どんなアプリ?
みんな大好き「いらすとや」さん
記事の挿絵に使ってみたいけれども、適切な画像を探すのに苦労していませんか?
検索キーワードを何にしようか迷ったり、一つ一つ検索するのは面倒だなぁとか。
そんな苦労を解決してくれる、
ドキュメントの文章をまるっと全部与えると、自動で特徴的なキーワードを見つけてくれて、そのトピックに合った画像を「いらすとや」さんから探してきて、文章中に埋め込んでレコメンドしてくれるアプリを作ってみました。
例えば、下図のように北大路魯山人「だしの取り方」の文章を全部与えると、「鉋(カンナ)」や「だし」などの特徴的なキーワードを自動抽出して、それに合った挿絵を適した位置にレコメンドしてくれ、簡単に挿絵入りの文章を作れます。
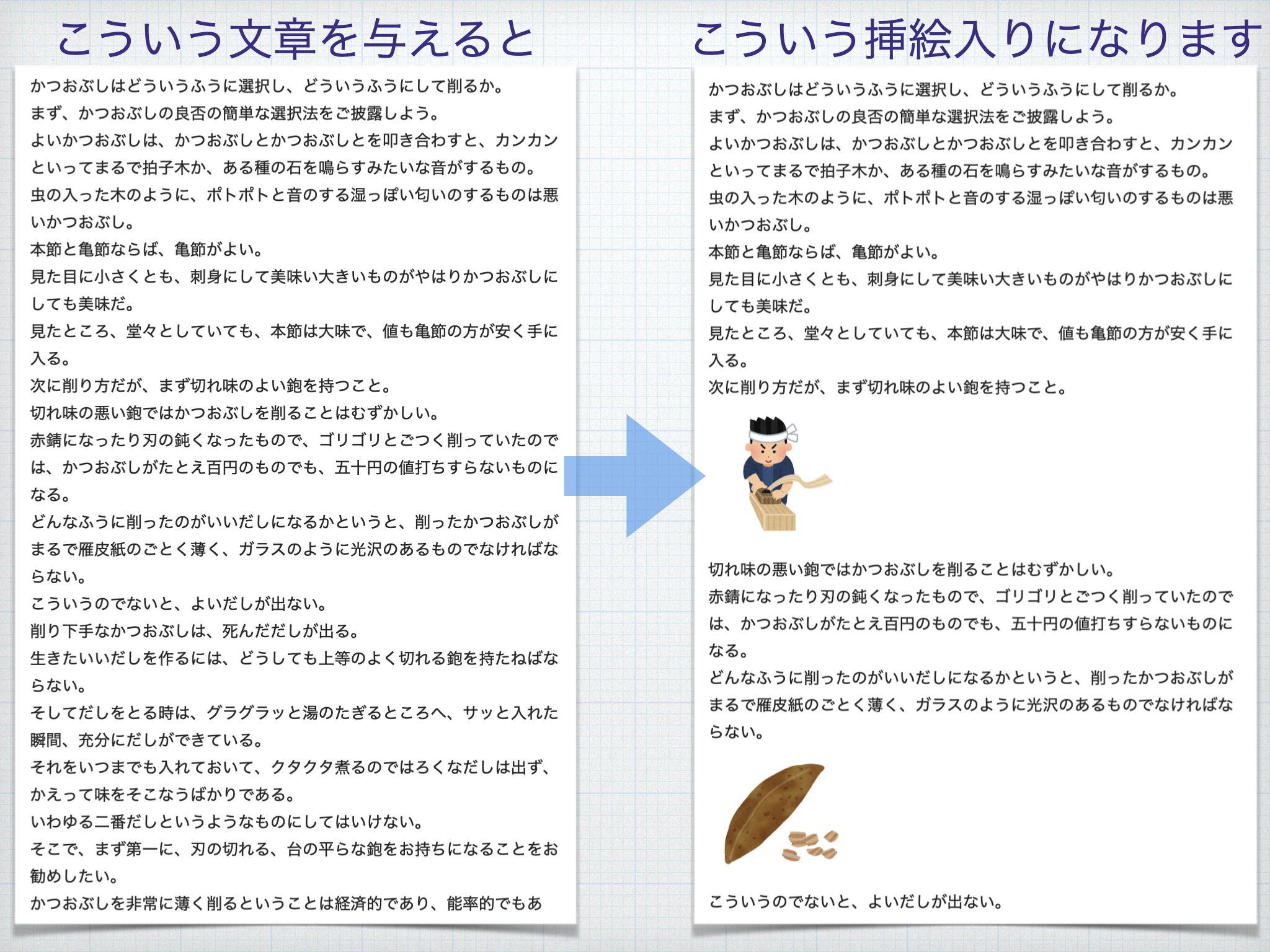
加えて、レコメンド完了までの所要時間は数秒です。簡単かつ高速!

