はじめに
SPSS Modeler Premium 18.6では日本語テキスト分析が可能になっています。
テキスト分析についてはModelerFlowのチュートリアルと@TTS22 さんの日本語解説記事がありますので、この内容をオンプレ版のModelerで実行してみます。
3つの記事からなっています。
①インタラクティブ・ワークベンチ
②カテゴリーのフラグ化(←この記事)
③テキストリンク分析
■テスト環境
- Modeler Premium 18.6
- Windows 11 64bit
テストデータ
@TTS22 さんが翻訳してくれたホテルの満足度調査のデータを使います。
Comments列にテキストデータが入っています。820件あります。

テキストマイニング
「IBM SPSS Text Analytics」のパレットから「テキストマイニング」のノードを接続します。
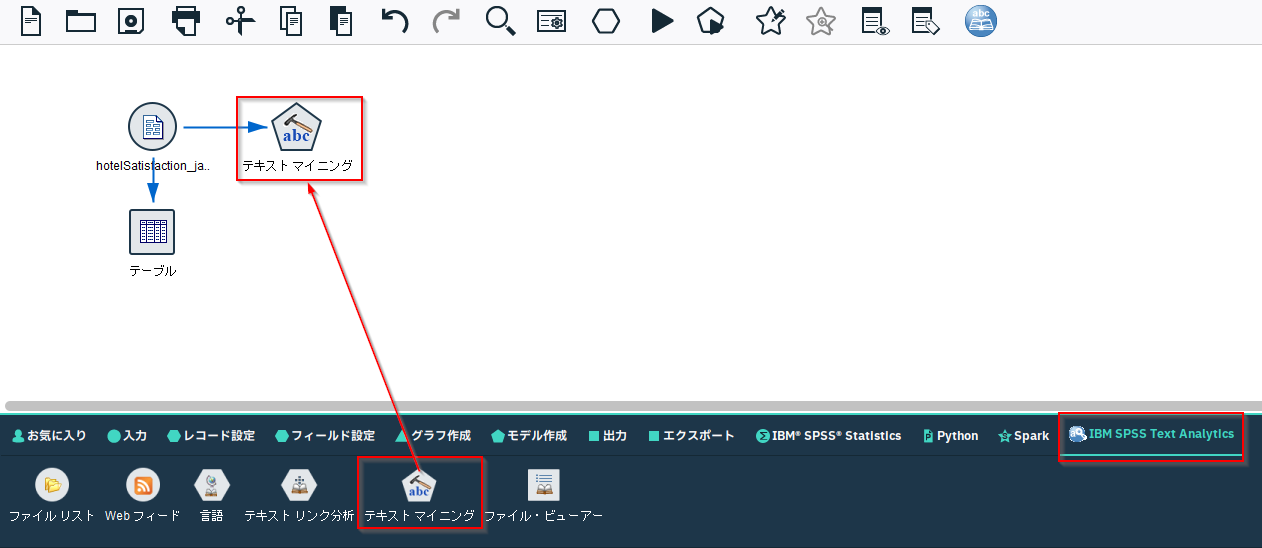
まず、フィールドのタブで以下を選択します。
IDフィールド:id
テキストフィールド:Comments

