はじめに
ログ集約といえば古くはtd-agentで収集してfluentdのaggregatorサーバでまとめるという方式が主流でしたが、時代はフルマネージド、そしてマイクロサービスとなり、新しい状況にふさわしいプレイヤーはついに出揃った感があります。
そこで、今回はログ収集機構について送信、収集、処理、分析のフェーズに分けて、勝手にマイクロサービス時代のログ集約システム周りを総括したいと思います。
マイクロサービスとは
マイクロサービスとは、システム内のアプリケーション、モジュール、サービスを極力小さく構成し、互いのアプリケーション間の依存度を低く構成されたサービスのことを指します。そして、ここで紹介するサービスはすべて互いに用途に応じてサービスの切り替えを簡単に行えるように構成されています。
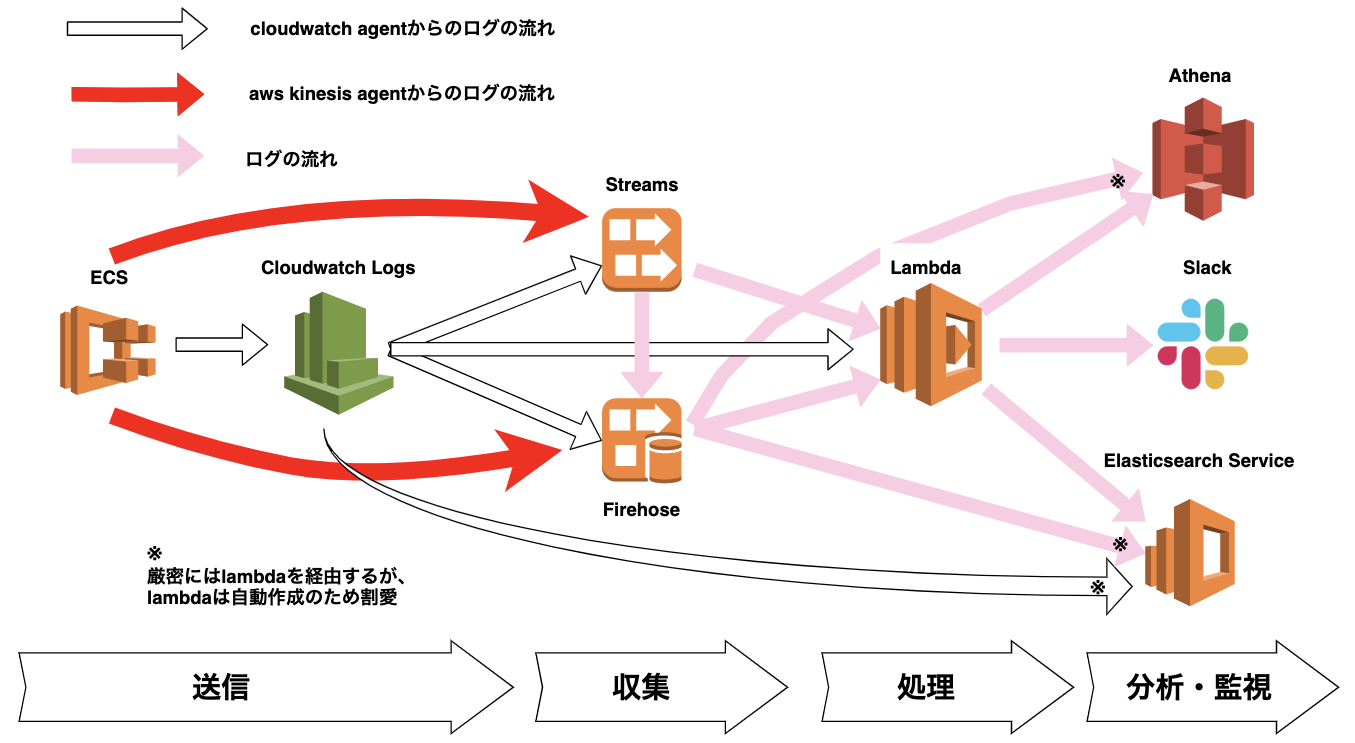
ログ収集概念図
今回説明するリソースの大まかな概念図です。ログ収集の関係サービス全てを網羅している訳ではないのでご参考まで。
例えば、今回の説明でも少し登場するsplunkやIoTやRedshiftなどは省略されています。
送信
従来はfluentd(td-agent)が頑張っていた部分ですが、AWS用fluentdのプラグインは存在するものの、どうしても純正ではないので対応が後手になってしまう部分があるようです。
という訳で、ログ送信はおよそ次の二つのエージェントに分けられる状況となっております。
aws-kinesis-agent
| 特徴 | ・EC2、コンテナがagent.jsonで規定した内部の任意のログをkinesisに送信する ・cloudwatchでagentのメトリクス監視可能 |
| 転送機能 | ・ログの一行を随時、json、もしくはユーザが規定した様式のいずれかのデータとしてkinesisに送信 |
| メリット | ・送信先を複数指定可能 ・KCLを使用することで大容量の送信に対応 |
| デメリット | ・ログローテーション考えないといけない |
aws-kinesis-agentはkinesis Data StreamsかFirehoseに対して任意のログ出力を送信します。
後述しますが、プラグインや設定を導入することにより簡単なログの整形や大量のログ送信にも耐えることができます。