以下、このアプリの作り方について解説していきます。
なお、本記事はあなたの文章に合った「いらすとや」画像をレコメンド♪シリーズの第三弾、応用編です。
適宜、シリーズの過去記事もご参照ください。
アルゴリズムの概要
アルゴリズムは次の3ステップでできています。
- 与えられた文章の中から特徴的なキーワードを抽出する。
- キーワードごとに(単純なキーワードマッチではなく)その意味に近い「いらすと」を検索する。
検索方法はアルゴリズム解説編の方法とほぼ同じです(少し違います)。 - 文章内のそのキーワードが初登場する位置に、検索した「いらすと」(複数個)を挿絵の候補としてレコメンドする。
この候補中から人が気に入った「いらすと」をクリックすると(いらすとやさんの該当ページを表示するとともに)その「いらすと」のみを挿絵として残す。
前提知識・スキル・マインド
アルゴリズム解説編の前提知識・スキル・マインドに加えて、アルゴリズム解説編の内容を理解していることとさせてください。
※いらすとやさんの画像の利用可能範囲は「ご利用について」と「よくあるご質問」をご確認ください。このアプリの利用時において踏んでしまいやすいものですと、商用利用における点数制限などありますので。
必要環境・データ
アルゴリズム解説編の必要環境・データに次を加えたものです。
-
日本語文区切りツール ja_sentence_segmenter
-
専門用語(キーワード)自動抽出システム TermExtractのPythonモジュール
-
学習済み分散表現モデル:
- ダウンロード: https://drive.google.com/file/d/16NYoJrQAX_Y72fgwBrK_ZHxgumbK9ZX3/view?usp=sharing
- Wikipediaの文章を形態素解析し、形態素の原形を用いて学習したfastTextモデルをMagnitude用に変換したものです。
- 注意: アルゴリズム解説編で使用する分散表現とは別のものです。
ライセンス
アルゴリズム解説編のライセンスに準じます。
アルゴリズム解説
それではアルゴリズムを実装していきましょう。
アルゴリズム解説編のコードをベースに少し追加変更したもののため、ほとんど同じ部分はざっくり省略します。
本記事再現(※)用ソースコードは下記からダウンロードできますので、全体はそれをご参照ください。
Google Colaboratory用の方がツールやデータの準備が不要な分だけ簡単です。
- Google Colaboratory用ソースコード ※ツールのインストールとデータのダウンロードも自動実行します。
※以下、画像メタデータとして、全件を用いた場合で解説しています。アルゴリズム解説編の必要環境・データにて、いらすとやさんのご好意で配布している94件の画像メタデータを用いた場合では違う結果になります(当然ですが、その94件に合ったキーワードに対してのみ意味のあるレコメンドができるので、今回の例では意味のある画像は出ません)。
注釈「全件の場合」「94件の場合」を目印にしてどちらの場合か見分けてください。
以下、例文として、北大路魯山人「だしの取り方」を用いて解説していきます。
document_text = """
かつおぶしはどういうふうに選択し、どういうふうにして削るか。まず、かつおぶしの良否の簡単な選択法をご披露しよう。よいかつおぶしは、かつおぶしとかつおぶしとを叩き合わすと、カンカンといってまるで拍子木か、ある種の石を鳴らすみたいな音がするもの。虫の入った木のように、ポトポトと音のする湿っぽい匂いのするものは悪いかつおぶし。
本節と亀節ならば、亀節がよい。見た目に小さくとも、刺身にして美味い大きいものがやはりかつおぶしにしても美味だ。見たところ、堂々としていても、本節は大味で、値も亀節の方が安く手に入る。
...以下省略...
