RAGの精度向上に有効な施策としてGraphRAGという手法があります。
インプットされた文章をノードとエッジと呼ばれる要素に分解し、ノード間の関係性をグラフデータとして表現する手法になります。
例えば文章中に出てくる人物をノードとし、人物間の関係性をエッジで表現する、といったイメージです。
ベクトル検索を使ったRAGの場合「ドキュメント内の離れた箇所に登場するけれども、関係性の強い情報」といったものを扱う際に課題がありました。
GraphRAGの活用により、そういった情報を関連のある情報として拾えるようになり、生成AIによる文脈理解の促進、回答精度の向上につながるそうです。
詳細は下記ブログをご参照ください。
今回はそんなGraphRAGを使ったチャットアプリを作ってみました。
RAG実装にあたっては、グラフデータとベクトルデータのハイブリッド検索を利用しました。
チャットアプリにおける処理の流れは以下のようなイメージです。
- RAGで使いたいPDFファイルをチャット上にアップロード
- アップロードされたPDFファイルを解析し、チャンク分割、グラフ化、テキスト索引とベクトル索引の作成を実施
- 質問を投稿するとグラフのテキスト索引、ベクトル索引の両方を使ったハイブリッド検索を行い、検索結果を生成AIへコンテキストとして連携
- 生成AIからの回答をチャット上に表示
LangChainと生成AIにより作成されたグラフデータのイメージが以下になります。
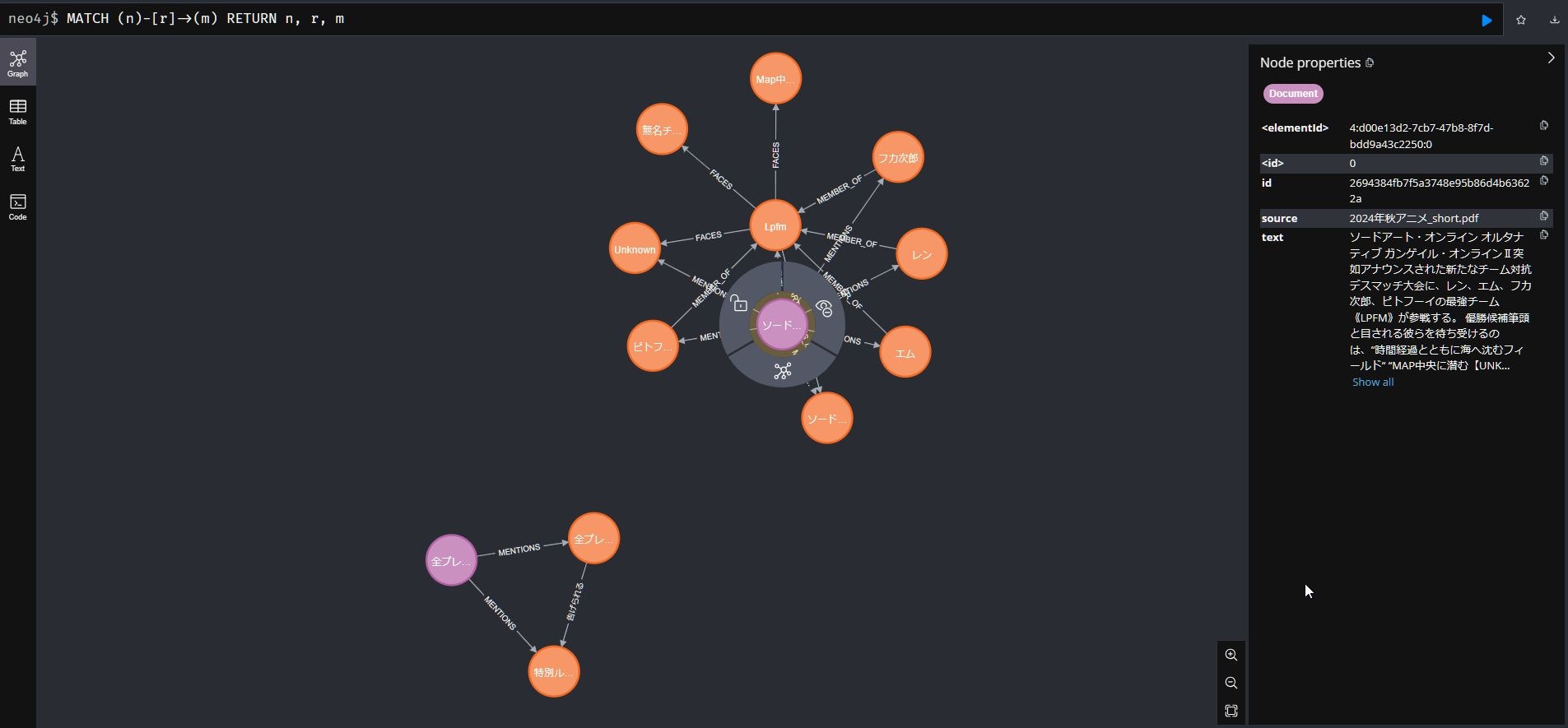
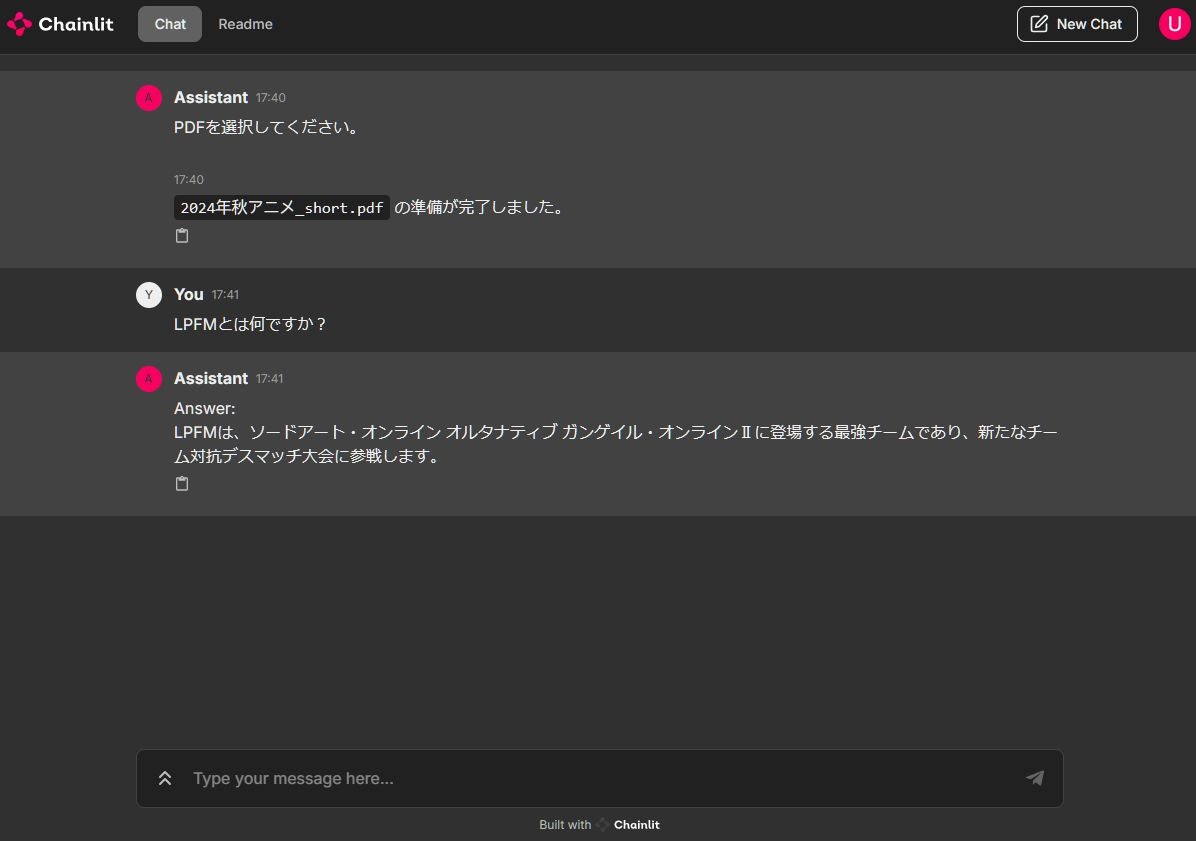
チャットアプリのイメージが以下になります。
目次
構成情報
チャットアプリ作成にあたり下記OSSを利用しました。
- グラフデータベース: Neo4j
- オーケストレーションツール: LangChain
- チャットUI: Chainlit
OSSの3点はOCI上の下記Computeインスタンスに導入しました。
- Shape: VM.Standard3.Flex (3 OCPU、48 GB RAM)
- OS: Oracle Linux 8.9
また生成AIは GPT-4o を、EmbeddingはOCI Generative AI Serviceが提供する cohere.embed-multilingual-v3.0 を利用しました。
Neo4jインストール
今回はローカルにNeo4jをインストールしてグラフデータ格納に利用しました。
まずNeo4jの要件となっているJavaをインストールします。
$ yum install java-17-openjdk
Neo4jインストールに必要なRPMレポジトリ情報を設定します。
$ rpm --import https://debian.neo4j.com/neotechnology.gpg.key
$ vi /etc/yum.repos.d/neo4j.repo
# 下記内容を記入します。
# [neo4j]
# name=Neo4j RPM Repository
# baseurl=https://yum.neo4j.com/stable/5
# enabled=1
# gpgcheck=1
Neo4jをインストールします。