cloudwatch agent
| 特徴 | ・cloudwatch logsに対してEC2、コンテナ内の任意のメトリクス、ログを送信できる ・簡単なフィルタリング可能(正規表現不可) |
| 転送機能 | ・(cloudwatch logsの話だが) サブスクリプションによりlambda、kinesis、AES(elasticsearch)にログを送ることができる |
| メリット | ・コンテナでは標準出力に送ることでログローテ不要 ・AWSでの一覧性を容易にする |
| デメリット | ・一つのロググループに対し送信先を一つしか指定できない (二つ以上の宛先に送信する場合は、lambdaを使用するしかない) ・フィルタはあるけれど正規表現を使えない ・標準出力に複数のログを含めてしまうと、ログが混ざる ・lambdaに直にログ送信すると、送信漏れが起こる可能性があるので、その対応を考えなくてはいけない |
cloudwatch agentは EC2上で通常cloudwatch logsに表示されないログに対してもcloudwatch logsで参照できるようにします。
さらにcloudwatch logsに集約してからは、サブスクリプションという機能でログをlambda、AES、kindsisに転送することができます。
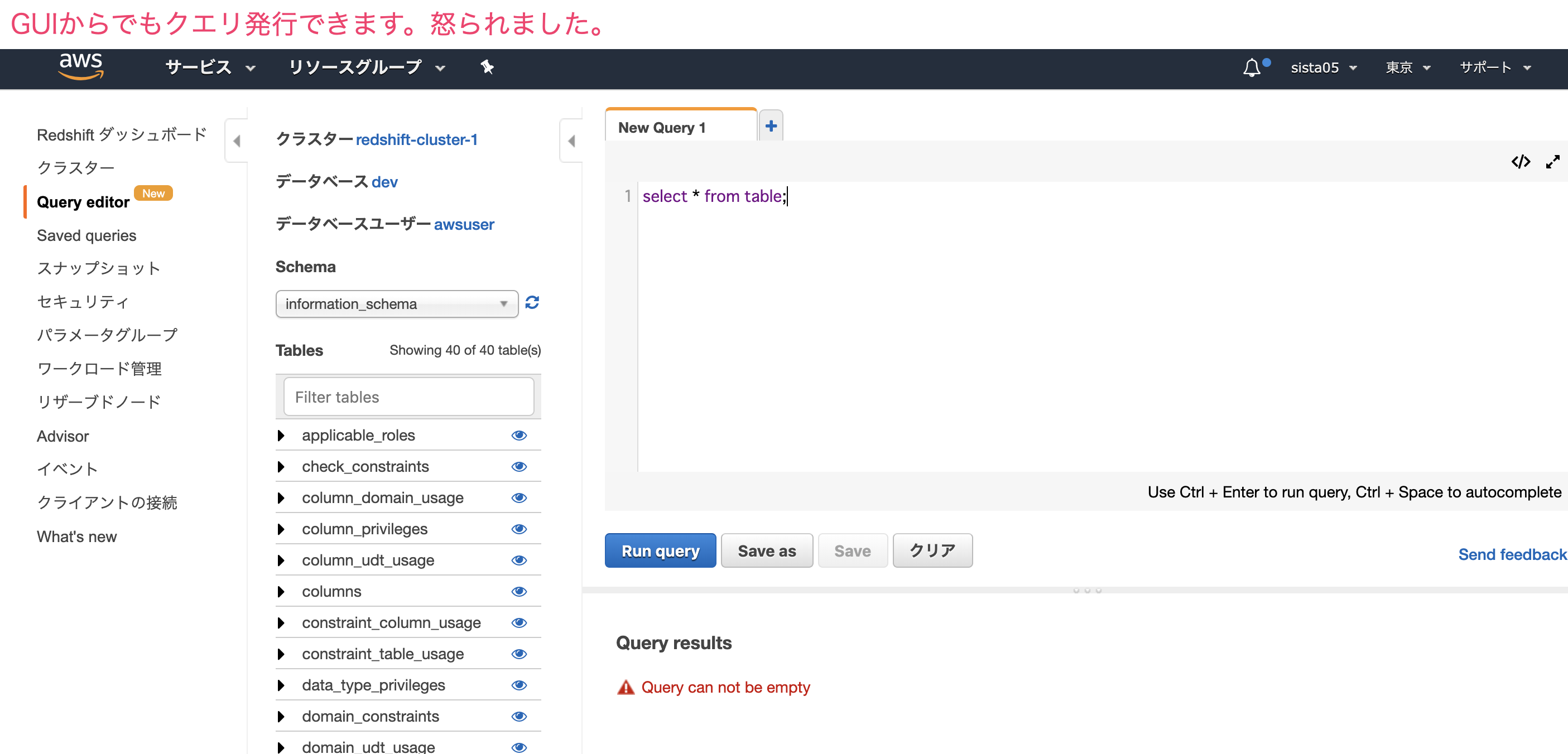
kinesisに送信する場合はGUIからサブスクリプションフィルタをかけることができないので、例えば以下のように設定します。
サブスクリプションフィルタ例
$ aws logs put-subscription-filter \
--log-group-name "CloudTrail" \
--filter-name <somefiltername> \
--filter-pattern "{$.userIdentity.type = Root}" \
--destination-arn "arn:aws:logs:<region>:<accountid>:destination:testDestination"
