はじめに
SPSS Modeler Premium 18.6では日本語テキスト分析が可能になっています。
テキスト分析についてはModelerFlowのチュートリアルがありますので、この内容をオンプレ版のModelerで実行してみます。
3つの記事からなっています。
①インタラクティブ・ワークベンチ(←この記事)
②カテゴリーのフラグ化
③テキストリンク分析
■テスト環境
- Modeler Premium 18.6
- Windows 11 64bit
テストデータ
@TTS22 さんが翻訳してくれたホテルの満足度調査のデータを使います。
Comments列にテキストデータが入っています。820件あります。

テキストマイニング
「IBM SPSS Text Analytics」のパレットから「テキストマイニング」のノードを接続します。
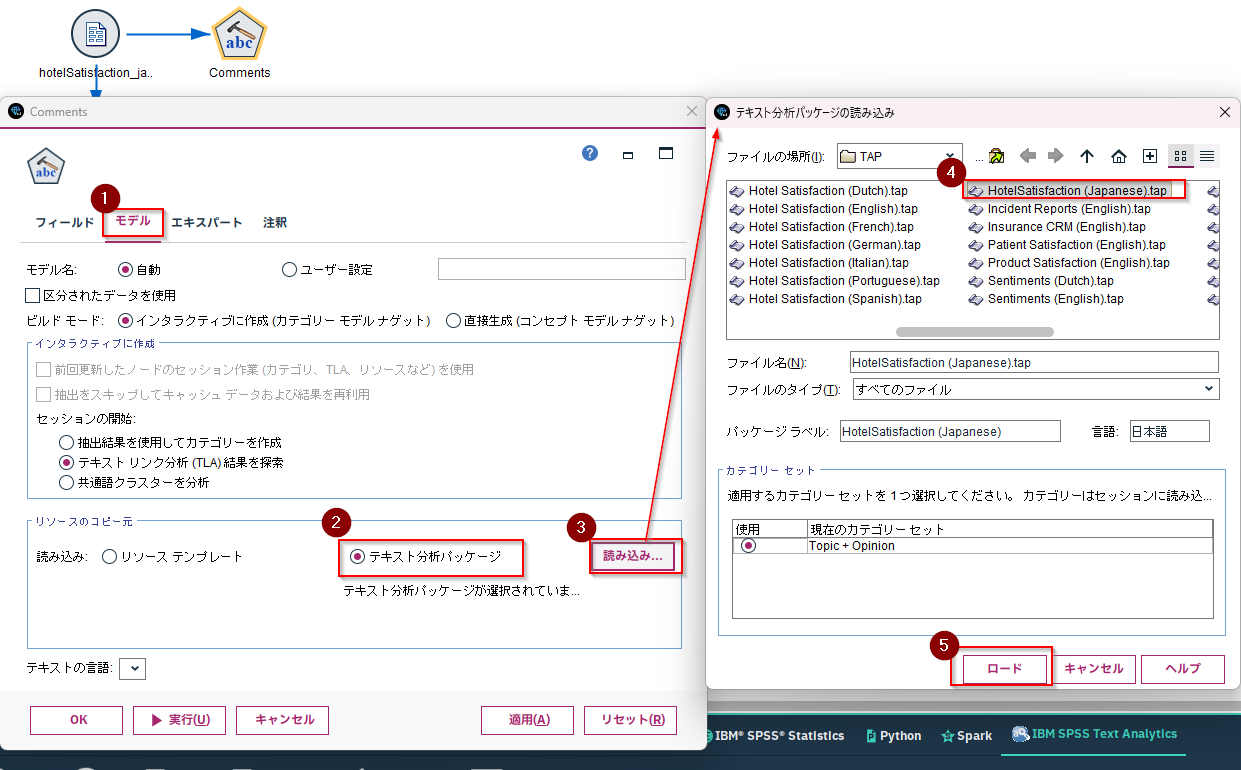
まず、フィールドのタブで以下を選択します。
IDフィールド:id
テキストフィールド:Comments

次に、モデルのタブで「テキスト分析パッケージ」を選び、「読み込み」をクリックし、「HotelSatisfaction (Japanese).tap」を選んで「ロード」します。
そして「実行します」
インタラクティブ・ワークベンチ
