※この記事は 2023/7/22 に作成しました。
※オプションで、「地域の設定」の「クエリステップ」は、「常に英語」に設定されています。日本語で使用している場合は、各自環境で作成されるコードに読み替えてください。
Index
- (1) Table.AddIndexColumn → Table.Pivot
- (2) Table.Split → Table.Transpose → Table.Combine
- (3) List.Split → Table.FromRows
- (4) Table.AlternateRows → Table.FromColumns
- (5) List.Alternate → Table.FromColumns
- (6) まとめ
課題: 1列に積み重なったデータの整形
様々な整形されていないデータを扱っていると、以下のような形式のデータを扱うことがあります。
鬼滅の刃 10
[著]吾峠呼世晴
2018/03/01
鬼滅の刃 11
[著]吾峠呼世晴
2018/06/01
鬼滅の刃 12
[著]吾峠呼世晴
2018/08/01
鬼滅の刃 13
[著]吾峠呼世晴
2018/11/01
上記の例では、書名、著者名、出版日の3つの項目が1列に積み重なっています。これを、以下の表形式にする方法を紹介し、どれが一番いいのか比較してみます。
| 書名 | 著者名 | 出版日 |
|---|---|---|
| 鬼滅の刃 10 | [著]吾峠呼世晴 | 2018/03/01 |
| 鬼滅の刃 11 | [著]吾峠呼世晴 | 2018/06/01 |
| 鬼滅の刃 12 | [著]吾峠呼世晴 | 2018/08/01 |
| 鬼滅の刃 13 | [著]吾峠呼世晴 | 2018/11/01 |
- 参考とした記事: @PowerBIxyz(Takeshi Kagata)さんの「Power Query workout - Table.AlternateRows / List.Alternate」
かなり深い話なので、この記事だけで何の話か理解できた人は、かなりの強者です。私も20回回ったくらいでやっと何の話か分かった気がします。
- 今回使用するデータ: メディア芸術データベース・ラボの「データセットダウンロード」からjson形式のデータを変換して使用させていただきました。