タイムリーな話題としては、ついにFargateのログドライバーにもSplunkが対応しましたので、大体メジャーなAWSリソースのログをSplunk上で管理できるようになったのではないでしょうか。Splunkは、AWS上のインフラ環境をボード上で一覧管理できるツールで、一覧性に欠けるCloudwatch logsと比較して、横断的な検索をかけることができます。
収集
従来は、ログデータをAggregatorサーバに集約する構成が一般的でしたが、Aggregatorは冗長化しづらくボトルネックとなっていました。
また、サーバやネットワークで障害が発生した場合のためにログの保持についても考慮が必要でしたが、kinesisが一度保存したデータについては保証してくれるようになったため、設計がずいぶん楽になりました。
なお、kinesis Analyticsは現時点で東京リージョンに来てないので割愛しました。
(※と思ったら今年の5/8に来てましたね・・・・・。投入されたデータに対してsqlをかけることができますが、lambdaでも同じことできますね。)
kinesis Data Streams
| 特徴 | ・リアルタイム ・カスタム |
| 容量 | シャードを増やすことで事実上無制限 |
| 転送先 | ・Firehose ・lambda |
| 保持期間 | 最大七日間保持 |
| 料金 | ・シャード時間ごとに課金 シャード一本で月1 × 24(h) × 31(day) × 0.026 = $19.344 (約2200円) |
Kinesis Data Streamは送信元、送信先、実行のトリガーなどをAWSのリソース内で柔軟に設定することが可能です。シャードという概念上の土管みたいなのを増やすことにより、事実上無制限に流量を増やすことができます。また、取り込んだデータは最大で七日間保持しておくことができます。シャードの数とシャードが存在している期間により使用料金が変わってきます。
kinesis Firehose
| 特徴 | ・設定に手間がかからない ・遅延あり(60~900秒) |
| 容量 | ・1,000 レコード/秒 ・1,000 トランザクション/秒 ・1 MiB/秒 ※制限緩和可能 |
| 転送元 | ・IoT ・API ・agent |
| 転送先 | ・s3 ・Redshift ・lambda ・splunk |
| 保持期間 | 24時間保持 |
| 料金 | 取り込まれたデータ量による。 レコードの大きさや数で変わってくるがざっくり1GBでヒトケタ円。 |
