フィールド名(列名)をCSVファイルで指定して一括変更する
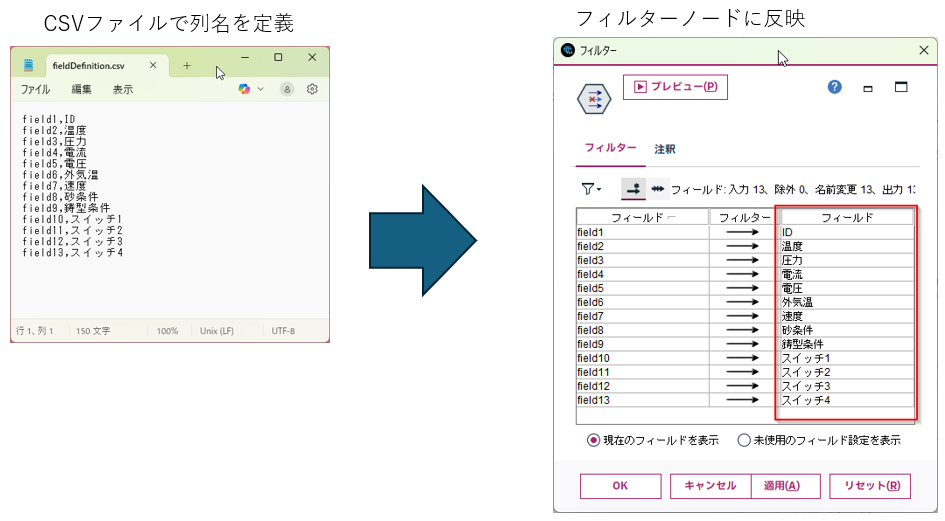
1.想定される利用目的
・列名のないデータの列名定義
・略語や英語の列名のわかりやすい日本語列名への変換
2.サンプルストリームのダウンロード
サンプルストリーム
サンプル列名定義CSV
3.サンプルストリームの説明
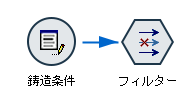
a.入力するデータは以下の通りです。fieldXXという列名で定義されていません。
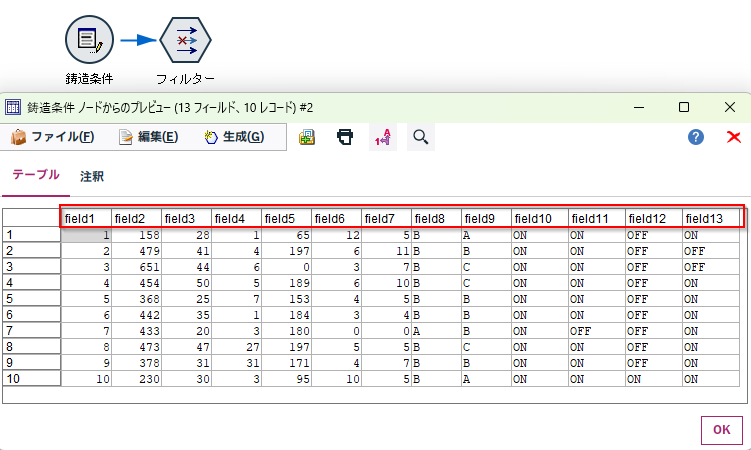
b.[フィルター]ノードをつなぎます。デフォルトでは列名はそのままです。この設定をスクリプトで変更していきます。

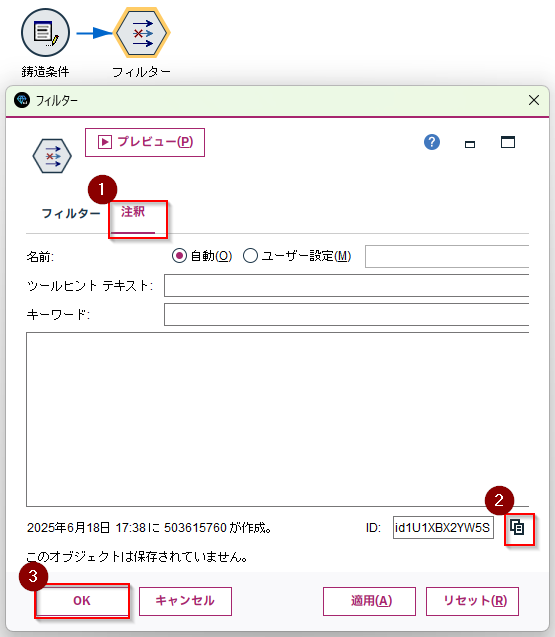
