19.1 結合関数(Combiner)
19.1.1 UIからの操作
結合関数は、Table.ToList や Table.CombineColumns などの関数によって利用され、テーブル内の各行を処理して単一の値を生成します。デリミター(区切り文字)を指定して結合することが一般的です。
UIを使って実行される一般的な操作は「変換」タブにある「列のマージ」です。複数の列を選択しているときに有効になります。
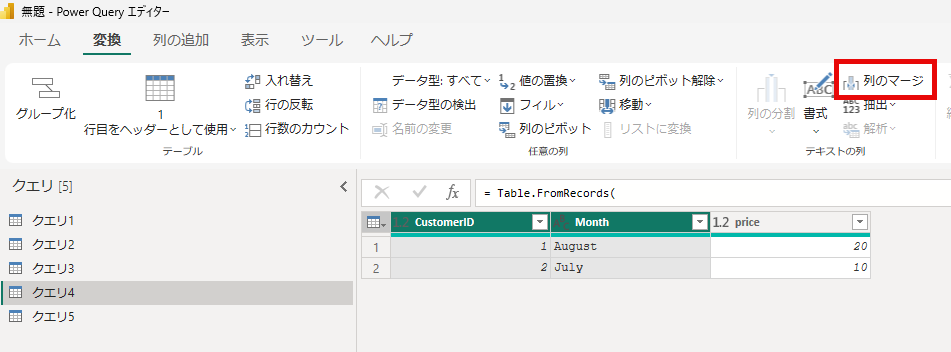
Table.CombineColumns と Combiner.CombineTextByDelimiter が使用されます。テキスト伊賀の型が検出された場合、Table.TransferColumnTRypes が組み込まれます。
let
Source = Table.FromRecords(
{
[CustomerID = 1, Month = "August", price = 20],
[CustomerID = 2, Month = "July", price = 10]
},
type table [CustomerID = number, Month = text, price = number]
),
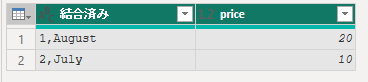
#"Merged Columns" =
Table.CombineColumns(
Table.TransformColumnTypes(
Source,
{{"CustomerID", type text}},
"ja-JP"
),
{"CustomerID", "Month"},
Combiner.CombineTextByDelimiter(
",",
QuoteStyle.None
),
"結合済み"
)
in
#"Merged Columns"
元の列を保持したい場合は、「列の追加」タブから「列のマージ」を選択してください。ただし、その場合は結合関数の代わりに Text.Combine 関数を使用して単一の値を生成するコードが生成されます。
let
Source = Table.FromRecords(
{
[CustomerID = 1, Month = "August", price = 20],
[CustomerID = 2, Month = "July", price = 10]
},
type table [CustomerID = number, Month = text, price = number]
),
#"Inserted Merged Column" =
Table.AddColumn(
Source,
"結合済み",
each Text.Combine(
{Text.From([CustomerID], "ja-JP"),
[Month]},
","
),
type text
)
in
#"Inserted Merged Column"

19.1.2 主な結合関数
1.Combiner.CombineTextByDelimiter
- 指定した区切り文字を使用して、リスト内の要素を連結します。
let
Source = {"Alice", "Bob", "Charlie"},
Combined = Combiner.CombineTextByDelimiter(", ")(Source)
in
Combined

2. Combiner.CombineTextByEachDelimiter
- リスト内の要素を複数の区切り文字で結合します。
let
inputList = {"", "030", "1234", "9999", "568", ""},
delimiterPattern = { "(", ")", "-", "[", "]" },
closure =
Combiner.CombineTextByEachDelimiter( delimiterPattern ),
Result = closure( inputList )
in
Result

3. Combiner.CombineTextByLengths
- 指定された長さを使用してテキスト値のリストを単一のテキストに結合する関数を返します。
- パラメータ
- Lengths (list):各テキストセクションの長さを指定します。
- Template (text):初期の文字列シーケンス。
Combiner.CombineTextByLengths(
{ 4, 4, 4, 4 },
