本記事は@claviers2kさんの以下の記事のWindows&完全ローカル版となります。
Docker版Ollama、LLMには「Phi3-mini」、Embeddingには「mxbai-embed-large」を使用し、OpenAIなど外部接続が必要なAPIを一切使わずにRAGを行ってみます。
対象読者
- Windowsユーザー
- CPUのみ(GPUありでも可)
- ローカルでRAGを実行したい人
- Proxy配下
実行環境
- Windows10 メモリ32G(16GあればOK) GPUなし
- Ubuntu24.04 on WSL2
- VSCode + Rye (Python3.12.4)
目次
- WSL+Ubuntu+Docker環境のセットアップ
- VSCodeのインストール
- VSCodeにWSL拡張をインストール
- Ollama(Docker版)のインストール
- LLMモデルのダウンロードと実行
- Embeddingモデルのダウンロード
- Ryeのインストール
- VSCode+RyeでRAGスクリプトを編集・実行
- Phi3を使用して回答させる
WSL+Ubuntu+Docker環境のセットアップ
以下の記事を参考にWSL+Docker環境を構築してください。
VSCodeのインストール
WindowsにVisual Studio Codeをインストールしてください。
VSCodeにWSL拡張をインストール
VSCodeを起動し、以下のように「WSL」という拡張機能をインストールしてください。
- 画面左側の拡張機能アイコンをクリック
- 検索欄に「wsl」と入力
- 下図の「WSL」拡張を選択し、「インストール」

この拡張機能をインストールすることで、WSLのUbuntu内のファイルをVSCodeで編集できるようになります。
Ollama(Docker版)のインストール
公式の手順はこちらです。
本記事では、公式の手順に以下の2つのオプションを追加指定しています。
-
-eで環境変数HTTPS_PROXYを指定 -
--restart alwaysの追加
変数 ${HTTP_PROXY} の HTTP_PROXY は、冒頭のWSL環境構築手順 にある .bashrc ファイル内で宣言している環境変数です。(Proxy配下にない場合は不要です)
--restart always は、コンテナを自動的に開始するオプションです。指定しない場合、Ubuntuの起動時に毎回Ollamaコンテナを起動する必要があります。
CPUのみ使用する場合はCPU編を、GPUを使用する場合はGPU編を行ってください。
Ollamaのインストール:CPU編
1. Docker版Ollamaのインストール(GPU対応なし)
docker run -d -v ollama:/root/.ollama -e HTTPS_PROXY=${HTTP_PROXY} -p 11434:11434 --name ollama --restart always ollama/ollama
Ollamaのインストール:GPU編
1. Nvidia container toolkit のインストール
公式の手順通り、最初に Nvidia container toolkit をインストールします。
「Installing with Apt」の部分を実行していきます。
1. Configure the production repository:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
2. Update the packages list from the repository:
sudo apt-get update
3. Install the NVIDIA Container Toolkit packages:
sudo apt-get install -y nvidia-container-toolkit
次に、「Configuration」の部分を実行していきます。
1. Configure the container runtime by using the nvidia-ctk command:
sudo nvidia-ctk runtime configure --runtime=docker
2. Restart the Docker daemon:
sudo systemctl restart docker