$ yum install neo4j-5.23.0
LangChainとの連携に必要なAPOCプラグインを追加します。
cp -p /var/lib/neo4j/labs/apoc-5.23.0-core.jar /var/lib/neo4j/plugins
Neo4jのコンフィグに対してリモートアクセス許可、APOC利用許可の設定をします。
vim /etc/neo4j/neo4j.conf
# dbms.connector.http.enabled=true
# dbms.connector.http.listen_address=XX.XX.XX.XX:7474 #サーバーのIPアドレス
# dbms.connector.bolt.listen_address=0.0.0.0:7687 #Boltプロトコルコネクタ
# dbms.security.procedures.unrestricted=apoc.*
# dbms.security.procedures.allowlist=apoc.*
Neo4jのサービス自動起動を設定し、サービスを起動しておきます。
systemctl enable neo4j
systemctl start neo4j
Neo4j向けにファイアウォールを設定します。
# TCP 7474への通信を許可
$ firewall-cmd --add-port=7474/tcp
# TCP 7687への通信を許可
$ firewall-cmd --add-port=7687/tcp
# 設定保存
$ firewall-cmd --runtime-to-permanent
# 設定リロード
$ firewall-cmd --reload
# 内容確認
$ firewall-cmd --list-all
OCIセキュリティ・リストのIngressルールに以下の許可設定を追加します。
- 7474/tcp
- 7687/tcp
ブラウザからアクセスし、Neo4jが利用できることを確認します。
Neo4j構築時にデフォルトで用意されるアカウントは neo4j/neo4j です。
http://<ComputeのパブリックIP>:7474
正常に起動、アクセス許可されていれば以下のような画面が表示されます。
Python環境のセットアップ
Python環境を準備します。
Python仮想環境を作るにあたり、今回はAnacondaを導入します。
# Anacondaインストール
$ mkdir -p ~/miniconda3
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
$ bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
# 不要ファイル削除
$ rm -rf ~/miniconda3/miniconda.sh
# Anaconda初期セットアップ
$ ~/miniconda3/bin/conda init bash
Python仮想環境を新規作成し、アクティベートします。
$ conda create -n grag python=3.12
$ conda activate grag
必要なPythonライブラリをインストールします。