解法1: ピボットを使用する
Power Queryのピボット機能を使って行うことができます。この方法は、ブログやYoutubeで紹介されることが多く、とても人気のある方法です。
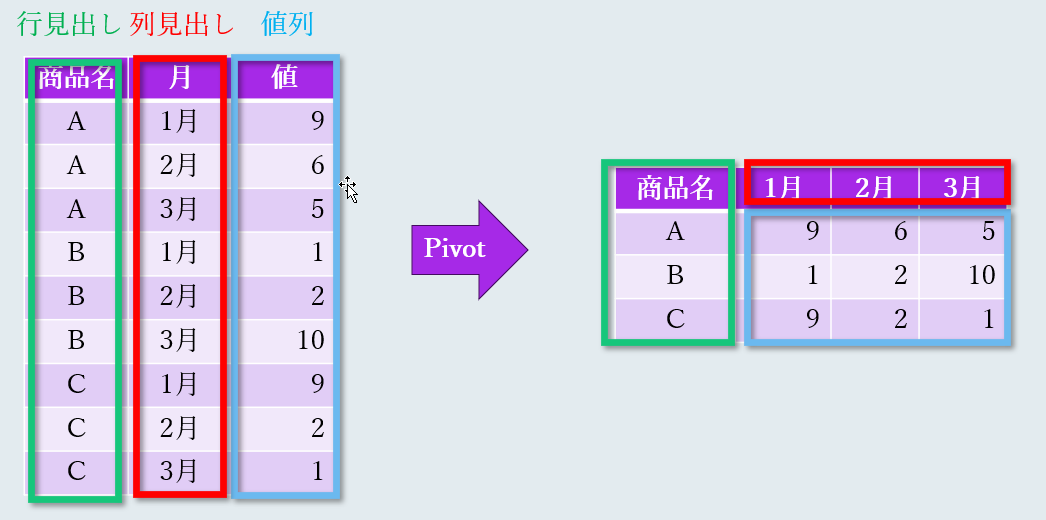
Table.AddIndexColumn
元のデータは、値値となります。ここに行見出しと列見出しを「列の追加」で作成していきます。
まず、「列の追加」タブで「全般」グループの「インデックス列(0から)」を選択します。
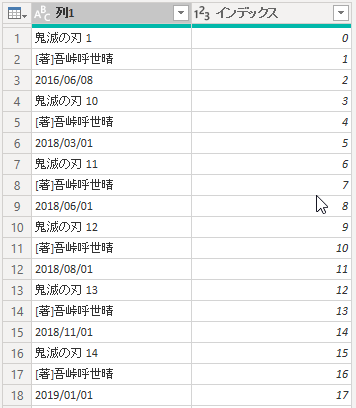
Table.AddColumn
次に、追加された「インデックス」列を選択して、「列の追加」タブで「数値から」グループの「標準」→「剰余」を選択し、値に項目数の3を入れると、0~2を繰り返す値が設定され、これが列見出しになります。
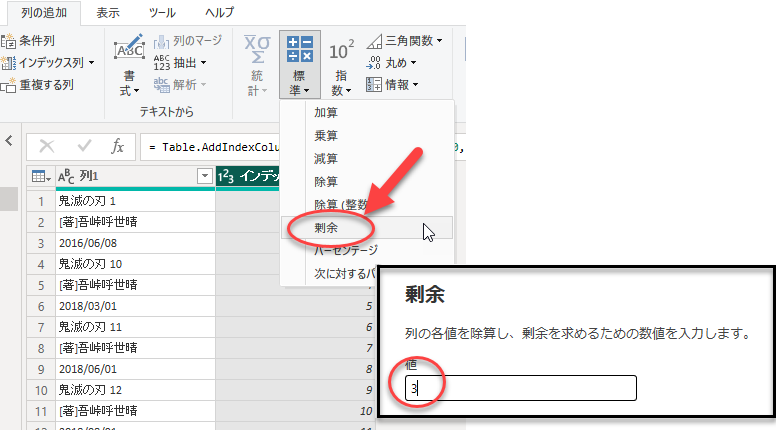
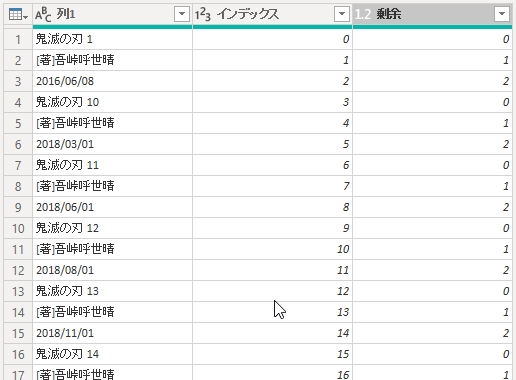
Table.TransformColumns
行見出しは、先に作成した「インデックス」列を変換します。
「変換」タブで「数値の列」グループの「整数」→「整数除算」を選択し、値に列数の3を入れます。
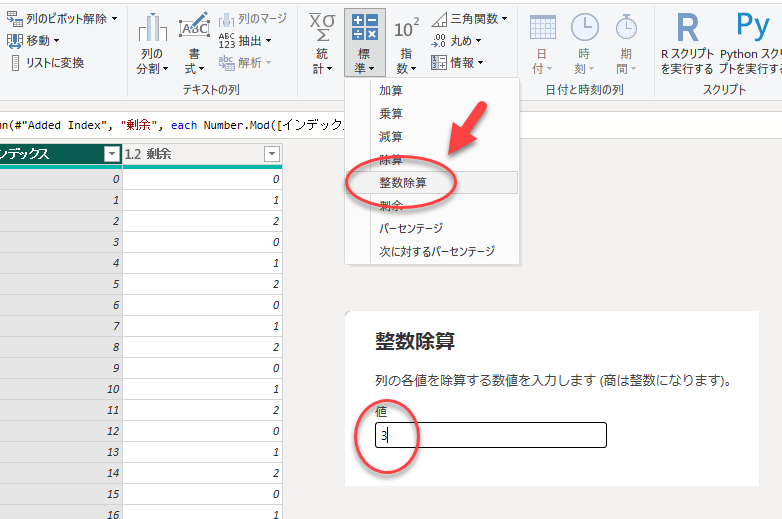
変換を実行すると、以下のようになります。
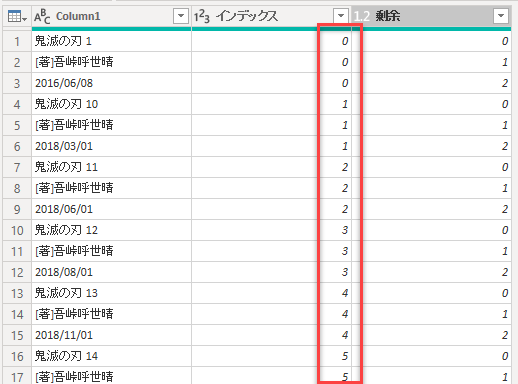
Table.Pivot
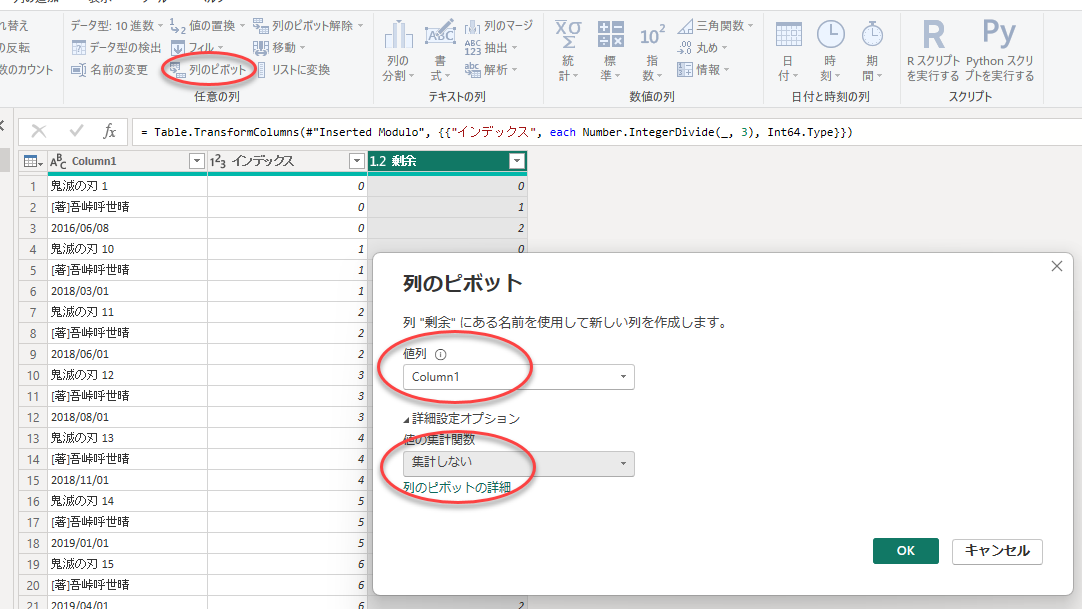
列見出しになる「剰余」列を選択し、「変換」タブで「任意の列」グループの「列のピボット」を選択します。「列のピボット」のダイアログが表示されますので、値列となる Column1 と、値の集計関数に「集計しない」を選択してOKを押します。
以下のようなテーブルが出来上がりますので、最後に「インデックス」列を削除すれば完成です。
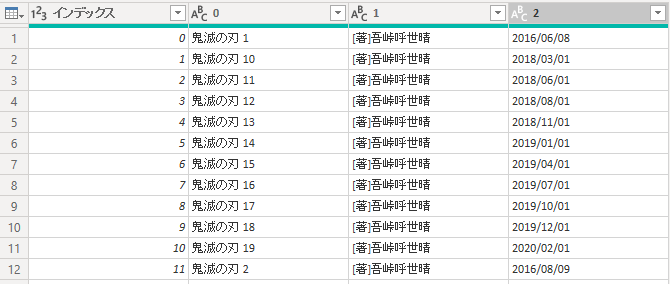
Table.Pivot関数解説
Table.Pivot関数の構文は以下の通りです。
Table.Pivot(
table as table,