2. Docker版Ollamaのインストール(GPU対応あり)
docker run -d --gpus=all -v ollama:/root/.ollama -e HTTPS_PROXY=${HTTP_PROXY} -p 11434:11434 --name ollama --restart always ollama/ollama
Ollamaのインストール後、Ollamaが動作しているか確認します。
docker ps
として、
user@Ubuntu2404:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9d53267f9bb6 ollama/ollama "/bin/ollama serve" 4 minutes ago Up 4 minutes 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama
のように出ればOKです。
LLMモデルのダウンロードと実行
Ollamaで使用するモデルをダウンロードして実行してみます。
本記事では、軽量なモデル(「SLM」とも呼ばれる)「Phi-3-mini」を使用します。
Phi-3は公式的には日本語をサポートしていないようですが、そこは無視してやっていきます。
モデルの検索
Ollamaの「Models」にある検索欄に「phi3」と入力します。
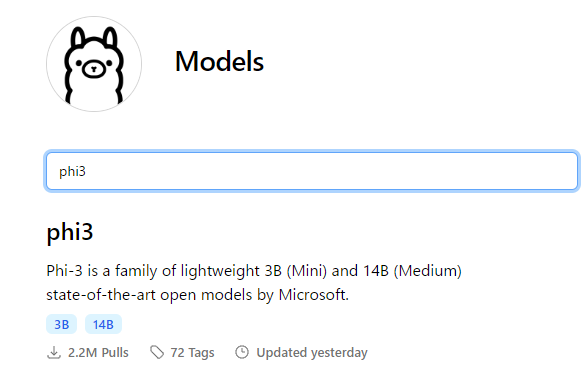
Ollamaのモデルは、デフォルトでは「Q4_0」という量子化されたモデルとなっています。「量子化」とは、情報を圧縮して軽量化することです。
ただし、「Q4_0」は4bit量子化でやや圧縮率が高く、量子化手法としても「レガシー」であり、「かなり大幅な質低下」があるとされています。(参照)
というわけで、Ollamaでモデルを選ぶときは「Q5_K_M」(かなりわずかな質低下【推奨】)を選んでいきます。
下図のように、プルダウンをクリックして「View more」をクリックします。
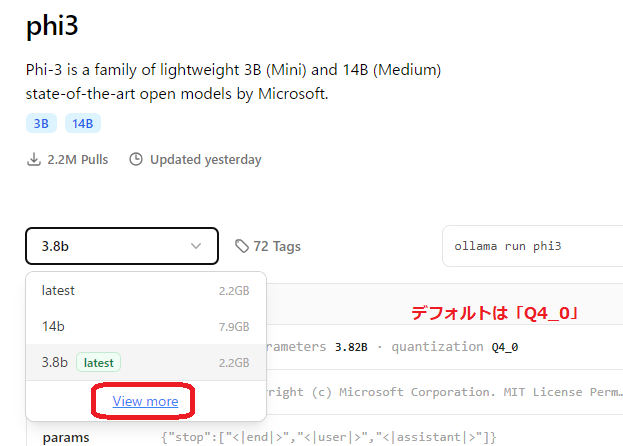
選択肢に128kと4kがありますが、これらはコンテキストウィンドウサイズの違いです。
今回はコンテキストウィンドウ(プロンプトの最大長)は小さくても問題ないため、
「3.8b-mini-4k-instruct-q5_K_M」(2.8G)を選択します。
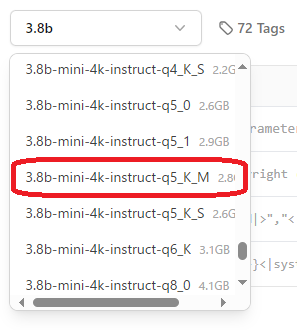
プルダウン選択後、下図の赤枠の部分をクリックしてモデルを実行するコマンド全体をコピーします。
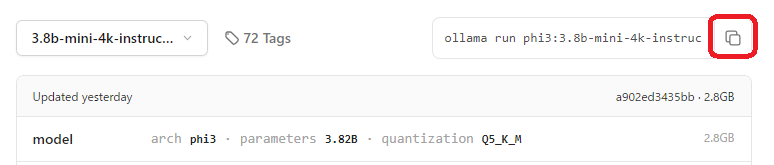
コピーしたコマンド ollama run phi3:3.8b-mini-4k-instruct-q5_K_M は、Ollamaのコンテナに入った状態で実行する形式であるため、コンテナ外部からモデルを実行する際は次のようにします。
docker exec -it ollama ollama run phi3:3.8b-mini-4k-instruct-q5_K_M
このコマンドを実行すると、ダウンロード済みでないモデルの場合は最初にダウンロードから始まります。
「>>>」表示になったらチャットできる状態です。
適当に文字を入力してみてください。
pulling manifest
pulling 7d6aeaf84a4a... 100% ▕████████████████████████████████████████████▏ 2.8 GB
pulling fa8235e5b48f... 100% ▕████████████████████████████████████████████▏ 1.1 KB
pulling 542b217f179c... 100% ▕████████████████████████████████████████████▏ 148 B
pulling 8dde1baf1db0... 100% ▕████████████████████████████████████████████▏ 78 B
pulling 67e3e6fd8c63... 100% ▕████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> こんにちは
こんにちは!お元気ですか?今日の天気はどうですか?