次に、モデルのタブで「テキスト分析パッケージ」を選び、「読み込み」をクリックし、「HotelSatisfaction (Japanese).tap」を選んで「ロード」します。
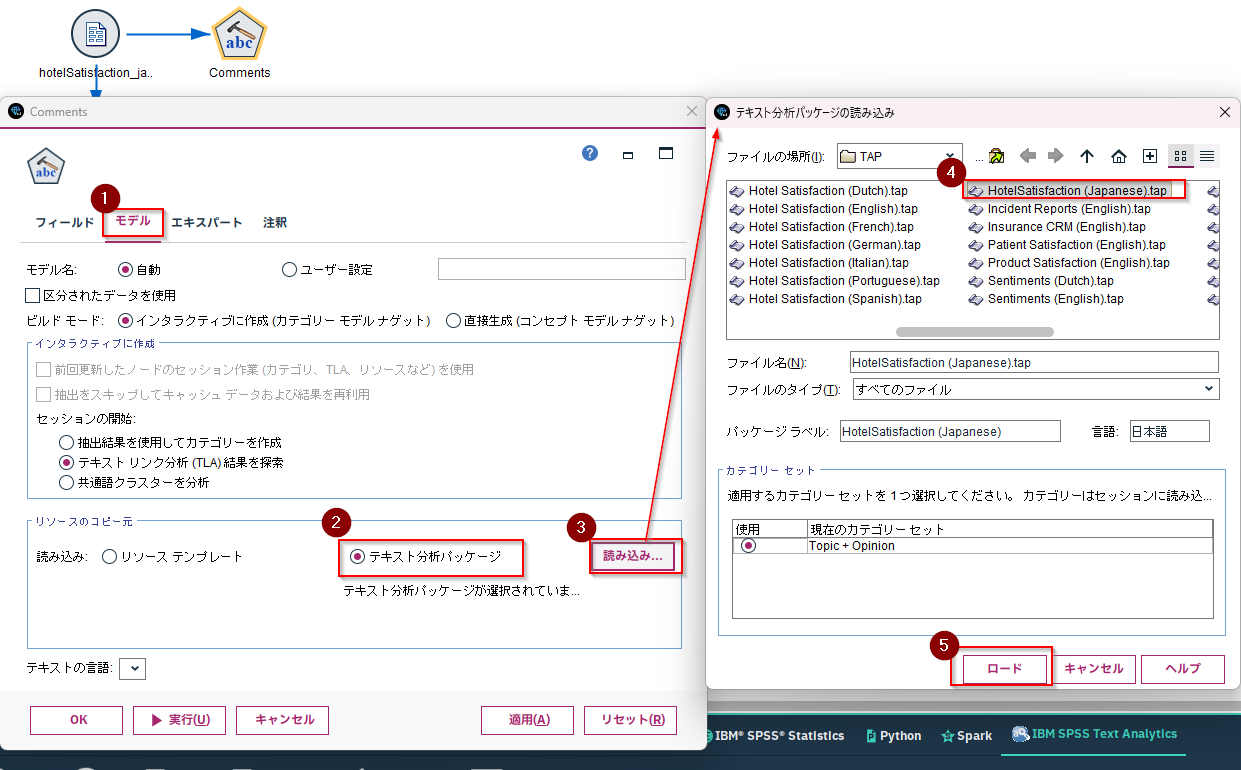
そして「実行します」
インタラクティブ・ワークベンチが開きます。
「カテゴリーとコンセプト」を選びます。
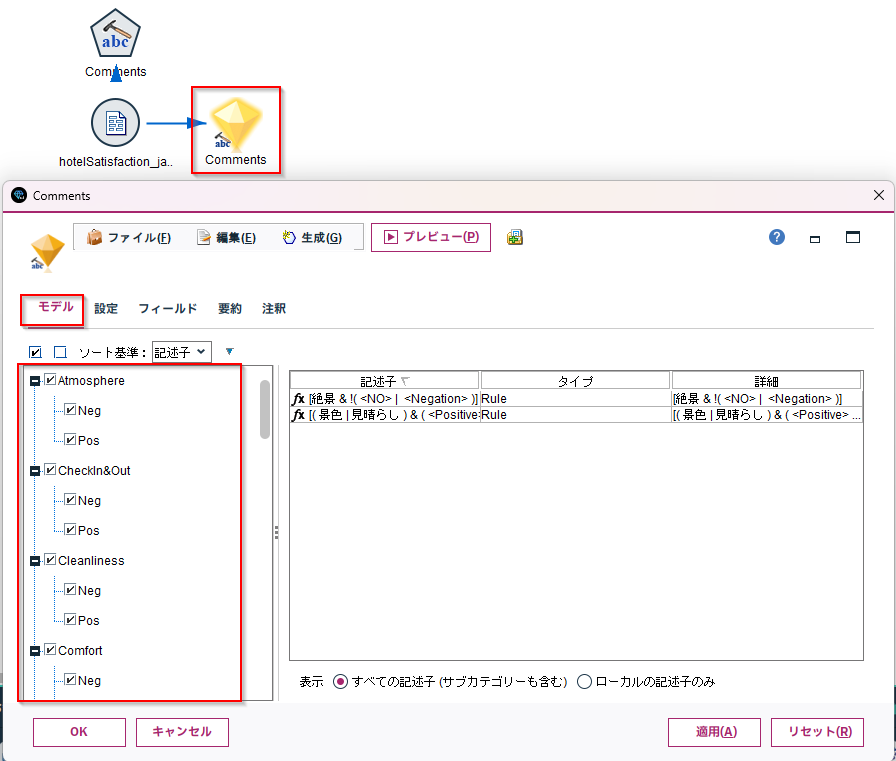
「HotelSatisfaction (Japanese)」のテキスト分析パッケージで定義された「カテゴリー」が表示されています。
「Atomosphere/Pos」などのカテゴリーが定義されています。このカテゴリーで「モデルを生成」します。