ステップ1: 特徴的なキーワードの抽出
与えられた文章の中から特徴的なキーワードを抽出します。
様々な方法がありえますが、今回は専門用語(キーワード)自動抽出システムTermExtractを用いたキーワード(専門用語)を抽出する方法を採用してみました。
様々な方法に関しては、一番最後に少し考察します。
TermExtractを用いることで、複数の形態素からなる専門用語を重要度付きでリストアップすることができます。
まず、TermExtractのインプットとなる文章に対する形態素解析結果(今回はMeCabを用います)を用意します。
最初に文区切りします。
日本語文区切りツールja_sentence_segmenterを使えば楽チンです。
import functools
from ja_sentence_segmenter.common.pipeline import make_pipeline
from ja_sentence_segmenter.concatenate.simple_concatenator import concatenate_matching
from ja_sentence_segmenter.split.simple_splitter import split_newline, split_punctuation
def split_sentences(text):
split_punc2 = functools.partial(split_punctuation, punctuations=r"。!?")
concat_tail_te = functools.partial(concatenate_matching, former_matching_rule=r"^(?P<result>.+)(て)$", remove_former_matched=False)
segmenter = make_pipeline(normalize_text, split_newline, concat_tail_te, split_punc2)
return segmenter(text)
sentences = list(split_sentences(document_text.replace("\r\n", "\n")))
sentencesが文区切りされた文のリストです。
次にMeCabを用いて形態素解析します。
import termextract.mecab
import termextract.core
mecab_text = ""
for sentence in sentences:
tokens = tokenize(sentence)
if tokens:
mecab_text += "".join([token.line + "\n" for token in tokens]) + "EOS\n"
mecab_textがTermExtractのインプットとなる、全文を形態素解析した結果です。
TermExtractによる専門用語(キーワード)抽出を行います。
今回はTermExtractのサンプルコードにならいLR(単名詞の左右の連接情報)情報を用いる方法を採用しました。他にもパープレキシティやTF/DFなどを用いる方法もあり、チューニング要素になりえます。
- TermExtractのサンプルコード: 和布蕪(日本語)による用語抽出
import collections
term_frequency = termextract.mecab.cmp_noun_dict(mecab_text)
term_lr = termextract.core.score_lr(term_frequency, ignore_words=termextract.mecab.IGNORE_WORDS, lr_mode=1, average_rate=1)
term_importance = termextract.core.term_importance(term_frequency, term_lr)
term_collection = collections.Counter(term_importance)
最後に、重要度が高い専門用語をQUERY_LIMIT個(仮に5個)選び、特徴的な単語として採用します。
irasuto_queries = []
QUERY_LIMIT=5
for tokenized_term, score in term_collection.most_common()[:QUERY_LIMIT]:
query = termextract.core.modify_agglutinative_lang(tokenized_term)
irasuto_queries.append(query)
print(query + " " + str(score))
今回の例文北大路魯山人「だしの取り方」では、次の単語が選ばれました。妥当なものが選ばれていますね。数値は重要度です。
だし 30.0
昆布 28.284271247461902
料理 19.364916731037084
