弊社では、お客様のデータドリブンな意思決定ができる体制作りをサポートするために、最適なデータ基盤を検討し、構築しています。それと並行してデータが蓄積された後の話、すなわちデータ活用の方法についてもDX人材育成という枠組みの中でサポートさせていただいています。DX人材というとマインドセット的な話に終始してしまうケースもありがちで、それも必要なことだと思いますが、個人的には業務を変えることができる総合的な能力を持つ人材・チームを指すと思います。
今回はデータ活用の強力な手段となり得るBigQuery MLの使い方を紹介したいと思います。
この記事を読むことで
- Big Query MLでモデル作成〜使用までの一連の流れが分かる
- 一連の構文の構造が理解できる(ほぼほぼ通常のSQL)
- 自身の業務課題とBigQuery ML利用を繋げるシナプスが形成される
と思います。
今回はGoogleの公開データセットを用いて、コードを実行できるように準備しました。
機械学習を手軽に使ってみたいという方にも、Python等で自分でモデル作成できるけど色々な手段を知りたいという方にも、読んでいただけると嬉しいです。
BigQuery MLとは?
BigQuery MLは、Google Cloudが提供するDWHであるBigQuery上で、機械学習モデルを作成・評価・利用ができるサービスです。BigQuery上で動作するため、大規模データを対象としたモデルが容易に作成できます。
また、作成したモデルはGoogle Cloud上で管理することができるので、Google Cloudのサービスを利用したMLOpsでの運用も容易です。
今回のシチュエーション
使用するデータ
今回はGoogleが公開しているシカゴのタクシー記録のデータセットを利用します。
<公開データセット>
Chicago Taxi Trips
<データセット名>
bigquery-public-data.chicago_taxi_trips.taxi_trips
解決したい課題
今回私はタクシー運転手です。タクシー運転手は歩合制でなのですが、私の会社は歩合率が小さく、頑張ってたくさんのお客さんを乗せても、それがあまり給料に反映されません。しかしチップであれば100%自分の手元に残るため、お客さんを選り好みすることで、より効率よく稼げるのではと思いました。
チップをくれるお客さんは全体で4割程度とデータは十分にあるので、今あるデータの範囲で検証してみます。
本記事はBiqQuery MLの利用手順が主題であるため、作成するモデルは現実課題と乖離している部分がある点はご了承ください。しかし、このように個人的に思いついたことを、すぐに実践できることがBigQuery MLの利点です。実際の業務の中の個人の思いつきを気軽に実践できる環境がDX推進に必要だと思います(今回は邪な動機ですが)。
それでは、モデルの作成・評価・予測の順番でBiqQuery MLを使い方を紹介します。
作成するモデル
過去のデータセットからお客さんが「チップをくれそう」「くれなさそう」というのを判断するモデルをこっそり作成します。
全体の流れ
全体はモデル作成・モデル評価・予測という流れで、それぞれ以下のステートメント・関数を使用します
-
CREATE MODELステートメントを使用して、2 項ロジスティック回帰モデルを作成する -
ML.EVALUATE関数でモデルを評価する -
ML.PREDICT関数でモデルを使用して予測を行う
モデル作成
まずはモデルの作成手順を紹介します。まずは基本的な構文でモデル作成の全体像を示した後に、具体的にテーブルを用いてモデルを作成します。
基本的な構文
CREATE OR REPLACE MODEL 'モデル名'
OPTIONS(model_type = 'モデルの種類'
labels = ['is_tipped']) AS
# 一般的なSELECT文によるデータ抽出処理で学習データ指定
SELECT
〜
FROM
〜
WHERE
〜
先頭でモデル作成・モデル設定を指定する以外は、一般的なSQLのクエリそのままです。
model_typeで作成するモデルの種類を指定します。今回は「チップをもらえる」「もらえない」の判断なのでロジスティック回帰を指定しています。labelsでラベル(正解データ)となるカラムを指定します。デフォルトではlabelという名前のカラムが指定されていますが、毎回明記した方が分かりやすいと思います。
| モデル | クエリ | 用途 |
|---|---|---|
| ロジスティック回帰 | logstic_reg | 分類の予測 |
| 線形回帰 | linear_reg | 数値の予測 |
