SPSS Modeler18.5の新機能の ネイティブ Python APIのテストをしてみました。これは、「拡張ノード」のなかでpandasを使ってModelerのデータを読んだり書いたりすることができる機能です。
これは日本からのリクエストが実現したものです。
Modeler18.4以前でも、拡張ノードでPythonを使うことはできましたが、「Python for Spark」のみでした。Sparkを使っていたために、初回起動時はオーバーヘッドがありました。2回目以降の実行ではあまり気にならないのですが、
また、pandasを使いたい場合には、toPandas()で変換するという面倒さとメモリの無駄遣いがありました。
この記事ではネイティブ Python APIが、どのように利用可能かをテストしてみました。
サンプルストリームは以下です。
- テスト環境
- Windows 11 64bit
- Modeler 18.5
- Python 3.10.7
各ノードの利用方法は以下の記事に詳しく書きました。
| アイコン | 拡張ノード |
|---|---|
 |
拡張の入力 |
 |
拡張の変換 |
 |
拡張のモデル |
 |
拡張の出力 |
 |
拡張のエクスポート |
バージョンなどの確認
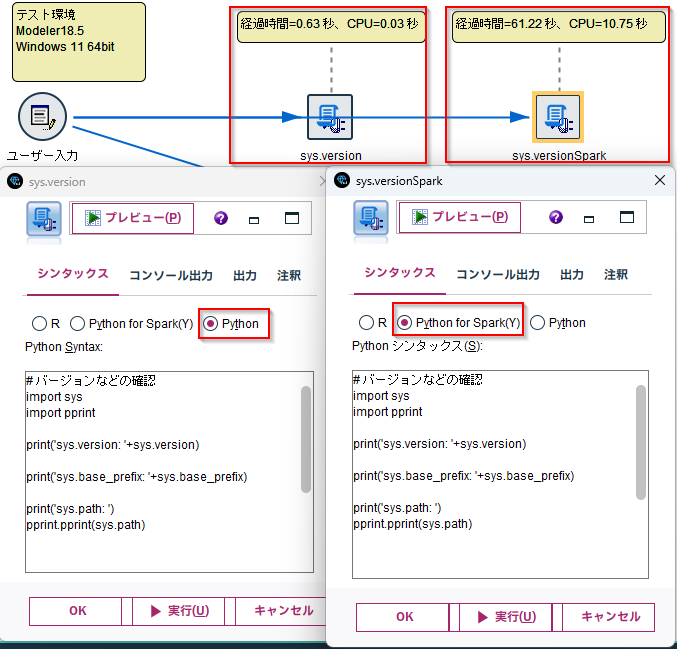
まず「拡張の出力ノード」で、Pythonのバージョンや実体を確認してみます。
「Python」を選択し、「Python Syntax」の欄に以下のスクリプトを記入します。
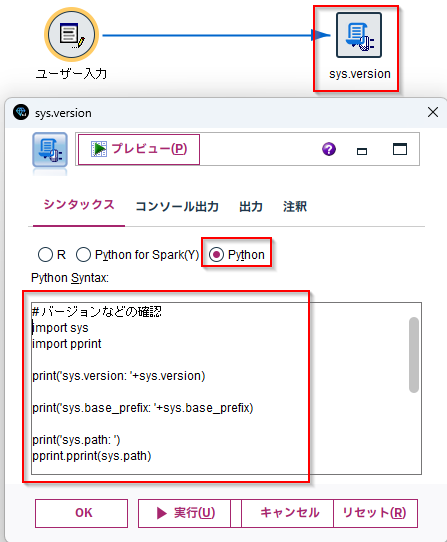
import sys
import pprint
print('sys.version: '+sys.version)
print('sys.base_prefix: '+sys.base_prefix)
print('sys.path: ')
pprint.pprint(sys.path)
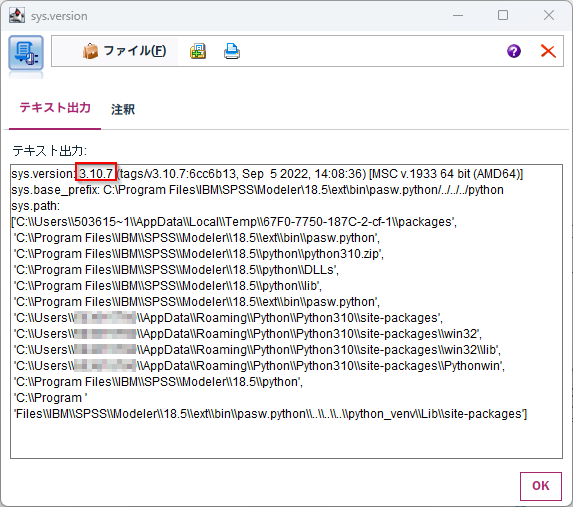
Pythonのバージョンは3.10.7でModelerのインストールディレクトリは配下にある製品同梱のPythonを使っています(Python for Sparkでは別にユーザーが導入したPythonを利用することもできましたが、この機能では製品同梱で固定です)。
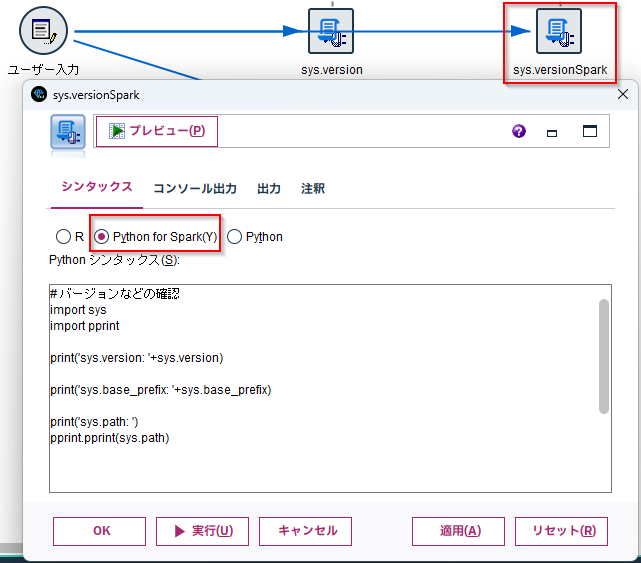
Python for Sparkは引き続き利用可能
Python for Sparkは引き続き利用可能です。
ネイティブPythonとPython for Sparkとのパフォーマンスの違い