kinesis Firehoseは、kinesis Data Streamsと比較して設定が楽で、GUI操作でagent、cloudwatch、IoTなどから集めたデータをそのままRedshiftやElasticsearchに送ることができます。また、あまり運用コストがかからないという利点がありますが、一方でリアルタイムなデータ転送には対応していません。
処理
ログの処理の仕方は、従来はFluentdのaggregatorサーバの設定ファイルtd_agent.confで書式を規定していました。
しかし、フルマネージドな環境においては特にlambdaを使用することで、かなり柔軟な処理設計ができるようになりました。
従来の処理方式と比較をしながら、フルマネージドでの利点を挙げていきます。
agent側の対応
ログのフォーマット整形をagentに任せる場合、agent側で処理するのもこれまではポピュラーな手段でした。
ですが、windows製のソフトを使用していたりすると、文字コードやフォーマットの対応がLinuxとはかなり異なる場合があり、agent側だけでの処理対応は難しい場合を私も経験したことがあります。
aws-kinesis-agentでログを送信する設定の一例
{
"cloudwatch.emitMetrics": true,
"cloudwatch.endpoint": "monitoring.ap-northeast-1.amazonaws.com",
"kinesis.endpoint": "https://kinesis.ap-northeast-1.amazonaws.com",
"flows": [
{
"filePattern": "/var/log/nginx/access*",
"kinesisStream": "stream01",
"dataProcessingOptions": [
{
"optionName": "CSVTOJSON",
"logFormat": "COMMONAPACHELOG",
"delimiter": "\\t",