"----^^^^////****"
)
( {"98", "DELTA", "19990110", "NO", "¯\_()_/¯"} )
-
Combiner.CombineTextByLengthに長さのリスト{ 4, 4, 4, 4 }と16文字のテンプレート"\\\\^^^^////****"が渡されます。 - 次に、5つの文字列のリスト
{"98", "DELTA", "19990110", "NO", "¯\_()_/¯"}に対して関数が適用されます。 - 長さのリストによって、文字列のリストから長さのリストの値に従って文字が切り出されます。
- テンプレートと重ね合わされ、長さが足りない部分はテンプレートの文字が表示されます。
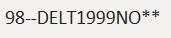
| 1 | 2 | 3 | 4 |
Text |98 |DELT|1999|NO |
Template|----|^^^^|////|****|
Result |98--|DELT|1999|NO**|
余分な文字は無視され、対応する長さが提供されていない追加のテキスト値も無視されます。
4. Combiner.CombineTextByPositions
- 指定された位置からテキストを連結する関数を返します
- パラメータ
- Positions (list):抽出する位置を指定します
- Template (text):初期の文字列シーケンス
Combiner.CombineTextByPositions(
{ 0, 4, 6, 10, 12, 12 },
Text.Repeat( "*", 14)
)
( {"98", "DELTA", "19990110", "NO", "¯\_()_/¯"} )

| 位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文字列リスト | 9 | 8 | D | E | 1 | 9 | 9 | 9 | N | O | ||||
| テンプレート | * | * | * | * | * | * | * | * | * | * | * | * | * | * |
| 結果 | 9 | 8 | * | * | D | E | 1 | 9 | 9 | 9 | N | O | * | * |
余分な文字は無視され、対応する長さが提供されていない追加のテキスト値も無視されます。
5. Combiner.CombineTextByRanges
- 指定された位置と長さを使用してテキストセグメントを連結する関数を返します。
- パラメータ
- Ranges (list):抽出する位置と文字数を指定します。
- Template (text):初期の文字列シーケンス。
Combiner.CombineTextByRanges(
{ {2, 2 }, {6, 4}, {10, 4}, {0, null} },
Text.Repeat( "*", 16)
)
( {"98", "DELTA", "19990110", "NO", "¯\_()_/¯"} )

| 位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文字列リスト | N | O | 9 | 8 | D | E | L | T | 1 | 9 | 9 | 9 | ||||
| テンプレート | * | * | * | * | * | * | * | * | * | * | * | * | * | * | * | * |
| 結果 | N | O | 9 | 8 | * | * | D | E | L | T | 1 | 9 | 9 | 9 | * | * |
19.2 分割関数(Splitter)
19.2.1 分割関数とは
分割関数は、Table.SplitColumn などの関数で、特定の区切り文字やパターンに基づいて文字列を分割し、リストに変換するための機能です。テキストデータの整形や列分割に使用されます。
UIでは、テキストを含む列を選択して、「ホーム」タブもしくは「変換」タブから「列の分割」を選択します。
以下のようなData列の項目で、区切り記号をカンマとスペースを設定して実行します。
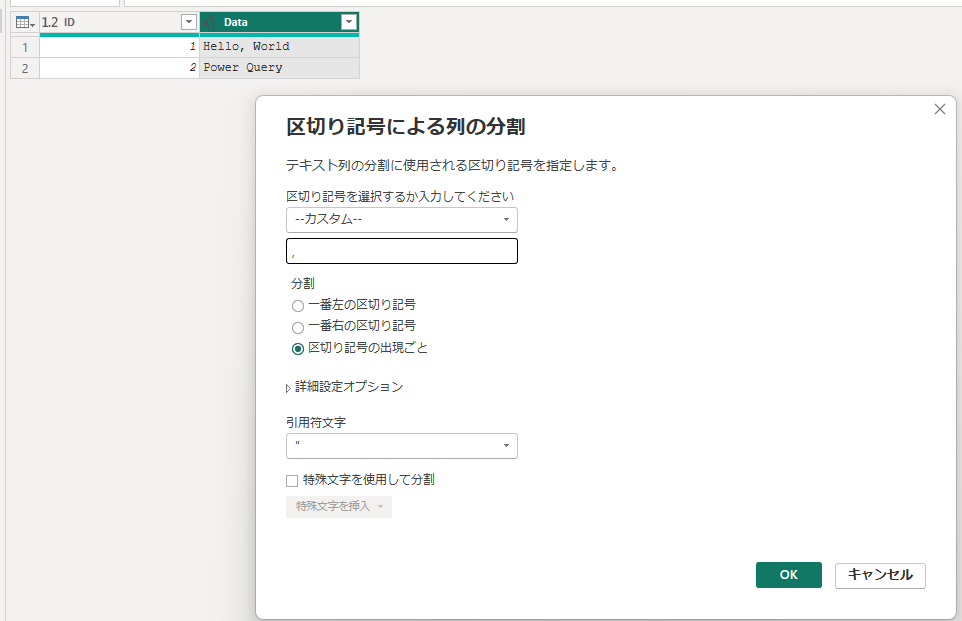
let
Source =
Table.FromRows(
{
{1,"Hello, World"},
{2,"Power Query"}
},