pip install -U langchain langchain-community sentence-transformers langchain-experimental neo4j pypdf python-dotenv oci oci-cli langchain_openai chainlit
OCI Generative AI Serviceの cohere.embed-multilingual-v3.0 を使う場合、OCI CLIのセットアップが必要です。
セットアップ手順は下記をご参照ください。
チャットアプリの実装コード
コード全体像は以下になります。
主要な部分の解説は後述します。
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain_core.prompts import PromptTemplate
from langchain_community.embeddings import OCIGenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
from langchain.schema.runnable import Runnable
from langchain.schema.runnable.config import RunnableConfig
from langchain_community.vectorstores.utils import DistanceStrategy
from typing import Optional
import chainlit as cl
# OCI情報
compartment_id = os.environ['compartment_id']
# Neo4j接続情報
url = os.environ['url']
user = os.environ['username']
pwd = os.environ['password']
db_name = os.environ['db_name']
# chainlitアカウント情報
chainlit_user = os.environ['chainlit_user']
chainlit_pwd = os.environ['chainlit_pwd']
# embeddingモデル設定
embedding_model = OCIGenAIEmbeddings(
model_id="cohere.embed-multilingual-v3.0",
service_endpoint="https://inference.generativeai.us-chicago-1.oci.oraclecloud.com",
compartment_id=compartment_id,
)
# LLM設定
llm = ChatOpenAI(model_name="gpt-4o-mini")
# Chainlitの認証設定
@cl.password_auth_callback
def auth_callback(username: str, password: str):
if (username, password) == (chainlit_user, chainlit_pwd):