鉋 18.38477631085024
料理屋 11.771323825530848
料理と料理屋がやや重複しているように見えるので、何らかの方法で重複排除するともっと良くなるかもしれません。
ステップ2: キーワードの意味に近い「いらすと」を検索
ステップ1で抽出された特徴的なキーワードについて、キーワードごとに(単純なキーワードマッチではなく)その意味に近い「いらすと」を検索します。
検索方法はアルゴリズム解説編の方法とほぼ同じです。
違いは、使っている分散表現モデルと単語ベクトルの作り方だけです(検索方法は同じ)。
いくつか実験してみた結果、今回単語をキーに検索するからか、次の組み合わせが一番しっくりくる検索結果になりました(定性的かつ個人的な評価であるので妥当性を示すことは難しいですが)。
- 原形に変換した形態素を用いて学習した分散表現 https://www.floydhub.com/sonobe/datasets/fasttext_model/2 を用いる。
- 原形に変換した形態素を用いて単語ベクトルを計算する。
コードでいうと次のquery = token.baseがそこに該当します。
def get_token_vectors(sentence):
tokens = tokenize(sentence)
vecs = []
for token in tokens:
if is_stop(token):
continue
# query = token.surface
query = token.base
v = fasttext_model.query(query)
# v = v / np.linalg.norm(v, axis=0, ord=2)
vecs.append(v)
return vecs
def get_sentence_vector(sentence):
vecs = get_token_vectors(sentence)
if len(vecs) == 0:
return None
else:
# return np.array(vecs).max(axis=0)
# return np.array(vecs).mean(axis=0)
return np.array(vecs).sum(axis=0)
# return np.concatenate([np.array(vecs).max(axis=0), np.array(vecs).mean(axis=0)])
キーワードの意味に近い画像を検索する方法はアルゴリズム解説編と同一です。
つまり、キーワードとcos類似度が近い説明文を持った画像を探します。
検索結果を挿絵の候補としてレコメンド表示するHTMLにJavaScriptのコードが入っていますが、これは気に入った画像をクリックすると、いらすとやさんの該当ページを別ウィンドウに表示するとともに(通常の利用時と同じく、いらすとやさんに広告収入が入るようにするためです)、その画像のみを残して他は消すという処理になっています。
from IPython.display import display, HTML, clear_output
from html import escape
def to_irasuto_dom(item, similarity):
imgs = item["imgs"]
if not imgs:
return None
desc = escape(item["desc"])
page = item["page"]
dom_source = "<div>" + "".join(["<img src='" + img + "' width='100' onclick='window.open(\"" + page + "\", \"_blank\", \"noopener,noreferrer\");" + """
var thisImage = this.parentNode;
thisImage.parentNode.setAttribute("style", "padding:10px 10px 10px 10px;");
var unusedImages = [];
for (var node of thisImage.parentNode.childNodes) {
if (node !== thisImage) {
unusedImages.push(node);
} else {
for (var siblingNode of node.childNodes) {
if (siblingNode !== this) {
unusedImages.push(siblingNode);
}
}
}
for (var imgNode of node.getElementsByTagName("img")) {
imgNode.removeAttribute("onclick");
/* imgNode.setAttribute("style", Math.random() >= 0.5? "float:left" : "float:right"); */
}
};