type table [ID = number, Data = text]
),
#"Split Column by Delimiter" =
Table.SplitColumn(
Source,
"Data",
Splitter.SplitTextByDelimiter(", ", QuoteStyle.Csv),
{"Data.1", "Data.2"}
)
in
#"Split Column by Delimiter"
結果は、以下の様に Data.1 と Data.2 の2つに分割されます。

分割関数を効果的に使用するには、最初に引数を指定して定義し、その後、分割するテキスト文字列を渡して返された関数(クロージャとも呼ばれます)を呼び出すのが最善です。
19.2.2 主な分割関数
1. Splitter.SplitTextByDelimiter
- 指定した区切り文字でテキストを分割します。
3. Splitter.SplitTextByAnyDelimiter
- 複数の区切り文字に基づいてテキストを分割します。
3. Splitter.SplitTextByEachDelimiter
4. Splitter.SplitTextByWhitespace
19.2.3 quoteStyle パラメータ
quoteStyle.None
文字列内の引用符が特別な意味を持たず、テキスト内の他の文字と同様に扱われることを示します。
Table.FromList(
{"Hello, World", "Power Query", """Microsoft, Online"""},
Splitter.SplitTextByDelimiter(", ", QuoteStyle.None)
)
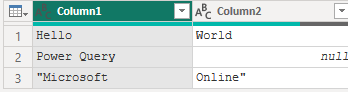
quoteStyle.Csv
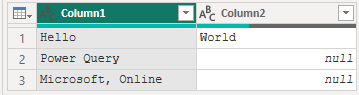
引用符が引用された文字列の開始と終了を示す特殊な文字として扱われることを意味します。文字列内のネストされた引用符は、連続する二つの引用符文字で表されます。オプションのquoteStyle引数を省略するかnullを渡すと、デフォルトでQuoteStyle.Csvが使用されます。
Table.FromList(
{"Hello, World", "Power Query", """Microsoft, Online"""},
Splitter.SplitTextByDelimiter(", ", QuoteStyle.Csv)
)
19.2.4 Splitter.SplitByNothing
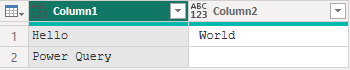
Splitter.SplitByNothing は、分割を行わず、入力された文字列をそのまま返します。この関数は、分割ロジックが不要な場合や、既に適切な形式になっているデータをそのまま扱いたい場合に利用されます。
例えば、
Table.FromList(
{"Hello, World", "Power Query"}
)
この結果は、以下の様になります。
分割を抑制したい場合は、Spliter.SplitByNothing をオプションに付けます。
Table.FromList(
{"Hello, World", "Power Query"},
Splitter.SplitByNothing()
)
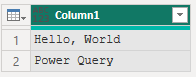
19.2.5 Splitter.SplitTextByAnyDelimiter
- 指定された
delimitersのいずれかを使用してテキストをテキスト値のリストに分割する関数を返します。 - パラメータ
- delimiters (list):区切り文字として使用する文字を指定します(必須)
- quoteStyle (number):引用符の扱い方を制御します(オプション)
- startAtEnd (logical):分割の方向を決定します(オプション)
let
string = "apple,""orange,banana;grape"",mango""",
splitFunction = Splitter.SplitTextByAnyDelimiter(
{",", ";"},
QuoteStyle.Csv,
true // 分割を後ろから行う
),
result = splitFunction(string)
in
result
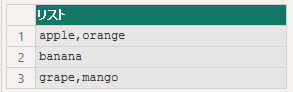
