はじめに
先回、ログ集約の文章を書いてからログ集約のお仕事を多く頂くようになり、ログを積極的にビジネスに活かす分析基盤構築の機会に恵まれました。それに伴い、いろいろなところで分析基盤にどのような技術を取り入れているか伺う機会が多くなりました。
分析基盤で利用されるツールの種類は多岐に渡り、企業様や事業の性格でいろいろ使い分けが出てきます。それなのに今回はそのような分析基盤の全体感を包括的に説明してしまう無謀な挑戦をしながら、私がおよそメジャーどころの分析基盤ツールを構築した際の使用感(と苦労話)を紹介したいと思います。
全体図
今回の記事で紹介する内容の構成イメージです。AWSとGCPのマルチクラウド、クロスプラットフォームの図になっています。AWSは極力クロスプラットフォームで環境を構築せずにAWSだけで囲い込みたい方針のようですが、世の中はクロスプラットフォームの流れに向いていくと思います。なぜなら、GCPやAzureがクロスプラットフォームを想定したサービスをいくつも打ち出しているからです。
データ分析基盤は幾層もの情報レベルのレイヤで説明されます。一般的にはDatalake/DataWareHouse/DataMartといった概念で説明されることが多いのですが、今回は技術的な話題を中心にしたいので、それよりは情報レベルのレイヤの低いETL(Extract/Transform/Load)の段階に分けて使用したツールを挙げていこうと思います。
ですが、今ではツールも便利になりETLの各段階をまたいで機能を提供するものも出てきました。また、ETLという言葉もELTと呼ばれたり、TはTransformではなくTransferであったりと、状況によって様々変わってくることがあります。そのために、どうしてもより包括的なDatalake/DataWareHouse/DataMartの段階と行きつ戻りつしながら説明する箇所が出てくることもありますがご容赦ください。


Extract
ログの抽出部分に相当します。
ログの抽出はほとんどログドライバによって行われているのでエンジニアはあまり意識することはありません。AWSではログの振り分けをする場合にCloudWatch Logs、GCPではCloud loggingやlog Sinkを使用しますが、それらは設定は特に難しいことはないのでここでは紹介しません。分析基盤としてはCloudWatch LogsとSplunkの組み合わせがサービスとして用意されていますが、導入事例としては少ないので今回は説明を見合わせました。
こちらもまだ事例は少ないのですが、ここではログ抽出としては非常に多く利用されていると言っていいfluetndの後継?であるFluentbitを用いた事例を紹介したいと思います。
AWS Firelens(Fluentd/Fluentbit)
去年の10月にFirelensがAWSからGAされました。FirelensはFluentdのsidecarを利用しやすくしたサービスで、ログの送信先を柔軟に変更することができることが特徴です。また、C++/Golangベースのfluetndbitをsidecarに用いることも可能です。先回の記事では時代遅れ的なことを書いたFluentdですが、GCPでもGKE上ではFluentdをログドライバのようにしてログ送信しているのでまだ全然現役な技術と感じています。しかし、FluentbitはさらにFluentdよりさらに使いやすくなっているように感じます。
Fluentbitは軽量/高速/設定が簡単、またFluentdとは異なりDockerImageのOSに依存せず使用できます。同じTreasure Data製品ですが、Fluentbitを作った人も私と同じようなことを考えてFluentbitを作ったのではないかと邪推しています。Fluentdに比べて設定が直感的で、awslogsドライバでは直接送信できないkinesisやDatadog、ElasticSearchなどのサービスにもデフォルトでログ送信できます。プラグイン次第でさらに他のサービスにもログ送信可能で、特にCloud Pub/Subにおいては私の方でプラグインに機能拡充するForkリポジトリを提供しています。是非ともご利用してください!
