1. はじめに
IBM Cloud Pak for Data as a Service(CP4DaaS)のSPSS Modelerにはテキストデータ分析を行うノードが提供されています。これまでは日本語に対応していませんでしたが、2024年10月9日の新機能により日本語のテキストデータにも対応しました。
SPSS Modelerの「テキスト分析」カテゴリーには以下の3つのノードが含まれます。

| ノード | 説明 |
|---|---|
| 言語の識別子 | ソース・データ内のテキスト・フィールドの自然言語を識別します。 |
| テキスト・リンク分析 | 既知のパターンに基づいてテキスト・データのコンセプト間の関連性を特定します。 |
| テキスト・マイニング | テキストから主要なコンセプトを抽出し、これらのコンセプトとその他のデータを使用してカテゴリーを作成します。 |
製品ドキュメントにテキスト分析のチュートリアルとしてホテル満足度のテキスト分析
が提供されています。
このチュートリアルで使用しているストリームやテキスト・データはリソース・ハブのSPSS Modeler projectに含まれていますが、英語のテキストを使用しています。
(CP4DaaSにログインすると画面右上のリンクからプロジェクトをダウンロードできます。)

この記事ではチュートリアルと同様の方法で、「テキスト・マイニング」ノードを使用して日本語のテキストを分析する手順を記載します。
-
作成するストリーム

-
実行結果例(Sentiment)
コメントごとにポジティブかネガティブかの評価を表示

-
実行結果例(ポジティブ_ワードクラウド)
ポジティブな評価のカテゴリーをワードクラウドで可視化

-
実行結果例(ネガティブ_ワードクラウド)
ネガティブな評価のカテゴリーをワードクラウドで可視化

使用する日本語テキストデータと作成するSPSSストリームのサンプルはこちらからダウンロードできます。
なお「テキスト・リンク分析」ノードを使用した手順は別の記事で記載しています。
2. プロジェクトの作成
最初にwatsonx.ai Studioのプロジェクトを作成します。
リソース・ハブで提供されているプロジェクトをインポートするか、新規に空のプロジェクトを作成します。
3. 日本語テキストデータの準備
リソース・ハブからダウンロードしたプロジェクトに含まれるテキストデータを日本語化します。対象のファイルは「hotelSatisfaction.xlsx」です。
820件のホテルの満足度に関する文章が含まれますが、機会翻訳サービス等を使用してヘッダー行以外を日本語に翻訳します。
以下は翻訳後のデータ例です。ここでは「hotelSatisfaction_japanese.xlsx」として保存し、プロジェクトにアップロードします。

4. SPSS Modelerストリームの作成
プロジェクトにSPSS Modelerストリームを作成します。
ここでは「Hotel Satisfaction Text Mining」という名前で作成しています。

5. 「テキスト・マイニング」ノードを使用したテキスト分析
ここでは以下のブランチ・ターミナル・ノードを作成します。
- Sentiment
コメントごとにポジティブかネガティブかの評価を表示します。 - ポジティブ_ワードクラウド
ポジティブな評価のカテゴリーをワードクラウドで可視化します。 - ネガティブ_ワードクラウド
ネガティブな評価のカテゴリーをワードクラウドで可視化します。
5-1. Sentiment
-
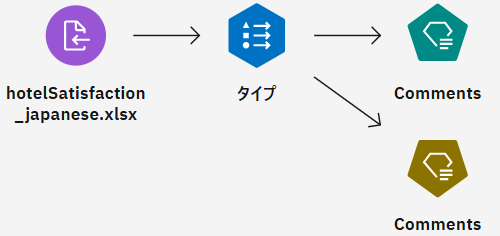
作成したSPSS Modelerストリームを開きます。
「データ資産」ノードを追加し、日本語テキストデータ(hotelSatisfaction_japanese.xlsx)を指定します。