文字列 apple,"orange,banana;grape",mango" に対して、startAtEnd オプションが true なので、分割は後ろから行われます。
QuoteStyle.Csv なので、",mango" の , は区切り記号と見なされません。grape",mango" までが1つの項目になります。次に、banana です。apple,"orange は、" が1つしかありませんが、省略されていると判断し、うしろから評価すると "apple,"orange となり、ここでも , は区切り記号と見なされません。従って、以下の様になります。
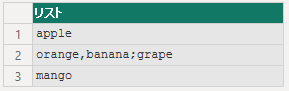
startAtEnd を false にすると、以下の様になります。
19.2.6 Splitter.SplitTextByCharacterTransition
Splitter.SplitTextByCharacterTransition 関数は、文字を別の種類の文字に切り替えるとき、文字列を文字列のリストに分割する関数が返されます。
Splitter.SplitTextByCharacterTransition(
before as anynonnull,
after as anynonnull
) as function
- before (list または function):文字を評価してtrueまたはfalseを返します
- after (list または function):文字を評価してtrueまたはfalseを返します
before パラメータ
let
string = "Abc1234aBc1234",
// 大文字の後ろで区切る
splitFunction =
Splitter.SplitTextByCharacterTransition(
{"A".."B"},
each true
),
result = splitFunction(string)
in
result
after パラメータ
英大文字の後ろで区切ります。

// 偶数の数字で文字列を区切る
let
string = "Abc1234Abc1234",
// 偶数の場合は true 奇数の場合と数値でないときは false
isEven = (char) =>
try
Number.IsEven(Number.From(char))
otherwise false,
// 偶数の数値の前で区切る
splitFunction =
Splitter.SplitTextByCharacterTransition(
each true,
isEven
),
result = splitFunction(string)
in
result
偶数の数値の前で区切ります。

19.2.7 Splitter.SplitTextByDelimiter
指定された区切り文字を使用してテキストをテキスト値のリストに分割する関数を返します。
Splitter.SplitTextByAnyDelimiter 関数より柔軟性は低いものの、より単純で直感的です。Text.Split 関数は、QuoteStyle.Csv が必要なければ、動作が最も単純で、基本的なテキスト分割に向いています。
パラメータ
- delimiter (text):区切り文字として使用する文字を指定します
- quoteStyle (number):引用符の扱い方を制御します
let
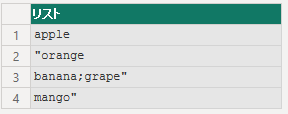
string = "apple,""orange,banana;grape"",mango""",
splitFunction = Splitter.SplitTextByDelimiter(
",",
QuoteStyle.None
)
in
splitFunction(string)
19.2.8 Splitter.SplitTextByEachDelimiter
指定された順序で区切り文字を使用してテキストを順番に分割し、テキスト値のリストに分割する関数を返します。
パラメータ
- delimiters (list):区切り文字として使用する文字を指定します
- quoteStyle (number):引用符の扱い方を制御します
- startAtEnd (logical):分割の方向を決定します
let
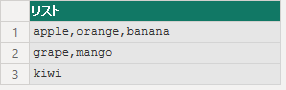