return cl.User(
identifier=chainlit_user, metadata={"role": "user", "provider": "credentials"}
)
else:
return None
@cl.on_chat_start
async def on_chat_start():
# ファイルアップロードの処理
files = None
while files is None:
# chainlitのファイルアップロード機能を利用
files = await cl.AskFileMessage(
# ファイルの最大サイズ
max_size_mb=20,
# ファイルをアップロードさせる画面のメッセージ
content="PDFを選択してください。",
# PDFファイルを指定する
accept=["application/pdf"],
# タイムアウトなし
raise_on_timeout=False,
).send()
loader = PyPDFLoader(files[0].path)
# テキスト抽出
pages = loader.load_and_split()
# テキスト分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=40)
docs = text_splitter.split_documents(pages)
# 分割結果を一時保存
lc_docs = []
for doc in docs:
lc_docs.append(Document(page_content=doc.page_content.replace("\n", ""), metadata={'source': files[0].name}))
# Neo4jへの接続情報を設定してgraphインスタンスを作成
graph = Neo4jGraph(
url=url,
username=user,
password=pwd,
database=db_name
)
# DB内のグラフを削除するクエリ
cypher = """
MATCH (n)
DETACH DELETE n;
"""
# 既存グラフを削除して前回の内容をリセット
graph.query(cypher)
# llmを使いドキュメントをグラフに変換するtransformerを作成
transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["entity"], # ノードのラベルに「entity」を設定
node_properties=["text"], # ノードのプロパティに「text」を設定
relationship_properties=True # リレーションシップのプロパティ生成を「True」に設定
)
# ドキュメントをグラフに変換
graph_documents = transformer.convert_to_graph_documents(lc_docs)
# 変換したグラフをデータベースに保存
graph.add_graph_documents(graph_documents, include_source=True)