for (var node of unusedImages) {
node.remove();
}'>""" for img in imgs]) + "<span>" + str(similarity) + ": " + desc + "</span></div>"
return dom_source
def to_irasuto_recommendation_dom(query, top_n=3):
query_vector = get_sentence_vector(query)
sims = []
if query_vector is None:
#print("検索できない文章です。もう少し文章を長くしてみてください。")
return None
else:
for item in items:
v = item["vec"]
if v is None:
sims.append(1.0)
else:
sim = sentence_similarity(query_vector, v)
sims.append(sim)
count = 0
irasuto_doms = []
for index in np.argsort(sims):
if count >= top_n:
break
irasuto_dom = to_irasuto_dom(items[index], sims[index])
if irasuto_dom is not None:
irasuto_doms.append(irasuto_dom)
count += 1
return ("<div style='background:rgb(253,243,243); padding:10px 10px 10px 10px;'><h3>キーワード「"
+ escape(query) + "」に合いそうな画像を探してみました。気に入ったものをクリックしてください。</h3>"
+ "".join(irasuto_doms) + "<button onclick='this.parentNode.remove();'>この中にはない</button></div>")
この検索結果のHTMLを文章中の適切な位置に埋め込めばOKです。
ステップ3: 挿絵候補を文中にレコメンド
最後に、ステップ2で得た挿絵候補のレコメンドを、文章内のそのキーワードが初登場する位置に表示します。
コードでいうと次のものです。説明はいらないレベルですね。
queries = irasuto_queries
document_html = ""
for sentence in sentences:
document_html += "<span>" + escape(sentence) + "</span><br>"
for query in queries:
if query in sentence:
document_html += to_irasuto_recommendation_dom(query=query, top_n=10)
queries = [query for query in queries if query not in sentence]
document_html += ""
display(HTML(document_html))
もう少し正確にするのであれば、文字列の比較(if query in sentence)ではなく、形態素が一致することを確認するといいでしょう。
アプリの動作確認
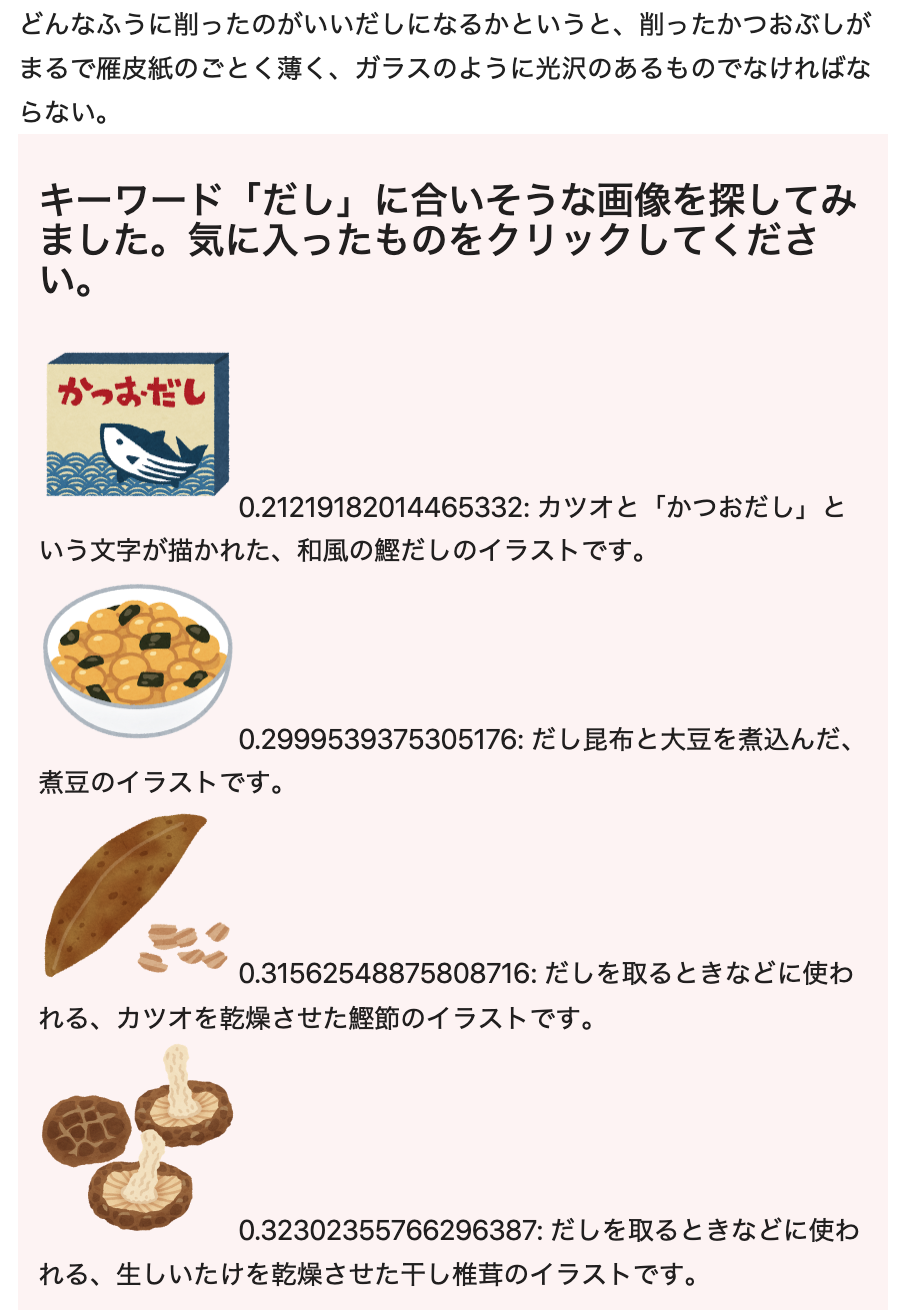
今回の例文北大路魯山人「だしの取り方」を対象に上記で解説したアルゴリズムを適用すると、まず、特徴的なキーワードとして次の5つがピックアップされます(重要度は画面に表示されません)。
- だし (30.0)
- 昆布 (28.284271247461902)
- 料理 (19.364916731037084)
- 鉋 (18.38477631085024)
- 料理屋 (11.771323825530848)
そして、下図のように、これらのキーワードが文章中で初登場する位置にレコメンドが表示されます(画像メタデータが全件の場合)。この方法ならここまで数秒ですが、仮に自分で同じことをしようとしたら、比べ物にならないくらい時間がかかるでしょう。

...
参考まで、画像メタデータが94件の場合(つまり、今回の例文に必要なメタデータがない場合)は下図のようになります。データが不足しているなりに頑張って近い意味の画像(魚や食事)を見つけてくれてはいます。

このレコメンドされた挿絵画像から気に入ったものをクリックすると、それだけが表示に残り最終的に下図のような挿絵入り文章ができあがります。

ほとんど手間なしに、圧倒的な読みやすさアップを実現できました!
まとめ
今回、そこそこ実用的な、ドキュメントの文章をまるっと全部与えると、自動で特徴的なキーワードを見つけてくれて、そのトピックに合った画像を「いらすとや」さんから探してきて、文章中に埋め込んでレコメンドしてくれるアプリを作ってみました。
いかがでしたでしょうか?