pivotValues as list,
attributeColumn as text,
valueColumn as text,
optional aggregationFunction as nullable function
) as table
pivotValues には、列見出しとなる項目のリスト、 attributeColumn は列見出しとなる項目の列名を設定します。そして、 valueColumn は、値列の列名を設定します。また、 optional には、集計関数を設定します。
| 集計関数名 | 関数 |
|---|---|
| カウント(すべて) | List.Count |
| カウント(空白なし) | List.NonNullCount |
| 最小値 | List.Min |
| 最大値 | List.Max |
| 中央 | List.Median |
集計しない場合は、optional は設定されません。
今回の処理で作成されたコードは、以下のようになっていました。(適宜改行&インデントしています)
PivotedColumn = Table.Pivot(
Table.TransformColumnTypes(
IntegerDividedColumn,
{
{
"剰余",
type text
}
},
"ja-JP"
),
List.Distinct(
Table.TransformColumnTypes(IntegerDividedColumn,
{
{
"剰余",
type text
}
},
"ja-JP"
)[剰余]),
"剰余",
"Column1"
),
Table.Pivotの第一引数と第二引数の中で Table.TransformColumnTypes が行われています。これは、列見出しとなる項目が10進数型になっていたため、ピボットするためにテキスト型に変換する必要があるからです。事前にテキスト型に変換するステップ「Changedtype」を挿入しておけば、Table.Pivotの引数は以下のようにすっきりした形になります。
PivotedColumn = Table.Pivot(
ChangedType,
List.Distinct(
ChangedType[剰余]
),
"剰余",
"Column1"
)