その他、Fluentd同様ログのフィルタリングやパースも可能で、かなり柔軟な対応を可能にします。Fluentdのforwarderで可能だったことを機能はそのままにより簡単で高速にしたイメージです。
枯れた技術を使用していますが その利用周りではまだ揉まれていない部分があり、2020/7/20現在 Fargateのプラットフォームバージョン1.4.0ではFirelensの拡張設定ファイルの読み込みができないバグがあります。最新に常に追従するような運用も時にはリスクになります。
現在ではバグも解消され、問題なく動作しています。FirelensだけでなくFluentbitもリリースを重ねて安定しているように見えます。
Transform
収集したログを整形、変換、送信する段階です。
分析基盤構築の話題は特にこの段階の説明が中心になります。ここでは、Cloud Dataflow、Fluentd Aggregator、オブジェクトストレージ、BigQueryなどのデータウェアハウスを紹介します。
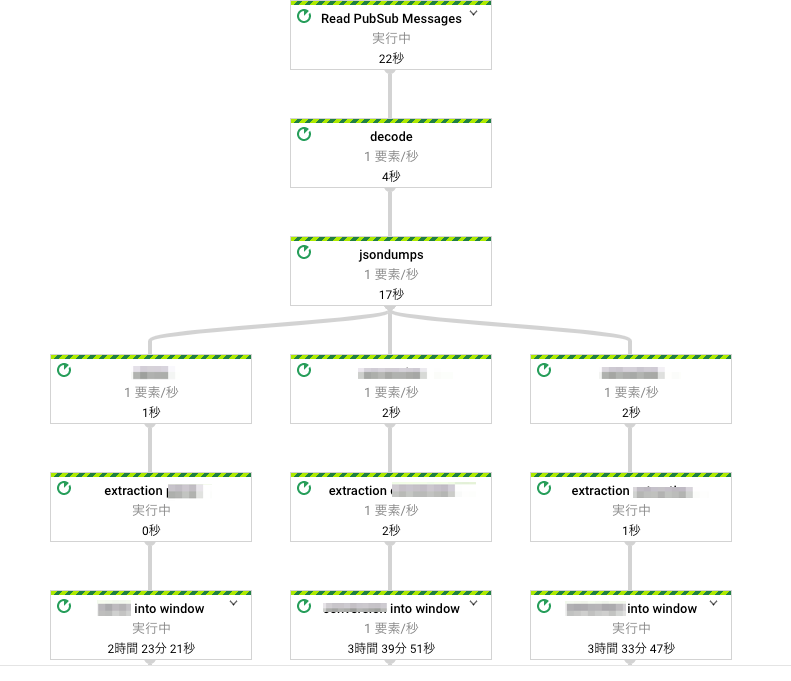
Cloud Dataflow
先回の記事ではKinesisを紹介しましたが、今回はGCPのCloud Dataflowを紹介します。まだ日本ではそこまで知名度はないですがじわじわと知名度が上がってきており、今後の躍進が期待できる技術と思います。
Cloud DataflowはApache BeamをGCP上で提供するサービスです。少し前までは大規模環境のログ集約といえばHadoop + Sparkを用いた技術が中心でした。現在においてもその組み合わせは最も高性能ですが、大容量データ処理に特化した構成であるため、例えば映像処理のような膨大な容量のデータを扱う処理でもなければ持て余し気味になることがありました。
その一方でApache BeamはHadoopよりも使いやすく小規模から大規模構成まで幅広く対応できることが特徴で、Cloud Dataflowの場合はオートスケーリングも可能になり、より広いユースケースで用いられることとなりました。コスト的にはKinesisより若干かかりますが、記述するコードはとても少なくなります。
日本ではまだ事例が少なく文献に当たる際に苦労したのですが、理解するとコーディングしやすく、単純な構造のパイプラインでしたらログの細かいフィルタリングはCloud Loggingのlog Sinkに任せてしまえば、パイプラインをコーディングで表現するだけで良いです。また、パイプラインの分岐や連結もわかりやすく記述できるし、他にも重複排除などと言ったETLにつきものの機能も簡単に実装できます。Apache BeamはJavaで作られているのでJavaのAPIが最も充実しているのですが、PythonのAPIもかなり増えてきており、API機能でまかなえない部分もPythonの記述の仕方でカバーできます。ログ集約対象のサービスはかなり多く、GCP上のサービスのログは全て取り扱えそうです(違ってたらごめんなさい)。もちろん実装次第でGCP以外のサービスでも、収集、送信共に可能です。
Fluentd Aggregator