考察、次のステップ
本シリーズの記事では、教育的な意味を持たせるために(という言い訳のもと)要改良点が残るような、極力素朴な作りになるよう心がけました。
今回で言うと、最初の特徴的なキーワードを抽出する処理、挿絵を入れる箇所を決める処理には改良の余地が大きくあります。改良点について、発展問題を提示する形で少し考察します。
今回の抽出手法は、出現頻度が高いほど重要度も高くなる手法を採用しました。
この方法には向き不向きがあります。必ずしも出現頻度が高い単語の方が挿絵に適している訳ではないからです。
今回の例文である北大路魯山人「だしの取り方」は論述する文章であり、出現頻度の高い単語が論述対象となっており、今回の手法に合っています。
反対に物語である太宰治「走れメロス」に対して今回の手法を適用すると、抽出される単語は「メロス」や「王」や「セリヌンティウス」などの登場人物の名称になってしまいます(結果的に挿絵の箇所も前半に偏ります)。しかし、物語で重要なのは感情の変化やイベントと思われます。
従って、物語の挿絵をレコメンドする場合は、極端な感情の出現や大きな変化、そのきっかけになったイベントの発生を捉え、それを検索キーワードにしたり、挿絵が前半に偏らないような工夫があるといいように思われます。
また、別のアプローチとしては、今回は単語を用いて検索するようにしましたが、アルゴリズム解説編で扱っていうようなもう少し長い文章や文節を抽出して検索クエリにするという方法もあるでしょう。
実は、TermExtractを用いた方法を採用する前に、sumyのTextRankを試したのですが、アルゴリズム解説編の方法(文ベクトル = 単語ベクトルの平均)をベースにした限りでは結果はイマイチでした。
理由は明らかです。TextRankを用いたため、複数の特徴的な単語が複数含まれた複数の意味を持つ長めの文章が抽出されやすく、その文において単語ベクトルの平均を取ると、各次元の値に特徴の少ない鈍ったベクトルになってしまい、結果的に同種の長めの文章しか検索でヒットしなくなります。
従って、もう少し長い文章を用いて挿絵をレコメンドする場合は、この辺の問題を回避する必要があるでしょう。例えば、特徴的な文を抽出するときに文の短さや現れる概念の簡潔さも評価指標に入れるとか、文ベクトルを計算するときに鈍りにくい方法(平均ではなくmax-poolingするとか、ニューラル言語モデルを用いた文埋め込みにするとか)を用いるなどの工夫があるといいように思われます。
これらの問題に挑んでみれば、より実用的なアプリを生み出せると想像しております。ご興味のある方はぜひチャレンジしてみてください。
Qiitaにおける「いらすと」出現率の高さを鑑みるに、この挿絵レコメンドアプリをQiitaの下書きに対してさくっと適用できる仕組みを作るのもやってみたいお題であります。
謝辞
このアプリを実現できたのは、自然言語処理技術の進展もありますが、ひとえに「いらすとや」さんの画像のバリエーションの豊富さにあります。いつも見るたびに「こんなニッチな画像もあるのか!」とセンスの良さに驚かされます。
「いらすとや」という素晴らしいサービスを公開され、
また、今回の解説記事と画像メタデータの公開についてご承諾くださいました「みふねたかし」様に深く感謝いたします。

免責事項
著者は本シリーズ記事を掲載するにあたって、その内容、機能等について細心の注意を払っておりますが、内容が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。
本記事内容のご利用により、万一、ご利用者様に何らかの不都合や損害が発生したとしても、著者や著者の所属組織(日鉄ソリューションズ株式会社、NSSOL。旧新日鉄住金ソリューションズ株式会社(ややこし)です)は何らの責任を負うものではありません。
関連記事
本記事にご興味がある方が関心を持ちそうなNSSOL Advent Calendar 2019の記事をご紹介します。
-
@shimopinoさんによる「最速で把握するテキストからの画像生成モデルの潮流!」
- 私の記事は文章に合った「いらすと」画像を検索するというアプローチでしたが、この記事は深層学習を用いて文章から「いらすと」画像を自動生成するというアプローチです。まだ崩壊した画像までとのことですが、未来を感じさせる話です。生成を試すためのコードとモデルも公開されています。理論面の説明も懇切丁寧で勉強になりました。