり」Yes で、左上の「classification」に進みます。
「クラス分類 教師あり学習」に当たるかと思います。
チャートでは「Linear SVC」になりました。
学習する時には、学習するデータ(=x_train)と、答え(=y_train)を分けてモデルに渡します。
以下のようなイメージです。
| y_train | x_train | ||||
|---|---|---|---|---|---|
| index | Survived | Pclass | Sex | Age | Fare |
| 0 | 0 | 3 | 1 | -0.530376641 | -0.518977865 |
| 1 | 1 | 1 | 0 | 0.571830994 | 0.69189675 |
| 2 | 1 | 3 | 0 | -0.254824732 | -0.506213563 |
| 3 | 1 | 1 | 0 | 0.365167062 | 0.348049152 |
| 4 | 0 | 3 | 1 | 0.365167062 | -0.503849804 |
コードは以下です。
##############################
# モデルの構築
##############################
from sklearn.svm import LinearSVC
# トレーニングデータを準備する
x_train = df_train.loc[:, ['Pclass', 'Sex', 'Age', 'Fare']].values
y_train = df_train.loc[:, ['Survived']].values
# y_train の次元を削除
y_train = numpy.reshape(y_train,(-1))
# モデルを生成する
model = LinearSVC(random_state=1)
5.トレーニングデータで学習する
学習は、モデルにトレーニングデータを渡すだけです。
##############################
# 学習
##############################
model.fit(x_train, y_train)
6.テストデータで結果を予想する
学習の結果をテストデータで見てみます。
test.csvをトレーニングデータ(x_train)と同じような形にする必要があります。
年齢、運賃の欠損がありますが、欠損してても結果は予想する必要があります。
テストデータの場合は削除せず「0」に変換します。
##############################
# test.csv を変換する
# convert test.csv
##############################
# test.csvを読み込む
# Load test.csv
df_test = pandas.read_csv('/kaggle/input/titanic/test.csv')
# 'PassengerId'を抽出する(結果と結合するため)
df_test_index = df_test.loc[:, ['PassengerId']]
# 'Survived', 'Pclass', 'Sex', 'Age', 'Fare'を抽出する
# Extract 'Survived', 'Pclass', 'Sex', 'Age', 'Fare'
df_test = df_test.loc[:, ['Pclass', 'Sex', 'Age', 'Fare']]
# 性別をLabelEncoderを利用して数値化する
# Digitize gender using LabelEncoder
df_test['Sex'] = encoder.transform(df_test['Sex'].values)
df_test_std = pandas.DataFrame(standard.transform(df_test.loc[:, ['Age', 'Fare']]), columns=['Age', 'Fare'])
# Age を標準化
# Standardize Age
df_test['Age'] = df_test_std['Age']
# Fare を標準化
# Standardize Fare
df_test['Fare'] = df_test_std['Fare']
# Age, Fare のNanを0に変換
# Convert Age and Fare Nan to 0
df_test = df_test.fillna({'Age':0, 'Fare':0})
df_test.head()
| Index | Pclass | Sex | Age | Fare |
|---|---|---|---|---|
| 0 | 3 | 1 | 0.298549339 | -0.497810518 |
| 1 | 3 | 0 | 1.181327932 | -0.512659955 |
| 2 | 2 | 1 | 2.240662243 | -0.464531805 |
| 3 | 3 | 1 | -0.231117817 | -0.482887658 |
| 4 | 3 | 0 | -0.584229254 | -0.417970618 |
テストデータも同じように変換できました。
結果を予想します。
テストデータを渡し、predict するだけです。
##############################
# 結果を予想する
# Predict results
##############################
x_test = df_test.values
y_test = model.predict(x_test)
y_test に結果が入っています。
結果を gender_submission.csv と同じ形式で保存します。
# PassengerId のDataFrameと結果を結合する
# Combine the data frame of PassengerId and the result
df_output = pandas.concat([df_test_index, pandas.DataFrame(y_test, columns=['Survived'])], axis=1)
# result.csvをカレントディレクトリに書き込む
# Write result.csv to the current directory
df_output.to_csv('result.csv', index=False)
以上で結果取得までできました。
前回と同様「Commit」で実行してみます。
実行完了後「Open Viersion」をクリックします。
result.csvが作成されていることが確認できます。
「Submit to Competition」をクリックし、提出してみましょう。
どうなるでしょうか・・・
7.提出した結果
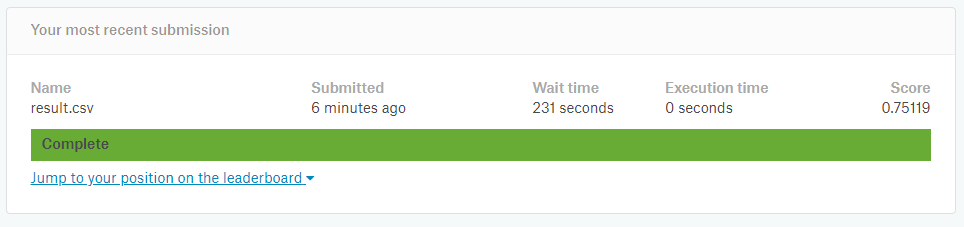
「0.75119」という結果になりました。75%です。
サンプルデータより悪くなっていますね^^;
8.まとめ
いかがだったでしょうか。
学習のパラメータ調整などは全く行いませんでしたが、学習の流れは理解できてました。
次回はもう少しいいスコアになるよう、データの精査や、学習パラメータを見ていきます。
履歴
2019/12/11 初版公開
2019/12/26 次回のリンク設置
2020/01/03 ソースのコメント修正
2020/03/26 「6.テストデータで結果を予想する」のソースコード一部修正