前述の通りPhi3は表向きには日本語がサポートされていませんが、日本語で返してくれました。
/bye
と打ち込んでチャットを終了させます。
Embeddingモデルのダウンロード
RAGを行うためにはEmbeddingという処理が必要になります。
Embeddingとは、「意味の数値化」を行うことです。
詳しいことは@Detroitさんの記事等をご参照ください。
Embeddingを行うには、Embedding用のモデルを使用します。
OpenAIにEmbedding用モデルがいくつかあるように、OllamaにもEmbedding用モデルがいくつかあります。
| モデル種別 | OpenAI | Ollama |
|---|---|---|
| LLM | GPT-4o GPT-4o-mini ... |
Phi3 llama3.1 gemma2 ... |
| Embedding | text-embedding-3-large text-embedding-3-small text-embedding-ada-002 |
mxbai-embed-large nomic-embed-text all-minilm |
使用するEmbeddingモデルの違いによって「意味を数値化」した際の数値が異なってきます。そのため、Embeddingモデルの違いによってRAGの性能が左右されることになります。
前置きが長くなりましたが、本記事ではEmbeddingモデルとして mxbai-embed-large を使用します。
以下のようにOllamaのpullコマンドを実行します。
docker exec -it ollama ollama pull mxbai-embed-large
Ryeのインストール
Python環境として「Rye」を使用しますので、公式のLinux用インストール手順通りにインストールします。
curl -sSf https://rye.astral.sh/get | bash
いくつか対話形式でインストール/設定が進んでいきますが、「yes」およびすべてデフォルトの選択でOKです。
Ryeのインストール後はUbuntuへの再ログインが必要になります
VSCode+RyeでRAGスクリプトを編集・実行
新規プロジェクトの作成
Ryeで新規プロジェクトを作成するには、rye init コマンドを実行します。
rye init を行うことで、
- 指定した名称のフォルダを作成
- そのフォルダにPythonの仮想環境を作成
してくれます。つまりこのフォルダがプロジェクトフォルダとなります。
今回は以下のように実行します。
rye init myrag
プロジェクトフォルダに入ってVSCodeを起動
cd myrag
でプロジェクトフォルダに入り、次のコマンドでVSCodeが起動するか確認します。
code .
初回実行時のみ、「VS Code Server for Linux」のダウンロードが行われるため少し時間がかかります
以下のダイアログが表示されたら、チェックを入れて「はい」を選択します。
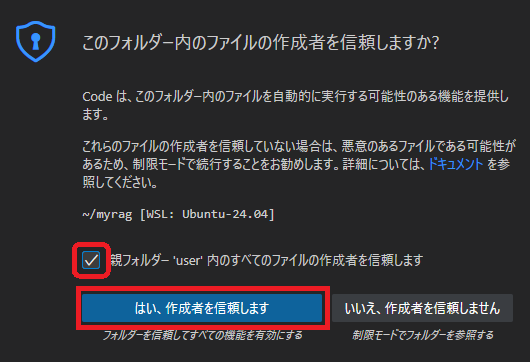
ここまでの操作で下図のようになっていればOKです。
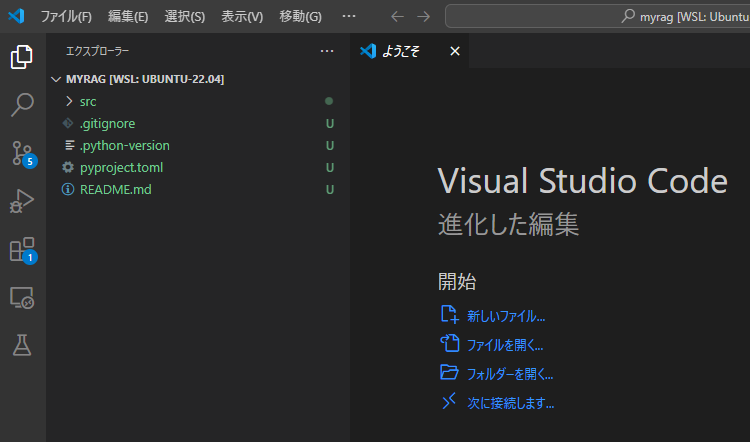
.pyファイルの新規作成
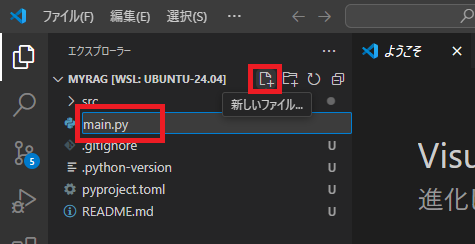
VSCodeのエクスプローラーで「+」アイコン(新しいファイル)をクリックし、ファイル名として「main.py」と入力します。(ファイル名は任意)
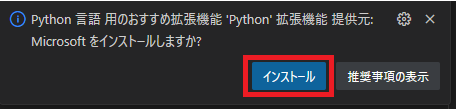
*.pyファイルを作成後、VSCodeの画面右下あたりに「Python 言語用のおすすめ拡張機能」のダイアログが出たら、「インストール」してください。
ryeで必要なパッケージを追加
VSCodeの画面右上の赤枠の部分をクリックし、下図のように「ターミナル」タブを表示した状態にします。