"customFieldNames": ["time", "remote_addr", "request_method", "request_length", "request_uri", "https", "uri", "query_string", "status", "bytes_sent", "body_bytes_sent", "referer", "useragent", "forwardedfor", "request_time", "upstream_response_time"]
}
]
},
{
"filePattern": "/var/log/nginx/error*",
"kinesisStream": "stream01",
"dataProcessingOptions": [
{
"optionName": "LOGTOJSON",
"logFormat": "COMMONAPACHELOG",
"matchPattern": "(^)([\\d/]+\\s[\\d{2}:]+) \\[(.+?)\\] (.+?)",
"customFieldNames": ["nginx_error", "time_stamp", "log_level", "message"]
}
]
},
{
"filePattern": "/var/log/php-fpm-error.log",
"kinesisStream": "stream01",
"dataProcessingOptions": [
{
"optionName": "LOGTOJSON",
"logFormat": "COMMONAPACHELOG",
"matchPattern": "(^)\\[([\\d\\-\\w:\\s]+)\\] (.+): (.+?)",
"customFieldNames": ["php-fpm-error", "time_stamp", "log_level", "message"]
}
]
}
]
}
lambdaの対応
ログのフォーマットがlinuxライクでない場合でも、ログ処理はすべてlambdaに任せてしまうことで処理部分の分離を図り、自由度の高いカスタマイズが可能になります。
言わずと知れたlambdaは、ユーザが任意の言語で処理を実装することが可能で、オートスケールし、様々なイベントをトリガーに処理を実行することが可能です。
KCL、KPLの対応
| ツール | 特徴 |
|---|---|
| KPL(Kinesis Producer Library) : | ・ログを集約する。 ・コア部分はC++で実装 |