注釈タブにうつって、ノードのIDをクリップボードにコピーしてメモして、閉じておきます。
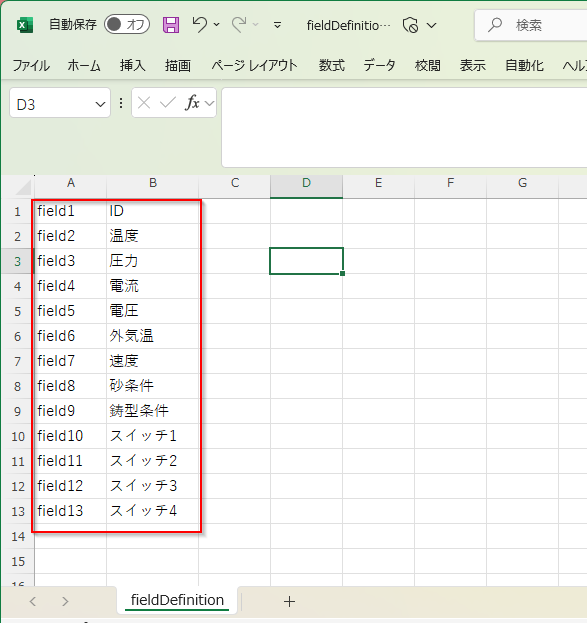
Excelなどで列名を定義を定義したCSVをUTF-8のエンコーディングで保存しておきます。
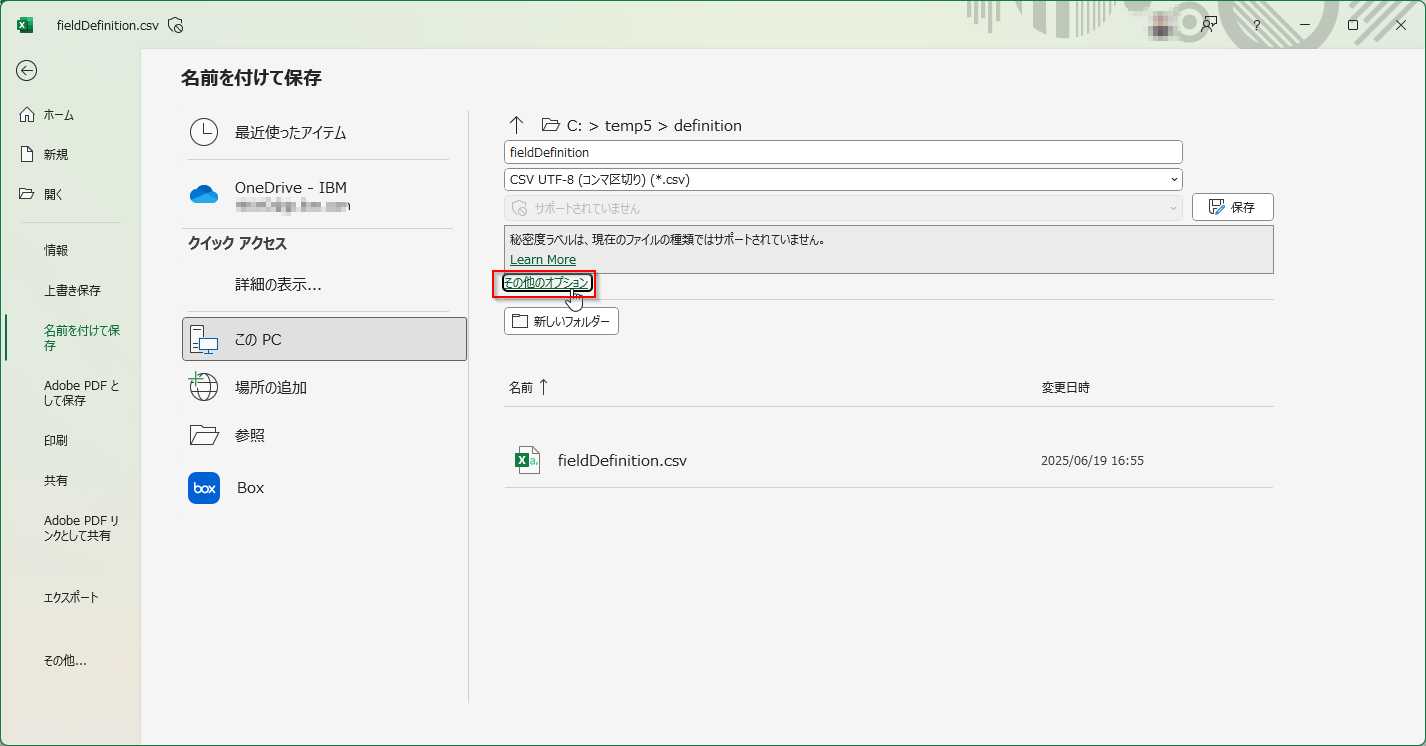
デフォルトではシフトJISで保存されてしまうので、保存の際に「その他のオプション」を選び、「CSV UTF-8(コンマ区切り)(*.csv)」で保存します。

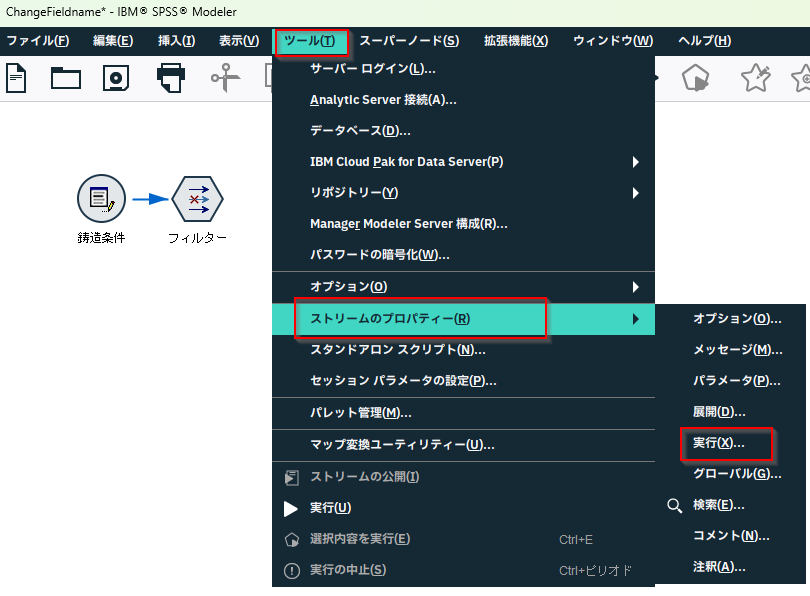
Modelerの「ツール」_「ストリームのプロパティー」_「実行」を開きます。
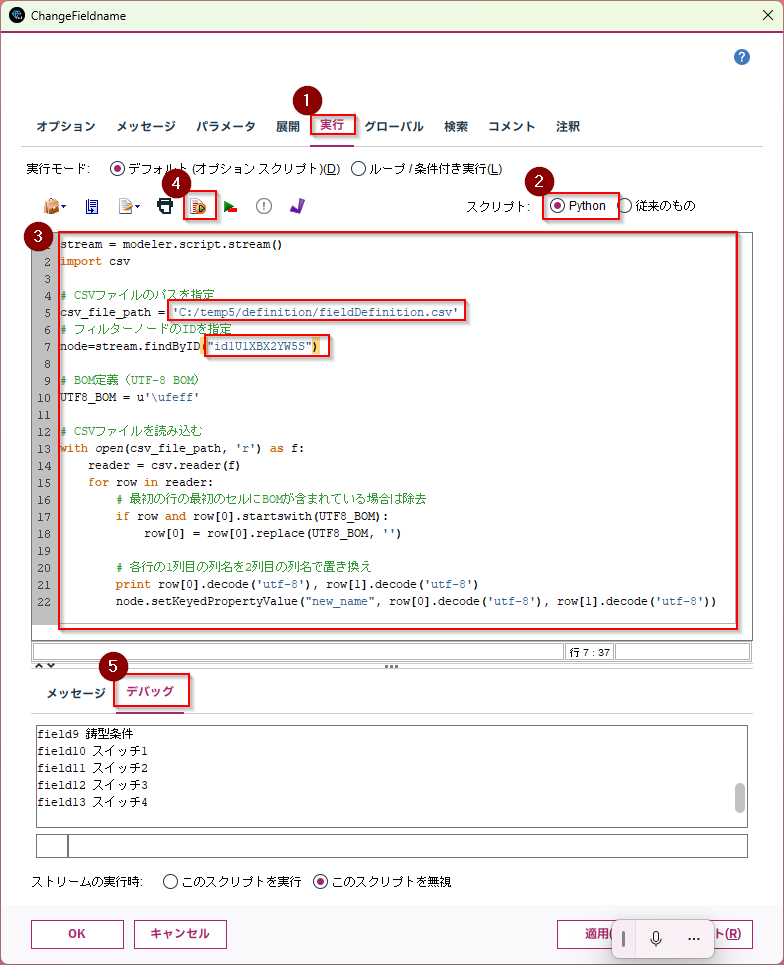
csv_file_pathに列定義をしたCSVファイルのパスを設定し、