他にも様々な種類のモデルを作成できます。詳しくは参考資料の項目にも示しているGoogle Cloudのドキュメントを参照してください。
実際に作成する
今回の課題に合わせてモデルを作成します。通常のSQLと同じようにWHERE文を使ってデータをクレンジングします。移動距離10マイル未満の比較的短距離の移動に利用するお客さんに絞っています(3000マイル以上移動するお客さんもあり)。
CREATE OR REPLACE MODEL
`test_detaset.tip_prediction_model` OPTIONS ( model_type='logistic_reg',
labels = ['is_tipped'] ) AS
#standardSQL
SELECT
IF
(tips > 0, '1', '0') AS is_tipped,
CAST(CAST(EXTRACT(HOUR
FROM
trip_start_timestamp) / 6 AS INT) AS STRING) AS time_type,
CAST(CAST(trip_miles/2 AS INT) AS STRING) AS mile_type,
CAST(EXTRACT(DAYOFWEEK
FROM
trip_start_timestamp) AS STRING) AS weekday,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
RAND() < 0.001
AND trip_miles < 10 #比較的距離が短いケースのみ対象にする
AND tips IS NOT NULL
AND pickup_longitude IS NOT NULL
AND pickup_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
学習結果を確認する
学習が完了するとBigQueryのコンソール上にモデルが作成されているので、選択すると学習結果の詳細を確認することができます。各指標の見かたはこちらを参考にしてください。

こちらはROC曲線の性能の目安になります。今回の曲線は限りなくPoor寄りで、まだまだヤマ勘と大差無いです。
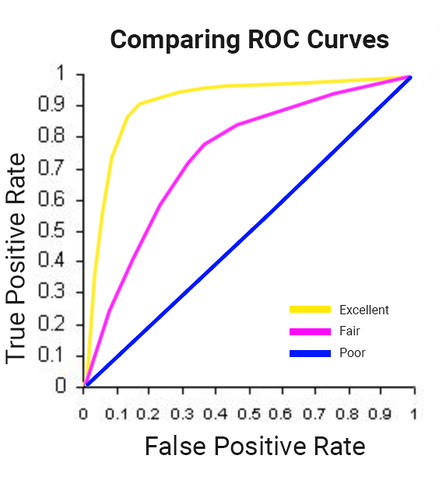
モデル評価
作成したモデルの性能を評価します。まずは基本的な構文から。
基本的な構文
SELECT
*
FROM
ml.EVALUATE(MODEL `モデル名`, (
# SELECT文で評価データを指定
SELECT
〜
FROM
〜
WHERE
〜
)
このように、ml.EVALUATE(model, table)の部分でモデルと評価データをそれぞれ選択します。評価データはSELECT文によって抽出されるデータをそのまま入力データとして使用できます。
SELECT *を使用していますが、結果は1行で6項目しか無いので問題ないと思います。必要に応じて結果を加工してください。
<出力項目>
- precision:適合率
- recall:再現率
- accuracy:精度
- f1_score:F1スコア
- nlog_loss:負の対数尤度
- roc_auc:ROC曲線の下部分の面積
実際に作成する
データ抽出のSELECT部分はモデル作成時とほとんど同じになります、一般的に学習データと評価データは別のものを使用するため、WHEREなどで条件を変えることになると思います。今回は2023年のデータを評価データとして使用しています。
SELECT
*
FROM
ml.EVALUATE(MODEL `test_detaset.tip_prediction_model`,
( #standardSQL
SELECT
IF
(tips > 0, '1', '0') AS is_tipped,
CAST(CAST(EXTRACT(HOUR
FROM
trip_start_timestamp) / 6 AS INT) AS STRING) AS time_type,
CAST(CAST(trip_miles/2 AS INT) AS STRING) AS mile_type,
CAST(EXTRACT(DAYOFWEEK
FROM
trip_start_timestamp) AS STRING) AS weekday,
pickup_longitude,
pickup_latitude,
dropoff_longitude,
dropoff_latitude,
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_miles < 10 #比較的距離が短いケースのみ対象にする