# ベクトルデータを含む検索用インデックス作成
index = Neo4jVector.from_existing_graph(
embedding=embedding_model,
url=url,
username=user,
password=pwd,
database=db_name,
node_label="entity", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # ベクトルデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="entity_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定
)
await cl.Message(content=f"`{files[0].name}` の準備が完了しました。").send()
# Cypherクエリ用のプロンプトテンプレート
template = """
Task: グラフデータベースに問い合わせるCypher文を生成する。
指示:
schemaで提供されている関係タイプとプロパティのみを使用してください。
提供されていない他の関係タイプやプロパティは使用しないでください。
schema:
{schema}
注意: 回答に説明や謝罪は含めないでください。
Cypher ステートメントを作成すること以外を問うような質問には回答しないでください。
生成された Cypher ステートメント以外のテキストを含めないでください。
質問: {question}"""
# プロンプトの設定
question_prompt = PromptTemplate(
template=template, # プロンプトテンプレートをセット
input_variables=["schema", "question"] # プロンプトに挿入する変数
)
# Cypherクエリを作成 → 実行 → 結果から回答を行うChainを作成
qa = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
cypher_prompt=question_prompt,
allow_dangerous_requests=True
)
# セッション登録
cl.user_session.set("runnable", qa)
@cl.on_message
async def on_message(message: cl.Message):
# セッション情報から設定を読み込み
runnable=cl.user_session.get("runnable")
# Chainlit設定
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached=True
# 回答生成
res=await runnable.ainvoke({"query": message.content}, callbacks=[cb])
# 回答表示
await cl.Message(content=f"\nAnswer:\n"+res['result']).send()
以降は主要箇所の解説になります。
# OCI情報
compartment_id = os.environ['compartment_id']