上の単にバージョンを出力するスクリプトを実行した場合で、 ネイティブPythonとPython for Sparkとのパフォーマンスの違いを確認してみたところ、やはり大きな差がありました。Python for Sparkは30-60秒程度の起動のオーバーヘッドがありました。
| 初回経過秒 | 二回目経過秒 | |
|---|---|---|
| ネイティブPython | 0.63 | 0.76 |
| Python for Spark | 61.22 | 1.39 |
パッケージ導入
パッケージ導入方法は以下の記事に書きました。
ネイティブpythonの拡張ノードでつかうpythonパッケージを導入する
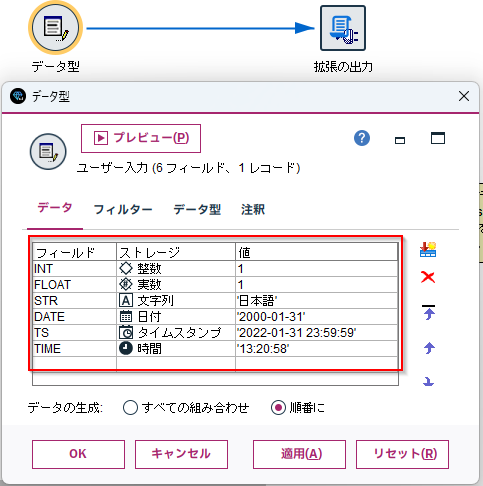
データ型
各データ型がどのように扱われるかについても調べました。
結論からいうと以下のマッピングになっていました。
| Modelerデータ型 | Pythonデータ型 |
|---|---|
| 整数 | int64 |
| 実数 | float64 |
| 文字列型 | str |
| 日付 | datetime.date |
| タイムスタンプ | datetime64[ns] |
| 時間 | datetime.time |
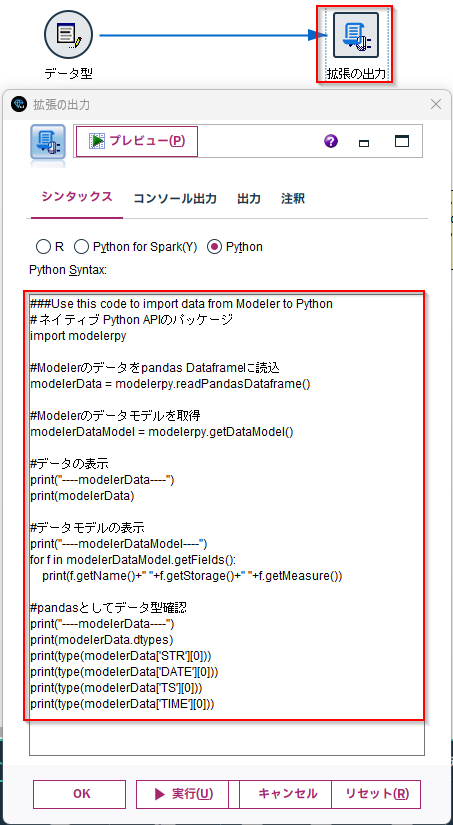
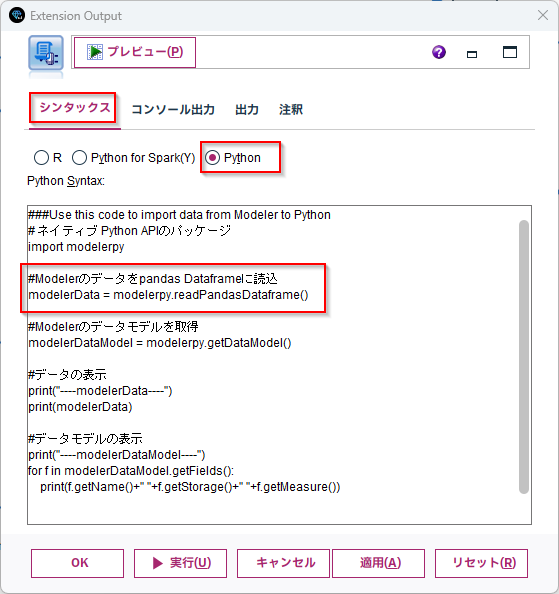
# ネイティブ Python APIのパッケージ
import modelerpy
#Modelerのデータをpandas Dataframeに読込
modelerData = modelerpy.readPandasDataframe()
#Modelerのデータモデルを取得
modelerDataModel = modelerpy.getDataModel()
#データの表示
print("----modelerData----")
print(modelerData)
#データモデルの表示
print("----modelerDataModel----")
for f in modelerDataModel.getFields():
print(f.getName()+" "+f.getStorage()+" "+f.getMeasure())
#pandasとしてデータ型確認
print("----modelerData----")
print(modelerData.dtypes)
print(type(modelerData['STR'][0]))
print(type(modelerData['DATE'][0]))
print(type(modelerData['TS'][0]))
print(type(modelerData['TIME'][0]))