| KCL(Kinesis Client Library) | ・集約されたログを展開(Disaggregation)する。 ・Javaで実装。 ・MultiLangDaemonを介して他言語でも実装可 |
また、特にkinesisと併用してデータを処理する場合には、kinesis専用のライブラリであるKPL(Kinesis Producer Library)、KCL(Kinesis Client Library)を用いることで一度に取り扱うデータ量を大きくすることができます。
ビッグデータを扱う環境や、秒間数万単位のログを取り扱う場合などに使用されています。
分析・監視
分析ツールでは、個人ユースや中小企業では取り扱うことが難しかったビッグデータを手軽にビジネスユースとして取り扱うことができるようになりました。
以下に代表的なツール例を挙げます。
| ツール | 用途 |
|---|---|
| s3 athena/QuickSight | s3に対してクエリ発行し、検索結果をグラフ描画、可視化する。 |
| Elasticsearch + kibana | Webシステム用全文検索エンジン。RESTで構築されたデータ構造に対して検索をかけ、グラフ描画、可視化する。 |
| Redshift(Spectrum) | ビッグデータ。並列処理により大量のデータを高速で処理する。 |
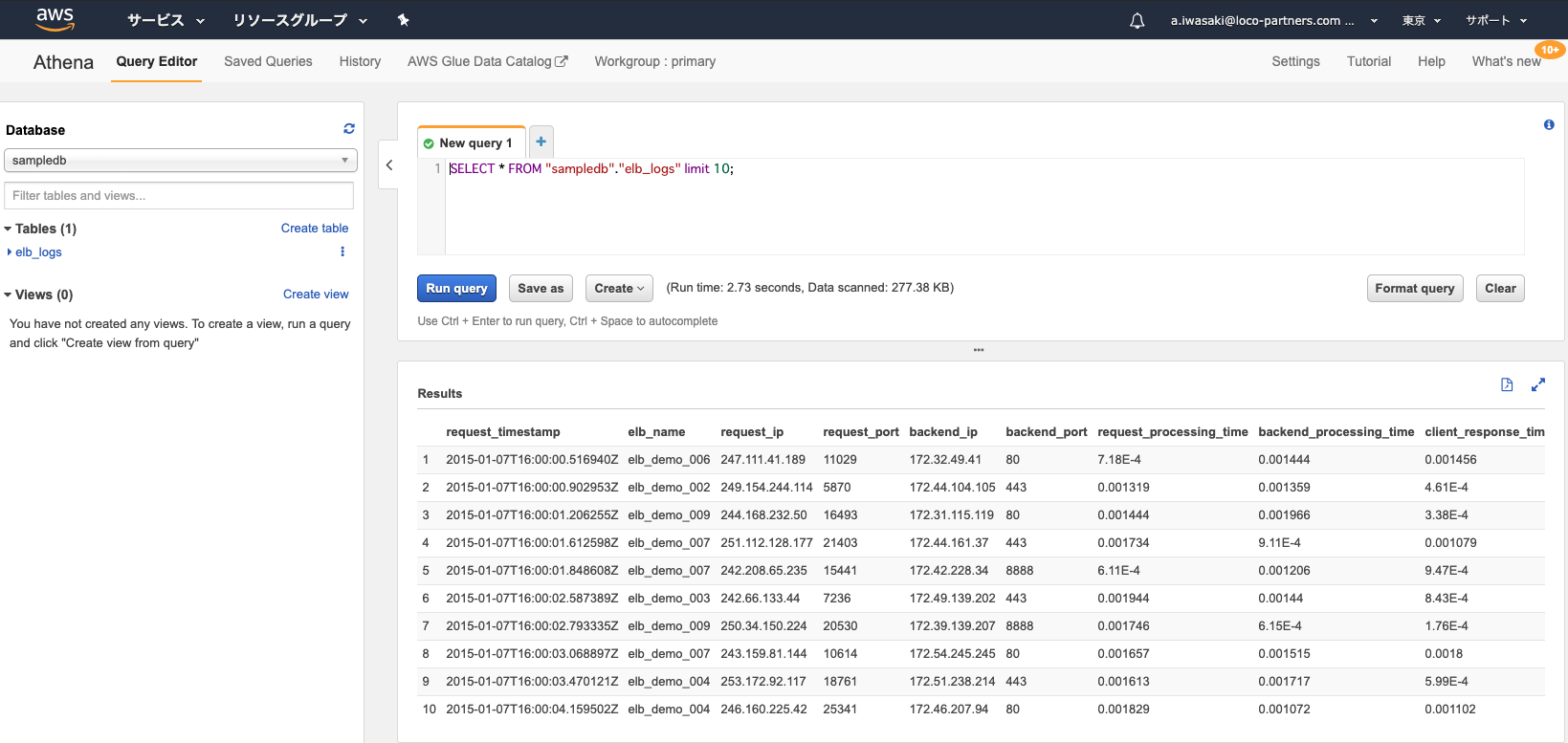
athena
s3 athena はs3に対してSQLクエリを発行することができるツールです。
athenaはクエリの発行数だけ料金を支払うシステムなので、パーティションを区切り、検索対象を絞ることは必須となります。こうした場合にためになる記事があるので、ぜひご覧になってください。
QuickSight
また、athenaはQuicksightと併せて使用するユースケースもあります。
Quicksightはs3を対象にathenaなどで分析した内容を視覚化するBIツールです。大容量データの分析などに使用します。
BIツールでビッグデータに対応すると言えば、他にはTableauなどが有名ですね。
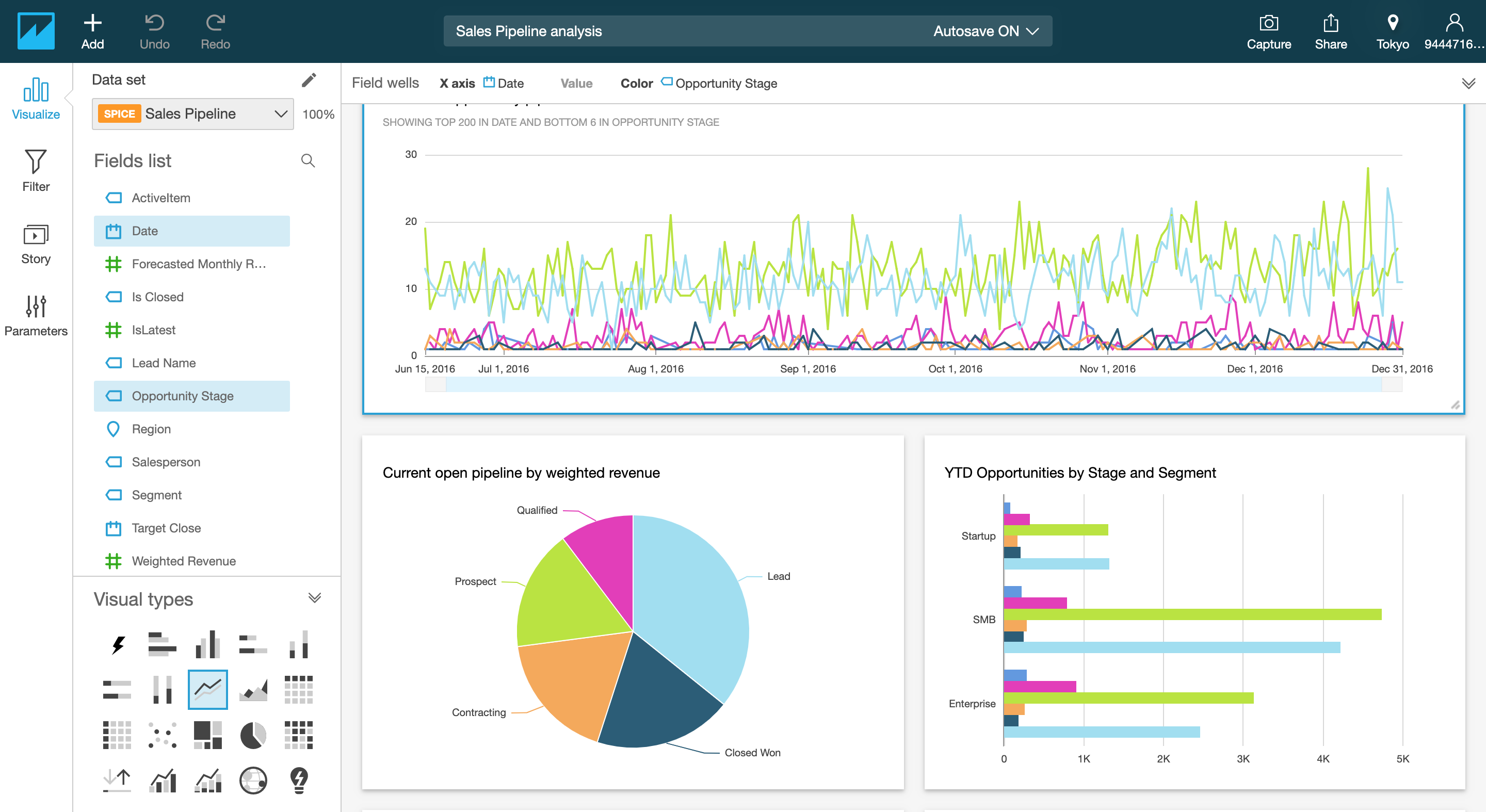