# Neo4j接続情報
url = os.environ['url']
user = os.environ['username']
pwd = os.environ['password']
db_name = os.environ['db_name']
# chainlitアカウント情報
chainlit_user = os.environ['chainlit_user']
chainlit_pwd = os.environ['chainlit_pwd']
こちらは dotenv を使って環境変数を読み込んでいます。
そのため事前に .env ファイルを作成し、以下情報を入力しておく必要があります。
- compartment_id: OCIのコンパートメントID
- url: Neo4jへの接続URL
- user: Neo4jのログインユーザ名
- pwd: Neo4jログインのパスワード
- db_name: Neo4jでGraphRAGに利用するデータベース名
- chainlit_user: Chainlitのログインユーザ名
- chainlit_pwd: Chainlitログインのパスワード
Chainlitのパスワード認証については以前投稿した下記記事をご参照ください。
またOpenAIのモデルを使う場合、OPENAI_API_KEY という変数名でAPIキーを .env ファイルに入力しておきます。
# llmを使いドキュメントをグラフに変換するtransformerを作成
transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["entity"], # ノードのラベルに「entity」を設定
node_properties=["text"], # ノードのプロパティに「text」を設定
relationship_properties=True # リレーションシップのプロパティ生成を「True」に設定
)
LLMを用いて入力されたテキストからグラフデータを自動生成する LLMGraphTransformer の設定を行っています。
# ドキュメントをグラフに変換
graph_documents = transformer.convert_to_graph_documents(lc_docs)
# 変換したグラフをデータベースに保存
graph.add_graph_documents(graph_documents, include_source=True)
前述した LLMGraphTransformer を使い、ドキュメントの内容をグラフ化しています。
また生成されたグラフデータをNeo4jに保存しています。
# ベクトルデータを含む検索用インデックス作成
index = Neo4jVector.from_existing_graph(
embedding=embedding_model,
url=url,
username=user,
password=pwd,
database=db_name,
node_label="entity", # 検索対象ノード
text_node_properties=["id", "text"], # 検索対象プロパティ