-
「タイプ」ノードを追加し、「データ資産」ノードと接続後、設定画面を開きます。「値の読み込み」をクリックし、値が読み込まれたら保存します。

-
「テキスト・マイニング」ノードを追加し、「タイプ」ノードと接続後、設定画面を表示します。テキストフィールドに「Comments」、IDフィールドに「id」、「リソースの選択 +」から「テキスト分析パッケージ」タブで「Hotel Satisfaction (Japanese)」を指定して保存します。

-
「テキスト・マイニング」ノード(前の手順により「Comments」という名前になっています。)を実行します。

-
出力された「Comments」をクリックします。
-
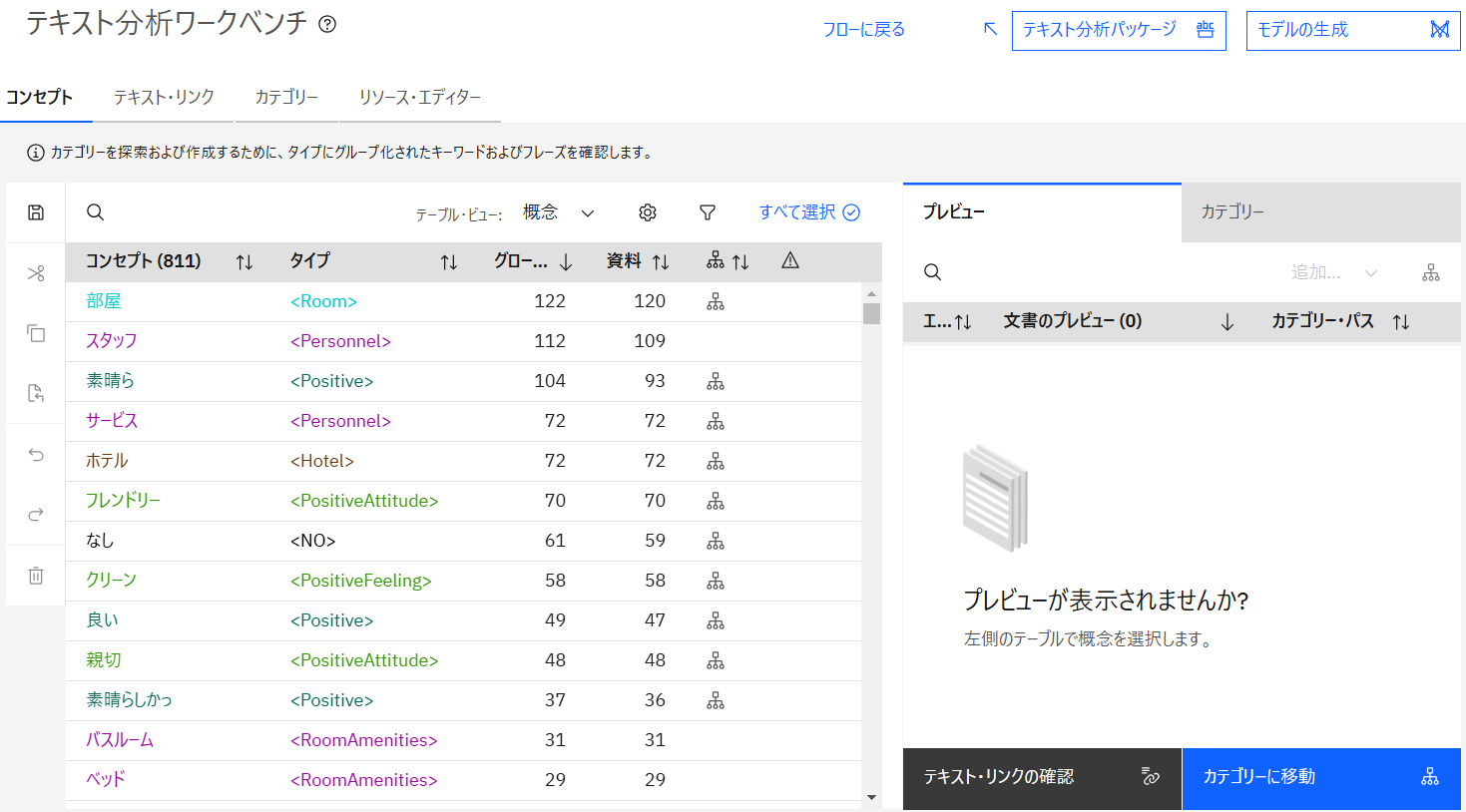
テキスト分析ワークベンチが起動します。この機能を使用して抽出された結果の微調整が行えますが、ここではデフォルトのまま、画面右上の「モデルの作成」をクリックします。
-
「ビルド」をクリックします。