elasticsearch + kibana
Web分析ツールです。index、typeと呼ばれるDB、テーブル構造を作成します。ですが、SQLよりも抽象的な検索に対応しています。長期的なデータ保持には向いていませんが、snapshotと呼ばれる機能でindexを過去のデータのバックアップを取得し、s3などに退避させておくことができます。
またkibanaと併用することで、現時点でのアクセスやエラー状況などをリアルタイムに可視化して表示することができます。

Redshift
1000万オーダ以上のクエリを発行する場合、RedshiftやBigQueryなどのツールを使用します。また、s3をデータレイクとして使用している場合には、Redshift Spectrumを使用すればs3に対してクエリを発行することができます。
それでもビッグデータにクエリを投げる場合ではBigQueryの方が安くて早いので、AWS+GCPなどのクロスプラットフォームで運用している企業さんも多いと聞きます。
通知
分析、監視の派生としての通知です。通知のプレイヤーは一般的なジョブマネージャー、メール、SNSなど様々な種類がありますが、つい先日、オラクルさんでslackには他のツールにはない魅力があると語っておられました。
そこで、今回の場合はslackを例として説明したいと思います。
Slack
通知したいメッセージをSlack webhookという個々のチャンネルに固有のURLに対してPOSTすることで、特定のチャンネルに対してメッセージ通知することができます。
以下ではモザイクを施していますが、エラーメッセージを専用チャンネルに通知し、チャンネルを登録しているユーザは一斉にメッセージの内容を知ることができます。

まとめ
以上、ログ集約システム周りの総括でした。
今回は特にAWS周りを中心に話を進めましたが、Redshiftの部分でも少し触れましたが、今後のマイクロサービスの目指す先はおそらくクロスプラットフォーム化の方向に進み、このサービスにおいてはGoogleが強い、Alibabaが強い、といったような使い分けが加速する時代に進んでいくのではないでしょうか。
マイクロサービス化が進むにつれコモディティ化も進み、そのような中で生き残るには個別の強みを特化していく必要が出てくるのでしょう。
ありがとうございました。