「ターミナル」タブにて、次項のプログラムに必要なパッケージをryeで追加・インストールします。
rye add ollama scikit-learn
パッケージ追加後は、rye syncコマンドを実行してパッケージをインストールします。
2024年8月5日追記:以下のコマンド rye sync は不要です。
rye sync
上記のRyeのインストール時、すべてデフォルト選択でインストールすると、パッケージインストーラとしてデフォルトでは uv が選択されています。
uv を選択した場合は 2024年2月23日リリースの 0.26.0 以降、rye add または rye remove コマンド実行時に auto-syncが実行されるため rye sync は不要になりました。
プログラミング
以下のプログラムは、@claviers2k さんのサンプルをそのまま使用させていただき、OpenAIのAPIに関わる部分だけをOllamaに置き換えたサンプルです。
import ollama
from sklearn.metrics.pairwise import cosine_similarity
def vectorize_text(text):
response = ollama.embeddings(
model="mxbai-embed-large",
prompt=text
)
return response["embedding"]
# 回答データベース
answers = [
"システム運用事業部",
"販売管理システム",
"第一システム部",
"システム開発事業部"
]
# 回答の埋め込みベクトルを取得
answers_vector = [vectorize_text(answer) for answer in answers]
def rag_sample(question):
# 質問の埋め込みベクトルを取得
question_vector = vectorize_text(question)
# コサイン類似度が最も高い回答を取得
max_similarity = 0
most_similar_index = 0
for index, vector in enumerate(answers_vector):
similarity = cosine_similarity([question_vector], [vector])[0][0]
print(f"コサイン類似度: {similarity.round(4)}:{answers[index]}")
# 取り出したコサイン類似度が最大のものを保存
if similarity > max_similarity:
max_similarity = similarity
most_similar_index = index
print(f"\n質問: {question}\n回答: {answers[most_similar_index]}\n")
if __name__ == '__main__':
# 質問文
question1 = "株式会社ABCの開発を行う事業部は?"
question2 = "株式会社ABCの運用を行う事業部は?"
question3 = "売上を管理するシステムは?"
rag_sample(question1)
rag_sample(question2)
rag_sample(question3)
RAGを実行
VSCodeのターミナルタブにて、以下のようにプログラム(main.py)を実行します。
rye run python main.py
mxbai-embed-large を使ったEmbeddingでは、以下のような結果となりました。
コサイン類似度: 0.7533:システム運用事業部
コサイン類似度: 0.6071:販売管理システム
コサイン類似度: 0.6994:第一システム部
コサイン類似度: 0.7896:システム開発事業部
質問: 株式会社ABCの開発を行う事業部は?