先回の記事では(しつこい)、Fluentdを古いと切り捨ててしまっていましたが、仕事でFluentdを使う機会は減らずまだまだ現役な技術なのだなと感じます。現在の分析基盤はクラウドで構築することがほぼ必須ですが、Fluentdは元々Saasが隆盛してくる以前から存在する技術なので、特にAggregatorとして使用するならクラウドでの運用に耐えるほど柔軟な変更/更新には対応できていないと思います。Fluentd Aggregatorは一度稼働し始めるとおいそれと構成を変えることができないため、設計段階でしっかりと構成の内容を煮詰めて検討しないと、後々になって検討が甘いところのつけが回ってくることになると考えています。
Fluentd Aggregatorを構成する場合には可用性が重要になると思います。冗長構成はもちろんのこと、バッファやハートビートを使用する際のチャンクの大きさ、Dockerよりはインスタンスで構成した方がいいのでインスタンスの大きさやディスク容量(IOPSに関わってきます)、プラグインのバージョン管理など、管理項目が多岐に渡るので運用が大変になります。他にもありますが長くなるので、Fluentd Aggregatorを構築する際に苦労した点は以下にまとめました。こうした点を踏まえながら運用する覚悟が必要です。
Fluentdを構成するにあたり苦労した点
Fluentdは、 ・問題が発生した場合にログ情報が十分でない場合が多く、dumpまで辿らないと原因がわかりにくいことが多い(プラグインの所為で死んだりすると原因が調査しにくい)。そんな時、dockerで構成されていたりするとさらに調査が面倒になる。 ・プラグインが乱立していて、相互で様式が異なるバージョン違いで、記載様式が大きく異なる ・送信漏れを回避するためにheartbeat通信をしているとbufferが詰まりやすくなる ・大規模なシステムでFluetdを連結させて構成を組んでいたりすると、Fluentd相互間で連携が取りづらくなり、ログ詰まりの原因につながりやすい ・ディレクティブも直観的に意味がわかりにくい(matchとfilterって名前、混同しやすくないですか?) ・プラグインは個人作成の物が多いので、プラグイン間で同じ機能なのに違う名称を用いていたりして更に混同しやすくなる などのようなことがあり、私は好きではありません。Digdag + Embulk
Digdagは並列処理、スレッド実行を得意としたWorkflow Engineです。Workflow Engineの有名どころは他にはLuigiやArgo、Airflowなどがありますが、Digdagの場合は特に記述が簡単で、大容量のデータを取り扱うことを得意としています。例えば、先ほども少し触れたテレビ局などの映像処理関係や創薬会社の遺伝子解析などです。
大容量データを処理する際には、例えばDigdag自身のリソースを消費しないようにバッチ処理用のdockerをジョブとして立ち上げて並列で実行すると良いと私は思います。Digdagはジョブのステートを全て自身のPosgreSQLに格納しているため、ジョブが失敗しても処理段階が失われず失敗したところから処理を継続できます。他にポイントとしては、Digdag自身に大量の処理をさせる場合はEmbulkを導入するケースがよくありますが、この場合はDigdag自体の処理性能が求められます。
大容量、高負荷の話をしてきましたが、Digdagを使う場合は可用性を担保するための構成が重要になってきます。Digdagの構成で注意したい点も長くなるので以下にまとめました。
Digdagを構成するにあたり注意したい点