-
「フローに戻る」をクリックします。

-
「保存して終了」をクリックします。
-
「Comments」というモデル・ナゲットが作成されました。モデル・ナゲットをダブルクリックし設定画面を開きます。
-
「設定」セクションを開き、スコアリング・モードに「フィールドとして」が選択されていることを確認し、True値に「1」、False値に「0」を設定し保存します。

-
「フィールド作成」ノードを追加し、「Comments」モデル・ナゲットと接続後、設定画面を表示します。派生フィールド名に「Neg」、式に以下の式を指定して保存します。
式sum_n(@FIELDS_MATCHING("Category_*Neg"))
-
「フィールド作成」ノードを追加し、前の手順の「フィールド作成」ノードと接続後、設定画面を表示します。派生フィールド名に「Pos」、式に以下の式を指定して保存します。
式sum_n(@FIELDS_MATCHING("Category_*Pos"))
-
「フィールド作成」ノードを追加し、前の手順の「フィールド作成」ノードと接続後、設定画面を表示します。派生フィールド名に「Sentiment」、派生と尺度に「名義」を設定し、「値の構成 +」をクリックします。

-
「値の追加 +」をクリックし、以下の通りフィールド設定値と値の設定条件を入力した後、「OK」をクリックします。
フィールド設定値 値の設定条件(真の場合に値を設定) "no score" Neg =0 and Pos=0 "positive" Neg=0 and Pos>0 "negative" Neg > 0 and Pos=0 "mixed" Pos > 0 and Neg > 0 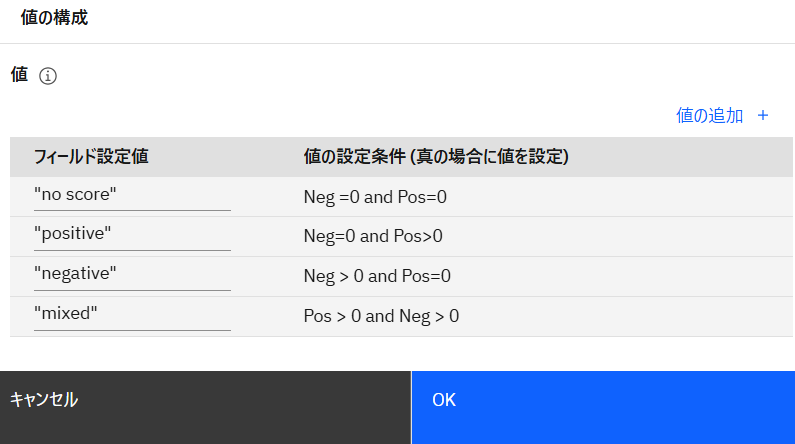
-
「保存」をクリックします。
-
「フィルター」ノードを追加し、「フィールド作成」ノードと接続後、設定画面を開きます。先頭に「Category_」がある入力フィールドをフィルターし、それ以外(id、Comments、Gender、Reason、Neg、Pos、Sentiment)を残し、保存します。

-
「ソート」ノードを追加し、「フィルター」ノードと接続後、設定画面を開きます。ソート順に「id」「昇順」を指定し、保存します。

-
「表」ノードを追加し、「ソート」ノードと接続後、設定画面を開きます。名前に「Sentiment」を指定して保存します。
-
以下のストリームができたら「Sentiment」ノードを選択してストリームを実行し、表の出力を確認してみます。