string = "apple,orange,banana;grape,mango,kiwi",
splitFunction =
Splitter.SplitTextByEachDelimiter(
{",", ";"},
QuoteStyle.None
),
result = splitFunction(string)
in
result
, ; の順番で区切ります。
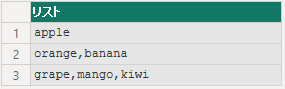
startAtEnd を true にすると、後方から区切っていきます。
19.2.9 Splitter.SplitTextByLengths
指定された長さでテキストを繰り返しテキスト値のリストに分割する関数を返します。データベースや固定幅の長さが事前に決まっているフラットファイルからの文字列を処理する際に特に有用です。これにより、各フィールドが一貫した文字数を占めることが保証され、解析プロセスが簡素化されます。
パラメータ
- lengths (number):テキストを分割するセグメントの長さを表す正の数
- startAtEnd (logical):分割の方向を決定します
let
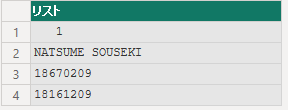
string = " 1NATSUME SOUSEKI 1867020918161209",
lengths = {4, 20, 8, 8},
splitFunction =
Splitter.SplitTextByLengths(
lengths
),
result = splitFunction(string)
in
result
固定長のデータを項目ごとに切り出します。
19.2.10 Splitter.SplitTextByPositions
この関数は、指定された位置でテキストを分割し、テキスト値のリストに分割する関数を返します。
パラメータ
- positions (list):分割する位置を指定します
- startAtEnd (logical):分割の方向を決定します
positionsリストは、分割のための累積文字数を表します。positionsリストの各項目は、前の項目と一致またはそれ以上である必要があり、負の値を取ることはできません。
let
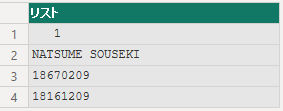
string = " 1NATSUME SOUSEKI 1867020918161209",
positions = {0, 4, 24, 32},
splitFunction =
Splitter.SplitTextByPositions(
positions
),
result = splitFunction(string)
in
result
19.2.11 Splitter.SplitTextByRanges
この関数は、指定された範囲に基づいてテキストを分割し、テキスト値のリストに分割する関数を返します。範囲は開始位置と長さによって定義されます。
パラメータ
- ranges (list):抽出する位置と文字数を指定します
- startAtEnd (logical):分割の方向を決定します
ranges リストは、開始位置と対応するテキストから抽出する文字数の2つの値を含むネストされたリストを含みます。または、null を指定して、文字列全体を含めることを示します。後続の抽出位置が前のものと重なる場合、後続の抽出が前のものを上書きします。範囲が指定されていない入力リストの余分な項目は無視されます。
let
string = " 1NATSUME SOUSEKI 1867020918161209",
ranges = {{0, 4}, {4, 20}, {24, 8}, {32, 8}},
splitFunction =
Splitter.SplitTextByRanges(
ranges
),
result = splitFunction(string)
in
result
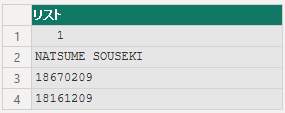
19.2.12 Splitter.SplitTextByRepeatedLengths
指定された長さでテキストを繰り返しテキスト値のリストに分割する関数を返します。
パラメータ
- lengths (number):各テキストセクションの長さを指定します
- startAtEnd (logical):分割の方向を決定します
let