embedding_node_property="embedding", # ベクトルデータの保存先プロパティ
index_name="vector_index", # ベクトル検索用のインデックス名
keyword_index_name="entity_index", # 全文検索用のインデックス名
search_type="hybrid" # 検索タイプに「ハイブリッド」を設定(デフォルトは「ベクター」)
)
保存されたグラフデータのプロパティ「text」に格納されている文章をベクトル化し、そのベクトルデータをもとに検索用のインデックスを作成します。
また search_type を hybrid とすることでハイブリッド検索を有効化しています。
# Cypherクエリ用のプロンプトテンプレート
template = """
Task: グラフデータベースに問い合わせるCypher文を生成する。
指示:
schemaで提供されている関係タイプとプロパティのみを使用してください。
提供されていない他の関係タイプやプロパティは使用しないでください。
schema:
{schema}
注意: 回答に説明や謝罪は含めないでください。
Cypher ステートメントを作成すること以外を問うような質問には回答しないでください。
生成された Cypher ステートメント以外のテキストを含めないでください。
質問: {question}"""
生成AIがグラフデータを使って回答するようにテンプレートを用意しています。
主要な解説は以上となります。
使ってみる
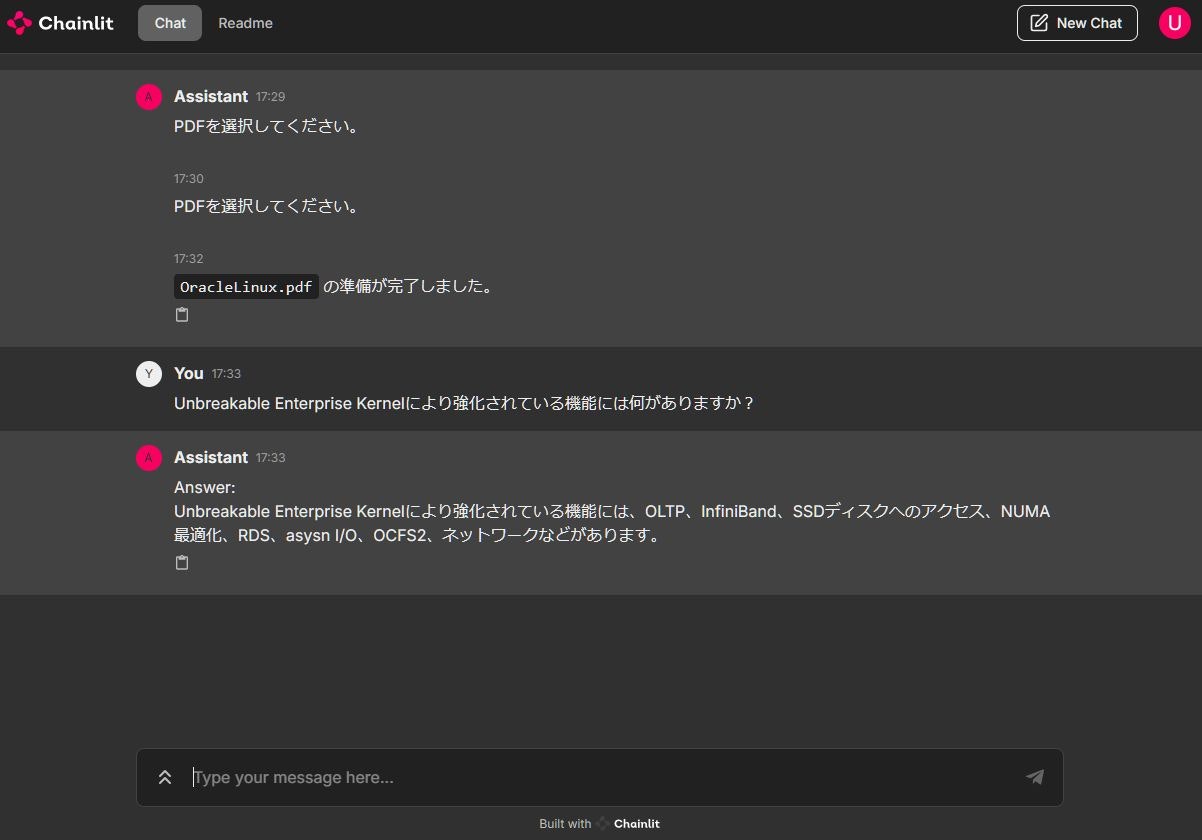
今回は試しにWikipediaから拾ってきたOracle Linuxの概要をインプットしてみました。
ファイルをアップロードし「Unbreakable Enterprise Kernelにより強化されている機能には何がありますか?」と質問してみたところ、以下のように回答が返ってきました。
また自動生成されたグラフデータをNeo4j上で確認してみます。
以下はグラフデータ全体を確認するためのCypher形式のクエリです。
MATCH (n)-[r]->(m)
RETURN n, r, m
すると下記画像が表示されました。
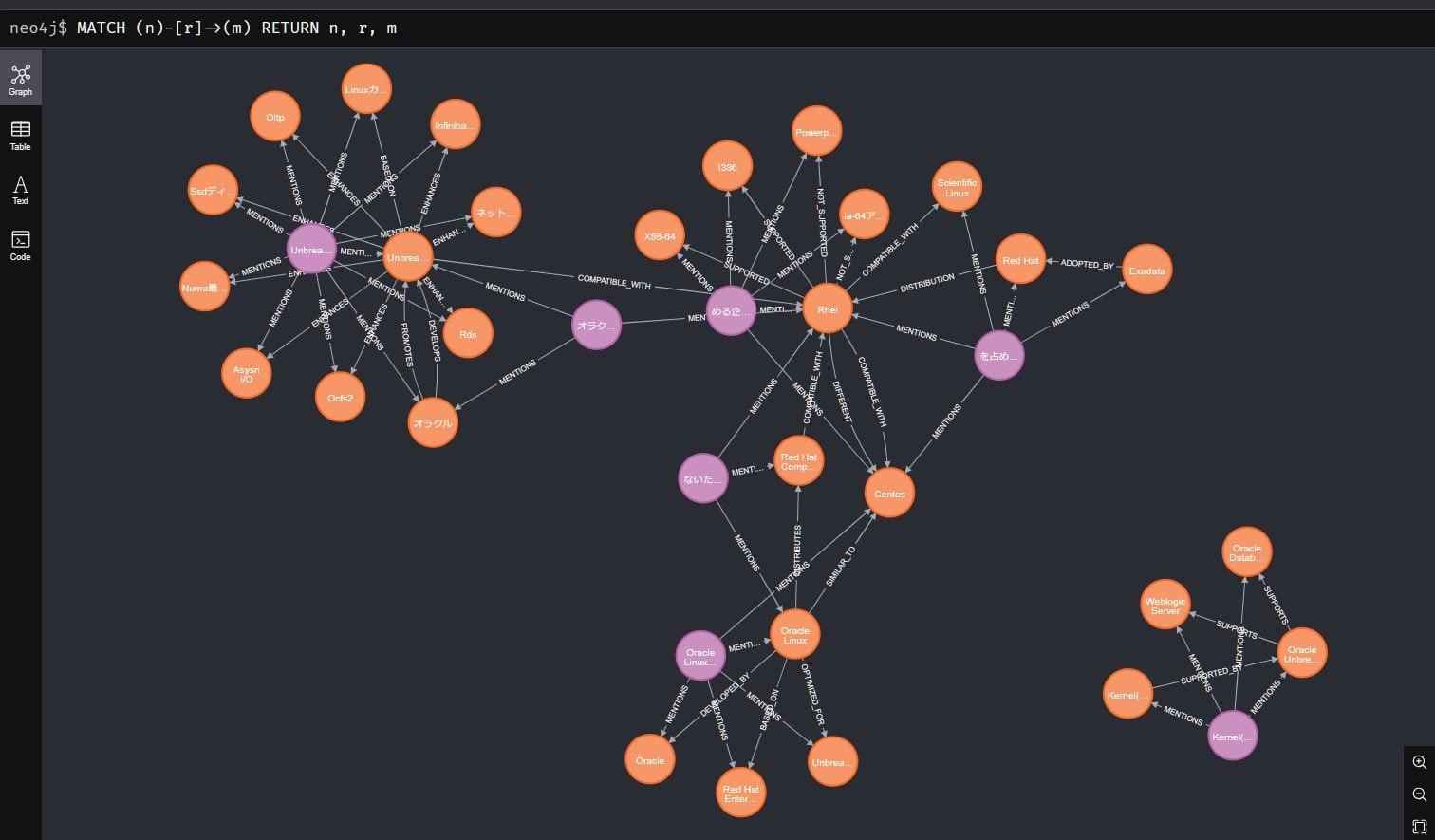
グラフの左上を見ると「Unbreakable Enterprise Kernel」というノードから「InfiniBand」や「OCFS2」といったノードへエッジが伸びており、エッジに「ENHANCES」と書かれています。
LLMが回答を生成する際にグラフで表現されている上記情報を読み取り、強化された機能を回答してくれたようです。
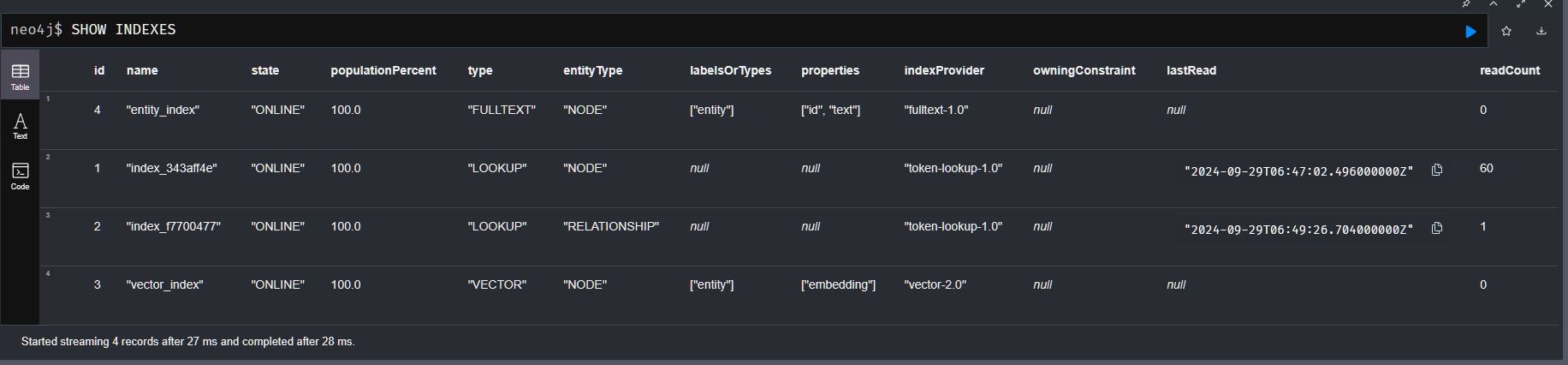
ついでにベクトルデータで作成された検索用の索引も確認してみます。
以下のコマンドをNeo4j管理画面で実行します。
SHOW INDEXES
すると下記画像のように表示され「vector_index」という名前の索引が作られているのを確認できます。
以上、GraphRAGを使ったチャットアプリ実装でした。
参考資料
本アプリ実装にあたり、下記サイトを参考にさせて頂きました。