AND tips IS NOT NULL
AND pickup_longitude IS NOT NULL
AND pickup_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
AND EXTRACT(YEAR
FROM
trip_start_timestamp) = 2023 ))
評価結果を確認する
クエリ結果は以下のようになります。モデル作成時から結果は良くなかったですが、評価でもヤマ勘とほとんど同じですね…

モデルで予測
作成したデータを未知の入力データに対して適用します
基本的な構文
SELECT
*
FROM
ml.PREDICT(MODEL `モデル名`, (
# 一般的なSELECT文によるデータ抽出処理で入力データ指定
SELECT
〜
FROM
〜
WHERE
〜
評価と書き方は同じです。ml.EVALUATEの箇所がml.PREDICTに置き換わっています。
実際に作成する
これまでに作成・評価したモデルで予測を実行します。
今回も全ての結果を出力するためにSELECT *としていますが、必要に応じて変更してください。(出力内容は後述)
SELECT
*
FROM
ml.PREDICT(MODEL `test_detaset.tip_prediction_model`,
( #standardSQL
SELECT
IF
(tips > 0, '1', '0') AS is_tipped,
CAST(CAST(EXTRACT(HOUR
FROM
trip_start_timestamp) / 6 AS INT) AS STRING) AS time_type,
CAST(CAST(trip_miles/2 AS INT) AS STRING) AS mile_type,
CAST(EXTRACT(DAYOFWEEK
FROM
trip_start_timestamp) AS STRING) AS weekday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
trip_miles < 10 # 比較的距離が短いケースのみ対象にする
AND tips IS NOT NULL
AND pickup_longitude IS NOT NULL
AND pickup_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
AND EXTRACT(YEAR
FROM
trip_start_timestamp) = 2023 ))
実行結果を確認する
実行結果は次のようになります。各データの入力情報とそれに対する予測結果(今回は0 or 1)に加えて、それぞれの分類値の確率が出力されます。

モデルをVertex AIに保管する
作成したモデルをVertex AI Registryに保管すればAPIとしてサービングすることができ、BigQuery上でなくてもモデルを使用することができます。今回はVertex AI Registryへの登録方法のみ紹介します。モデル作成時にオプションと追加することで自動的に登録されます。
CREATE OR REPLACE MODEL 'モデル名'
OPTIONS(model_type='モデルの種類'
labels = ['is_tipped']
model_registry='vertex_ai',
vertex_ai_model_id='モデルのID'
) AS
# 一般的なSELECT文によるデータ抽出処理で学習データ指定
SELECT
〜
FROM
〜
WHERE
〜
余談ですが、今回のケースではお客さんに行き先を聞いた時点で全ての入力項目が揃うので、行き先を聞いた後にモデルを実行してチップをもらえなさそうなら乗車拒否するような運用になります。ちょっと運用面でも問題が大きそうなので、そういった点も考える必要がありそうです。
※あくまでBigQuery MLの使用方法が本記事の主題なのでご了承ください
最後に
全然良い結果にはならなかったですが、BigQuery MLを利用してモデルを作成し、作成したモデルを予測に使用する方法を紹介しました。BigQuery上でモデルを作成できるため、データ基盤と非常に相性がいいです。気軽にモデルを作って試すことができると思います。
BigQueryに最新のデータを蓄積し、モデルを継続的にアップデートして運用するというような、MLOps的な運用も可能となるので、ぜひデータ活用方法の一つとしていただけると嬉しいです。
参考資料
Googleのドキュメントにもサンプルがあるので、本記事の後に読めば理解が深まると思います。