Table.Pivotの第二引数は、 ChangedType[剰余] として値のリストを抽出した後に List.Distinct で重複を削除しています。
ソースコード
今回のコードの全体は、以下のようになっています。
let
// ファイルの読み込み
Source = Table.FromColumns(
{
Lines.FromBinary(
File.Contents( "** File Name **" ),
null,
null,
932 // シフトJIS
)
}
),
// インデックス列の追加(0から始まる)
AddedIndex =
Table.AddIndexColumn(
Source,
"インデックス",
0,
1,
Int64.Type
),
// 列見出しを作成
InsertedModulo =
Table.AddColumn(
AddedIndex,
"剰余",
each Number.Mod([インデックス], 3),
type number
),
// 行見出しを作成
IntegerDividedColumn =
Table.TransformColumns(
InsertedModulo,
{
{
"インデックス",
each Number.IntegerDivide(_, 3),
Int64.Type
}
}
),
// ピボット前に型変換を行う
ChangedType =
Table.TransformColumnTypes(
IntegerDividedColumn,
{
{"剰余", type text}
}
),
// 剰余列に対してピボットを行う
PivotedColumn =
Table.Pivot(
ChangedType,
List.Distinct(ChangedType[剰余]),
"剰余",
"Column1"
),
// インデックス列削除
RemovedColumns = Table.RemoveColumns(PivotedColumn, {"インデックス"}),
// 項目名変更
RenamedColumns =
Table.RenameColumns(
RemovedColumns,
{
{"0", "書名"},
{"1", "著者名"},
{"2", "出版日"}
}
)
in
RenamedColumns