-
コメントごとにネガティブ(Neg)な内容の数、ポジティブ(Pos)な内容の数、Sentimentが出力されています。Sentimentは「フィールド作成」ノード(Sentiment)に設定した条件(例:Neg=0 and Pos>0 の場合、"positive")で判断された結果を示しています。
5-2. ポジティブ_ワードクラウド / ネガティブ_ワードクラウド
ここでは別のモデル・ナゲットを追加して、ワードクラウドを表示するためのブランチ・ターミナル・ノードを作成します。
またテキスト分析ワークベンチを使用して、デフォルトでは英語になっているカテゴリー名を日本語に変更する手順も合わせて記載します。
-
「テキスト・マイニング」ノード(Comments)を選択し、ストリームを実行します。

-
出力された「Comments」をクリックし、テキスト分析ワークベンチを起動します。
-
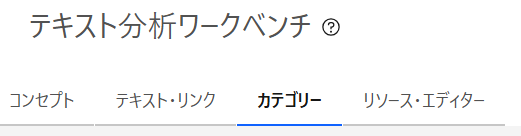
「カテゴリー」タブを開きます。
-
カテゴリーから「Comfort」を選択し、「カテゴリ」メニューから「カテゴリー名の変更」を選択します。

-
「快適さ」に変更します。

-
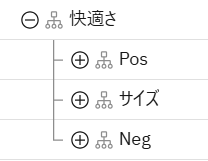
「快適さ」を展開し、「Size」も同様の手順で日本語に変更します。
-
その他のカテゴリーとサブカテゴリー(Pos、Neg以外)も同様に日本語に変更します。

-
画面右上の「モデルの作成」をクリックします。

-
「ビルド」をクリックします。
-
「フローに戻る」をクリックします。
-
「保存して終了」をクリックします。
-
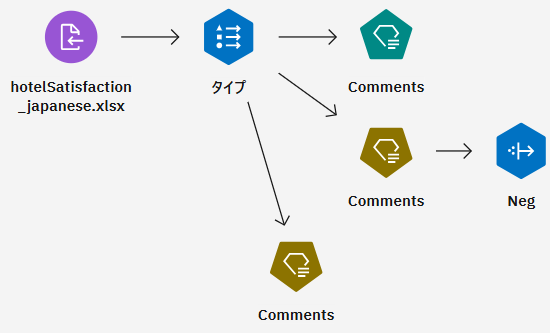
「Comments」というモデル・ナゲットが新しく追加されました。モデル・ナゲットをダブルクリックし設定画面を開きます。
-
カテゴリーが日本語になっていることを確認します。
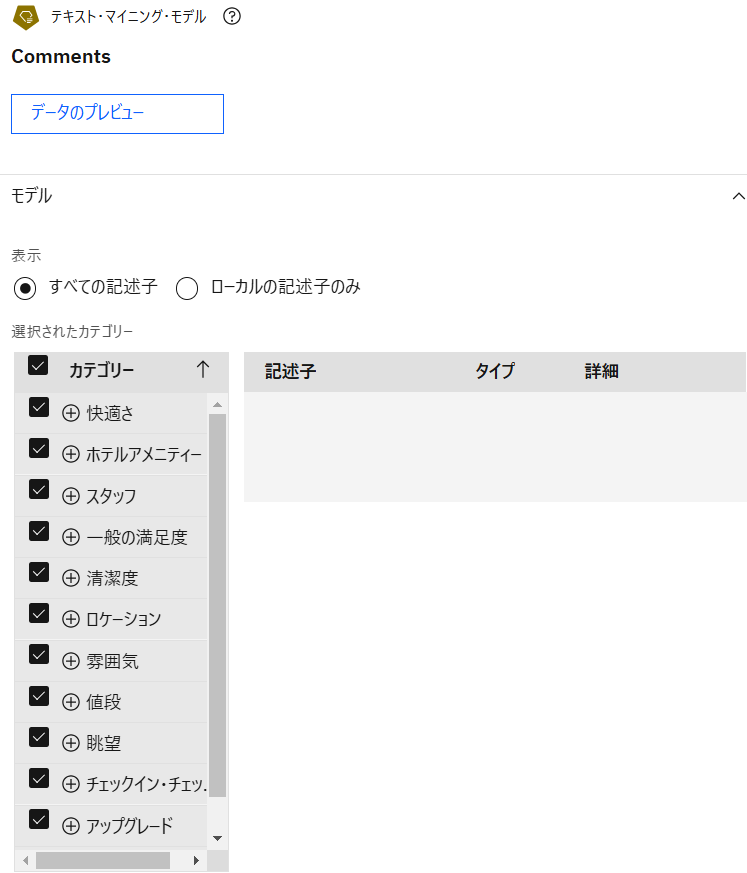
-
「設定」セクションを開き、スコアリング・モードに「レコードとして」を選択し、保存します。