string = "Apple OrangeBananaGrape Mango ",
splitFunction =
Splitter.SplitTextByRepeatedLengths(
12,
false
),
result = splitFunction(string)
in
result
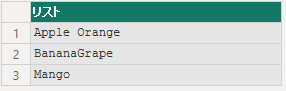
19.2.13 Splitter.SplitTextByWhitespace
各空白文字でテキストをテキストのリストに分割する関数を返します。Power Query M言語における空白文字には、スペースやキャリッジリターン、ラインフィード、タブなどの制御文字が含まれます。
パラメータ
- quoteStyle (number):引用符の扱い方を制御します
let
string = "A#(000D)B#(tab)C#(lf)D#(cr,lf)E#(cr)F#(lf)1#(000D)",
splitFunction = Splitter.SplitTextByWhitespace(),
result = splitFunction(string)
in
result

19.3 実践例
19.3.1 データクレンジングと統合
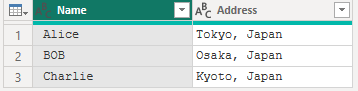
上記データを以下の様に整形する
let
// サンプルデータの作成
Source = Table.FromRecords(
{
[Name = " Alice ", Address = "Tokyo, Japan"],
[Name = " BOB ", Address = "Osaka, Japan"],
[Name = " Charlie ", Address = "Kyoto, Japan"]
}, type table [Name = text, Address = text]
),
CleanedNamesAndSplitAddress =
Table.TransformColumns(
Source,
{
// 名前のトリムと大文字小文字の統一
{
"Name",
each Text.Proper(Text.Trim(_)),
type text
},
// 住所の分割
{
"Address",
Splitter.SplitTextByDelimiter(", "),
type list
}
}
),
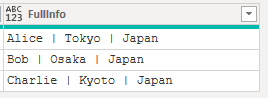
// 結合して新しいフィールドを作成
Combined =
Table.AddColumn(
CleanedNamesAndSplitAddress,
"FullInfo",
each
Combiner.CombineTextByDelimiter(" | ")({[Name]} & [Address])
)
in
Combined

19.3.2 制御文字と余分なスペースの削除
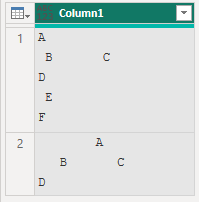
上記データから余分な改行やスペース、タブを消去
let
Source = Table.FromColumns(
{
{
"A#(000D) B#(tab) C#(lf)D#(cr,lf) E#(cr)F#(lf)1#(0000000D)",
" A #(000D) B#(tab) C#(lf)D "
}
}, type table [Column1 = text]
),
Cleaned =
Table.AddColumn(
Source,
"Cleaned",
each
Text.Trim(
Text.Combine(
Splitter.SplitTextByWhitespace()([Column1])
)
)
)
in
Cleaned
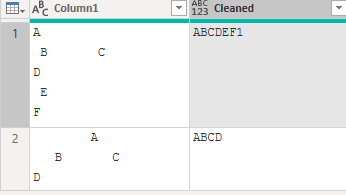
19.3.3 文字列からメールアドレスを抽出
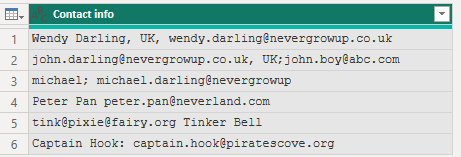
上記データからメールアドレスを抽出
let
Source = Table.FromRows(
{
{"Wendy Darling, UK, wendy.darling@nevergrowup.co.uk"},
{"john.darling@nevergrowup.co.uk, UK;john.boy@abc.com"},
{"michael; michael.darling@nevergrowup"},
{"Peter Pan peter.pan@neverland.com"},