・Digdag Agent(処理する側)とDigdag Server(UIを表示する側)の分離が必要 ・ジョブ実行時に負荷が高くなるとUIにアクセスできなくなり、ジョブの緊急停止などができなくなる ・Digdag Agentを2台以上にするHA構成は当然必要 ・流行りのDockerを使用してDigdagを構成するよりは、インスタンスにDigdagを入れてしまった方が安定する ・Dockerで組んでしまうと高負荷に処理が耐えにくくなるし、Dockerが落ちたことを検知しにくくなる(Server側はDockerでもいい) ・内部のPostgreSQLはいわばDigdag本体と言ってもよく、AuroraやCloud SQLなどのマネージドサーバでPgを組んだ方がいい ・ジョブのステートをちゃんとジョブに記載しておかないと、ジョブが失敗したところから継続しにくくなる
オブジェクトストレージ(s3/GCS)
E(Extract)で抽出したログは、T(Transform)の段階ではDatalakeとして、s3、GCSなどのオブジェクトストレージに格納したり、処理の中継段階として一時保存したりします。
分析基盤では、概念的にはオブジェクトストレージはDatalakeの段階に相当することが多いです。ですが、そのDatalakeと言う言葉のニュアンスでデータをあまり深く考えることなく溜め込んでしまうと事故の元になりがちです。データ基盤を作るに当たって意識が向きにくいけれど重要なことは、きちんとデータの位置づけを決めることです。データをきっちり整理して管理しないとデータを活用する段階で重複や欠けが生じてしまいます。
データウェアハウス(BigQuery/RedShift)
BigQueryやRedshiftはデータウェアハウスの段階として説明されることが多いです。双方を比較した場合、ユースケースによって細かく違うのでここでは詳しくは紹介しませんが、大体においてBigQueryの方がクエリがかなり早く、導入事例も多く、コストも安いと聞きます。
最近では、マルチプラットフォームでBigQueryを動かすことができるBigQuery Omniが発表され、BigQueryの応用範囲が劇的に広がりそうな予感がしました。ですが、実体はAnthos上でBigQueryを動かし、Anthosとの契約を結んでいる場合でのみ利用できるので、おいそれと手が出る代物ではなさそうです。
他にはBigQueryはカラム単位でアクセスを制限する機能も出たり機能の拡充が活発ですが、日本リージョンで利用する場合にはまだ未対応の機能も多いので、データの性質上日本から持ち出せないようなデータがある場合には注意が必要となります。
データ基盤構築におけるBigQueryでのテーブル構築のポイントとしては、データセット/テーブル/ビューの管理は然ることながら、見逃しやすいのはタイムパーティションでテーブルを区切ることでしょうか。BigQueryはクエリに料金がかかってくるので、タイムパーティションを区切らないとwhere句を用いていても料金がかかります。個人的に苦労して、尚且つあまり議論がされていない部分で言うとBigQueryのテーブル構造はカラムはcsv、カラムのネストはJSONの構造となっています。ネストしたカラム構造にデータを格納する際にはいろいろ細かい設定が必要になります。また、スキーマの変更に柔軟に対応できないところもつらいです。