インタラクティブ・ワークベンチをつかうことで、テキスト分析をインタラクティブに行うことができます。また、この記事では行いませんが、最終的には整理したカテゴリーでフラグを立てるモデルを作る事ができます。
コンセプト
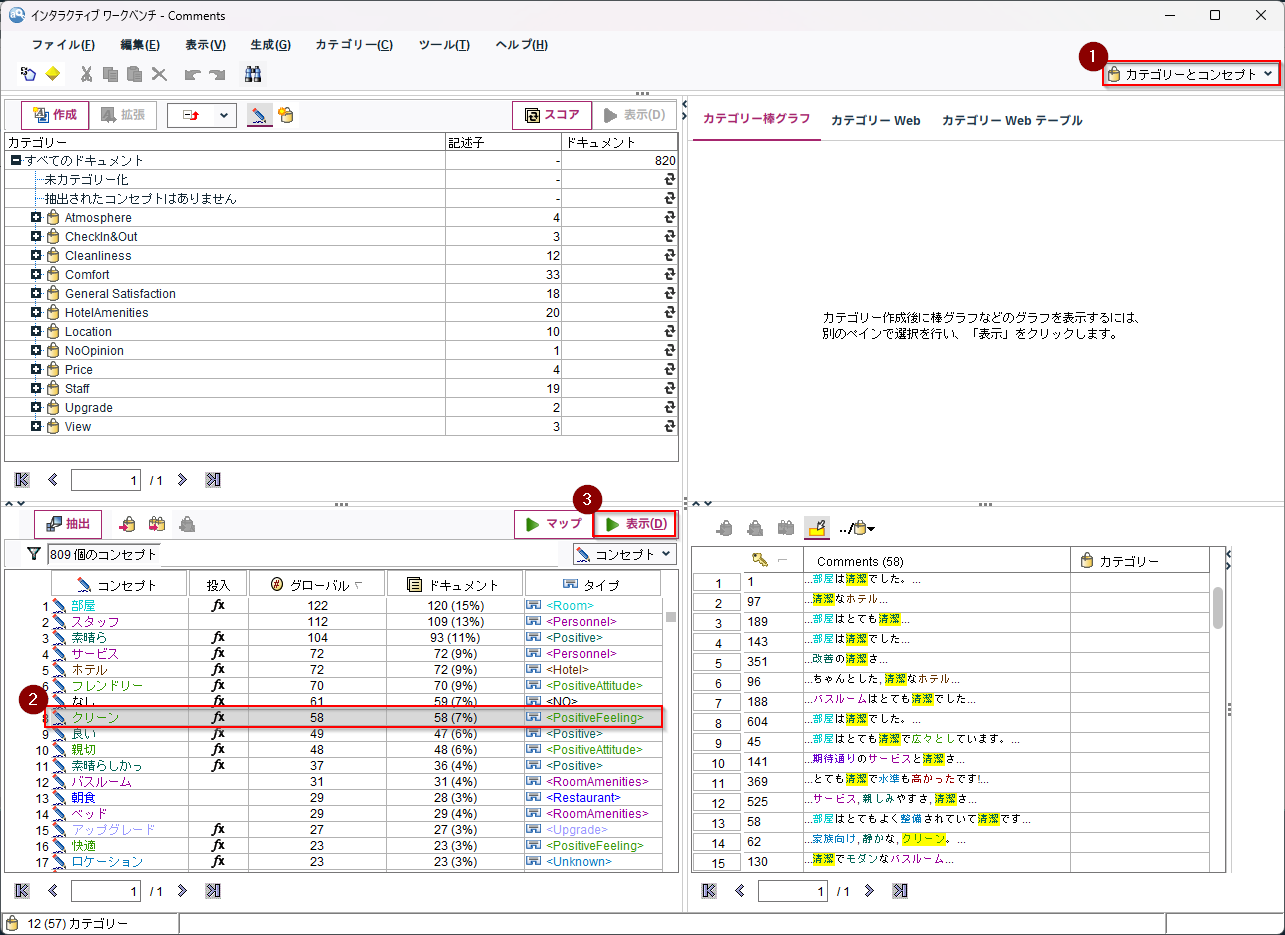
「カテゴリーとコンセプト」を選びます。
左下にテストデータから抽出されたコンセプトがリストされています。
「クリーン」は58個のドキュメントに含まれ、58回出現しています。グローバルの方がドキュメントより多いコンセプトもあります。例えば「部屋」はグローバルが122でドキュメントは120ですので、同一文書の中で複数回「部屋」というコンセプトが出現しているケースがあることがわかります。
「コンセプト」とはいくつかの類似キーワードからなる概念です。「クリーン」というコンセプトを選んで「表示」をクリックすると、抽出された元文書が表示されます。これを見ると「クリーン」というコンセプトは「清潔」という類似キーワードも含んでいることがわかります。
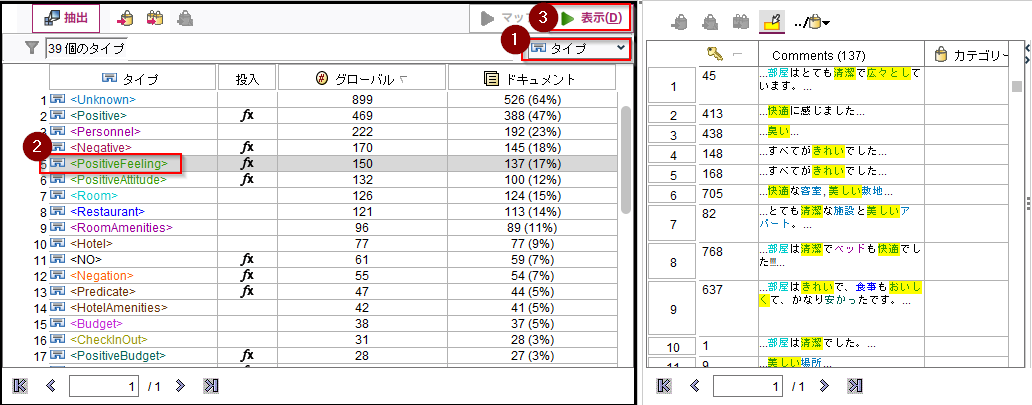
また、「クリーン」は<PositiveFeeling>という「タイプ」も割り当てられています。「タイプ」は複数の「コンセプト」をまとめたものです。「快適」も<PositiveFeeling>という「タイプ」に分類されています。