node=stream.findByIDに先ほどコピーしたフィルターノードのIDを設定して、以下のスクリプトを入力して実行ボタンを押します。
stream = modeler.script.stream()
import csv
# CSVファイルのパスを指定
csv_file_path = '<列定義をしたCSVファイルのパス>'
# フィルターノードのIDを指定
node=stream.findByID("<フィルターノードのID>")
# BOM定義(UTF-8 BOM)
UTF8_BOM = u'\ufeff'
# CSVファイルを読み込む
with open(csv_file_path, 'r') as f:
reader = csv.reader(f)
for row in reader:
# 最初の行の最初のセルにBOMが含まれている場合は除去
if row and row[0].startswith(UTF8_BOM):
row[0] = row[0].replace(UTF8_BOM, '')
# 各行の1列目の列名を2列目の列名で置き換え
print row[0].decode('utf-8'), row[1].decode('utf-8')
node.setKeyedPropertyValue("new_name", row[0].decode('utf-8'), row[1].decode('utf-8'))
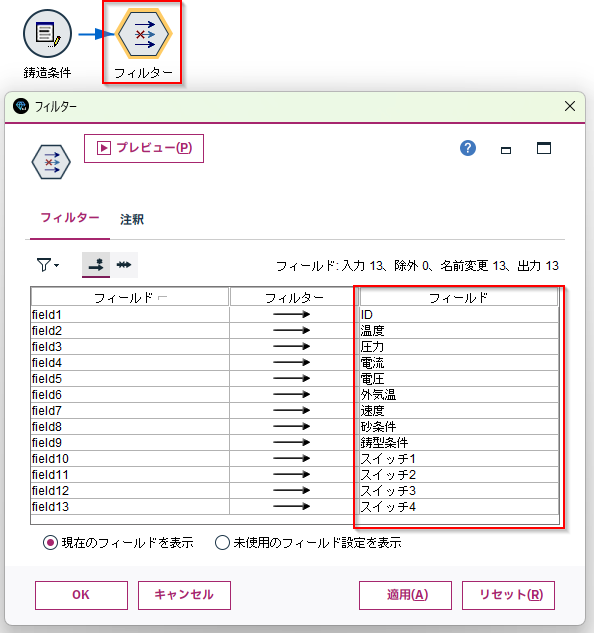
以下のようにフィルターノードに変換された列名が設定されています。
4.参考情報
列名を変更する/不要な列を削除する(SPSS Modeler データ加工逆引き7-7)
[フィルター]ノードで列名を一括変換
[フィルター]ノードを扱った記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)