RedShiftの方では、私はs3に対してクエリをかけることができるRedshift Spectrumが結構使いやすくてコストも安いので好きでした。BigQueryと異なりスキーマレスなところも良いでしょうか。RedshiftはBigQueryに比べて目立った機能の拡充はないですが機能改善はずっと続けてられている様子なので、引き続き動静を注視したいと思います。
Load
データを活用する段階です。一般にBIツールと呼ばれているものが相当します。OSSとして提供されているツールから、有料のツールまでいくつか紹介していきたいと思います。
Redash/Metabase
OSSのBIツールです。大体BigQueryやRedshiftと連携して用いられます。Redashは使いやすいですが安い印象で、Metabaseは直感的な使用に向いている感覚です。これらはOSSということもあり導入にあたってのハードルが高くないので、まずはBIツールご検討の段階として始めるには適していると思いますが、やはりOSSなのでバグの対応が行き届いていないところもあります。
最近の話題としては、RedashがDatabricksに買収されたとの発表がありました。今後はより充実した中身に変わってくるのではないでしょうか。後に紹介するTableauも去年Salesforceに買収されましたがこの分野は買収のニュースが多いので、BIツールの状況は発展途上で状況もこれから色々変わってくるのでしょう。
Metabase
Elasticsearch + Kibana
ECサイトでとてもよく導入されている組み合わせです。柔軟な検索ができるため検索エンジンとして使用されますがその反面複雑なクエリには向かないので、分析に使用する場合はアドホック分析として用いられることが多いです。有償機能としてX-packがあり、こちらを導入すると描画機能は向上しますが、結構高価なので検討が必要になるでしょう。
クラウドではマネージドのElasticsearchを提供するサービスもありますが、細かい設定が必要になることが多いElasticsearchではマネージドの場合では設定ができない場合があったり、また、一度保存したデータを部分的に削除することが難しいのでそういった点は注意が必要です。
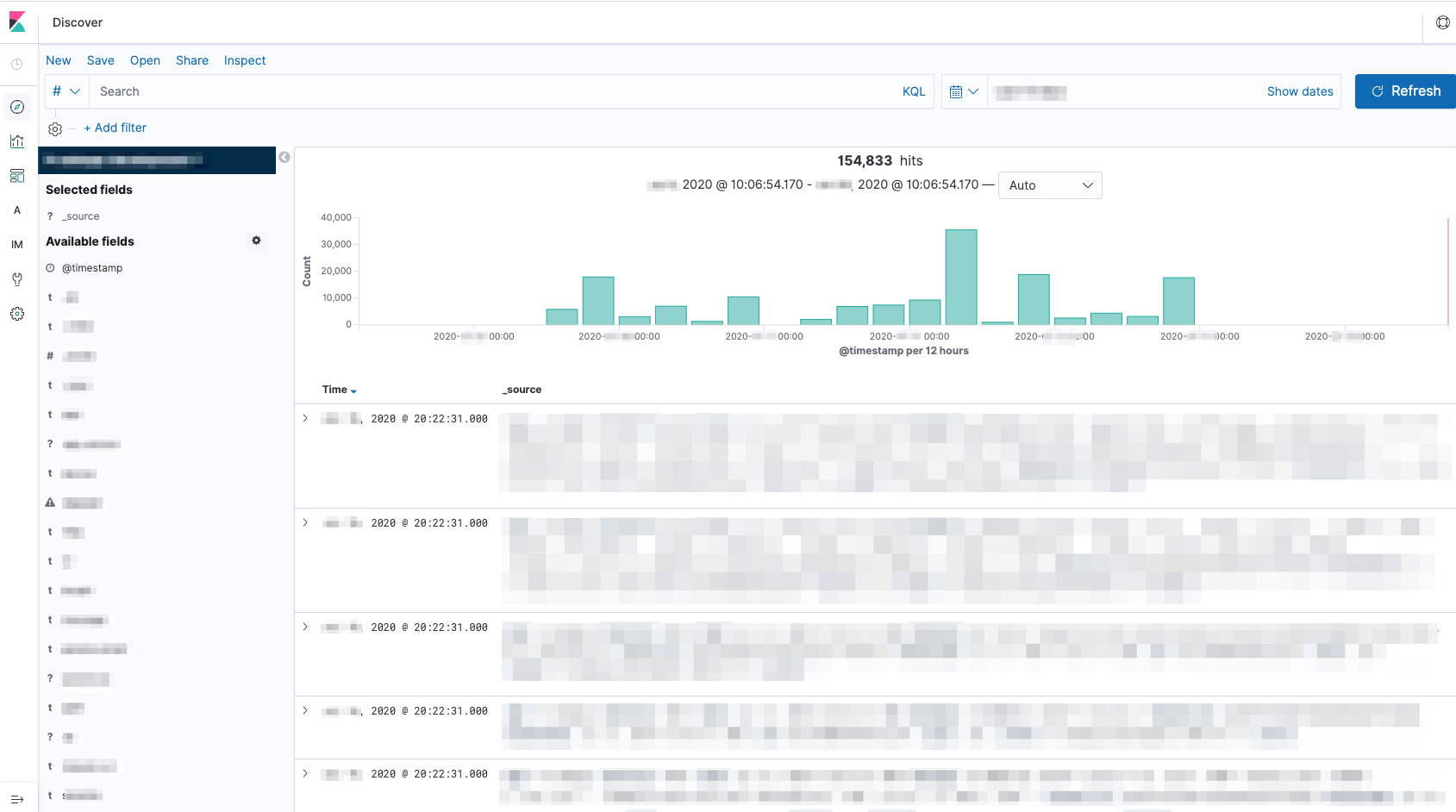
Tableau + Alteryx
Tableauは現在でも使用されているビジネス分析ツールの中では割と早い段階で登場したツールなので、有名なBIツール群の中ではクラウドを前提としたシステムに追従できておらず、クラウドで使用する分には満足できない部分があるかもしれません。というのは、分析データをローカルPCに保存する必要があるので、大容量のデータを描画する場合などには自身のPCの性能に動きが制限され、BIツールで重要なポイントである「ユーザーエクスペリエンスを損なう」ことになるかもしれません。おそらくそういった声が取り入れられてクラウド版のTableauが後発で出てきたのでしょうが、まだ機能面では十分と言ったレベルに達していないようです。
Looker
Loockerは現行のBIツールではおそらく一番優秀だと思います。Lookerを利用するような企業は資金も潤沢で、日本の企業ではわずか70社程度しか利用されていないそうですが、とても優秀な製品なので紹介します。LookMLというyaml形式のデータモデリング言語を用いてクエリを発行し、UIも合わせて直感的な操作が可能であり、もし大きなプロジェクトでご利用を検討されていらしてるとしたら一考の価値があると思います。先にも少し申し上げましたが唯一のネックは非常に高価なうえ、お試しで利用することができないので、なかなか導入を考えるところまでは行かない模様です。
