はじめに
前回の記事では、LangGraphを使って簡単なDFA(有限オートマトン)を実装することで、その仕組みや使い方を学びました。
LangGraphの仕組みに少しずつ慣れてきたので、今回は一歩踏み込んで「LLM(大規模言語モデル)とのしりとり対戦」プログラムに挑戦してみました。
ゲームの概要
今回作成したしりとり対戦ゲームの主な流れは以下の通りです。
- ユーザーが単語を入力する
- 入力された単語がしりとりのルールに違反していないかチェックする
- 「ん」で終わっていないか?
- 既出の単語ではないか?
- 前の単語とつながっているか?
- ルール違反があればユーザーの負け
- ルールOKなら、次はAI(Gemini)が単語を考える
- AIが考えた単語をルールチェックする
- ルール違反があればAIの負け(ユーザーの勝ち)
- ルールOKなら、再びユーザーのターンに戻る
この一連の流れを、LangGraphの状態遷移グラフとして実装しました。
ノートブックはこちら
公開当初のノートブック
llmの手番で末尾「ん」チェックしてない問題修正版
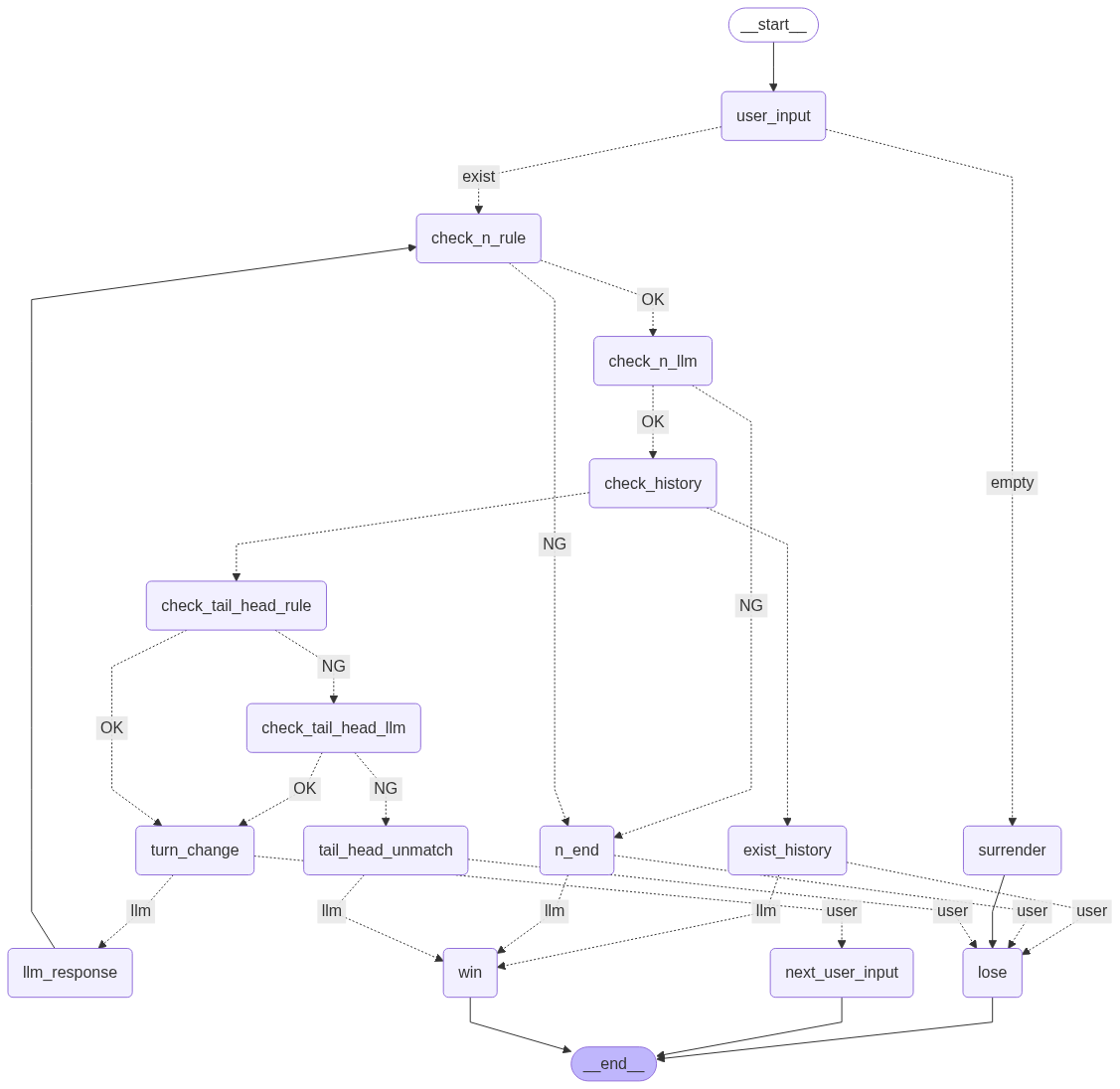
グラフの全体像
LangGraphで実装したグラフの全体像は以下のようになります。各ノードが処理のステップを表し、矢印が状態の遷移を表しています。
公開当初のグラフ
llmの手番で末尾「ん」チェックしてない問題修正版
主要なノード(処理ステップ)の実装
1. AI(Gemini)の応答
AIがしりとりの単語を考えるノードです。現在の状態(直前の単語、履歴)をプロンプトに含めて、Gemini APIに問い合わせます。
# llm応答ステップ
def llm_step(state: ShiritoriState):
prompt = f'''以下の条件に従って、しりとりの単語を1つ出してください。
- 前の単語: {state['last_word']}
- 使用済み単語: {", ".join(state['history'])}
- 「ん」で終わらないこと
- 再使用禁止
単語だけを返してください。'''
reply = gemini_reply(prompt)
word = re.findall(r'\w+', reply)[0] # 最初の単語を取得
print(f"Geminiの単語: {word}")
state["input_word"] = word
state["user_turn"] = False
return state
2. ルールチェック(LLMの活用)
しりとりのルールチェックは、単純な文字列比較だけでは難しい場合があります。例えば、「公園(こうえん)」が「ん」で終わることや、「駱駝(らくだ)」が「ら」で始まることなどを判定するには、単語の「読み」が必要です。
そこで、この判定部分にLLM(Gemini)を活用します。
「ん」で終わるかの判定
check_n_llm ノードでは、入力された単語が読み方として「ん」で終わるかをGeminiに判定させます。
def routing_check_n_llm(state: ShiritoriState):