モデルのパレットに「Comments」というモデルができますので、これを「hotelSatisfaction_japanese.csv」ノードに接続します。

センチメント分析
このモデルではPositiveかNegativeかの分類ができているので、2つの方法でセンチメント分析をしてみます。
フィールドに展開して集計
まずはカテゴリーをフィールドに展開していきます。
モデルを開いてみると、AtomosphereやCheckin&Outなどのカテゴリーの下にNegとPosのサブカテゴリーがあり、PositiveかNegativeかを分類できることがわかります。これらをフラグ化していきます。
「設定」タブにうつり、「フィールドとしてのカテゴリー」にチェックがあることを確認します。これでフラグ化が行われます。「真の値」と「偽の値」は集計しやすいように「1」「0」にしておきます。

プレビューをしてみると各カテゴリーがフラグ化されたことがわかります。
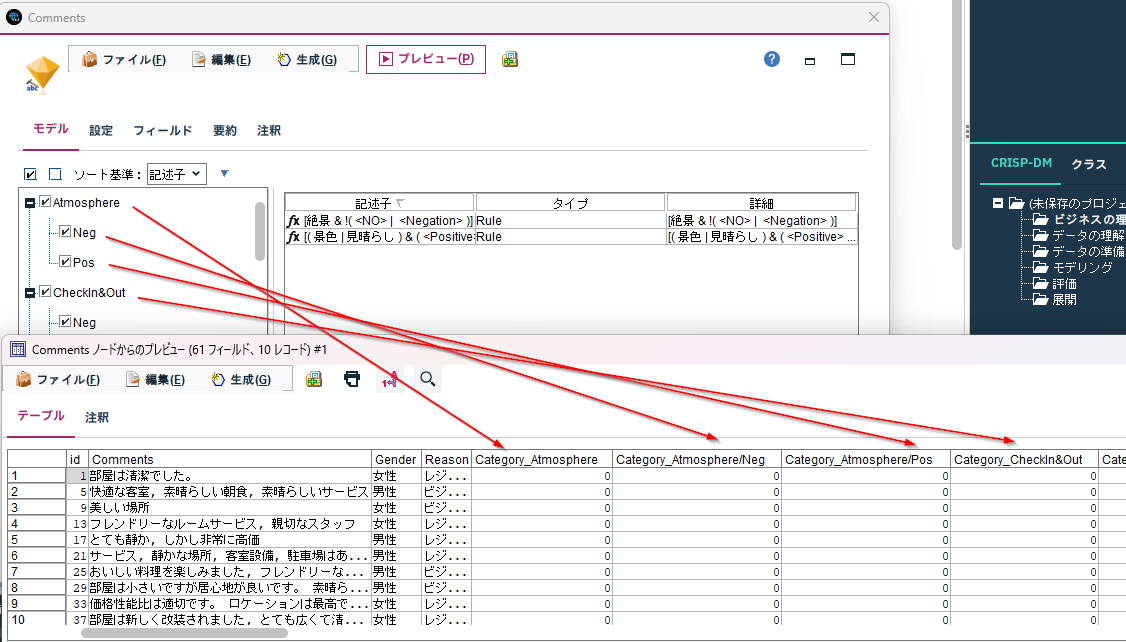
モデルの実行は内部的にパラレル実行されるようで順序が変わってしまうので、ソートノードで並べておくのがおすすめです。また、スコアリングの実行は重めの処理なのでキャッシュしておくのもおすすめです。
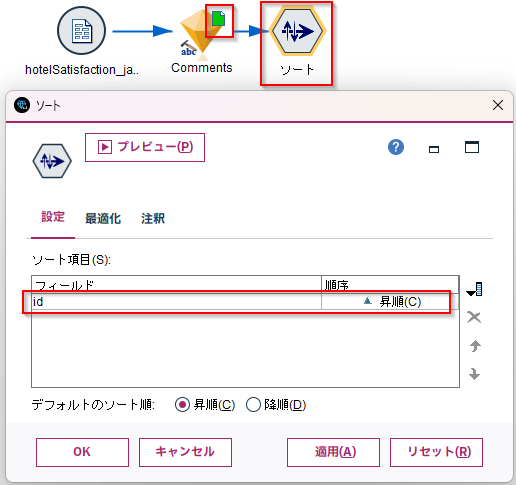
フィールド作成ノードで、以下のClem式を使って、PositiveとNegativeのカテゴリ数を計算します。

sum_n(@FIELDS_MATCHING("Category_*Neg"))
sum_n(@FIELDS_MATCHING("Category_*Pos"))
以下のように"Category_*Neg"などにマッチする列の値を足しこんでいっています。