回答: システム開発事業部
コサイン類似度: 0.7572:システム運用事業部
コサイン類似度: 0.6087:販売管理システム
コサイン類似度: 0.7009:第一システム部
コサイン類似度: 0.7675:システム開発事業部
質問: 株式会社ABCの運用を行う事業部は?
回答: システム開発事業部
コサイン類似度: 0.7773:システム運用事業部
コサイン類似度: 0.7138:販売管理システム
コサイン類似度: 0.7973:第一システム部
コサイン類似度: 0.7897:システム開発事業部
質問: 売上を管理するシステムは?
回答: 第一システム部
OpenAIのEmbeddingモデルを使用した結果とは異なることがわかります。
2番目の回答は「システム運用事業部」になって欲しいところですが、微妙な差で「システム開発事業部」となったようです。
Phi3を使用して回答させる
上記の例では質問に対して回答を固定的にprintしているだけなので、Phi3を使用して回答させてみます。
プログラムを以下のように変更してみました。
「回答データベース」の部分についても少し情報を追加しました。
import ollama
from sklearn.metrics.pairwise import cosine_similarity
def vectorize_text(text):
response = ollama.embeddings(
model="mxbai-embed-large",
prompt=text
)
return response["embedding"]
# 回答データベース
answers = [
"システム運用事業部では、各種システムの運用・保守業務を行います",
"販売管理システムは、各種商品とその売り上げを管理します",
"第一システム部は、主に製品Xを担当する部署です",
"システム開発事業部では、各種システムの設計・開発業務を行います"
]
# 回答の埋め込みベクトルを取得
answers_vector = [vectorize_text(answer) for answer in answers]
def rag_sample(question):
# 質問の埋め込みベクトルを取得
question_vector = vectorize_text(question)
# コサイン類似度が最も高い回答を取得
max_similarity = 0
most_similar_index = 0
for index, vector in enumerate(answers_vector):
similarity = cosine_similarity([question_vector], [vector])[0][0]
#print(f"コサイン類似度: {similarity.round(4)}:{answers[index]}")
# 取り出したコサイン類似度が最大のものを保存
if similarity > max_similarity:
max_similarity = similarity
most_similar_index = index
#print(f"\n質問: {question}\n回答: {answers[most_similar_index]}\n")
prompt = f"""
次の質問について、情報を基に簡潔に回答して下さい。
# 質問
{question}
# 情報
{answers[most_similar_index]}
# 回答
"""
print(prompt)
stream = ollama.generate(
model="phi3:3.8b-mini-4k-instruct-q5_K_M",
prompt=prompt,
stream=True
)
for chunk in stream:
c = chunk['response']
print(c, end='', flush=True)
if __name__ == '__main__':
# 質問文
question1 = "株式会社ABCの開発を行う事業部は?"
question2 = "株式会社ABCの運用を行う事業部は?"
question3 = "売上を管理するシステムは?"
rag_sample(question1)
rag_sample(question2)
rag_sample(question3)
結果は以下のようになりました。
次の質問について、情報を基に簡潔に回答して下さい。
# 質問
株式会社ABCの開発を行う事業部は?
# 情報
システム開発事業部では、各種システムの設計・開発業務を行います
# 回答
株式会社ABCの株式会社ABCの開発を行う事業部は、システム開発事業部です。
次の質問について、情報を基に簡潔に回答して下さい。
# 質問
株式会社ABCの運用を行う事業部は?
# 情報
システム開発事業部では、各種システムの設計・開発業務を行います
# 回答
株式会社ABCの運用を行う事業部はシステム開発事業部です。
-----
次の質問について、情報を基に簡潔に回答して下さい。
# 質問
売上を管理するシステムは?
# 情報
販売管理システムは、各種商品とその売り上げを管理します
# 回答
販売管理システム
まとめ
Ollamaを使用してローカル環境でRAGを実行できました。
しかし一部の回答が期待する結果とはなりませんでした。
RAGの精度はEmbeddingモデルによって左右されることがわかりました。
謝辞
@claviers2kさん、勝手ながら記事・プログラムを流用させていただきました。ありがとうございました。