Monitoring
最後にMonitoring(監視)です。データ分析基盤には監視は欠かすことができません。クラウド環境で監視をする場合に登場する監視ソフトは現在ではほぼ二極化している状況であり、その二つを紹介したいと思います。
Datadog
Datadogは監視ツール全般を見渡しても比較的設定が簡単で使いやすいです。設定が簡単なだけでなく内容も細かいところまで詰めることができますが、その分お金がかかります。1hostの監視コストが月$18です。ですが、監視Saasということを考えると、監視の手間をDatadog側で持ってもらっていると言うことができるので、監視に割くことができる人的リソースやOSSの監視ツールを使用した場合の管理コストと直接的な監視費用との費用対効果を比べながら導入を検討されると良いでしょう。監視に力を入れたくないけれど監視はちゃんとしたい、監視対象ホストはそこまで数が多くない、という場合に検討の余地があると思います
Prometeus + Grafana
Datadogともう一つよく挙げられるのが、PrometheusとGrafanaの組み合わせです。Prometheusは公式で完全な監視を保証しない旨が出ています。そのため、ログを恒久的に保持したまま監視の可用性を保証するために、thanosを用いてHA構成を組むなりデータを永続化したりと利用者側で工夫する必要が出てきます。一方で、運用環境によっては監視対象の数が膨大であったり、監視が事業の主要な目的となっている会社もあると思います。そうした場合はPrometheusとGrafanaは検討してみても良いと思います。
Grafanaのダッシュボードは有志の方が多数の物を用意されており、監視用のexporter(DatadogのAgentのようなものと考えてください)を導入してGrafanaが公開しているダッシュボードをインポートすれば、洗練されたビジュアルのダッシュボードがすぐに作成できます。利用のしやすさもなかなかなので、上記のような状況に該当される方はご検討されてみてはいかがでしょうか。

まとめ
以上、私が携わってきたデータ基盤構築を振り返りながら、概観をまとめてみました。
ログ集約をビジネスに活かすという際に、それが構築、管理コストに見合うものなのか?というのは常につきまとうテーマであると思います。自社の性格に合った構成を組み、正しくリスクとリターンを把握し、ビジネスに活かすというのは難しい課題ですが、ここではまず選定の先鞭となるように導入時における問題に焦点を当てて紹介してきました。皆様の分析基盤構築の一助となれば幸いです。
データ分析とは各データ間の様々な相関を見つけて、それをビジネス用途に生かすことです。そのためには多角的な視点で分析をするために、いかにしてデータを編集加工しやすい形にするか。が重要なポイントになってきます。昨今ではこうしたデータ基盤構築ブームが以前に比べれば少し下火になってきたところと思いますが、その本質は時代を経ても変わるものではなく、常に誰からも必要とされる技術であると考えています。集積したデータを利用するサイクルを何度も回していくことで、真に役立つエコシステムを作り上げる。データ分析基盤に必要なことはそうしたものだと考えています。