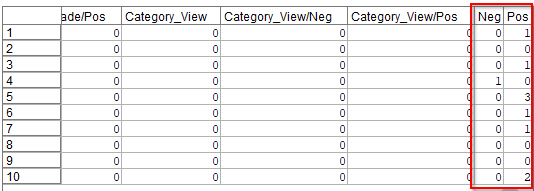
プレビューすると以下のように算出されています。
次にこのPosとNegの値から、以下の条件でセンチメントを一意に決定します。
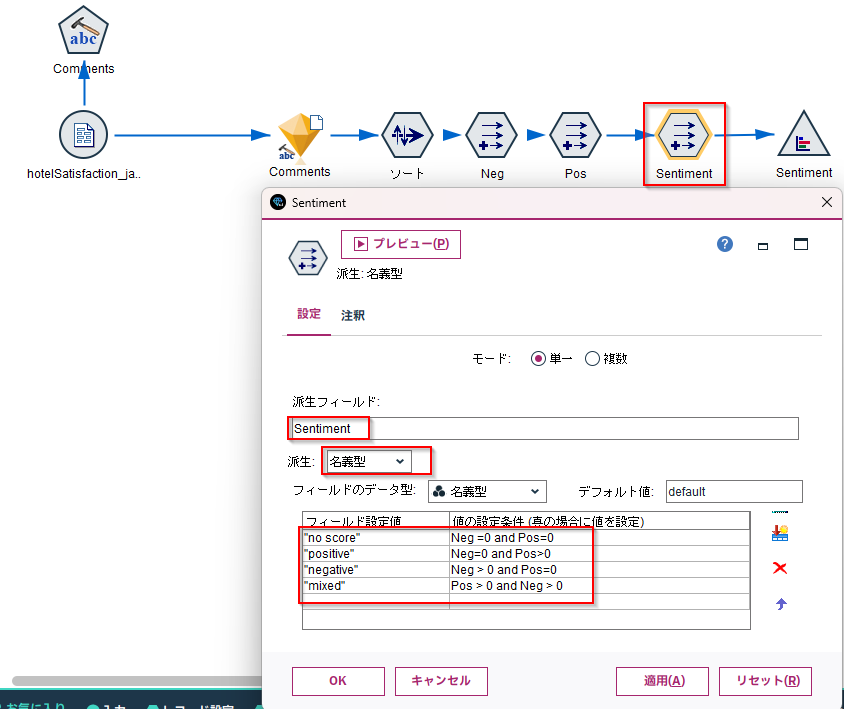
| 設定値 | 条件 |
|---|---|
| "no score" | Neg =0 and Pos=0 |
| "positive" | Neg=0 and Pos>0 |
| "negative" | Neg > 0 and Pos=0 |
| "mixed" | Pos > 0 and Neg > 0 |
以下のように判定できます。

棒グラフで表示してみます。
フィールド:Sentiment
色:Reason
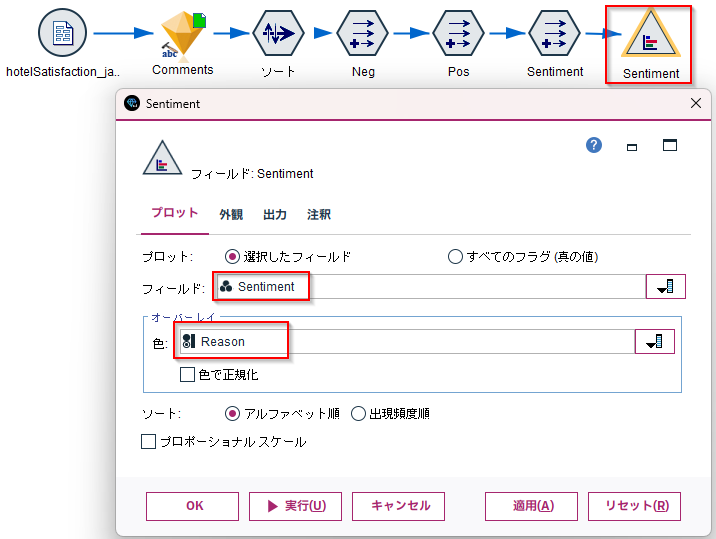
結果は以下のようになりました。
45.1%がポジティブな意見で、ネガティブな意見はレジャーの割合が高そうです。