prompt = f'''しりとりにおいて、今回の単語が「ん」で終わっているかどうかを判定してください。
【ルール】
- カタカナ、ひらがな、漢字といった表記は無視して読み方の最後の文字で判断してください。
- たとえば「饂飩」などは読み方が「うどん」なので「ん」で終わっているためNGです。
【今回の単語】:{state['input_word']}
【出力フォーマット】
次のJSON形式で出力してください:
{{
"n_end": true, // または false
"reason": "ここに簡潔な理由を記述"
}}
'''
# (API呼び出しとJSONパース処理)
# ...
if not result["n_end"]:
return "OK"
else:
return "NG"
単語のつながり判定
同様に、check_tail_head_llm ノードでは、前の単語の最後の文字と、今回の単語の最初の文字が(読み方として)一致しているかを判定させます。
def routing_check_tail_head_llm(state: ShiritoriState):
prompt = f'''しりとりにおいて、前の単語と今回の単語が正しくつながっているかを判定してください。
【ルール】
- 単語の最初の文字は、前の単語の最後の文字と一致している必要があります。
- ...
- カタカナ、ひらがな、漢字といった表記は無視して読み方の最後の文字で判断してください。
- たとえば「らっこ」→「コップ」などは有効。
【前の単語】:{state['last_word']}
【今回の単語】:{state['input_word']}
【出力フォーマット】
...
'''
# (API呼び出しとJSONパース処理)
# ...
if result["valid_connection"]:
return "OK"
else:
return "NG"
このように、ルールベースでは実装が面倒な「読み」に関する判定をLLMに任せることで、より自然なしりとりを実現しています。
実行結果
実際に動かしてみると、このようにAIとの対話形式でゲームが進行します。
あなたの単語(終了(投了)は空のままエンター): リンゴ
Geminiの単語: ゴリラ
あなたの単語(終了(投了)は空のままエンター): 駱駝
Geminiの単語: だちょう
あなたの単語(終了(投了)は空のままエンター): 運
'運' は「ん」で終わったためゲームオーバーです。
あなたの負けです
まとめ
LangGraphを使うことで、LLMの柔軟な判断力も必要とするアプリケーションを、状態遷移のグラフとして非常に見通し良く実装できました。
各ステップが独立したノードの形で実装できるため、機能の追加や修正も容易そうです。
より良いしりとりになるように以下のチェックの追加をしていきたいです。
「ユーザーが単語ではなく文章を入力した場合は負けにする」
「既出単語のチェック時に表記ゆれ(ひらがな、カタカナ、漢字)も考慮する」
修正
7/2 19:55頃 llmの手番で末尾「ん」チェックしてない問題 を修正
7/8 23:10頃 単語ではなく文章を入力した場合は負けにする チェックを追加