「コンセプト」を「タイプ」に切り替えると、「タイプ」がリストされます。<PositiveFeeling>は137個のドキュメントに出現していることがわかります。<PositiveFeeling>を選んで、「表示」をクリックすると、抽出された元文書が表示されます。「きれい」、「美しい」などが含まれた文書も抽出されています。
カテゴリー
やはり「カテゴリーとコンセプト」を選びます。
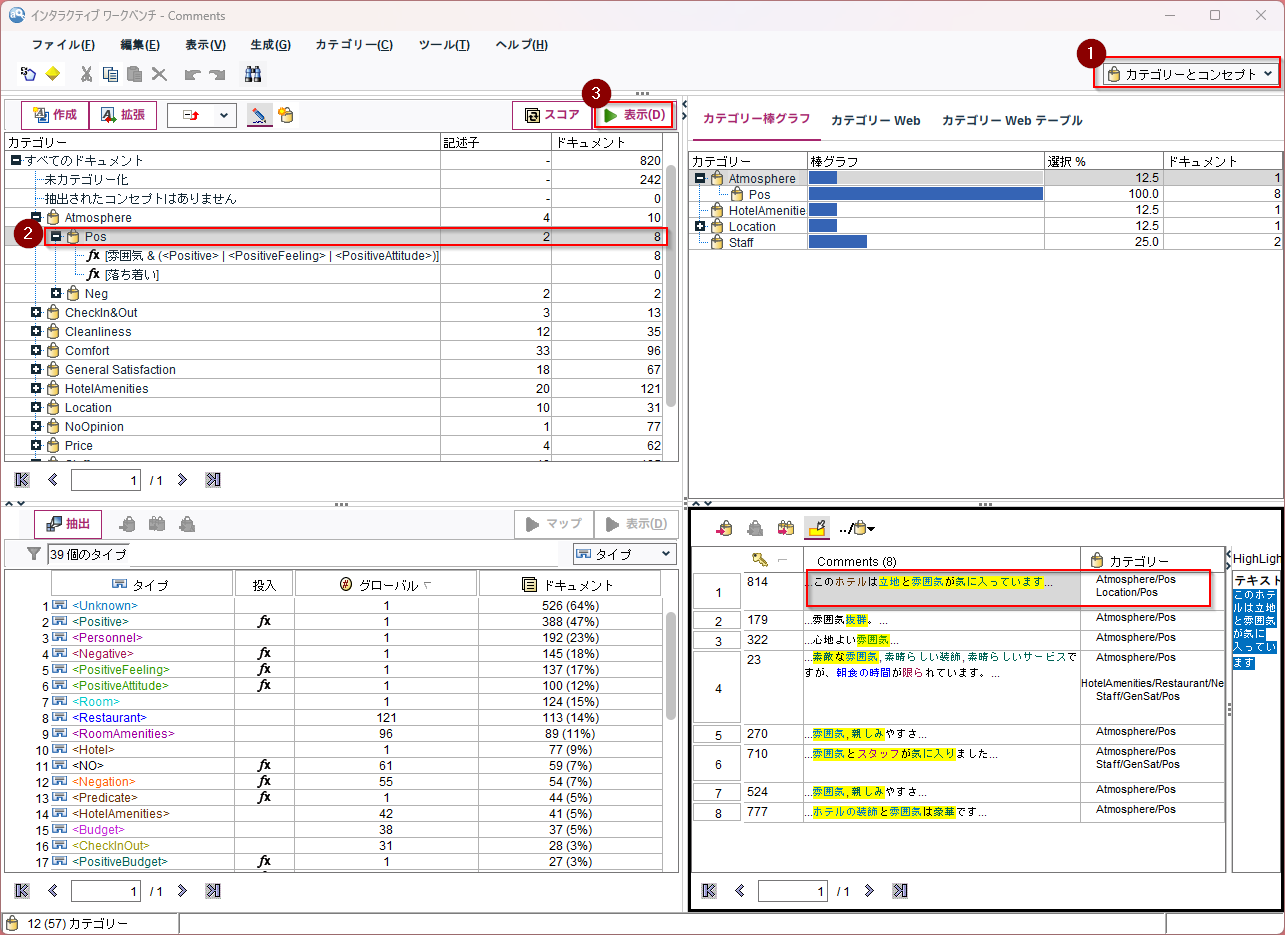
「カテゴリー」は「コンセプト」や「タイプ」の組合せでルールをつくって分類したものです。「Atomosphere/Pos」は「雰囲気」というコンセプトとタイプなどの組合せが分類される「カテゴリー」です。
「表示」をクリックすると、対象ドキュメントの件数が計算され、右下のペインに抽出された元文書と分類された「カテゴリー」が表示されます。これをみると「カテゴリー」複数の「カテゴリー」に分類されうることがわかります。「このホテルは立地と雰囲気が気に入っています」という文書は「Atomosphere/Pos」、「Location/Pos」の2つの「カテゴリー」に分類されています。
テキスト・リンク分析
「テキストリンク分析」に切り替えます。
「タイプ」の組合せ出現パターンを定義したルールにマッチしたTLAパターンがリストされます。<Personal><PositiveAttitude>のルールには69件ヒットしています。
<Personal><PositiveAttitude>を選択すると「コンセプトWeb」に同時に出現した「コンセプト」がリンクで表示されます。「スタッフ」ー「親切」、「スタッフ」ー「フレンドリー」は特に出現頻度が多いことがわかります。また「表示」をクリックすると、抽出された元文書が表示されます。

まとめ
インタラクティブ・ワークベンチは、Modelerから使う場合はモデルを作成するためにだけ使うことも多いと思いますが、これ単体でもテキスト分析を行うことができます。特に該当している文書を表示する機能がわかりやすいと思います。
とはいえ、より込み入った集計や機械学習をつかった分析を行うためにはやはりカテゴリーのモデルを作る事が必要になってきますので、記事②カテゴリーのフラグ化を参考にしてください。
サンプル
サンプルストリーム
サンプルデータ
参考
ホテル満足度のテキスト分析 - Docs | IBM Cloud Pak for Data as a Service
【CP4DaaS】SPSS ModelerのText Analyticsで日本語テキストデータを分析する (テキスト・マイニング) #ibmcloud - Qiita