レコードに展開して集計
次はカテゴリーをフィールドに展開していきます。
モデルナゲットをコピーして、「設定」タブで「レコードとしてのカテゴリー」を選びます。

やはり、モデルの実行は内部的にパラレル実行されるようで順序が変わってしまうので、ソートノードで並べておくのがおすすめです。また、スコアリングの実行は重めの処理なのでキャッシュしておくのもおすすめです。

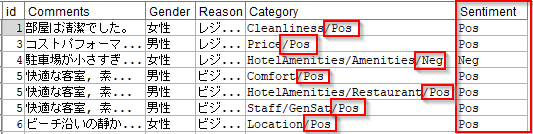
結果は以下のようになります。カテゴリーがレコードに展開されるので、一つのコメントが複数のカテゴリに該当すると複数行になります。この例ではid=5の「快適な客室, 素晴らしい朝食, 素晴らしいサービス」のコメントはComfort/Pos、HotelAmenities/Restaurant/Pos、Staff/GenSat/Posのカテゴリに該当したので3レコードになっています。
一方でid=2のコメントはどのカテゴリーにも該当しなかったのでレコードが削除されています。

センチメントの情報を抜き出します。Category列にNegやPosが含まれているかで判定しています。

| 設定値 | 条件 |
|---|---|
| Neg | Category matches "*/Neg" |
| Pos | Category matches "*/Pos" |
以下のように抜き出せます。
次に「置換」ノードで、CategoryからNegとPosを取り除いて上位カテゴリーのみを抜き出します。
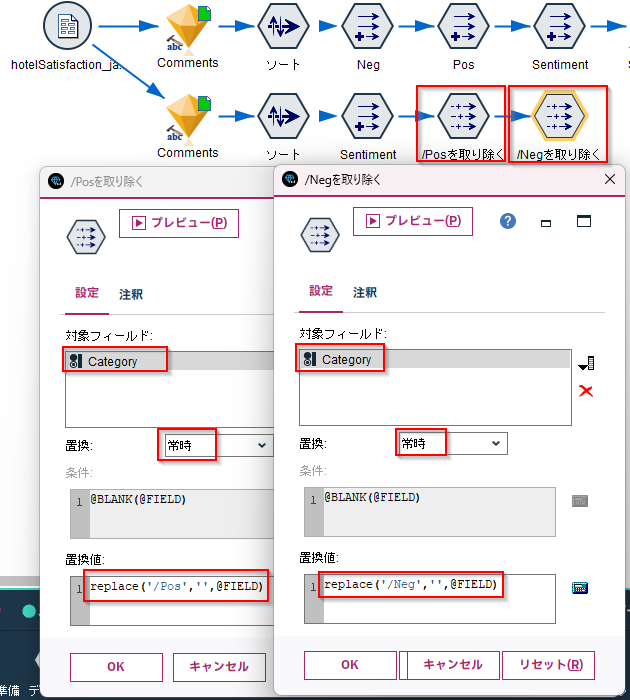
replace('/Pos','',@FIELD)
replace('/Neg','',@FIELD)
以下のようにCategoryからNegとPosを取り除けました。

カテゴリーごとのセンチメントを棒グラフで表示します。
フィールド:Category
色:Sentiment
色で正規化:チェック

以下の結果を見るとLocationやUpgradeはポジティブな意見が100%で、Confort/Sizeはネガティブな意見が多いことがわかります。

まとめ
やはり、Modelerのテキスト分析ではこの記事で紹介したカテゴリーのフラグ化が最も使われると思います。
レコードに展開して集計も上位カテゴリで分析する際には役に立つことがわかりました。ただ、このサンプルは「HotelSatisfaction (Japanese)」のテキスト分析パッケージはがあったので、比較的簡単な操作できましたが、カテゴリを自分で定義していくのはかなり大変です。
単純なコンセプトによるフラグ化が、やはり一番出番が多いのかなと思います。
サンプル
サンプルストリーム
サンプルデータ
参考
ホテル満足度のテキスト分析 - Docs | IBM Cloud Pak for Data as a Service
【CP4DaaS】SPSS ModelerのText Analyticsで日本語テキストデータを分析する (テキスト・マイニング) #ibmcloud - Qiita