SPSS Modeler18.5の新機能の ネイティブ Python APIのテストをしてみました。これは、「拡張ノード」のなかでpandasを使ってModelerのデータを読んだり書いたりすることができる機能です。
この記事ではネイティブ Python APIで「拡張のインポートノード」が、どのように利用可能かをテストしてみました。
マニュアルにサンプル・ストリームがついていましたので、これを修正してテストしてみています。
サンプルストリームは以下です。
- テスト環境
- Windows 11 64bit
- Modeler 18.5
- Python 3.10.7
拡張のインポート
CSVファイルの読み込み
「Python」を選択し、「Python Syntax」の欄に以下のスクリプトを記入します。

###Use this code to export data from Python to Modeler
# ネイティブ Python APIのパッケージ
import modelerpy
import pandas
#データモデルの参照時
if modelerpy.isComputeDataModelOnly():
outputDataModel = None
###Compute output data model here
###出力データモデルの設定
outputDataModel = modelerpy.DataModel([
modelerpy.Field('Age', 'integer', 'continuous'),
modelerpy.Field('Sex', 'string', 'flag'),
modelerpy.Field('BP', 'string', 'nominal'),
modelerpy.Field('Choles', 'string', 'nominal'),
modelerpy.Field('Na', 'real', 'continuous'),
modelerpy.Field('K', 'real', 'continuous'),
modelerpy.Field('Drug', 'string', 'nominal'),
])
modelerpy.setOutputDataModel(outputDataModel)
#データ出力時
else:
outputData = None
###Compute output data here
###ファイルからデータの読み込み
outputData = pandas.read_csv('C:/Program Files/IBM/SPSS/Modeler/18.5/Demos/DRUG1n')
###データの出力
modelerpy.writePandasDataframe(outputData)
コードの内容
大きくはデータモデルの処理とデータ自体の処理の二つに分かれています。
処理の分岐
「データモデルの処理」と「データ自体の処理」の分岐を以下のif文で行っています。
if modelerpy.isComputeDataModelOnly()
modelerpy.isComputeDataModelOnly():のif文は、後続のノードがデータモデルを参照する場合に実データを用意しなくていいための分岐になります。Modelerは、後続のノードを接続した際に前のノードのデータモデルを参照します。例えば「フィルター」ノードを接続した場合にはデータは必要ありませんが、「列名」の情報は必要になります。このif文をなくしても動作はしますが、列名などのデータモデルを参照したいだけなのにデータの読み込みが行われてしまうため、無駄な処理が動いてしまいます。
なお、このif文は、「拡張の変換」ノードと「拡張モデル」ノードといった後続ノードが必要なノードでも、同様に使われます。
データモデルの処理
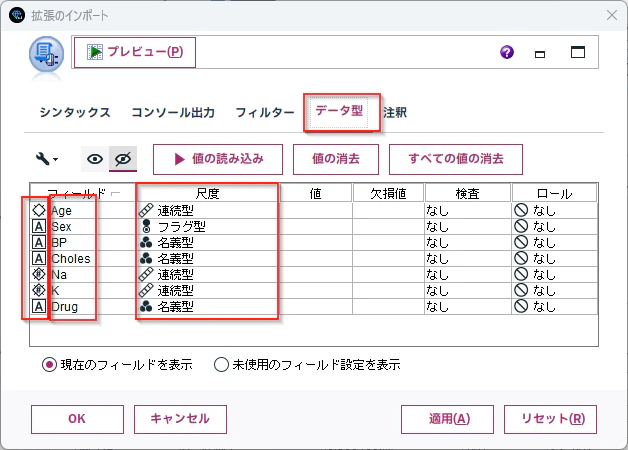
modelerpy.DataModelの配列にmodelerpy.Fieldで各列のデータモデルを定義しています。「フィールド名」、「データ型」、「尺度」を指定しています。これは後続のノードで利用されます。
outputDataModel = modelerpy.DataModel([
modelerpy.Field('Age', 'integer', 'continuous'),
modelerpy.Field('Sex', 'string', 'flag'),
modelerpy.Field('BP', 'string', 'nominal'),
modelerpy.Field('Choles', 'string', 'nominal'),
modelerpy.Field('Na', 'real', 'continuous'),
modelerpy.Field('K', 'real', 'continuous'),
modelerpy.Field('Drug', 'string', 'nominal'),
])
「データ型」タブで確認してみると、以下の部分の定義になっています。
データの処理
以下でCSVファイルからデータをpandas DataFrameに読み込んでいます。
pandas.read_csv('C:/Program Files/IBM/SPSS/Modeler/18.5/Demos/DRUG1n')
以下のmodelerpy.writePandasDataframe(outputData)で後続のノードにデータを出力しています。
modelerpy.writePandasDataframe(outputData)
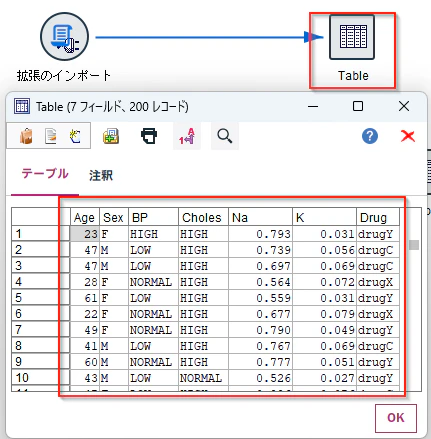
結果
以下のように、データが読み込めました。
参考
SPSS Modeler18.5の新機能の ネイティブ Python API #SPSS - Qiita
ネイティブ Python拡張のインポートノード:CSVファイルの読み込み
ネイティブ Python拡張の変換ノード:置き換え
ネイティブ Python拡張モデルノード:モデル作成OneClassSVM
ネイティブ Python拡張の出力ノード:データとペアプロット図(散布図行列)の表示
ネイティブ Python拡張のエクスポートノード:CSVファイルの出力
ネイティブpythonの拡張ノードでつかうpyhtonパッケージを導入する