-
「フィールド作成」ノードを追加し、「Comments」モデル・ナゲットと接続後、設定画面を表示します。派生フィールド名に「Sentiment」、派生と尺度に「名義」を設定し、「値の構成 +」をクリックします。

-
「値の追加 +」をクリックし、以下の通り「フィールド設定値」と「値の設定条件」を入力した後、「OK」をクリックします。
フィールド設定値 値の設定条件(真の場合に値を設定) Neg Category matches "*/Neg" Pos Category matches "*/Pos" 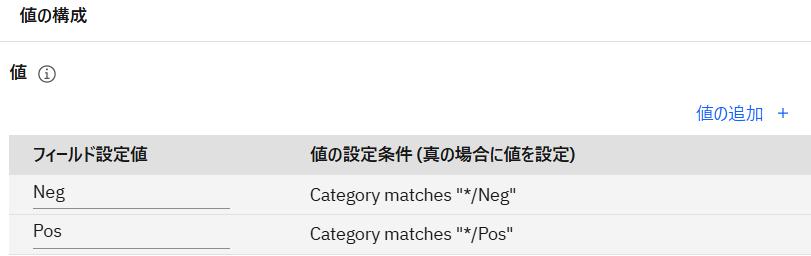
-
「保存」をクリックします。
-
「置換」ノードを追加し、「フィールド作成」ノードと接続後、設定画面を表示します。ノード名を「Pos」、対象フィールドに「Category」、置換に「常時」、置換文字列に以下の式を設定し保存します。
置換文字列replace('/Pos','',@FIELD)
-
「置換」ノードを追加し、前の手順の「置換」ノード(Pos)と接続後、設定画面を表示します。ノード名を「Neg」、対象フィールドに「Category」、置換に「常時」、置換文字列に以下の式を設定し保存します。
置換文字列replace('/Neg','',@FIELD)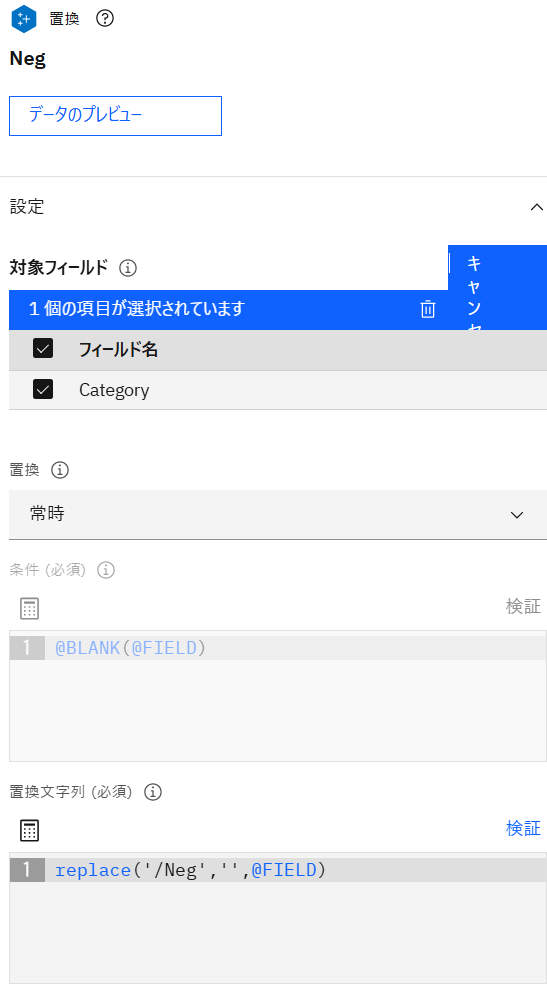
-
「条件抽出」ノードを追加し、「置換」ノード(Neg)と接続後、設定画面を表示します。名前に「ポジティブ」、条件に以下の式を設定し保存します。
条件Sentiment = "Pos"
-
「条件抽出」ノードを追加し、「置換」ノード(Neg)と接続後、設定画面を表示します。名前に「ネガティブ」、条件に以下の式を設定し保存します。
 条件
条件Sentiment = "Neg"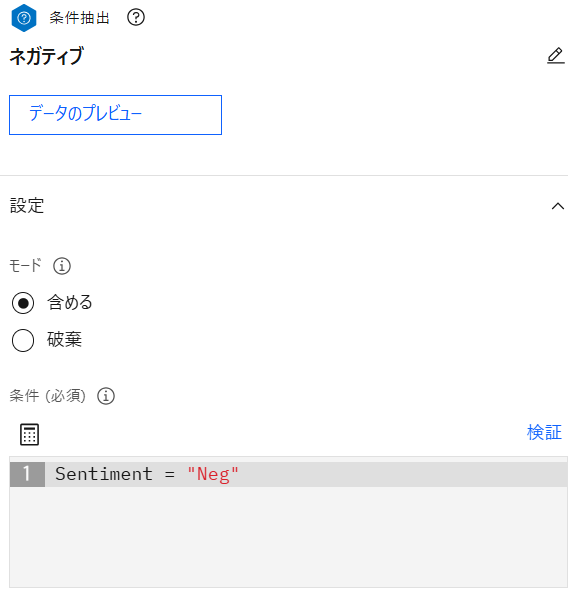
-
「グラフ」ノードを追加し、「条件抽出」ノード(ポジティブ)と接続後、設定画面を表示します。名前を「ポジティブ_ワードクラウド」に設定し、「図表ビルダーの起動」ボタンをクリックします。