{"tink@pixie@fairy.org Tinker Bell"},
{"Captain Hook: captain.hook@piratescove.org"}
}, type table [Contact info=text]
),
Splited =
Table.AddColumn(
Source,
"NewColumn",
// メールアドレスを抜き出して結合
each Text.Combine(
List.Select(
// メールアドレスに含まれない文字で区切る
Splitter.SplitTextByAnyDelimiter( {" ", ",", ":", ";"} )
( [Contact info] ),
each
// @xxx.xxx の形式になっていること
List.Count(
Splitter.SplitTextByEachDelimiter( {"@", "."} )( _ )
) = 3 and
// @は1つだけ
Text.Length( Text.Select(_, "@") ) = 1
),
", "
)
)
in
Splited

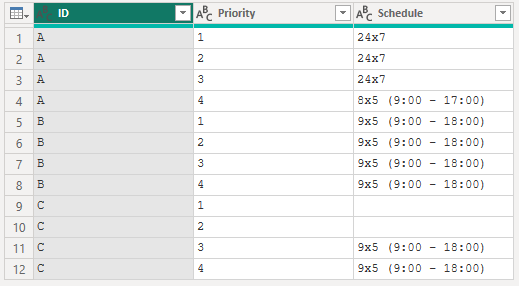
19.3.4 結合されたセルの値を分割
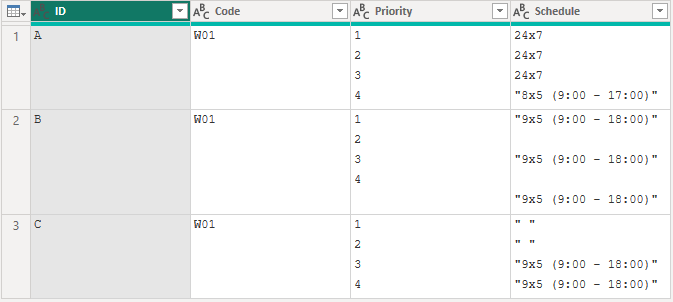
上記のデータを各レコードが単一の行をになるようデータを整える。
let
Data = [
p = Lines.ToText( {"1".."3"} ) & "4",
c = "W01",
s1 = Text.Combine( List.Repeat( {"24x7 #(cr,lf)"}, 3) &
{"""8x5 (9:00 - 17:00)"""} ),
s2 = Text.Combine( List.Repeat( {"""9x5 (9:00 - 18:00)"""} &
{"#(lf,cr)"}, 3) & {"""9x5 (9:00 - 18:00)"""} ),
s3 = Text.Combine( List.Repeat( {""" """} & {"#(lf)"}, 2) &
{"""9x5 (9:00 - 18:00)"""} & {"#(cr)"} & {"""9x5 (9:00 - 18:00)"""})
],
Source = Table.FromRecords(
{
[ID = "A", Code=Data[c], Priority = Data[p], Schedule = Data[s1]],
[ID = "B", Code=Data[c], Priority = Data[p], Schedule = Data[s2]],
[ID = "C", Code=Data[c], Priority = Data[p], Schedule = Data[s3]]
},
type table [ID = text, Code = text, Priority = text, Schedule = text]
),
// 新しい列にPriorityとSchuleのテーブルを作成
AddColumn =
Table.AddColumn(
Source,
"NewColumn",
each
Table.FromColumns(
{
Splitter.SplitTextByWhitespace()([Priority]),
Splitter.SplitTextByWhitespace()([Schedule])
},
{"Priority", "Schedule"}
),
type table [Priority = text, Schedule = text]
),
// IDとNewColumn以外は削除
SelectedColumn = Table.SelectColumns(
AddColumn,
{"ID", "NewColumn"}
),
// 展開
Expanded = Table.ExpandTableColumn(
SelectedColumn,
"NewColumn",
{"Priority", "Schedule"}
)
in
Expanded
19.3.5 大量の置換処理
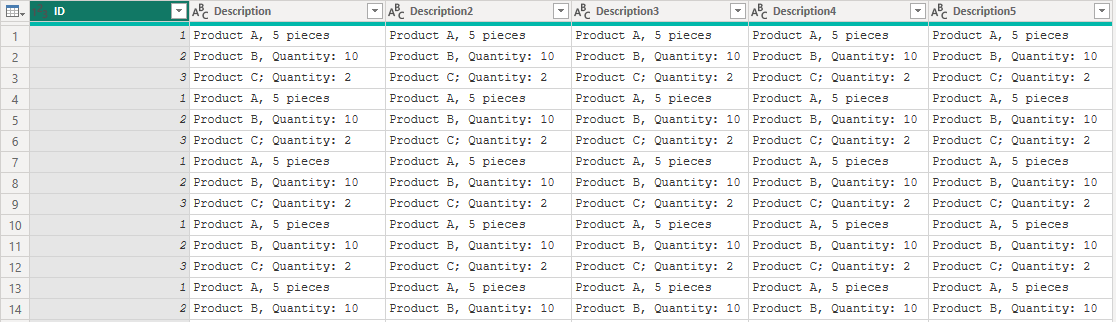
大量の値の置換が必要なデータセットがあり、個々のReplaceValueステップを使用しているため、クエリが遅く扱いにくくなっています。大量の置換を効率的に管理する方法は?