結果は以下のようになっています。(日本語のコンソール出力が文字化けしていますが、実データは特に化けていません)
----modelerData----
INT FLOAT STR DATE TS TIME
0 1 1.0 ���{�� 2000-01-31 2022-01-31 23:59:59 13:20:58
----modelerDataModel----
INT integer continuous
FLOAT real continuous
STR string flag
DATE date continuous
TS timestamp continuous
TIME time continuous
----modelerData----
INT int64
FLOAT float64
STR object
DATE object
TS datetime64[ns]
TIME object
dtype: object
<class 'str'>
<class 'datetime.date'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'datetime.time'>
テンプレート
「インポート」「変換」「モデル作成」「出力」「エクスポート」それぞれにあわせた拡張ノードのテンプレートが自動的に入るようになっています。
例えば「インポート」の場合ですと以下のスクリプトが自動的に入力されます。
###Use this code to export data from Python to Modeler
#import modelerpy
#if modelerpy.isComputeDataModelOnly():
# outputDataModel = None
###Compute output data model here
# modelerpy.setOutputDataModel(outputDataModel)
#else:
# outputData = None
###Compute output data here
# modelerpy.writePandasDataframe(outputData)
ちなみにこれも日本からのリクエストが実現したものです
その他
- コンソールへの日本語出力は現時点では文字化けしています。ただし、データとして扱う分には問題はありません。
- コンソールは、以前実行の出力が残ってしまうことがあるようです。
- scikitlearnのモデルはストリーム内に保存されるようになりました。外部のフォルダにpickleで保存する必要はありません。ちなみにこれも日本からのリクエストが実現しました。
参考
SPSS Modeler 18.5リリース #SPSS - Qiita