-
グラフタイプに「ワードクラウド」を選択し、ソースに「Category」を選択します。ワードクラウドが表示されることを確認し、画面右上の「グラフ定義の追加」をクリックします。

-
「フローに戻る」をクリックした後、「グラフ」ノードを保存します。

-
「グラフ」ノードを追加し、「条件抽出」ノード(ネガティブ)と接続後、設定画面を表示します。名前を「ネガティブ_ワードクラウド」に設定し、「図表ビルダーの起動」ボタンをクリックします。

-
グラフタイプに「ワードクラウド」を選択し、ソースに「Category」を選択します。ワードクラウドが表示されることを確認し、画面右上の「グラフ定義の追加」をクリックします。

-
「フローに戻る」をクリックした後、「グラフ」ノードを保存します。
-
以下のストリームができたら「ポジティブ_ワードクラウド」ノードと「ネガティブ_ワードクラウド」ノードをそれぞれ選択してストリームを実行し、表の出力を確認してみます。
-
「ポジティブ_ワードクラウド」ノードの表示例です。
-
「ネガティブ_ワードクラウド」ノードの表示例です。
おことわり
このサイトの掲載内容は私自身の見解であり、必ずしも所属会社の立場、戦略、意見を代表するものではありません。 記事は執筆時点の情報を元に書いているため、必ずしも最新情報であるとはかぎりません。 記事の内容の正確性には責任を負いません。自己責任で実行してください。