- 誤字脱字を変換リストを作成して修正する。
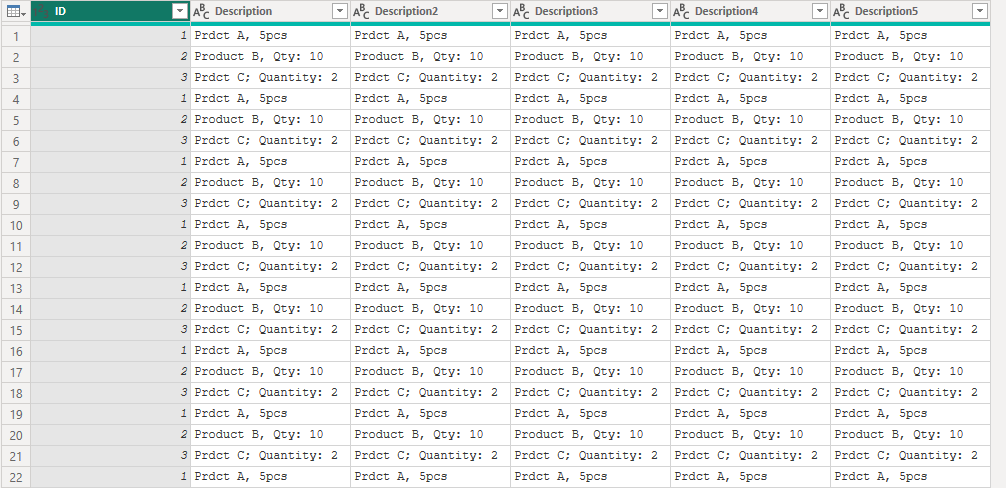
let
// テーブル作成
rawData = Table.FromColumns(
{
{1..3},
{"Prdct A, 5pcs", "Product B, Qty: 10", "Prdct C; Quantity: 2"},
{"Prdct A, 5pcs", "Product B, Qty: 10", "Prdct C; Quantity: 2"},
{"Prdct A, 5pcs", "Product B, Qty: 10", "Prdct C; Quantity: 2"},
{"Prdct A, 5pcs", "Product B, Qty: 10", "Prdct C; Quantity: 2"},
{"Prdct A, 5pcs", "Product B, Qty: 10", "Prdct C; Quantity: 2"}
}, type table
[
ID=Int64.Type, Description=text, Description2=text,
Description3=text, Description4=text, Description5=text
]
),
reSized = Table.Repeat( rawData, 100 ),
// 置換対象
Old = List.Buffer({"Prdct", "pcs", "Qty" }),
// 置換後
New = List.Buffer({"Product", " pieces", "Quantity"}),
// 置換対象のオフセットのリスト作成 (0, 1, 2}
Iterations = List.Buffer({0..List.Count(Old)-1}),
// "Prodct", "pcs", "Qty" の順で置換を行う
Replacer =
List.Accumulate(
Iterations, // {0, 1, 2}
reSized, // seed
(state, current) =>
Table.ReplaceValue(
state,
Old{current}, // oldValue
New{current}, // mewValue
Replacer.ReplaceText, // replacer
// 対象列は、列名がDescriptionで始まる
List.Select(
Table.ColumnNames(rawData),
each
Text.StartsWith(_, "Description")
)
)
)
in
Replacer
19.3.6 行を条件付きで結合する(宿題)
複数行のrecords(この場合はサンプルの銀行取引明細書(図 11.41))を単一の行に変換しましょう。
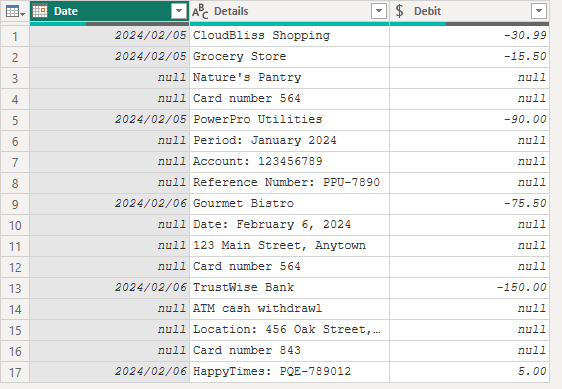
let
Source = Table.FromRows(
{
{#date(2024, 2, 5), "CloudBliss Shopping", -30.99},
{#date(2024, 2, 5), "Grocery Store",-15.5},
{null, "Nature's Pantry", null},
{null, "Card number 564", null},
{#date(2024, 2, 5), "PowerPro Utilities", -90.0},
{null, "Period: January 2024", null},
{null, "Account: 123456789", null},
{null, "Reference Number: PPU-7890", null},
{#date(2024, 2, 6), "Gourmet Bistro", -75.50},
{null, "Date: February 6, 2024", null},
{null, "123 Main Street, Anytown", null},
{null, "Card number 564", null},
{#date(2024, 2, 6), "TrustWise Bank", -150},
{null, "ATM cash withdrawl", null},
{null, "Location: 456 Oak Street, Anytown", null},
{null, "Card number 843", null},
{#date(2024, 2, 6), "HappyTimes: PQE-789012", 5}
}, type table [Date=date, Details=text, Debit=Currency.Type]
)
in
Source
ヒント
-
Table.Groupを使用します。 -
groupKindをGroupKind.Localにします。 - カスタム比較関数を作成します。